Archive
Christmas books for 2023
This year’s Christmas book list, based on what I read this year, and for the first time including a blog series that I’m sure will eventually appear in book form.
“To Explain the World: The discovery of modern science” by Steven Weinberg, 2015. Unless you know that Steven Weinberg won a physics Nobel prize, this looks like just another history of science book (the preface tells us that he also taught a history of science course for over a decade). This book is written by a scientist who appears to have read the original material (I’m assuming in translation), who puts the discoveries and the scientists involved at the center of the discussion; this is not the usual historian who sprinkles in a bit about science, while discussing the cast of period characters. For instance, I had never understood why the work of Galileo was considered to be so important (almost as a footnote, historians list a few discoveries of his). Weinberg devotes pages to discussing Galileo’s many discoveries (his mathematics was a big behind the times, continuing to use a geometric approach, rather than the newer algebraic techniques), and I now have a good appreciation of why Galileo is rated so highly by scientists down the ages.
Chapter 2 of “When Old Technologies Were New: Thinking about electric communication in the late nineteenth century” by Carolyn Marvin, 1988. The book is worth buying just for chapter 2, which contains many hilarious examples of how the newly introduced telephone threw a spanner in to the workings of the social etiquette of the class of person who could afford to install one. Suitors could talk to daughters without other family members being present, public phone booths allowed any class of person to be connected directly to the man of the house, and when phone companies started publishing publicly available directories containing subscriber name/address/number, WELL!?! In the US there were 1 million telephones installed by 1899, and subscribers were sometimes able to listen to live musical concerts and sports events (commercial radio broadcasting did not start until the 1920s).
“The Grand Strategy of the Roman Empire: From the first century A.D. to the third” by Edward Luttwak, 1976; h/t Mr. and Mrs. Psmith’s review. I cannot improve or add to John Psmith’s review. The book contains more details; the review captures the essence. On a related note, for the hard core data scientists out there: Early Imperial Roman army campaigning: observations on marching metrics, energy expenditure and the building of marching camps.
“Innovation and Market Structure: Lessons from the computer and semiconductor industries” by Nancy S. Dorfman, 1987. An economic perspective on the business of making and selling computers, from the mid-1940s to the mid-1980s. Lots of insights, (some) data, and specific examples (for the most part, the historians of computing are, well, historians who can craft a good narrative, but the insights are often lacking). The references led me to: Mancke, Fisher, and McKie, who condensed the 100K+ pages of trial transcript from the 1969–1982 IBM antitrust trial down to 1,500+ pages of Historical narrative.
Worshipping the Future by Helen Dale and Lorenzo Warby. Is “… a series of essays dissecting the social mechanisms that have led to the strange and disorienting times in which we live.” The series is a well written analysis that attempts to “… understand mechanisms of how and the why, …” of Woke.
Honourable mentions
“The Big Con: The story of the confidence man and the confidence trick” by David W. Maurer (source material for the film The Sting).
“Cubed: A secret history of the workplace” by Nikil Saval.
Halstead & McCabe metrics: The wisdom of the ancients
Study after study finds that the predictive power of both the Halstead metric and the McCabe cyclomatic complexity metric is no better than counting lines of code, for the characteristics of interest. Why do people continue to use and cite the Halstead and McCabe metrics?
My experience, talking to people, is that many believe these metrics have greater predictive power than lines of code. Sometimes I explain the situation, other times I move on.
Those who are aware of the facts often continue to use these metrics. Why do they do this?
Given the lack of alternative metrics that are more effective than lines of code, for the claimed uses of Halstead/McCabe, following the herd is the easy option (I regularly point this out to people, after explaining that Halstead/McCabe don’t do what is claimed on the tin). Tools are available to calculate the metrics; the manual effort is clicking buttons or running a command.
Why were the Halstead/McCabe metrics ‘successful’, in that they are the ones people cite/use today?
Both were formulated in the mid-1970s, when the discussion around measuring software started in earnest, so they had some first-mover advantage (within a few years they were both being suggested for use by US Military). Individuals promoted their ideas: Maurice Halstead was a senior professor, with colleagues and lots of graduate students, who advertised the metric via their publications; Thomas McCabe was working for the NSA when his famous paper was published, and went on to form a company working in the area of source code analysis.
The Halstead/McCabe metrics can both be calculated by processing the source one line at a time (just count decision points for McCabe, no need for the pretentious graph theory stuff). In the 1970s, computer memory was often measured in kilobytes, which made it difficult to implement complicated metrics that required keeping dependency information in memory.
Metrics based on the subroutine/function/procedure/method as the measured unit of source code had an implementation and usage advantage over metrics based on larger units of code.
In the 1990s, object-oriented programming, in the form of C++ and then Java, took off. The common view, by those caught up in the times, was that object-oriented software was so different from what went before that it needed its own metrics.
The 1991 paper: Towards a Metrics Suite for Object Oriented Design, by Chidamber and Kemerer, introduced the six CK metrics (as they become known; 1992 update). The nearest this paper comes to citing the Halstead/McCabe work is to say: “Some early work has recognized the shortcomings of existing metrics and the need for new metrics especially designed for OO.” The paper followed in the footsteps of the earlier work in not providing any evidence for the claims made (the update contains histograms of metric values from a C++ project and a Smalltalk project).
The 1996 paper: Evaluating the Impact of Object-Oriented Design on Software Quality, by Abreu and Melo, introduced the MOOD metrics (Metrics for Object-Oriented Design).
At the end of 2022 the total citation counts returned by Google Scholar were: McCabe 8,670, Halstead 4,900, CK 8,160, and MOOD 354.
The plot below shows the number of new citations returned by Google Scholar, each year, for the respective metrics papers (or book for Halstead; code+data):
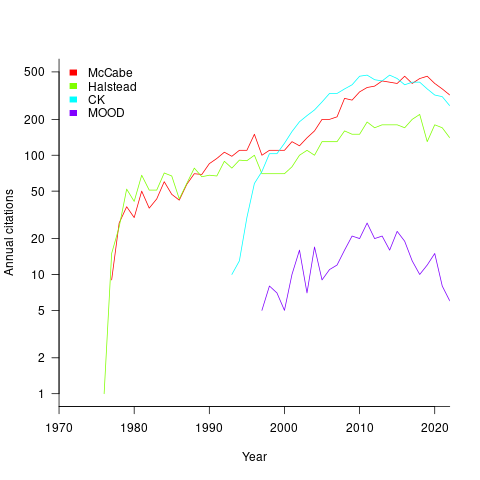
The ongoing growth in annual rate of citation probably has more to do with the growth in the number of software papers published each year, rather than these metric papers being cited by an expanding number of research fields.
Do authors tend to cite one or the other of Halstead/McCabe, or both?
Using Google Scholar’s ‘search within’ option to find the subset of papers that included a string matching the title of a paper: 46% of the Halstead citations include a citation of the McCabe paper, and 25% of the McCabe citations include a citation of the Halstead paper.
The Inciteful’s paper network (with citation counts: Halstead 1,052 and McCabe 4,970) found 657 papers citing both (62% of the Halstead total, 12% of the McCabe).
It’s not possible to make use of the OpenCitations API because it is DOI based, and the Halstead citation is a book.
An evidence-based software engineering book from 2002
I recently discovered the book A Handbook of Software and Systems Engineering: Empirical Observations, Laws and Theories by Albert Endres and Dieter Rombach, completed in 2002.
The preface says: “This book is about the empirical aspects of computing. … we intend to look for rules and laws, and their underlying theories.” While this sounds a lot like my Evidence-based Software Engineering book, the authors take a very different approach.
The bulk of the material consists of a detailed discussion of 50 ‘laws’, 25 hypotheses and 12 conjectures based on the template: 1) a highlighted sentence making some claim, 2) Applicability, i.e., situations/context where the claim is likely to apply, 3) Evidence, i.e., citations and brief summary of studies.
As researchers of many years standing, I think the authors wanted to present a case that useful things had been discovered, even though the data available to them is nowhere near good enough to be considered convincing evidence for any of the laws/hypotheses/conjectures covered. The reasons I think this book is worth looking at are not those intended by the authors; my reasons include:
- the contents mirror the unquestioning mindset that many commercial developers have for claims derived from the results of software research experiments, or at least the developers I talk to about software research. I’m forever educating developers about the need for replications (the authors give a two paragraph discussion of the importance of replication), that sample size is crucial, and using professional developers as subjects.
Having spent twelve chapters writing authoritatively on 50 ‘laws’, 25 hypotheses and 12 conjectures, the authors conclude by washing their hands: “The laws in our set should not be seen as dogmas: they are not authoritatively asserted opinions. If proved wrong by objective and repeatable observations, they should be reformulated or forgotten.”
For historians of computing this book is a great source for the software folklore of the late 20th/early 21st century,
- the Evidence sections for each of the laws/hypotheses/conjectures is often unintentionally damming in its summary descriptions of short/small experiments involving a handful of people or a few hundred lines of code. For many, I would expect the reaction to be: “Is that it?”
Previously, in developer/researcher discussions, if a ‘fact’ based on the findings of long ago software research is quoted, I usually explain that it is evidence-free folklore; followed by citing The Leprechauns of Software Engineering as my evidence. This book gives me another option, and one with greater coverage of software folklore,
- the quality of the references, which are often to the original sources. Researchers tend to read the more recently published papers, and these are the ones they often cite. Finding the original work behind some empirical claim requires following the trail of citations back in time, which can be very time-consuming.
Endres worked for IBM from 1957 to 1992, and was involved in software research; he had direct contact with the primary sources for the software ‘laws’ and theories in circulation today. Romback worked for NASA in the 1980s and founded the Fraunhofer Institute for Experimental Software Engineering.
The authors cannot be criticized for the miniscule amount of data they reference, and not citing less well known papers. There was probably an order of magnitude less data available to them in 2002, than there is available today. Also, search engines were only just becoming available, and the amount of material available online was very limited in the first few years of 2000.
I started writing a book in 2000, and experienced the amazing growth in the ability of search engines to locate research papers (first using AltaVista and then Google), along with locating specialist books with Amazon and AbeBooks. I continued to use university libraries for papers, which I did not use for the evidence-based book (not that this was a viable option).
Programming Languages: History and Fundamentals
Programming Languages: History and Fundamentals by Jean E. Sammet is often cited in discussions of language history, but very rarely read (I appreciate that many oft cited books have not been read by those citing them, but age further reduces the likelihood that anybody has read this book; it was published in 1969). I read this book as an undergraduate, but did not think much of it. For around five years it has been on my list of books to buy, should a second-hand copy become available below £10 (I buy anything vaguely interesting below this price, with most ending up left on trains or the book table of coffee shops).
Thanks to Adam Gashlin the Internet Archive now contains a downloadable copy.
The list of 120 languages covered contains a handful of the 28 languages covered in an article from 1957. Sammet says that of the 120, 20 are already dead or on obsolete computers (i.e., it is unlikely that another compiler will be written), and that about 15 are widely used/implemented).
Today, the book is no longer a discussion of the recent past, but a window in to the Cambrian explosion of programming languages that happened in the 1960s (almost everything since then has been a variation on a theme); languages from the 1950s are also included.
How does the material appear to me from a 2022 vantage-point?
The organization of the book reminded me that programming languages were once categorized by application domain, i.e., scientific/engineering users, business users, and string & list processing (i.e., academic users). This division reflected the market segmentation for computer hardware (back then, personal computers were still in the realm of science fiction). Modern programming language books (e.g., Scott’s “Programming Language Pragmatics”) often organize material based on implementation details, e.g., lexical analysis, and scoping rules.
The overview of programming languages given in the first three chapters covers nearly all the basic issues that beginners are taught today, but the emphasis is different (plus typographical differences, such as keyword spelt ‘key word’).
Two major language constructs are missing: Dynamic storage allocation is not discussed: Wirth’s book Algorithms + Data Structures = Programs is seven years in the future, and Kernighan and Ritchie’s The C Programming Language nine years; Simula gets a paragraph, but no mention of the object-oriented concepts it introduced.
What is a programming language, and what are the distinguishing features that make some of them high-level programming languages?
These questions may sound pointless or obvious today, but people used to spend lots of time arguing over what was, or was not, a high-level language.
Sammet says: “… the first characteristic of a programming language is that the user can write a program without knowing much—if anything—about the physical characteristics of the machine on which the program is to be run.”, and goes on to infer: “… a major characteristic of a programming language is that there must be a reasonable potential of having a source program written in that language run on two computers with different machine codes without rewriting the source program. … In most programming languages, some—but often very little—rewriting of the source program is necessary.”
The reason that some rewriting of the source was likely to be needed is that there were often a lot of small variations between compilers for the same language. Compilers tended to be bespoke, i.e., the Fortran compiler for the X cpu running OS Y was written specifically for that combination. Retargetting an existing compiler to a new cpu or OS was much talked about, but it was more fun to write a new compiler (and anyway, support for new features was needed, and it was simpler to start from scratch; page 149 lists differences in Fortran compilers across IBM machines). It didn’t help that there was also a lot of variation in fundamental quantities such as word length, e.g., 16, 18, 20, 24, 32, 36, 40, 48, 60 bit words; see page 18 of Dictionary of Computer Languages.
Sammet makes the distinction: “One of the prime differences between assembly and higher level languages is that to date the latter do not have the capability of modifying themselves at execution time.”
Sammet then goes on to list the advantages and disadvantages of what she calls higher level languages. Most of the claimed advantages will be familiar to readers: “Ease of Learning”, “Ease of Coding and Understanding”, “Ease of Debugging”, and “Ease of Maintaining and Documenting”. The disadvantages included: “Time Required for Compiling” (the issue here is converting assembler source to object code is much faster than compiling a high-level language), “Inefficient Object Code” (the translation process was often a one-to-one mapping of what was written, e.g., little reuse of register contents), “Difficulties in Debugging Without Learning Machine Language” (symbolic debuggers are still in the future).
Sammet’s observation: “In spite of the fact that higher level languages have been with us for over 10 years, there has been relatively little quantitative or qualitative analysis of their advantages and disadvantages.” is still true 50 years later.
If you enjoy learning about lots of different languages, you will like this book. The discussion of specific languages contains copious examples, which for me brought things to life.
Sites such as the Internet Archive and Bitsavers make the book’s references accessible (there are a few I had not seen before), and offer readers a path to pre-Cambrian times.
Saul Rosen’s 1967 book “Programming Systems and Languages” is sometimes cited in discussions of programming language history. This book is a collection of papers that discuss a variety of languages and the operating systems that support them. Fewer languages are covered, but in more depth, along with lots of implementation details. Again, lots of interesting references.
What can be learned from studying long gone development practices?
Current ideas about the best way of building a software system are heavily influenced by the ideas that captured the attention of previous generations of developers. Can anything of practical use be learned from studying long gone techniques for building software systems?
During the writing of my software engineering book, I was spending a lot of time researching the development techniques used during the twentieth century, and one day I suddenly realised that this was a waste of time. While early software developers tend to be eulogized today, the reality is that they were mostly people who had little idea what they were doing, who through personal competence of being in the right place at the right time managed to produce something good enough. On the whole, twentieth century software development techniques are only of historical interest. Yes, some timeless development principles were discovered, and these can be integrated into today’s techniques (which may also turn out to be of their-time).
My experience of software development in the late 1970s and 1980s is that there was rarely any connection between what management told the world about the development process, and how those reporting to the manager actually did the development.
If you are a manager in a world where software development is still very new, and you are given the job of managing the development of a software system, how do you go about it? A common approach is to apply the techniques that are already being used to run the manager’s organization. On a regular basis, managers came up with the idea of applying techniques from the science of industrial production (which is still happening today).
In the 1970s and 1980s there were usually very visible job hierarchies, and sharply defined roles. Organizations tended to use their existing job hierarchies and roles to create the structure for their software development employees. For years after I started work as a graduate, managers and secretaries were surprised to see me typing; secretaries typed, men did not type, and women developers fumed when they were treated like secretaries (because they had been seen typing).
The manual workers performed data entry, operated the computer (e.g., mounted tapes, and looked after the printer). The junior staff often started with the job title programmer, or perhaps junior programmer and there might be senior programmers; on paper these people wrote the code to implement the functionality specified by a systems analyst (or just analyst, or business analyst, perhaps with added junior or senior). Analysts did not to write code and programmers only coded what the specification they were given, at least according to management.
Pay level was set by the position in the job hierarchy, with those higher up earning more than those below them, and job titles/roles were also mapped to positions in the hierarchy. This created, in theory, a direct correspondence between pay and job title/role. In practice, organizations wanted to keep their productive employees, and so were flexible about the correspondence between pay and title, e.g., during their annual review some people were more interested in the status provided by a job title, while others wanted more money and did not care about job titles. Add into this mix the fact that pay/title levels rarely matched up between organizations, it soon became obvious to all that software job titles were a charade.
How should the people at the sharp end go about building a software system?
Structured programming was the widely cited technique in the 1970s. Consultants promoted their own variants, with Jackson structured programming being widely known in the UK, with regular courses and consultants offering to train staff. Today, structured programming appears remarkably simplistic, great for writing tiny programs (it has an academic pedigree), but not for anything larger than a thousand lines. Part of its appeal may have been this simplicity, many programs were small (because computer memory was measured in kilobytes) and management often thought that problems were simple (a recurring problem). There were a few adaptations that tried to address larger scale issues, e.g., Warnier/Orr structured programming.
The military were major employers of software developers in the 1960s and 1970s. In the US Work Breakdown Structure was mandated by the DOD for project development (for all projects, not just software), and in the UK we had MASCOT. These mandated development methodologies were created by committees, and have not been experimentally tested to be better/worse than any other approach.
I think the best management technique for successfully developing a software system in the 1970s and 1980s (and perhaps in the following decades), is based on being lucky enough to have a few very capable people, and then providing them with what is needed to get the job done while maintaining the fiction to upper management that the agreed bureaucratic plan is being followed.
There is one technique for producing a software system that rarely gets mentioned: keep paying for development until something good enough is delivered. Given the life-or-death need an organization might have for some software systems, paying what it takes may well have been a prevalent methodology during the early days of major software development.
To answer the question posed at the start of this post. What might be learned from a study of early software development techniques is the need for management to have lots of luck and to be flexible; funding is easier to obtain when managing a life-or-death project.
Widely used programming languages: past, present, and future
Programming languages are like pop groups in that they have followers, fans and supporters; new ones are constantly being created and some eventually become widely popular, while those that were once popular slowly fade away or mutate into something else.
Creating a language is a relatively popular activity. Science fiction and fantasy authors have been doing it since before computers existed, e.g., the Elf language Quenya devised by Tolkien, and in the computer age Star Trek’s Klingon. Some very good how-to books have been written on the subject.
As soon as computers became available, people started inventing programming languages.
What have been the major factors influencing the growth to widespread use of a new programming languages (I’m ignoring languages that become widespread within application niches)?
Cobol and Fortran became widely used because there was widespread implementation support for them across computer manufacturers, and they did not have to compete with any existing widely used languages. Various niches had one or more languages that were widely used in that niche, e.g., Algol 60 in academia.
To become widely used during the mainframe/minicomputer age, a new language first had to be ported to the major computers of the day, whose products sometimes supported multiple, incompatible operating systems. No new languages became widely used, in the sense of across computer vendors. Some new languages were widely used by developers, because they were available on IBM computers; for several decades a large percentage of developers used IBM computers. Based on job adverts, RPG was widely used, but PL/1 not so. The use of RPG declined with the decline of IBM.
The introduction of microcomputers (originally 8-bit, then 16, then 32, and finally 64-bit) opened up an opportunity for new languages to become widely used in that niche (which would eventually grow to be the primary computing platform of its day). This opportunity occurred because compiler vendors for the major languages of the day did not want to cannibalize their existing market (i.e., selling compilers for a lot more than the price of a microcomputer) by selling a much lower priced product on microcomputers.
BASIC became available on practically all microcomputers, or rather some dialect of BASIC that was incompatible with all the other dialects. The availability of BASIC on a vendor’s computer promoted sales of the hardware, and it was not worthwhile for the major vendors to create a version of BASIC that reduced portability costs; the profit was in games.
The dominance of the Microsoft/Intel partnership removed the high cost of porting to lots of platforms (by driving them out of business), but created a major new obstacle to the wide adoption of new languages: Developer choice. There had always been lots of new languages floating around, but people only got to see the subset that were available on the particular hardware they targeted. Once the cpu/OS (essentially) became a monoculture most new languages had to compete for developer attention in one ecosystem.
Pascal was in widespread use for a few years on micros (in the form of Turbo Pascal) and university computers (the source of Wirth’s ETH compiler was freely available for porting), but eventually C won developer mindshare and became the most widely used language. In the early 1990s C++ compiler sales took off, but many developers were writing C with a few C++ constructs scattered about the code (e.g., use of new, rather than malloc/free).
Next, the Internet took off, and opened up an opportunity for new languages to become dominant. This opportunity occurred because Internet related software was being made freely available, and established compiler vendors were not interested in making their products freely available.
There were people willing to invest in creating a good-enough implementation of the language they had invented, and giving it away for free. Luck, plus being in the right place at the right time resulted in PHP and Javascript becoming widely used. Network effects prevent any other language becoming widely used. Compatible dialects of PHP and Javascript may migrate widespread usage to quite different languages over time, e.g., Facebook’s Hack.
Java rode to popularity on the coat-tails of the Internet, and when it looked like security issues would reduce it to niche status, it became the vendor supported language for one of the major smart-phone OSs.
Next, smart-phones took off, but the availability of Open Source compilers closed the opportunity window for new languages to become dominant through lack of interest from existing compiler vendors. Smart-phone vendors wanted to quickly attract developers, which meant throwing their weight behind a language that many developers were already familiar with; Apple went with Objective-C (which evolved to Swift), Google with Java (which evolved to Kotlin, because of the Oracle lawsuit).
Where does Python fit in this grand scheme? I don’t yet have an answer, or is my world-view wrong to treat Python usage as being as widespread as C/C++/Java?
New programming languages continue to be implemented; I don’t see this ever stopping. Most don’t attract more users than their implementer, but a few become fashionable amongst the young, who are always looking to attach themselves to something new and shiny.
Will a new programming language ever again become widely used?
Like human languages, programming languages experience strong networking effects. Widely used languages continue to be widely used because many companies depend on code written in it, and many developers who can use it can obtain jobs; what company wants to risk using a new language only to find they cannot hire staff who know it, and there are not many people willing to invest in becoming fluent in a language with no immediate job prospects.
Today’s widely used programmings languages succeeded in a niche that eventually grew larger than all the other computing ecosystems. The Internet and smart-phones are used by everybody on the planet, there are no bigger ecosystems to provide new languages with a possible route to widespread use. To be widely used a language first has to become fashionable, but from now on, new programming languages that don’t evolve from (i.e., be compatible with) current widely used languages are very unlikely to migrate from fashionable to widely used.
It has always been possible for a proficient developer to dedicate a year+ of effort to create a new language implementation. Adding the polish need to make it production ready used to take much longer, but these days tool chains such as LLVM supply a lot of the heavy lifting. The problem for almost all language creators/implementers is community building; they are terrible at dealing with other developers.
It’s no surprise that nearly all the new languages that become fashionable originate with language creators who work for a company that happens to feel a need for a new language. Examples include:
- Go created by Google for internal use, and attracted an outside fan base. Company languages are not new, with IBM’s PL/1 being the poster child (or is there a more modern poster child). At the moment Go is a trendy language, and this feeds a supply of young developers willing to invest in learning it. Once the trendiness wears off, Google will start to have problems recruiting developers, the reason: Being labelled as a Go developer limits job prospects when few other companies use the language. Talk to a manager who has tried to recruit developers to work on applications written in Fortran, Pascal and other once-widely used languages (and even wannabe widely used languages, such as Ada),
- Rust a vanity project from Mozilla, which they have now
abandonedcast adrift. Did Rust become fashionable because it arrived at the right time to become the not-Google language? I await a PhD thesis on the topic of the rise and fall of Rust, - Microsoft’s C# ceased being trendy some years ago. These days I don’t have much contact with developers working in the Microsoft ecosystem, so I don’t know anything about the state of the C# job market.
Every now and again a language creator has the social skills needed to start an active community. Zig caught my attention when I read that its creator, Andrew Kelley, had quit his job to work full-time on Zig. Two and a-half years later Zig has its own track at FOSEM’21.
Will Zig become the next fashionable language, as Rust/Go popularity fades? I’m rooting for Zig because of its name, there are relatively few languages whose name starts with Z; the start of the alphabet is over-represented with language names. It would be foolish to root for a language because of a belief that it has magical properties (e.g., powerful, readable, maintainable), but the young are foolish.
Learning useful stuff from the Ecosystems chapter of my book
What useful, practical things might professional software developers learn from the Ecosystems chapter in my evidence-based software engineering book?
This week I checked the ecosystems chapter; what useful things did I learn (combined with everything I learned during all the other weeks spent working on this chapter)?
A casual reader would conclude that software engineering ecosystems involved lots of topics, with little or no theory connecting them. I had great plans for the connecting theories, but lack of detailed data, time and inspiration means the plans remain in my head (e.g., modelling the interaction between the growth of source code written in a particular language and the number of developers actively using that language).
For managers, the usefulness of this chapter is the strategic perspective it provides. How does what they and others are doing relate to everything else, and what patterns of evolution are to be expected?
Software people like to think that everything about software is unique. Software is unique, but the activities around it follow patterns that have been followed by other unique technologies, e.g., the automobile and jet engines. There is useful stuff to be learned from non-software ecosystems, and the chapter discusses some similarities I have learned about.
There is lots more evidence of the finite lifetime of software related items: lifetime of products, Linux distributions, packages, APIs and software careers.
Some readers might be surprised by the amount of discussion about what is now historical hardware. Software needs hardware to execute it, and the characteristics of the hardware of the day can have a significant impact on the characteristics of the software that gets written. I suspect that most of this discussion will not be that useful to most readers, but it provides some context around why things are the way they are today.
Readers with a wide knowledge of software ecosystems will notice that several major ecosystems barely get a mention. Embedded systems is a huge market, as is Microsoft Windows, and very many professional developers use C++. However, to date the focus of most research has been around Linux and Android (because its use of Java, a language often taught in academia), and languages that have a major package repository. So the ecosystems chapter presents a rather blinkered view of software engineering ecosystems.
What did I learn from this chapter?
Software ecosystems are bigger and more complicated that I had originally thought.
Readers might have a completely different learning experience from reading the ecosystems chapter. What useful things did you learn from the ecosystems chapter?
Happy 60th birthday: Algol 60
Report on the Algorithmic Language ALGOL 60 is the title of a 16-page paper appearing in the May 1960 issue of the Communication of the ACM. Probably one of the most influential programming languages, and a language that readers may never have heard of.
During the 1960s there were three well known, widely used, programming languages: Algol 60, Cobol, and Fortran.
When somebody created a new programming languages Algol 60 tended to be their role-model. A few of the authors of the Algol 60 report cited beauty as one of their aims, a romantic notion that captured some users imaginations. Also, the language was full of quirky, out-there, features; plenty of scope for pin-head discussions.
Cobol appears visually clunky, is used by business people and focuses on data formatting (a deadly dull, but very important issue).
Fortran spent 20 years catching up with features supported by Algol 60.
Cobol and Fortran are still with us because they never had any serious competition within their target markets.
Algol 60 had lots of competition and its successor language, Algol 68, was groundbreaking within its academic niche, i.e., not in a developer useful way.
Language family trees ought to have Algol 60 at, or close to their root. But the Algol 60 descendants have been so successful, that the creators of these family trees have rarely heard of it.
In the US the ‘military’ language was Jovial, and in the UK it was Coral 66, both derived from Algol 60 (Coral 66 was the first language I used in industry after graduating). I used to hear people saying that Jovial was derived from Fortran; another example of people citing the language the popular language know.
Algol compiler implementers documented their techniques (probably because they were often academics); ALGOL 60 Implementation is a real gem of a book, and still worth a read today (as an introduction to compiling).
Algol 60 was ahead of its time in supporting undefined behaviors 😉 Such as: “The effect, of a go to statement, outside a for statement, which refers to a label within the for statement, is undefined.”
One feature of Algol 60 rarely adopted by other languages is its parameter passing mechanism, call-by-name (now that lambda expressions are starting to appear in widely used languages, call-by-name has a kind-of comeback). Call-by-name essentially has the same effect as textual substitution. Given the following procedure (it’s not a function because it does not return a value):
procedure swap (a, b); integer a, b, temp; begin temp := a; a := b; b:= temp end; |
the effect of the call: swap(i, x[i]) is:
temp := i; i := x[i]; x[i] := temp |
which might come as a surprise to some.
Needless to say, programmers came up with ‘clever’ ways of exploiting this behavior; the most famous being Jensen’s device.
The follow example of go to usage appears in: International Standard 1538 Programming languages – ALGOL 60 (the first and only edition appeared in 1984, after most people had stopped using the language):
go to if Ab < c then L17 else g[if w < 0 then 2 else n] |
Orthogonality of language use won out over the goto FUD.
The Software Preservation Group is a great resource for Algol 60 books and papers.
Ecosystems as major drivers of software development
During the age of the Algorithm, developers wrote most of the code in their programs. In the age of the Ecosystem, developers make extensive use of code supplied by third-parties.
Software ecosystems are one of the primary drivers of software development.
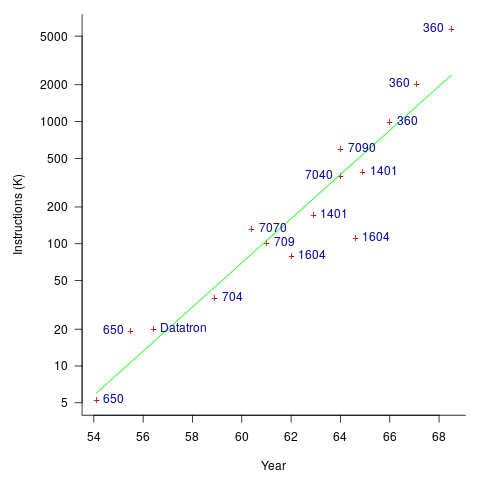
The early computers were essentially sold as bare metal, with the customer having to write all the software. Having to write all the software was expensive, time-consuming, and created a barrier to more companies using computers (i.e., it was limiting sales). The amount of software that came bundled with a new computer grew over time; the following plot (code+data) shows the amount of code (thousands of instructions) bundled with various IBM computers up to 1968 (an antitrust case eventually prevented IBM bundling software with its computers):
Some tasks performed using computers are common to many computer users, and users soon started to meet together, to share experiences and software. SHARE, founded in 1955, was the first computer user group.
SHARE was one of several nascent ecosystems that formed at the start of the software age, another is the Association for Computing Machinery; a great source of information about the ecosystems existing at the time is COMPUTERS and AUTOMATION.
Until the introduction of the IBM System/360, manufacturers introduced new ranges of computers that were incompatible with their previous range, i.e., existing software did not work.
Compatibility with existing code became a major issue. What had gone before started to have a strong influence on what was commercially viable to do next. Software cultures had come into being and distinct ecosystems were springing up.
A platform is an ecosystem which is primarily controlled by one vendor; Microsoft Windows is the poster child for software ecosystems. Over the years, Microsoft has added more and more functionality to Windows, and I don’t know enough to suggest the date when substantial Windows programs substantially depended on third-party code; certainly small apps may be mostly Windows code. The Windows GUI certainly ties developers very closely to a Windows way of doing things (I have had many people tell me that porting to a non-Windows GUI was a lot of work, but then this statement seems to be generally true of porting between different GUIs).
Does Facebook’s support for the writing of simple apps make it a platform? Bill Gates thought not: “A platform is when the economic value of everybody that uses it, exceeds the value of the company that creates it.”, which some have called the Gates line.
The rise of open source has made it viable for substantial language ecosystems to flower, or rather substantial package ecosystems, with each based around a particular language. For practical purposes, language choice is now about the quality and quantity of their ecosystem. The dedicated followers of fashion like to tell everybody about the wonders of Go or Rust (in fashion when I wrote this post), but without a substantial package ecosystem, no language stands a chance of being widely used over the long term.
Major new software ecosystems have been created on a regular basis (regular, as in several per decade), e.g., mainframes in the 1960s, minicomputers and workstation in the 1970s, microcomputers in the 1980s, the Internet in the 1990s, smartphones in the 2000s, the cloud in the 2010s.
Will a major new software ecosystem come into being in the future? Major software ecosystems tend to be hardware driven; is hardware development now basically done, or should we expect something major to come along? A major hardware change requires a major new market to conquer. The smartphone has conquered a large percentage of the world’s population; there is no larger market left to conquer. Now, it’s about filling in the gaps, i.e., lots of niche markets that are still waiting to be exploited.
Software ecosystems are created through lots of people working together, over many years, e.g., the huge number of quality Python packages. Perhaps somebody will emerge who has the skills and charisma needed to get many developers to build a new ecosystem.
Software ecosystems can disappear; I think this may be happening with Perl.
Can a date be put on the start of the age of the Ecosystem? Ideas for defining the start of the age of the Ecosystem include:
- requiring a huge effort to port programs from one ecosystem to another. It used to be very difficult to port between ecosystems because they were so different (it has always been in vendors’ interests to support unique functionality). Using this method gives an early start date,
- by the amount of code/functionality in a program derived from third-party packages. In 2018, it’s certainly possible to write a relatively short Python program containing a huge amount of functionality, all thanks to third-party packages. Was this true for any ecosystems in the 1980s, 1990s?
Experimental Psychology by Robert S. Woodworth
I have just discovered “Experimental Psychology” by Robert S. Woodworth; first published in 1938, I have a reprinted in Great Britain copy from 1951. The Internet Archive has a copy of the 1954 revised edition; it’s a very useful pdf, but it does not have the atmospheric musty smell of an old book.
The Archives of Psychology was edited by Woodworth and contain reports of what look like ground breaking studies done in the 1930s.
The book is surprisingly modern, in that the topics covered are all of active interest today, in fields related to cognitive psychology. There are lots of experimental results (which always biases me towards really liking a book) and the coverage is extensive.
The history of cognitive psychology, as I understood it until this week, was early researchers asking questions, doing introspection and sometimes running experiments in the late 1800s and early 1900s (e.g., Wundt and Ebbinghaus), behaviorism dominants the field, behaviorism is eviscerated by Chomsky in the 1960s and cognitive psychology as we know it today takes off.
Now I know that lots of interesting and relevant experiments were being done in the 1920s and 1930s.
What is missing from this book? The most obvious omission is equations; lots of data points plotted on graph paper, but no attempt to fit an equation to anything, e.g., an exponential curve to the rate of learning.
A more subtle omission is the world view; digital computers had not been invented yet and Shannon’s information theory was almost 20 years in the future. Researchers tend to be heavily influenced by the tools they use and the zeitgeist. Computers as calculators and information processors could not be used as the basis for models of the human mind; they had not been invented yet.
Recent Comments