Archive
Good enough reliability models: still an unknown
Estimating the likelihood that a software system will operate as intended, for some period of time, is one of the big problems within the field of software reliability research. When software does not operate as intended, a fault, or bug, or hallucination is said to have occurred.
Three events need to occur for a user of a software system to experience a fault:
- a developer writes code that does not always behave as intended, i.e., a coding mistake,
- the user of the software feeds it input that causes the coding mistake to produce unintended behavior,
- the unintended behavior percolates through the system to produce a visible fault (sometimes an unintended behavior does not percolate very far, and does not produce any change of visible behavior).
Modelling each kind of event and their interaction is a huge undertaking. Researchers in one of the major subfields of software reliability take a global approach, e.g., they model time to next fault experience, using data on the number of faults experienced per given amount of cpu/elapsed time (often obtained during testing). Modelling the fault data obtained during testing results in a model of the likelihood of the next fault experienced using that particular test process. This is useful for doing a return-on-investment calculation to decide whether to do more testing. If the distribution of inputs used during testing is similar to the distribution of customer inputs, then the model can be of use in estimating the rate of customer fault experiences.
Is it possible to use a model whose design was driven by data from testing one or more software systems to estimate the rate of fault experiences likely when testing other software systems?
The number of coding mistakes will differ between systems (because they have different sizes, and/or different developer abilities), and the testers’ ability will be different, and the extent to which mistaken behavior percolates through code will differ. However, it is possible for there to be a general model for rate of fault experiences that contains various parameters that need to be fitted for each situation.
Since that start of the 1970s, researchers have been searching for this general model (the first software reliability model is thought to be: “Program errors as a birth-and-death process” by G. R. Hudson, Report SP-3011, System Development Corp., 1967 Dec 4; please send me a copy, if you have one).
The image below shows the 18 models discussed in the 1987 book “Software Reliability: Measurement, Prediction, Application” by Musa, Iannino, and Okumoto (later editions have seriously watered down the technical contents, and lack most of the tables/plots). It’s to be expected that during the early years of a new field, many different models will be proposed and discussed.
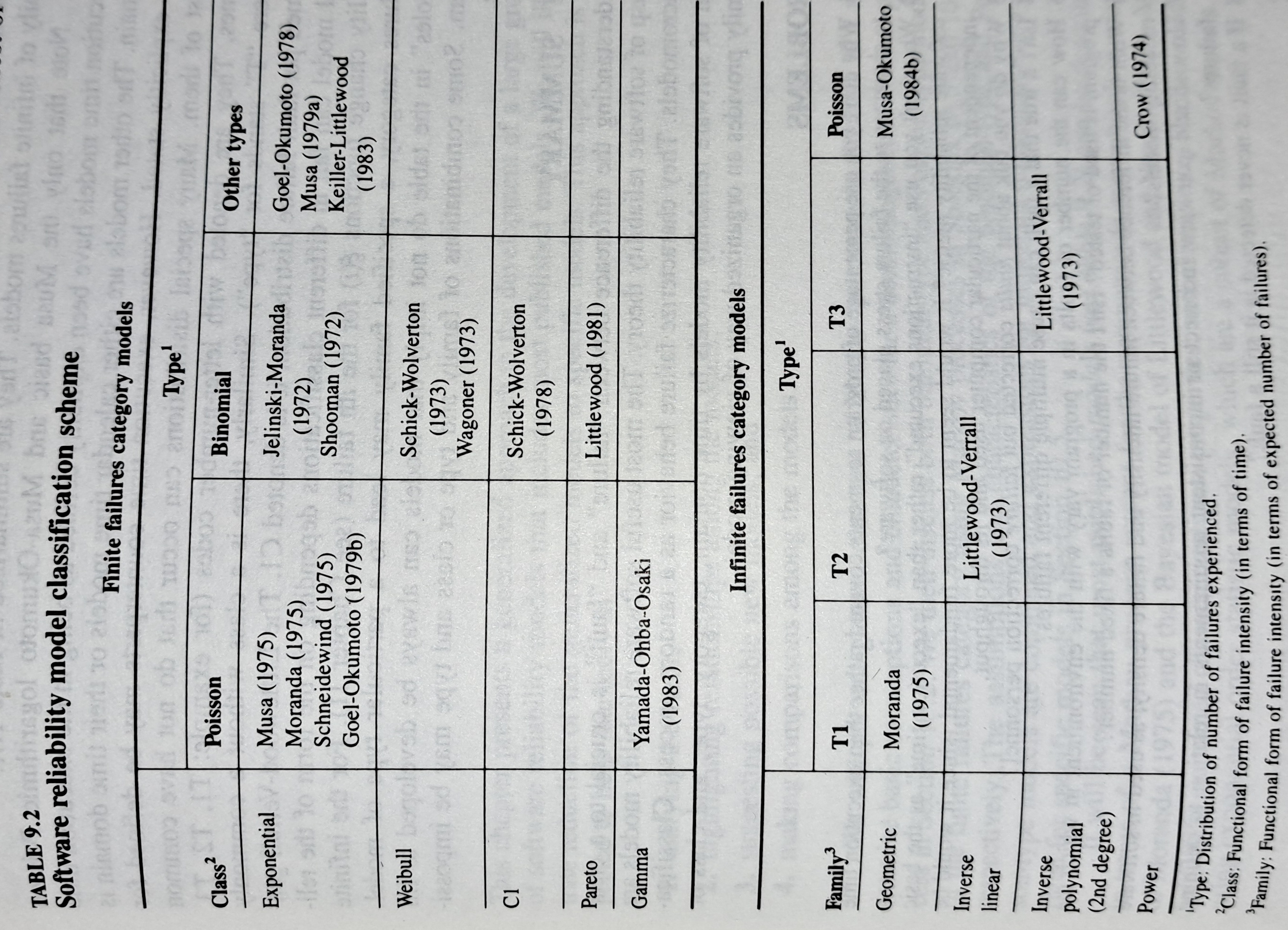
Did researchers discover a good-enough general model for rate of fault experiences?
It’s hard to say. There is not enough reliability data to be confident that any of the umpteen proposed models is consistently better at predicting than any other. I believe that the evidence-based state of the art has not yet progressed beyond the 1982 report Software Reliability: Repetitive Run Experimentation and Modeling by Nagel and Skrivan.
Fitting slightly modified versions of existing models to a small number of tiny datasets has become standard practice in this corner of software engineering research (the same pattern of behavior has occurred in software effort estimation). The image below shows 16 models from a 2021 paper.
Nearly all the reliability data used to create these models is from systems built in the 1960s and 1970s. During these decades, software systems were paid for organizations that appreciated the benefits of collecting data to build models, and funding the necessary research. My experience is that few academics make an effort to talk to people in industry, which means they are unlikely to acquire new datasets. But then researchers are judged by papers published, and the ecosystem they work within is willing to publish papers extolling the virtues of another variant of an existing model.

The various software fault datasets used to create reliability models tends to be scattered in sometimes hard to find papers (yes, it is small enough to be printed in papers). I have finally gotten around to organizing all the public data that I have in one place, a Reliability data repo on GitHub.
If you have a public fault dataset that does not appear in this repo, please send me a copy.
The units of measurement for software reliability
How do the people define software reliability? One answer can be found by analyzing defect report logs: one study found that 42.6% of fault reports were requests for an enhancement, changes to documentation, or a refactoring request; a study of NASA spaceflight software found that 63% of reports in the defect tracking system were change requests.
Users can be thought of as broadly defining software reliability as the ability to support current (i.e., the software works as intended) and future needs (i.e., functionality that the user does not yet know they need, e.g., one reason I use R, rather than Python, for data analysis, is because I believe that if a new-to-me technique is required, a package+documentation supporting this technique is more likely to be available in R).
Focusing on current needs, the definition of software reliability depends on the perspective of who you ask, possibilities include:
- commercial management: software reliability is measured in terms of cost-risk, i.e., the likelihood of losing an amount £/$ as a result of undesirable application behavior (either losses from internal use, or customer related losses such as refunds, hot-line support, and good will),
- Open source: reliability has to be good enough and at least as good as comparable projects. The unit of reliability might be fault experiences per use of the program, or the number of undesirable behaviors encountered when processing pre-existing material,
- user-centric: mean time between failure per uses of the application, e.g., for a word processor, documents written/edited. For compilers, mean time between failure per million lines of source translated,
- academic and perhaps a generic development team: mean time between failure per million lines/instructions executed by the application. The definition avoids having to deal with how the software is used,
- available data: numeric answers require measurement data to feed into a calculation. Data that is relatively easy to collect is cpu time consumed by tests that found some number of faults, or perhaps wall time, or scraping the bottom of the barrel the number of tests run.
If an organization wants to increase software reliability, they can pay to make the changes that increase reliability. Pointing this fact out to people can make them very annoyed.
Natural elimination, or the survival of the good enough
Thanks to Darwin, the world is full of people who think that evolution, in nature, works by: natural selection, or the survival of the fittest. I thought this until I read “Good Enough: The Tolerance for Mediocrity in Nature and Society” by Daniel Milo.
Milo makes a very convincing case that nature actually works by: natural elimination, or the survival of the good enough.
Why might Darwin have gone with natural selection in his book, On the Origin of Species? Milo makes the point that the only real evidence that Darwin had to work with was artificial selection, that is the breeding of farm animals and domestic pets to select for traits that humans found desirable. Darwin’s visit to the Galápagos islands triggered a way of thinking, it did not provide him with the evidence he needed; Darwin’s Finches have become a commonly cited example of natural selection at work, but while Darwin made the observations it was not until 80 years later that somebody else spotted their relevance.
The Origin of Species, or to use its full title: “On the Origin of Species by means of natural selection, or the preservation of favored races in the struggle for life.” is full of examples and terminology relating to artificial selection.
Natural selection, or natural elimination, isn’t the result the same?
Natural selection implies an optimization process, e.g., breeders selecting for a strain of cows that produce the most milk.
Natural elimination is a good enough process, i.e., a creature needs a collection of traits that are good enough for them to create the next generation.
A long-standing problem with natural selection is that it fails to explain the diversity present in a natural population of some breed of animal (there is very little diversity in each breed of farm animal, they have been optimized for consistency). Diversity is not a problem for natural elimination, which does not reduce differences in its search for fitness.
The diversity produced as a consequence of natural elimination creates a population containing many neutral traits (i.e., characteristics that have no positive or negative impact on continuing survival). When a significant change in the environment occurs, one or more of the neutral traits may suddenly have positive or negative survival consequences; the creatures with the positive traits have opportunity time to adapt to the changed environment. A population whose members possess a diverse range of neutral traits has a higher chance of long-term survival than a population where diversity has been squeezed in the quest for the fittest.
I think that natural elimination also applies within software ecosystems. Commercial products survive if enough customers buy them, software developers need good enough know-how to get the job done.
I’m sure customers would prefer software ecosystems to operate on the principle of survival of the fittest (it reduces their costs). Over the long term is society best served by diverse software ecosystems or softwaremonocultures? Diversity is a way of encouraging competition, but over time there is diminishing returns on the improvements.
Recent Comments