Archive
Compiler validation is now part of history
Compiler validation makes sense in a world where there are many different hardware platforms, each with their own independent compilers (third parties often implemented compilers for popular platforms, competing against the hardware vendor). A large organization that spends hundreds of millions on a multitude of computer systems (e.g., the U.S. government) wants to keep prices down, which means the cost of porting its software to different platforms needs to be kept down (or at least suppliers need to think it will not cost too much to switch hardware).
A crucial requirement for source code portability is that different compilers be able to compile the same source, generating code that produces the same behavior. The same behavior requirement is an issue when the underlying word-size varies or has different alignment requirements (lots of code relies on data structures following particular patterns of behavior), but management on all sides always seems to think that being able to compile the source is enough. Compilers vendors often supported extensions to the language standard, and developers got to learn they were extensions when porting to a different compiler.
The U.S. government funded a conformance testing service, and paid for compiler validation suites to be written (source code for what were once the Cobol 85, Fortran 78 and SQL validation suites). While it was in business, this conformance testing service was involved C compiler validation, but it did not have to fund any development because commercial test suites were available.
The 1990s was the mass-extinction decade for companies selling non-Intel hardware. The widespread use of Open source compilers, coupled with the disappearance of lots of different cpus (porting compilers to new vendor cpus was always a good money spinner, for the compiler writing cottage industry), meant that many compilers disappeared from the market.
These days, language portability issues have been essentially solved by a near monoculture of compilers and cpus. It’s the libraries that are the primary cause of application portability problems. There is a test suite for POSIX and Linux has its own tests.
There are companies selling compiler C/C++ test suites (e.g., Perennial and PlumHall); when maintaining a compiler, it’s cost-effective to have a set of third-party tests designed to exercise all the language.
The OpenGroup offer to test your C compiler and issue a brand certificate if it passes the tests.
Source code portability requires compilers to have the same behavior and traditionally the generally accepted behavior has been defined by an ISO Standard or how one particular implementation behaved. In an Open source world, behavior is defined by what needs to be done to run the majority of existing code. Does it matter if Open source compilers evolve in a direction that is different from the behavior specified in an ISO Standard? I think not, it makes no difference to the majority of developers; but be careful, saying this can quickly generate a major storm in a tiny teacup.
2017 in the programming language standards’ world
Yesterday I was at the British Standards Institution for a meeting of IST/5, the committee responsible for programming languages.
The amount of management control over those wanting to get to the meeting room, from outside the building, has increased. There is now a sensor activated sliding door between the car-park and side-walk from the rear of the building to the front, and there are now two receptions; the ground floor reception gets visitors a pass to the first floor, where a pass to the fifth floor is obtained from another reception (I was totally confused by being told to go to the first floor, which housed the canteen last time I was there, and still does, the second reception is perched just inside the automatic barriers to the canteen {these barriers are also new; the food is reasonable, but not free}).
Visitors are supposed to show proof that they are attending a meeting, such as a meeting calling notice or an agenda. I have always managed to look sufficiently important/knowledgeable/harmless to get in without showing any such documents. I was asked to show them this time, perhaps my image is slipping, but my obvious bafflement at the new setup rescued me.
Why does BSI do this? My theory is that it’s all about image, BSI is the UK’s standard setting body and as such has to be seen to follow these standards. There is probably some security standard for rules to follow to prevent people sneaking into buildings. It could be argued that the name British Standards is enough to put anybody off wanting to enter the building in the first place, but this does not sound like a good rationale for BSI to give. Instead, we have lots of sliding doors/gates, multiple receptions (I suspect this has more to do with a building management cat fight over reception costs), lifts with no buttons ‘inside’ for selecting floors, and proof of reasons to be in the building.
There are also new chairs in the open spaces. The chairs have very high backs and side-baffles that surround the head area, excellent for having secret conversations and in-tune with all the security. These open areas are an image of what people in the 1970s thought the future would look like (BSI is a traditional organization after all).
So what happened in the meeting?
Cobol standard’s work becomes even more dead. PL22.4, the US Cobol group is no more (there were insufficient people willing to pay membership fees, so the group was closed down).
People are continuing to work on Fortran (still the language of choice for supercomputer Apps), Ada (some new people have started attending meetings and support for @ is still being fought over), C, Internationalization (all about character sets these days). Unprompted somebody pointed out that the UK C++ panel seemed to be attracting lots of people from the financial industry (I was very professional and did not relay my theory that it’s all about bored consultants wanting an outlet for their creative urges).
SC22, the ISO committee responsible for programming languages, is meeting at BSI next month, and our chairman asked if any of us planned to attend. The chair’s response, to my request to sell the meeting to us, was that his vocabulary was not up to the task; a two-day management meeting (no technical discussions permitted at this level) on programming languages is that exciting (and they are setting up a special reception so that visitors don’t have to go to the first floor to get a pass to attend a meeting on the ground floor).
Fortran 2008 Standard has been updated
An updated version of ISO/IEC 1539-1 Information technology — Programming languages — Fortran — Part 1: Base language has just been published. So what has JTC1/SC22/WG5 been up to?
This latest document is bug a release of the 2010 standard, known as Fortran 2008 (because the ANSI Standard from which the ISO Standard was derived, sed -e "s/ANSI/ISO/g" -e "s/National/International/g", was published in 2008) and incorporates all the published corrigenda. I must have been busy in 2008, because I did not look to see what had changed.
Actually the document I am looking at is the British Standard. BSI don’t bother with sed, they just glue a BSI Standards Publication page on the front and add BS to the name, i.e., BS ISO/IEC 1539-1:2010.
The interesting stuff is in Annex B, “Deleted and obsolescent features” (the new features are Fortranized versions of languages features you have probable seen elsewhere).
Programming language committees are known for issuing dire warnings that various language features are obsolescent and likely to be removed in a future revision of the standard, but actually removing anything is another matter.
Well, the Fortran committee have gone and deleted six features! Why wasn’t this on the news? Did the committee foresee the 2008 financial crisis and decide to sneak out the deletions while people were looking elsewhere?
What constructs cannot now appear in conforming Fortran programs?
- “Real and double precision DO variables. .. A similar result can be achieved by using a DO construct with no loop control and the appropriate exit test.”
What other languages call a for-loop, Fortran calls a DO loop. So loop control variables can no longer have a floating-point type.
- “Branching to an END IF statement from outside its block.”
An if-statement is terminated by the token sequence
END IF, which may have an optional label. It is no longer possible toGOTOthat label from outside the block of the if-statement. You are going to have to label the statement after it. - “PAUSE statement.”
This statement dates from the days when a computer (singular, not plural) had its own air-conditioned room and a team of operators to tend its every need. A
PAUSEstatement would cause a message to appear on the operators’ console and somebody would be dispatched to check the printer was switched on and had paper, or some such thing, and they would then resume execution of the paused program.I think WG5 has not seen the future here. Isn’t the
PAUSEstatement needed again for cloud computing? I’m sure that Amazon would be happy to quote a price for having an operator respond to aPAUSEstatement. - “ASSIGN and assigned GO TO statements and assigned format specifiers.”
No more assigning labels to variables and GOTOing them, as a means of leaping around 1,000 line functions. This modern programming practice stuff is a real killjoy.
- “H edit descriptor.”
First programmers stopped using punched cards and now the H edit descriptor have been removed from Fortran; Herman Hollerith no longer touches the life of working programmers.
In the good old days real programmers wrote
11HHello World. Using quote delimiters for string literals is for pansies. - “Vertical format control. … There was no standard way to detect whether output to a unit resulted in this vertical format control, and no way to specify that it should be applied; this has been deleted. The effect can be achieved by post-processing a formatted file.”
Don’t panic, C still supports the
\vescape sequence.
Fortran & Cobol in the USAF over the years 1955-1986
I recently discovered a new dataset from Rome’s golden age, going back to 1955. Who knew that in 1955 the US Air Force took delivery of 133,075 lines of Cobol? The plot below shows lines of code against year, broken down by major languages used.
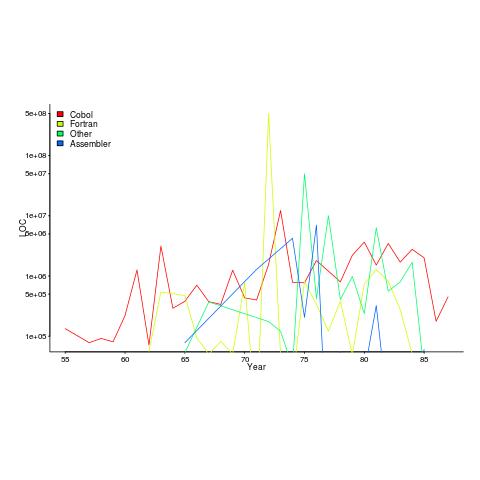
I got the data from the Master’s thesis of Captain NeSmith II (there is probably more software engineering data to be found in US Air Force officers’ Master’s thesis than all published academic papers before 2005). Captain NeSmith got his data from the Information Systems Designator (ISD) database maintained by the Standard Information Systems Center (SISC); the data does not include classified project and embedded systems. This database contained more data than appeared in the thesis, but I cannot find it anywhere.
Given the spiky nature of the data I’m guessing that LOC and development costs are counted in the year a project is delivered. Maintenance costs are through to financial year 1984.
The big question that jumps out of the data is “What project delivered 0.5 billion lines of Fortran in 1972?”
The LOC for Assemble suspiciously does not occur before 1965.
In the 1980s people were always talking about the billion+ lines of Cobol in use by the US Government. Over the 31 year span of this USAF data, 46 million lines of Cobol were delivered at a cost of $0.5 billion. Did another 50 arms of the government produce similar amounts of Cobol? Is the USAF under/over representative of Cobol?
The plot below shows yearly LOC against development cost, plus fitted regression lines.
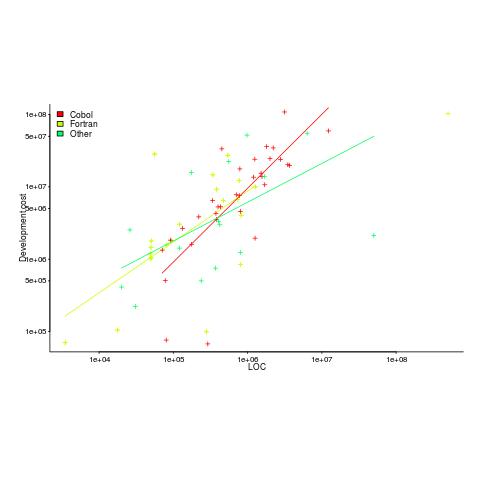
Using development cost as a proxy for effort, the coefficients of the fitted lines were close to those I fitted to Boehm’s embedded data (i.e., the exponents were lower than those listed by Boehm); Fortran 0.7, Cobol 1 and Other 0.5 (the huge Fortran outlier was excluded).
Adding Year to the regression model shows than Fortran development cost decreased by around 8% per year. Cobol may have been around 1% per year, depending on which model is chosen.
The maintenance costs can be plotted, but there is just too much uncertainty about them to say anything sensible (was inflation taken into account, how heavily used were the programs {more usage find more faults and demand for more features}, etc.).
NeSmith’s thesis contains a lot more data. The reproduction quality is not great, so the numbers have to be typed in. If you find any bugs in my data+code, please let me know and if you type in any of the other tables I would love a copy.
Actively maintained production compilers for middle-age languages
The owners of the Borland C++ compiler have stopped maintaining it. So we are now down to, by my counting, three four different production quality C++ compilers still being actively maintained (Visual C++ {the command line c1.exe, not the interactive IDE compiler}, GCC, LLVM and EDG); lots of companies repackage EDG and don’t talk about it.
How many production compilers for other middle-age languages are still being actively maintained?
Ada I think is now down to one (GNAT; I’m not sure of the status of what was the Intermetrics compiler).
Cobol has two+ (I’m not sure how many internal compilers IBM has, some of which are really Microfocus) that I know of (Microfocus and Fujitsu {was ACUCobol}).
Fortran probably needs more than one hand to count its compilers. Nothing like having large engineering applications using the languages features supported by your compiler to keep the maintenance fees rolling in.
C still has lots of compilers (a C validation suite vendor told me many years ago that they had over 150 customers). Embedded processors can be a very tough target for the general purpose algorithms used in GCC and LLVM, so vendors with hand crafted compilers can still eek out a living.
Perl has one (which I find surprising).
R has one, but like Cobol it is not a fashionable language in compiler writing circles. Over the last couple of years there have been a few ‘play’ implementations and rumors of people creating a new production quality implementation.
Lisp has one or millions, depending on how you view dialects or there could be a million people with a different view on the identity of the 1.
Snobol-4 still has one (yes, I am a fan of this language).
There are lots of languages which have not yet reached middle-age, so its too soon to start counting how many actively supported compilers they still have in production use.
2015 in the programming language standard’s world
Last Tuesday I was at the British Standards Institute for a meeting of IST/5, the programming languages committee.
My suggestion that the Cobol 2014 standard may be the last revision of that language appears to be coming true; there has been a steep decline in membership of the US Cobol committee (this is where all the work is done, with the rest of the world joining this committee or rubber stamping what comes out of it), and nobody has expressed interest in being involved in new work items.
Fortran appears to be going strong, with a revised standard planned for 2017.
In October C++ are rectifying the fact that they have not meet in Hawaii for three years. In fairness I ought to point out that the Fortran committee, when hosted by INCITS/PL22.3, regularly hold meetings in Las Vegas (I’m told its because the hotel rooms are cheap; Nevada is where US underground atom bomb tests were located and lots of super-computers executing programs written in Fortran were involved, or perhaps readers can think of an alternative explanation that does not invoke secret government organizations).
I found out that PL/1 is still an ISO Standard.
Work on the C and Ada standards continues.
Prolog has a new convenor, Ulrich Neumerkel. There was a meeting during April in Dresden, Germany but no minutes have been published. Did anybody attend?
ISO/IEC 23360-1:2006, the ISO version of the Linux Base Standard is almost 10 years behind the specification published by the organization who actually does the work. Some voices have expressed an interest in updating the ISO document. What does ISO’s version of the Linux Standard Base have to do with the committee responsible for programming languages?
Well, a long time ago in a galaxy far away, or the late 1980s in London, some people decided to set up a committee that specified O/S related library functions callable from C programs. SC22, programming languages, was the existing ISO committee having the closest fit with this new working group; initially it produced a specification that went under the name POSIX. Jump forward 15 years and Linux was the big POSIX success story (ok, the Linux people might see things differently) and dare I suggest that one of the motivations for creating ISO/IEC 23360-1:2006 might have been to bask in the reflected success of Linux. I understand the motivation of people involved in the standard’s process for wanting to published an update that reflects the current state of play (seriously out of date standards degrade the brand), but I don’t see why the Linux Foundation would be interested in going through the hassle of making this happen (unless they are having a mid-life crisis and are seeking approval of their work from an authority figure). Watch this blog for a 2016 status update.
Verified compilers and soap powder advertising
There’s a new paper out claiming to be about a formally-verified C compiler, it even states a Theorem about its abilities! If this paper appeared as part of a Soap powder advert the Advertising Standards Authority would probably require clarification of the claims. What clarifications might appear in the small print tucked away at the bottom of the ad?
- C source code is not verified directly, it is first translated to the formal notations used by the verification system; the software that performs this translation is assumed to be correct.
- The CompCert system may successfully translate programs containing undefined behavior. Any proof statements made about such programs may not be valid.
- The support tools are assumed to be correct; primarily the Coq proof assistant, which is written in OCaml.
- The CompCert system makes decisions about implementation dependent behaviors and any proofs only apply in the context of these decisions.
- The CompCert system makes decisions about unspecified behaviors and any proofs only apply in the context of these decisions.
Some notes on the small print:
The C source translator used by CompCert rarely gets mentioned in any of the published papers; what was done to check its accuracy (I have previously discussed some options)? Presumably the developers who wrote it tried very hard to make sure they did a good job, just like the authors of f2c, a Fortran to C translator, did. Connecting f2c as a front-end of the CompCert system gives us a verified Fortran compiler! I think the f2c translator is much more likely to be correct than the CompCert C source translator, it has been used by a lot more people, processed a lot more source and maintained over a longer period.
When they encounter undefined behavior in source code production C compilers sometimes generate code that has very unexpected behavior. Using the CompCert system will not avoid unexpected behavior in these situations; CompCert simply washes its hands for this kind of code and says all bets are off.
Proving the support tools correct would simply move the assumption of correctness to a different set of tools. I am not aware of any major effort to test whether the Coq system behaves as intended, but have not read all the papers describing it (the list of reported faults is does not appear to be publicly available); bugs have been found in the OCaml implementation.
Like all compilers that generate code, CompCert has to make implementation dependent decisions and select one of the possible unspecified behaviors. The C-Semantics tool generates all unspecified behaviors, rather than just one.
The oldest compiler still in production use is?
What is the oldest compiler still in production use?
A CHILL compiler I worked on a long time ago has probably been in production use for 30 years now.
Code gets added and deleted from production software all the time, how might ‘oldest’ be measured? I propose using the mean age of every line of code, including comments, where the age of a line is reset to zero when it is modified in any way (excluding code formatting).
The following are two environmental factors that enable a production compiler to get very old:
- a relatively obscure language: popular languages have new compilers written for them (compiler death through competition) or have new features added to them (requiring new lines of code which could even displace ‘aged’ code),
- a very long-lived application associated with the language: obscure languages tend to be very quickly abandoned in the dust of history unless they have a symbiotic relationship with an important application,
- very long-lived host hardware and target processor: changing either often requires substantial new code or a move to a newer compiler. For ancient the only candidate is the IBM 370 and just really old the Intel 80×80, Zilog Z80.
Virtual machines provide a mechanism to be host hardware independent. The Micro Focus Cobol had a rewrite in the early 1990s (it might have had others since) and I don’t think UCSD Pascal I.5 is still used for production work.
Fortran is an evolving language and very popular in some application domains. I doubt there are any (mean age) old Fortran compilers in production use.
Why do I put forward the ITT (in its International Telephone & Telegraph days, these bits subsequently sold off) CHILL compiler as potentially the oldest compiler currently in production use?
- Obscure language and long-lived application (telephone switching software),
- host hardware was IBM 370 family, target processor Intel 8086 (later updated to support 80386),
- large development team and very small support team (i.e., lots of old code and small changes over the years),
- single customer, i.e., no push to add features to attract new customers or keep existing ones.
My last conversation with anybody associated with this compiler was a chance meeting over 10 years ago, so I might be a bit out of date.
30+ year old source code for compilers can be downloaded (e.g., the original PDP 11 C compiler) but these compilers are not in production use (forgotten about military installations anybody?)
I welcome other proposals for the oldest compiler currently in production use.
Parsing R code: Freedom of expression is not always a good idea
With my growing interest in R it was inevitable that I would end up writing a parser for it. The fact that the language is relatively small (the add-on packages do the serious work) hastened the event because it did not look like much work; famous last words. I knew about R’s design and implementation being strongly influenced by the world view of functional programming and this should have set alarm bells ringing; this community have a history of willfully ignoring some of the undesirable consequences of their penchant of taking simple ideas and over generalizing them (i.e., I should have expected hidden complications).
While the official R language definition only contains a tiny fraction of the information needed to create a full implementation I decided to use it rather than ‘cheat’ and look at the R project implementation sources. I took as my oracle of correctness the source code of the substantial amount of R in its 3,000+ package library. This approach would help me uncover some of the incorrect preconceived ideas I have about how R source fits together.
I started with a C lexer and chopped and changed (it is difficult to do decent error recovery in automatically generated lexers and I prefer to avoid them). A few surprises cropped up ** is supported as an undocumented form of ^ and by default ]] must be treated as two tokens (e.g., two ] in a[b[c]] but one ]] in d[[e]], an exception to the very commonly used maximal munch rule).
The R grammar is all about expressions with some statement bits and pieces thrown in. R operator precedence follows that of Fortran, except the precedence of unary plus/minus has been increased to be above multiply/divide (instead of below). Easy peasy, cut and paste an existing expression grammar and done by tea time :-). Several tea times later I have a grammar that parses all of the R packages (apart from 80+ real syntax errors contained therein and a hand full of kinky operator combinations I’m not willing to contort the grammar to support). So what happened?
Two factors accounts for most of the difference between my estimate of the work required and the actual work required:
- my belief that a well written grammar has no ambiguities (while zero is a common goal for many projects a handful might be acceptable if the building is on fire and I have to leave). A major advantage of automatic generation of parser tables from a grammar specification is being warned about ambiguities in the grammar (either shift/reduce or reduce/reduce conflicts). At an early stage I was pulling my hair out over having 59 conflicts and decided to relent and look at the R project source and was amazed to find their grammar has 81 ambiguities!
I have managed to get the number of ambiguities down to the mid-30s, not good at all but it will have to do for the time being.
- some of my preconceptions about of how R syntax worked were seriously wrong. In some cases I spotted my mistake quickly because I recognized the behavior from other languages I know, other misconceptions took a lot longer to understand and handle because I did not believe anybody would design expression evaluation to work that way.
The root cause of the difference can more concretely be traced to the approach to specifying language syntax. The R project grammar is written using the form commonly seen in functional language implementations and introductory compiler books. This form has the advantage of being very short and apparently simple; the following is a cut down example in a form of BNF used by many parser generators:
expr : expr op expr | IDENTIFIER ; op : &' | '==' | '>' | '+' | '-' | '*' | '/' | '^' ; |
This specifies a sequence of IDENTIFIERs separated by binary operators and is ambiguous when the expression contains more than two operators, e.g., a + b * c can be parsed in more than one way. Parser generators such as Yacc will complain and flag any ambiguity and pick one of the possibilities as the default behavior for handling a given ambiguity; developers can specify additional grammar information in the file read by Yacc to guide its behavior when deciding how to resolve specific ambiguities. For instance, the relative precedence of operators can be specified and this information would be used by Yacc to decide that the ambiguous expression a + b * c should be parsed as-if it had been written like a + (b * c) rather than like (a + b) * c. The R project grammar is short, highly ambiguous and relies on the information contained in the explicitly specified relative operator precedence and associativity directives to resolve the ambiguities.
An alternative method of specifying the grammar is to have a separate list of grammar rules for each level of precedence (I always use this approach). In this approach there is no ambiguity, the precedence and associativity are implicitly specified by how the grammar is written. Obviously this approach creates much longer grammars, there will be at least two rules for every precedence level (19 in R, many with multiple operators). The following is a cut down example containing just multiple, divide, add and subtract:
... multiplicative_expression: cast_expression | multiplicative_expression '*' cast_expression | multiplicative_expression '/' cast_expression ; additive_expression: multiplicative_expression | additive_expression '+' multiplicative_expression | additive_expression '-' multiplicative_expression ; ... |
The advantages of this approach are that, because there are no ambiguities, the developer can see exactly how the grammar behaves and if an ambiguity is accidentally introduced when editing the source it should be noticed when the parser generator reports a problem where previously there were none (rather than the new ambiguity being hidden in the barrage of existing ones that are ignored because they are so numerous).
My first big misconception about R syntax was to think that R had statements, it doesn’t. What other languages would treat as statements R always treats as expressions. The if, for and while constructs have values (e.g., 2*(if (x == y) 2 else 4)). No problem, I used Algol 68 as an undergraduate, which supports this kind of usage. I assumed that when an if appeared as an operand in an expression it would have to be bracketed using () or {} to avoid creating a substantial number of parsing ambiguities; WRONG. No brackets need be specified, the R expression if (x == y) 2 else 4+1 is ambiguous (it could be treated as-if it had been written if (x == y) 2 else (4+1) or (if (x == y) 2 else 4)+1) and the R project grammar relies on its precedence specification to resolve the conflict (in favor of the first possibility listed above).
My next big surprise came from the handling of unary operators. Most modern languages give all unary operators the same precedence, generally higher than any binary operator. Following Fortran the R unary operators have a variety of different precedence levels; however R did not adopt the restrictions Fortran places on where unary operators can occur.
I assumed that R had adopted the restrictions used by other languages containing unary operators at different precedence levels, e.g., not allowing a unary operator token to follow a binary operator token (i.e., there has to be an intervening opening parenthesis); WRONG. R allows me to write 1 == !1 < 0, while Fortran (and Ada, etc) require that a parenthesis be inserted between the operands == ! (hopefully resulting in the intent being clearer).
I had to think a bit to come up with an explicit set of grammar rules to handle R unary operator's freedom of expression (without creating any ambiguities).
Stepping back from the details. My view is that programming language syntax should be designed to reduce the number of mistakes developers make. Requiring that brackets appear in certain contexts helps prevent mistakes by the original author and subsequent readers of the code.
Claims that R (or any other language) syntax is 'natural' is clearly spurious and really no more than a statement of preference by the speaker. Our DNA has not yet been found to equip us to handle one programming language better than another.
Over the coming months I hope to have the time to analyse R source looking for faults that might not have occurred had brackets been used. Also how much code might be broken if R started to require brackets in certain contexts?
An example of the difference that brackets can make is provided by the handling of the unary ! operator in R and C/C++/Java/etc. Take the expression !x > y, which R parses as-if written !(x > y) and C/C++/Java/etc as if written (!x) > y. I would not claim that either is better than the other from the point of view of developers getting the behavior right, I know that some C programmers get it wrong and I suspect that some R programmers do too.
By increasing the precedence of unary plus/minus the R designers ensured that 8/-2/2 was parsed like (8/-2)/2 rather than 8/(-2/2).
Recent Comments