Archive
Relative sizes of computer companies
How large are computer companies, compared to each other and to companies in other business areas?
Stock market valuation is a one measure of company size, another is a company’s total revenue (i.e., total amount of money brought in by a company’s operations). A company can have a huge revenue, but a low stock market valuation because it makes little profit (because it has to spend an almost equally huge amount to produce that income) and things are not expected to change.
The plot below shows the stock market valuation of IBM/Microsoft/Apple, over time, as a percentage of the valuation of tech companies on the US stock exchange (code+data on Github):
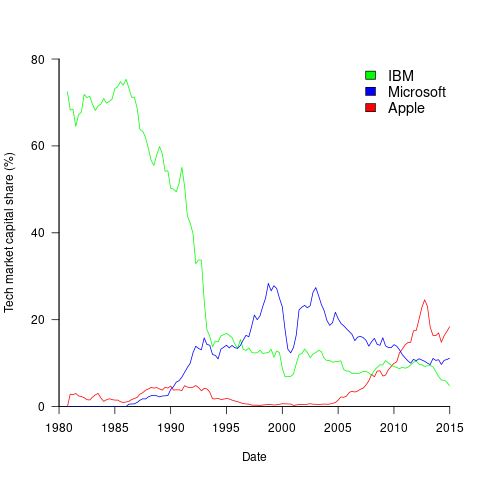
The growth of major tech companies, from the mid-1980s caused IBM’s dominant position to dramatically decline, while first Microsoft, and then Apple, grew to have more dominant market positions.
Is IBM’s decline in market valuation mirrored by a decline in its revenue?
The Fortune 500 was an annual list of the top 500 largest US companies, by total revenue (it’s now a global company list), and the lists from 1955 to 2012 are available via the Wayback Machine. Which of the 1,959 companies appearing in the top 500 lists should be classified as computer companies? Lacking a list of business classification codes for US companies, I asked Chat GPT-4 to classify these companies (responses, which include a summary of the business area). GPT-4 sometimes classified companies that were/are heavy users of computers, or suppliers of electronic components as a computer company. For instance, I consider Verizon Communications to be a communication company.
The plot below shows the ranking of those computer companies appearing within the top 100 of the Fortune 500, after removing companies not primarily in the computer business (code+data):
![]()
IBM is the uppermost blue line, ranking in the top-10 since the late-1960s. Microsoft and Apple are slowly working their way up from much lower ranks.
These contrasting plots illustrate the fact that while IBM continued to a large company by revenue, its low profitability (and major losses) and the perceived lack of a viable route to sustainable profitability resulted in it having a lower stock market valuation than computer companies with much lower revenues.
Rereading The Mythical Man-Month
The book The Mythical Man-Month by Fred Brooks, first published in 1975, continues to be widely referenced, my 1995 edition cites over 250K copies in print. In the past I have found it to be a pleasant, relatively content free, read.
Having spent some time analyzing computing data from the 1960s, I thought it would be interesting to reread Brooks in the light of what I had recently learned. I cannot remember when I last read the book, and only keep a copy to be able to check when others cite it as a source.
Each of the 15 chapters, in the 1975 edition, takes the form of a short five/six page management briefing on some project related topic; chapters start with a picture of some work or art on one page, and a short quote from a famous source occupies the opposite page. The 20th anniversary edition adds four chapters, two of which ‘refire’ Brooks’ 1986 paper introducing the term No Silver Bullet (that no single technlogy will produce an order of magnitude improvement in productivity).
Rereading, I found the 1975 contents to be sufficiently non-specific that my newly acquired knowledge did not change anything. It was a pleasant read, various ideas and some data points are presented, the work of others is covered and cited, a few points are briefly summarised and the chapter ends. The added chapters have a different character than the earlier ones, being more detailed in their discussion and more specific in suggesting outcomes. The ‘No Silver Bullet’ material dismisses some of the various claimed discoveries of a silver bullet.
Why did the book sell so well?
The material is an easy read, and given that no solutions are heavily pushed, there is little to disagree with.
Being involved on a project for the first time can be a confusing experience, and even more experienced people get lost. Brooks can provide solace through his calm presentation of project behaviors as stuff that happens.
What project experience did Brooks have?
Brooks’ PhD thesis The Analytic Design of Automatic Data Processing Systems was completed in 1956, and, aged 25, he joined IBM that year. He was project manager for System/360 from its inception in late 1961 to its launch in April 1964. He managed the development of the operating system OS/360 from February 1964, for a year, before leaving to found the computer science department at the University of North Carolina at Chapel Hill, where he remained.
So Brooks gained a few years of hands-on experience at the start of his career and spent the rest of his life talking about it. A not uncommon career path.
Managing the development of an O/S intended to control a machine containing 16K of memory (i.e., IBM’s System/360 model 30) might not seem like a big deal. Teams of half-a-dozen good people had implemented projects like this since the 1950s. However, large companies create large teams, operating over multiple sites, with every changing requirements and interfaces, changing hardware, all with added input from marketing (IBM was/is a sales-driven organization). I suspect that the actual coding effort was a rounding error, compared to the time spent in meetings and on telephone calls.
Brooks looked after the management, and Gene Amdahl looked after the technical stuff (for lots of details see IBM’s 360 and early 370 systems by Pugh, Johnson, and Palmer).
Brooks was obviously a very capable manager. Did the O/360 project burn him out?
Analyzing mainframe data in light of the IBM antitrust cases
Issues surrounding the decades of decreasing cost/increasing performance of microcomputers, powered by Intel’s x86/Pentium have been extensively analysed. There has been a lot of analysis of pre-Intel computers, in particular Mainframe computers. Is there any major difference?
Mainframes certainly got a lot faster throughout the 1960s and 1970s, and the Computer and Automation’s monthly census shows substantial decreases in rental prices (the OCR error rate is not yet low enough for me to be willing to spend time extracting 300 pages of tabular data).
During the 1960s and 1970s the computer market was dominated by IBM, whose market share was over 70% (its nearest rivals, Sperry Rand, Honeywell, Control Data, General Electric, RCA, Burroughs, and NCR, were known as the seven dwarfs).
While some papers analyzing the mainframe market do mention that there was an antitrust case against IBM, most don’t mention it. There are some interesting papers on the evolution of families of IBM products, but how should this analysis be interpreted in light of IBM’s dominant market position?
For me, the issue of how to approach the interpretation of IBM mainframe cost/performance/sales data is provided by the book The U.S. Computer Industry: A Study of Market Power by Gerald Brock.
Brock compares the expected performance of a dominant company in a hypothetical computer industry, where anticompetitive practices do not occur, with IBM’s performance in the real world. There were a variety of mismatches (multiple antitrust actions have found IBM guilty of abusing its dominant market power).
Any abuse of market power by IBM does not impact the analysis of computer related issues about what happened in the 1950s/1960s/1970, but the possibility of this behavior introduces uncertainty into any analysis of why things happened.
Intel also had its share of antitrust cases, which will be of interest to people analysing the x86/Pentium compatible processor market.
Two approaches to arguing the 1969 IBM antitrust case
My search for software engineering data has made me a regular customer of second-hand book sellers; a recent acquisition is: “Big Blue: IBM’s use and abuse of power” by Richard DeLamarter, which contains lots of interesting sales and configuration data for IBM mainframes from the first half of the 1960s.
DeLamarter’s case, that IBM systematically abused its dominant market position, looked very convincing to me, but I saw references to work by Franklin Fisher (and others) that, it was claimed, contained arguments for IBM’s position. Keen to find more data and hear alternative interpretations of the data, I bought “Folded, Spindled, and Mutilated” by Fisher, McGowan and Greenwood (by far the cheaper of the several books that have written on the subject).
The title of the book, Folded, Spindled, and Mutilated, is an apt description of the arguments contained in the book (which is also almost completely devoid of data). Fisher et al obviously recognized the hopelessness of arguing IBM’s case and spend their time giving general introductions to various antitrust topics, arguing minor points or throwing up various smoke-screens.
An example of the contrasting approaches is calculation of market share. In order to calculate market share, the market has to be defined. DeLamarter uses figures from internal IBM memos (top management were obsessed with maintaining market share) and quote IBM lawyers’ advice to management on phrases to use (e.g., ‘Use the term market leadership, … avoid using phrasing such as “containment of competitive threats” and substitute instead “maintain position of leadership.”‘); Fisher et al arm wave at length and conclude that the appropriate market is the entire US electronic data processing industry (the more inclusive the market used, the lower the overall share that IBM will have; using this definition IBM’s market share drops from 93% in 1952 to 43% in 1972 and there is a full page graph showing this decline), the existence of IBM management memos is not mentioned.
Why do academics risk damaging their reputation by arguing these hopeless cases (I have seen it done in other contexts)? Part of the answer is a fat pay check, but also many academics’ consider consulting for industry akin to supping with the devil (so they get a free pass on any nonsense sprouted when “just doing it for the money”).
Recent Comments