Archive
Correlation between risk attitude and willingness to refer back
What is the connection between a software developer’s risk attitude and the faults they insert in code they write or fail to detect in code they review? This is a very complicated question and in an experiment performed at the 2011 ACCU conference I investigated one particular instance; the connection between risk attitude and recall of previously seen information.
The experiment consisted of a series of problems having the same format (the identifiers used varied between problems). Each problem involved remembering information on four assignment statements of the form:
p = 6 ; b = 4 ; r = 9 ; k = 8 ; |
performing some other unrelated task for a short time (hopefully long enough for them to forget some of the information they had previously seen) and then having to recognize the variables they had previously seen within a list containing five identifiers and recall the numeric value assigned to each variable.
When reading code developers have the option of referring back to previously read code and this option was provided to subject. Next to each identifier listed in the recall part of the problem was space to write the numeric value previously seen and a “would refer back” box. Subjects were told to tick the “would refer back” box if, in real life” they would refer back to the previously seen assignment statements rather than rely on their memory.
As originally conceived this experimental format is investigating the impact of human short term memory on recall of previously seen code. Every time I ran this kind of experiment there was a small number of subjects who gave a much higher percentage of “would refer back” answers than the other subjects. One explanation was that these subjects had a smaller short term memory capacity than other subjects (STM capacity does vary between people), another explanation is that these subjects are much more risk averse than the other subjects.
The 2011 ACCU experiment was designed to test the hypothesis that there was a correlation between a subject’s risk attitude and the percentage of “would refer back” answers they gave. The Domain-Specific Risk-Taking (DOSPERT) questionnaire was used to measure subject’s risk attitude. This questionnaire and the experimental findings behind it have been published and are freely available for others to use. DOSPERT measures risk attitude in six domains: social, recreation, gambling, investing health and ethical.
The following scatter plot shows each (of 30) subject’s risk attitude in the six domains (x-axis) plotted against percentage of “would refer back” answers (y-axis).
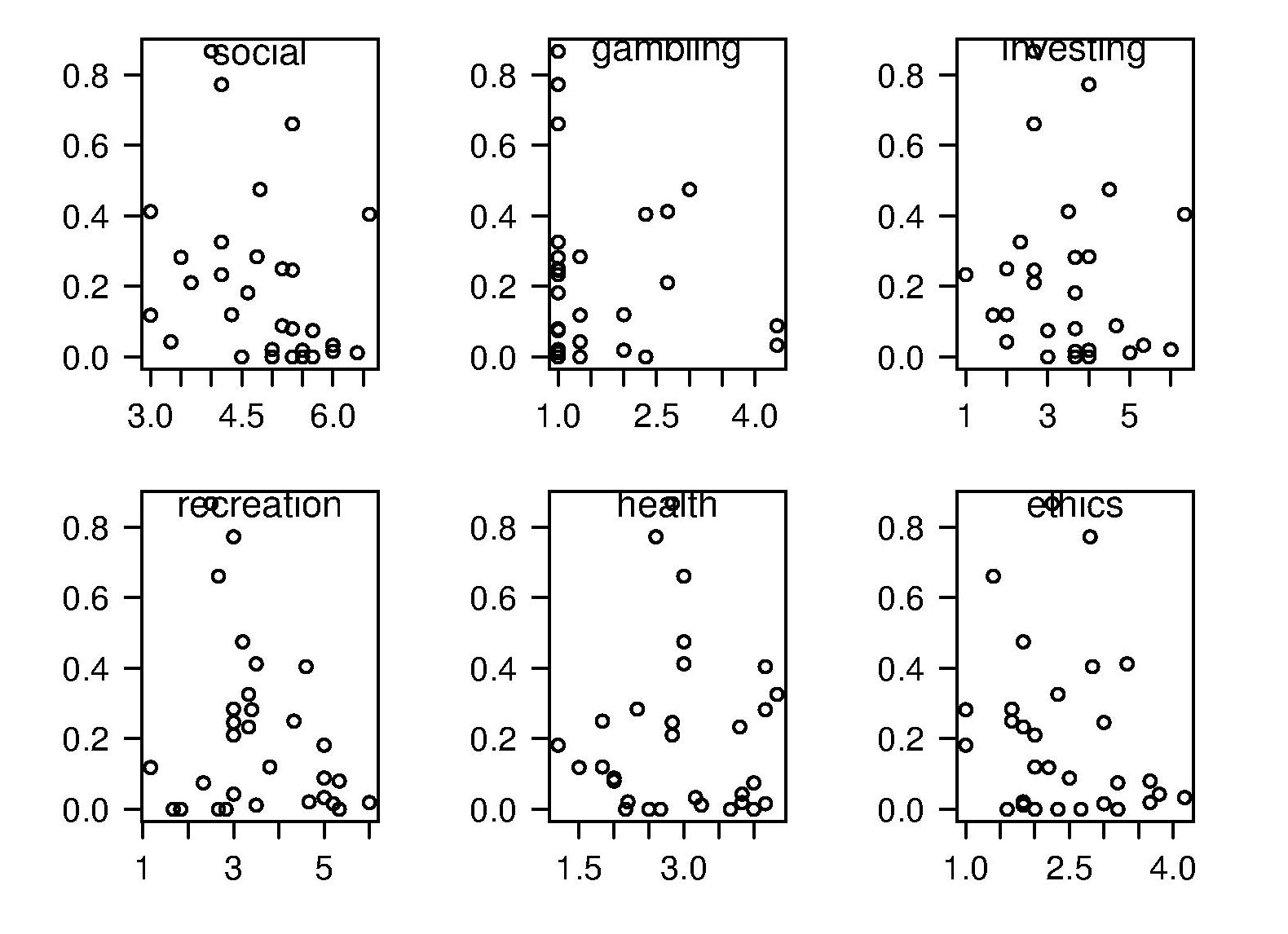
A Spearman rank correlation test confirms what is visibly apparent, there is no correlation between the two quantities. Scatter plots using percentage of correct answers and total number of questions answers show a similar lack of correlation.
The results suggest that risk attitude (at least as measured by DOSPERT) is not a measurable factor in subject recall performance. Perhaps the subjects that originally caught my attention (there were three in 2011) really do have a smaller STM capacity compared to other subjects. The organization of the experiment (one hour during a one lunchtime of the conference) does not allow for a more extensive testing of subject cognitive characteristics.
Compiling to reduce the impact of soft errors on program output
Optimizing compilers have traditionally made code faster and smaller (sometimes a choice has to be made between faster/larger and slower/smaller). The huge growth in the use of battery power devices has created a new attribute for writers of optimizers to target, finding code sequences that minimise power consumption (I previously listed this as a major growth area in the next decade). Radiation (e.g., from cosmic rays) can cause a memory or processor bit to flip, known as a soft error, and I have recently been reading about how code can be optimized to reduce the probability that soft errors will alter the external behavior of a running program.
The soft error rate is usually quoted in FITs (Failure in Time), with 1 FIT corresponding to 1 error per  hours per megabit, or
hours per megabit, or  errors per bit-hour. A PC with 4 GB of DRAM (say 1000 FIT/Mb which increases with altitude and is 10 times greater in Denver, Colorado) has a MTBF (mean time between failure) of
errors per bit-hour. A PC with 4 GB of DRAM (say 1000 FIT/Mb which increases with altitude and is 10 times greater in Denver, Colorado) has a MTBF (mean time between failure) of  hours, around once every 33 hours. Calculating the FIT for processors is complicated.
hours, around once every 33 hours. Calculating the FIT for processors is complicated.
Uncorrected soft errors place a limit on the maximum number of computing nodes that can be usefully used by one application. At around 50,000 nodes, a system will be spending half its time saving checkpoints and restarting from previous checkpoints after an error occurs.
Why not rely on error correcting memory? Super computers containing terabytes are built containing error correcting memory, but this does not make the problem go away, it ‘only’ reduces it by around two orders of magnitude. Builders of commodity processors don’t use much error correction circuitry because it would increase costs/power consumption/etc for an increased level of reliability that the commodity market is not interested in; vendors of high-end processors add significant amounts of error correction circuitry.
Most of the compiler research I am aware of involves soft errors occurring on the processor, and this topic is discussed below; there has been some work on assigning variables deemed to be critical to a subset of memory that is protected with error correcting hardware. Pointers to other compiler research involving memory soft errors welcome.
A commonly used technique for handling hardware faults is redundancy, usually redundant hardware (e.g., three processors performing the same calculating and a majority vote used to decide which of the outputs to accept). Software only approaches include the compiler generating two or more independent machine code sequences for each source code sequence whose computed values are compared at various check points and running multiple copies of a program in different threads and comparing outputs. The
Shoestring compiler (based on llvm) takes a lightweight approach to redundancy by not duplicating those code sequences that are less affected by register bit flips (e.g., the value obtained from a bitwise AND that extracts 8 bits from a 32-bit register is 75% less likely to deliver an incorrect result than an operation that depends on all 32 bits).
The reliability of single ‘thread’ generated code can be improved by optimizing register lifetimes for this purpose. A value is loaded into a register and sometime later it is used one or more times. A soft error corrupting register contents after the last use of the value it contains has no impact on program execution, the soft error has to occur between the load and last use of the value for it to possibly influence program output. One group of researchers modified a compiler (Trimaran) to order register usage such that the average interval between load and last usage was reduced by 10%, compared to the default behavior.
Developers don’t have to wait for compiler or hardware support, they can improve reliability by using algorithms that are robust in the presence of ‘faulty’ hardware. For instance, the traditional algorithms for two-process mutual exclusion are not fault-tolerant; a fault-tolerant mutual exclusion algorithm using  variables, where a single fault may occur in up to
variables, where a single fault may occur in up to  variables is available.
variables is available.
Automatically improving code
Compared to 20 or 30 years ago we know a lot more about the properties of algorithms and better ways of doing things often exist (e.g., more accurate, faster, more reliable, etc). The problem with this knowledge is that it takes the form of lots and lots of small specific details, not the kind of thing that developers are likely to be interested in, or good at, remembering. Rather than involve developers in the decision-making process, perhaps the compiler could figure out when to substitute something better for what had actually been written.
While developers are likely to be very happy to see what they have written behaving as accurately and reliably as they had expected (ignorance is bliss), there is always the possibility that the ‘less better’ behavior of what they had actually written had really been intended. The following examples illustrate two relatively low level ‘improvement’ transformations:
- this case is probably a long-standing fault in many binary search and merge sort functions; the relevant block of developer written code goes something like the following:
while (low <= high) { int mid = (low + high) / 2; int midVal = data[mid]; if (midVal < key) low = mid + 1 else if (midVal > key) high = mid - 1; else return mid; }
The fault is in the expression
(low + high) / 2which overflows to a negative value, and returns a negative value, if the number of items being sorted is large enough. Alternatives that don’t overflow, and that a compiler might transform the code to, include:low + ((high - low) / 2)and(low + high) >>> 1. - the second involves summing a sequence of floating-point numbers. The typical implementation is a simple loop such as the following:
sum=0.0; for i=1 to array_len sum += array_of_double[i];
which for large arrays can result in
sumlosing a great deal of accuracy. The Kahan summation algorithm tries to take account of accuracy lost in one iteration of the loop by compensating on the next iteration. If floating-point numbers were represented to infinite precision the following loop could be simplified to the one above:sum=0.0; c=0.0; for i = 1 to array_len { y = array_of_double[i] - c; // try to adjust for previous lost accuracy t = sum + y; c = (t - sum) - y; // try and gets some information on lost accuracy sum = t; }
In this case the additional accuracy is bought at the price of a decrease in performance.
Compiler maintainers are just like other workers in that they want to carry on working at what they are doing. This means they need to keep finding ways of improving their product, or at least improving it from the point of view of those willing to pay for their services.
Many low level transformations such as the above two examples would be not be that hard to implement, and some developers would regard them as useful. In some cases the behavior of the code as written would be required, and its transformed behavior would be surprising to the author, while in other cases the transformed behavior is what the developer would prefer if they were aware of it. Doesn’t it make sense to perform the transformations in those cases where the as-written behavior is least likely to be wanted?
Compilers already do things that are surprising to developers (often because the developer does not fully understand the language, many of which continue to grow in complexity). Creating the potential for more surprises is not that big a deal in the overall scheme of things.
Estimating the reliability of compiler subcomponent
Compiler stress testing can be used for more than finding bugs in compilers, it can also be used to obtain information about the reliability of individual components of a compiler. A recent blog post by John Regehr, lead investigator for the Csmith project, covered a proposal to improve an often overlooked aspect of automated compiler stress testing (removing non-essential code from a failing test case so it is small enough to be acceptable in a bug report; attaching 500 lines of source to a report in a sure fire way for it to be ignored) triggered this post. I hope that John’s proposal is funded and it would be great if the researchers involved also received funding to investigate component reliability using the data they obtain.
One process for estimating the reliability of the components of a compiler, or any other program, is:
- divide the compiler into a set of subcomponents. These components might be a collection of source files obtained through cluster analysis of the source, obtained from a functional analysis of the implementation documents or some other means,
- count the number of times each component executes correctly and incorrectly (this requires associating bugs with components by tracing bug fixes to the changes they induce in source files; obtaining this information will consume the largest amount of the human powered work) while processing lots of source. The ratio of these two numbers, for a given component, is an estimate of the reliability of that component.
How important is one component to the overall reliability of the whole compiler? This question can be answered if the set of components is treated as a Markov chain and the component transition probabilities are obtained using runtime profiling (see Large Empirical Case Study of Architecture–based Software Reliability by Goševa-Popstojanova, Hamill and Perugupalli for a detailed discussion).
Reliability is a important factor in developers’ willingness to enable some optimizations. Information from a component reliability analysis could be used to support an option that only enabled optimization components having a reliability greater than a developer supplied value.
The one big threat to validity of this approach is that stress tests are not representative of typical code. One possibility is to profile the compiler processing lots of source (say of the order of a common Linux distribution) and merge the transition probabilities, probably weighted, to those obtained from stress tests.
Quality of data analysis: two recent papers
Software engineering research has and continues to suffer from very low quality data analysis. The underlying problem is that practitioners are happy to go along with the status quo, not bothering to learn basic statistics or criticize data analysis in papers they are asked to review. Two recent papers I have read spring out as being at opposite ends of the spectrum.
In their paper A replicated survey of IT software project failures Khaled El Emam and A. Günes Koru don’t just list the mean values for the responses they get they also give the 95% confidence bounds on those values. At a superficial level this has the effect of making their results look much less interesting; for instance a quick glance at Table 3 “Reasons for project cancellation” suggests there is a significant difference between “Lack of necessary technical skills” at 22% and “Over schedule” at 17% but a look at the 95% confidence bounds, (6%–48%) and (4%–41%) respectively, shows that almost nothing can be said about the relative contribution of these two reasons (why publish these numbers, because nothing else has been published and somebody has to start somewhere). The authors understand the consequences of using a small sample size and have the integrity to list the confidence bounds rather than leave the reader to draw completely unjustified conclusions. I wish everybody was as careful and upfront about their analysis as these authors.
The paper Assessing Programming Language Impact on Development and Maintenance: A Study on C and C++ by Pamela Bhattacharya and Iulian Neamtiu takes some interesting ideas and measurements and completely mangles the statistical analysis (something the conference’s reviewers should have picked up on).
I encourage everybody to measure code and do statistical analysis. It looks like what happened here is that a PhD student got in over her head and made lots of mistakes, something that happens to us all when learning a new subject. The problem is that these mistakes made it through into a published paper and its conclusions are likely to repeated (these conclusions may or may not be true and it may or may not be possible to reliably test them from the data gathered, but the analysis presented in the paper faulty and so its conclusions cannot be trusted). I hope the authors will reanalyze their data using the appropriate techniques and publish an updated version of the paper.
Some of the hypothesis being tested include:
- C++ is replacing C as a main development language. The actual hypothesis tested is the more interesting question: “Is the percentage of C++ in projects that also contain substantial amounts of C growing at the expense of C?”
So the unit of measurement is the project and only four of these are included in the study; an extremely small sample size that must have an error bound of around 50% (no mention of error bounds in the paper). The analysis of the data claims to use linear regression but seems completely confused, lets not get bogged down in the details but move on to other more obvious mistakes.
- C++ code is of higher internal quality than C code. The data consists of various source code metrics, ignoring whether these are a meaningful measure of quality, lets look at how the numbers are analysed. I was somewhat surprised to read: “the distributions of complexity values … are skewed, thus arithmetic mean is not the right indicator of an ongoing trend. Therefore, …, we use the geometric mean …” While the arithmetic mean might not be a useful indicator (I have trouble seeing why not), use of the geometric mean is bizarre and completely wrong. Because of its multiplicative nature the geometric mean of a set of values having a fixed arithmetic mean decreases as its variance increases. For instance, the two sets of values (40, 60) and (20, 80) both have an arithmetic mean of 50, while their geometric means are 48.98979 (i.e.,
^0.5") ) and 40 (i.e.,
) and 40 (i.e., ^0.5") ) respectively.
) respectively.
So if anything can be said about the bizarre idea of comparing the geometric mean of complexity metrics as they change over time, it is that increases/decreases are an indicator of decrease/increase in variance of the measurements.
- C++ code is less prone to bugs than C code. The statistical analysis here made a common novice mistake. The null hypothesis tested was: “C code has lower or equal defect density than C++ code.” and this was rejected. The incorrect conclusion drawn was that “C++ code is less prone to bugs than C code.” Statistically one does not follow from the other, the data could be inconclusive and the researchers should have tested this question as the null hypothesis if this is the claim they wanted to make. There are also lots of question marks over other parts of the analysis, but this is the biggest blunder.
Searching for inaccurate literals in R
In creating the numbers tool I wanted to be able to do two things, 1) obtain information about what source did by matching the numeric literals it contained against a database of ‘interesting’ values (now with over 14,000 entries) and 2) flag possible incorrect numeric literals (e.g., 3.1459265 when 3.14159265 had been intended in core/Helix.cpp of the MIFit source {now fixed}).
I have recently been enhancing ‘incorrect numeric literal’ support and using the latest release of R as a test bed (whose floating-point literals are almost identical to the last release I looked at, R-2.11.1, log file here).
The first fault I found (0.20403... instead of 0.020403...) looked very serious until I realised it was involved in calculating an initial value feed into an iterative algorithm (at worst causing an extra iteration or so). It looks like the developer overlooked the “e-1” that appears in the original (click on ‘Page 48’).
The second possible problem turned out to be an ambiguity in the file main/color.c which contains the comment “CIE-XYZ to sRGB” above three expressions that perform a conversion from CIE-XYZ to BT.709 RGB. Did the developer get the comment or the numeric literals wrong? People are known to confuse the two forms of RGB (for an explanation see Annex B) .
Apart from a few minor errors such as 0.950301 instead of 0.9503041 (in …/grDevices/R/postscript.R) nothing else of interest turned up so I shifted attention to the add-on packages available on the Comprehensive R Archive Network.
The 3,000+ packages occupy almost 2 Gig in compressed form (fortunately numbers can operate directly on compressed archives and the files did not need to be unpacked) and I decided to limit the analysis to just the R source files, which cut the number of floating-point literals down to around 2 million (after ignoring the contents of comments, 10M compressed log file here).
The various floating-point literals having a value close to 2.30258509299404568402 (the most common match; no idea why the value ln(10) or 1/log(e) should be so popular) highlight the various issues that crop up when using approximate matching to look for faults. The following are some of these matches (first number is total occurrences, second sequence is the literal appearing in the source with dot denoting the same digit as in the number matched against):
92 ........ 2.30258509299404568402 ln(10) or 1/log(e) 5 ...............5 2.30258509299404568402 ln(10) or 1/log(e) 1 .....80528052805 2.30258509299404568402 ln(10) or 1/log(e) 3 .....6 2.30258509299404568402 ln(10) or 1/log(e) 2 .....67 2.30258509299404568402 ln(10) or 1/log(e) 1 .....38 2.30258509299404568402 ln(10) or 1/log(e) 2 .....8 2.30258509299404568402 ln(10) or 1/log(e) 1 .....42 2.30258509299404568402 ln(10) or 1/log(e) 2 ......7 2.30258509299404568402 ln(10) or 1/log(e) 2 ......2 2.30258509299404568402 ln(10) or 1/log(e) 1 ....... 2.30258509299404568402 ln(10) or 1/log(e) 2 .....6553 2.30258509299404568402 ln(10) or 1/log(e) 1 .......4566 2.30258509299404568402 ln(10) or 1/log(e)
Most of those 92 seven digit matches occur in a subdirectory called data implying that they do not occur within code expressions, while .....80528052805 contains enough extra trailing non-matching digits to suggest a different value really was intended. Are there enough unmatched trailing digits in .....6553 to consider it a different value? More experience needs to be gained before attempting to make this call automatically.
At the moment a person has to look at the code containing these ‘close’ values to decide whether the author made a mistake or really did mean to use the value given (unfortunately numbers does not yet have a fancy gui to simplify this task). Sometimes the literals appear in data and other times in an expression that requires domain knowledge to figure out whether it is correct or not. My cursory sampling of the very large data set did not find any serious problems.
Some of the unmatched literals contain so few significant digits they would match many entries in a database of ‘interesting’ values. For instance the numbers database used to contain 745.0, the mean radius of the minor planet Sedna (according to the latest NASA data), but it was removed because of the large number of false positive matches it generated.
Many of the unmatched literals appear to do not appear to have any special interest outside of code that contains them, for instance 0.2.
I am hoping that readers of this blog will download numbers and run their code through it. They might find some faults in their code and add new values to their local ‘interesting’ numbers database to target their own application domain(not forgetting to email me a copy to include in the next release). Suggestions for improving the detection of inaccurate literals always welcome (check to the TODO file first).
An interesting observation from comparing the mathematical equations in the book Computation of Special Functions with the Fortran source provided by its authors is that when a ‘known’ constant (e.g., pi, pi/2) appears in isolation (e.g., as an argument or a value in an assignment) its literal representation often contains as many digits as supported in 64-bits, while when the same constant appears within an expression evaluating a polynomial it often contains the same number of digits as the other literals appearing in that expression (which is usually less than supported in 64-bits).
Estimating the quality of a compiler implemented in mathematics
How can you tell if a language implementation done using mathematical methods lives up to the claims being made about it, without doing lots of work? Answers to the following questions should give you a good idea of the quality of the implementation, from a language specification perspective, at least for C.
- How long did it take you to write it? I have yet to see any full implementation of a major language done in less than a man year; just understanding and handling the semantics, plus writing the test cases will take this long. I would expect an answer of at least several man years
- Which professional validation suites have you tested the implementation against? Many man years of work have gone into the Perennial and PlumHall C validation suites and correctly processing either of them is a non-trivial task. The gcc test suite is too light-weight to count. The C Model Implementation passed both
- How many faults have you found in the C Standard that have been accepted by WG14 (DRs for C90 and C99)? Everybody I know who has created a full implementation of a C front end based on the text of the C Standard has found faults in the existing wording. Creating a high quality formal definition requires great attention to detail and it is to be expected that some ambiguities/inconsistencies will be found in the Standard. C Model Implementation project discoveries include these and these.
- How many ‘rules’ does the implementation contain? For the C Model Implementation (originally written in Pascal and then translated to C) every if-statement it contained was cross referenced to either a requirement in the C90 standard or to an internal documentation reference; there were 1,327 references to the Environment and Language clauses (200 of which were in the preprocessor and 187 involved syntax). My C99 book lists 2,043 sentences in the equivalent clauses, consistent with a 70% increase in page count over C90. The page count for C1X is around 10% greater than C99. So for a formal definition of C99 or C1X we are looking for at around 2,000 language specific ‘rules’ plus others associated with internal housekeeping functions.
- What percentage of the implementation is executed by test cases? How do you know code/mathematics works if it has not been tested? The front end of the C Model Implementation contains 6,900 basic blocks of which 87 are not executed by any test case (98.7% coverage); most of the unexecuted basic blocks require unusual error conditions to occur, e.g., disc full, and we eventually gave up trying to figure out whether a small number of them were dead code or just needed the right form of input (these days genetic programming could be used to help out and also to improve the quality of coverage to something like say MC/DC, but developing on a PC with a 16M hard disc does limit what can be done {the later arrival of a Sun 4 with 32M of RAM was mind blowing}).
Other suggested questions or numbers applicable to other languages most welcome. Some forms of language definition do not include a written specification, which makes any measurement of implementation conformance problematic.
Proving software correct
Users want confidence that software is ‘correct’; what constitutes correct depends on who you talk to and can vary between doing what the user expects and behaving according to a specification (which may include behavior that users did not expect or want).
The gold standard for software correctness is that achieved by mathematical proofs, or at least what most people believe is achieved by such proofs, i.e., a statement that is shown through a sequence of steps to be derived from a set of axioms. The sequence of steps used in most real proofs operate at a much higher level than axioms and rely on the reader to fill in the gaps left between each step. Ever since theorems were first stated they sometimes contained faults, i.e., were not correct theorems, and as mathematicians have continued to increase the size and complexity of theorems being ‘proved’ the technical and social issues involved in believing a published proof have grown in complexity.
Software proofs usually operate by translating the source in to some mathematical formalism and using a theorem prover to show that one or more properties are met. Perhaps the most famous use of such a proof that had an outcome different than that predicted is the 1996 Ariane 5 rocket crash; various proofs had been obtained for the Ariane 4 software showing that the value of some variables would never exceed given limits, these proofs involved input values that depended on the performance of the rocket and because Ariane 5 was more powerful than Ariane 4 the proofs were no longer valid (management would have found this out had they recheck the proofs using the larger values). Update: My only knowledge of this work comes from a conversation I recall with somebody working in the formal verification area, I no longer have contact with them and the company they worked for no longer exists; Pascal Cuoq’s comment below suggests they may have overstated the formal nature of the work, I have no means of double checking.
Purveyors of ‘software proof’ systems will tell you about the importance of feeding in the correct input values and will tell you about the known proofs they have managed to verify using their system. The elephant in the room that rarely gets mentioned is the correctness of the program that translates source code into the mathematical formalism used. These translators often handle that subset of the language which is relatively easy to map to the target formalism, the MALPAS C to IL translator is one exception to this (ok, yes my company wrote this translator so the opinion might be a little biased).
The method commonly associated with claims of correctness proof for a translator or compiler is slightly different from that described above for applications. This method involves manually writing some mathematics, using the chosen formalism, that ‘implements’ the translator/compiler. Strangely there are people who think that doing this is sufficient to claim the compiler is ‘verified’ or ‘proved correct’. As any schoolboy knows it is possible to write mathematics that contains mistakes and the writing of a mathematical implementation is just the first step in a process intended to increase confidence in a claim of correctness.
One of the questions that might be asked of a ‘mathematics implementation’ of a compiler is: does it faithfully interpret source code syntax/semantics according to the syntax/semantics specified in the appropriate language document?
Answering this question requires that the language syntax/semantics be specified in some mathematical notation that is amenable to formal analysis. Various researchers have created mathematical models for languages such as Ada, CHILL and C. However, these models are not recognized as being definitive, that status belongs to the corresponding ISO Standard written in English prose. The Modula-2 standard is specified using both English prose and equivalent mathematical notation with both having equal status as the definition of the language (any inconsistency between the two is decided why analyzing what behavior was intended); there were lots of plans to do stuff with this mathematics but the ISO language committee struggled just to produce a tool capable of printing the mathematics.
The developers of the Compcert system refer to it as a formally verified C compiler front-end when the language actually verified is called Clight, which they describe as a subset of the C language. This is very interesting work and I hope they continue to refine it and add support for more C-like constructs. But let’s be clear, the one thing missing from this project is any proof of a connection to the requirements contained in the C Standard.
I don’t know what it is about formal verification but those involved can at the same time be both very particular about the language they use in their mathematics and completely over the top in the claims they make about what their tools do. A speaker from Polyspace at one MISRA C conference claimed his tool could detect 100% of the coding guidelines specified in MISRA C, a surprising achievement for a runtime tool (as it was then) enforcing requirements mainly aimed at source code; I eventually got him to agree that the tool detected 100% of the constructs specified by the small subset of guidelines they had implemented.
I doubt that the Advertising Standard Authority would allow adverts containing the claims made by some formal verification advocates to appear in print or on TV; if soap manufacturers have to follow ASA rules then so should formal verification researchers.
Without a language specification written in a form amenable to mathematical analysis any claims of correctness have to be based on the traditional means of reading English prose very carefully and writing lots of tests to probe every obscure corner of the language specification. This was the approach used for the production of the Model Implementation of C, a system designed to detect all unspecified, implementation defined and undefined uses in C programs (it used a compiler, linker and interpreter). One measure of how well an implementor has studied the standard is how many faults they have discovered in it (some people claim this is a quality of standard issue, but the similar number of defects reported against the Ada and C Standards show that at least for Ada this is not true); here are some from the Model Implementation project.
Performance on independently written tests can be a good indicator of implementation correctness, depending on the quality of the tests. Both the Perennial and PlumHall C validation suites are of high quality, while suites such as the gcc testsuite are rather ad-hoc, have poor coverage and tend to be runtime oriented. The problem with high quality validation suites is that they cost enough money to put them out of reach of many research groups (I suspect another problem is that such groups don’t understand the benefits of using such suites or think they can do just as good a job in a few weeks).
Recently a new formal verification tool for C has appeared that performs all its verification checking at program runtime, i.e., after the user source has been translated to executable form. It is still very early days for kcc (they have yet to chose a name and the command used to invoke the translator is currently being used), they have an initial system up and running and are keen to continue improving it.
I am interested in the system because of what it might evolve into, including:
- a means of quickly checking the behavior of obscure bits of code (I get asked all sorts of weird questions and my brain is not always willing to switch to C language lawyer mode),
- a means of checking the consistency of the requirements in the C Standard, which will require another tool making use of the formalism built up by kcc,
- a tool which would help developers understand which parts of the C Standard they need to look at to understand some construct (the tool currently has a trace mode that needs lots of work).
Empirical software engineering is five years old
Science and engineering are built on theoretical models that are tested against measurements of ‘reality’. Until around 10 years ago there was very little software engineering ‘reality’ publicly available; companies rarely made source available and were generally unforthcoming about any bugs that had been discovered. What happened around 10 years ago was the creation of public software repositories such as SourceForge and public fault databases such as Bugzilla. At last researchers had access to what could be claimed to be real world data.
Over the last five years there has been an explosion of papers using SourceForge/Bugzilla kinds of data looking for a connection between everything+kitchen sink and faults. The traditional measures such as Halstead and McCabe have not stood up well against this onslaught of data, hardly surprising given they were more or less conjured out of thin air. Some researchers are trying to extract information about developer characteristics from mailing lists; given that software is written by developers there is obviously a real need for the characteristics of major project contributors to play a significant role in any theory of software faults.
Software engineering data includes a lot more than what can be extracted from source code, bug lists and email lists. A growing number of repositories have been set up to hold measurement and experimental data, e.g., hardware failures, effort prediction (while some of this data is pre-2000 it tends to be low volume or poor quality), and file system related.
At the individual level a small number of researchers have made data available on their own web site, a few more will send a copy if asked and sadly there are many cases where the raw data has been lost. In two recent cases researchers have responded to my request for raw data by telling me they are working on additional papers and don’t want to make the data public yet. I can understand that obtaining interesting data requires a lot of work and researchers want to extract maximum benefit; I look forward to see the new papers and the eventual availability of the data.
My interest in all this data is that I have started work on a book covering empirical software engineering using R. Five years ago such book would have contained lots of equations, plenty of hand waving and if data sets were available they would probably have been small enough to print on one page. Today there are still plenty of equations (mostly relating to statistical this that and the other), no hand waving (well, none planned), data sets for everything covered (some in the gigabytes and a few that can still fit on a page) and pretty pictures (color graphs, as least for the pdf version).
When historians trace back the history of empirical software engineering I think they will say that it started for real sometime around 2005. Before then, any theories that were based on observation tended to have small, single study, data sets with little statistical significance or power.
Has the seed that gets software development out of the stone-age been sown?
A big puzzle for archaeologists is why Stone Age culture lasted as long as it did (from approximately 2.5 millions years ago until the start of the copper age around 6.3 thousand years ago). Given the range of innovation rates seen in various cultures through-out human history, a much shorter Stone Age is to be expected. A recent paper proposes that low population density is what maintained the Stone Age status quo; there was not enough contact between different hunter gather groups for widespread take up of innovations. Life was tough, and the viable lifetime of individual groups of people may not have been long enough for them to be likely to pass on innovations (either their own ones encountered through contact with other groups).
Software development is often done by small groups that don’t communicate with other groups and regularly die out (well there is a high turn-over, with many of the more experienced people moving on to non-software roles). There are sufficient parallels between hunter gathers and software developers to suggest both were/are kept in a Stone Age for the same reason, lack of a method that enables people to obtain information about innovations and how worthwhile these might be within a given environment.
A huge barrier to the development of better software development practices is the almost complete lack of significant quantities of reliable empirical data that can be used to judge whether a claimed innovation is really worthwhile. Companies rarely make their detailed fault databases and product development history public; who wants to risk negative publicity and lawsuits just so academics have some data to work with.
At the start of this decade, public source code repositories like SourceForge and public software fault repositories like Bugzilla started to spring up. These repositories contain a huge amount of information about the characteristics of the software development process. Questions that can be asked of this data include: what are common patterns of development and which ones result in fewer faults, how does software evolve and how well do the techniques used to manage it work.
Empirical software engineering researchers are now setting up repositories, like Promise, containing the raw data from their analysis of Open Source (and some closed source) projects. By making this raw data available, they are reducing the effort needed by other researchers to investigate their own alternative ideas (I have just started a book on empirical software engineering using the R statistical language that uses examples based on this raw data).
One of the side effects of Open Source development could be the creation of software development practices that have been shown to be better (including showing that some existing practices make things worse). The source of these practices not being what the software developers themselves do or how they do it, but the footsteps they have left behind in the sand.
Recent Comments