Archive
Comparing expression usage in mathematics and C source
Why does a particular expression appear in source code?
One reason is that the expression is the coded form of a formula from the application domain, e.g.,  .
.
Another reason is that the expression calculates an algorithm/housekeeping related address, or offset, to where a value of interest is held.
Most people (including me, many years ago) think that the majority of source code expressions relate to the application domain, in one-way or another.
Work on a compiler related optimizer, and you will soon learn the truth; most expressions are simple and calculate addresses/offsets. Optimizing compilers would not have much to do, if they only relied on expressions from the application domain (my numbers tool throws something up every now and again).
What are the characteristics of application domain expression?
I like to think of them as being complicated, but that’s because it used to be in my interest for them to be complicated (I used to work on optimizers, which have the potential to make big savings if things are complicated).
Measurements of expressions in scientific papers is needed, but who is going to be interested in measuring the characteristics of mathematical expressions appearing in papers? I’m interested, but not enough to do the work. Then, a few weeks ago I discovered: An Analysis of Mathematical Expressions Used in Practice, by Clare So; an analysis of 20,000 mathematical papers submitted to arXiv between 2000 and 2004.
The following discussion uses the measurements made for my C book, as the representative source code (I keep suggesting that detailed measurements of other languages is needed, but nobody has jumped in and made them, yet).
The table below shows percentage occurrence of operators in expressions. Minus is much more common than plus in mathematical expressions, the opposite of C source; the ‘popularity’ of the relational operators is also reversed.
Operator Mathematics C source = 0.39 3.08 - 0.35 0.19 + 0.24 0.38 <= 0.06 0.04 > 0.041 0.11 < 0.037 0.22 |
The most common single binary operator expression in mathematics is n-1 (the data counts expressions using different variable names as different expressions; yes, n is the most popular variable name, and adding up other uses does not change relative frequency by much). In C source var+int_constant is around twice as common as var-int_constant
The plot below shows the percentage of expressions containing a given number of operators (I’ve made a big assumption about exactly what Clare So is counting; code+data). The operator count starts at two because that is where the count starts for the mathematics data. In C source, around 99% of expressions have less than two operators, so the simple case completely dominates.
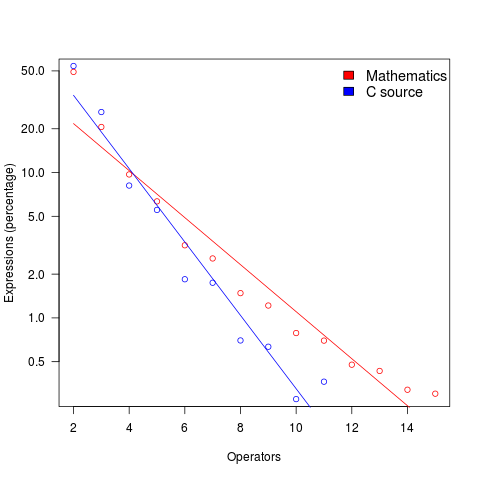
For expressions containing between two and five operators, frequency of occurrence is sort of about the same in mathematics and C, with C frequency decreasing more rapidly. The data disagrees with me again…
Number of possible different one line programs
Writing one line programs is a popular activity in some programming languages (e.g., awk and Perl). How many different one line programs is it possible to write?
First we need to get some idea of the maximum number of characters that written on one line. Microsoft Windows XP or later has a maximum command line length of 8191 characters, while Windows 2000 and Windows NT 4.0 have a 2047 limit. POSIX requires that _POSIX2_LINE_MAX have a value of at least 2048.
In 2048 characters it is possible to assign values to and use at least once 100 different variables (e.g., a1=2;a2=2.3;....; print a1+a2*a3...). To get a lower bound lets consider the number of different expressions it is possible to write. How many functionally different expressions containing 100 binary operators are there?
If a language has, say, eight binary operators (e.g., +, -, *, /, %, &, |, ^), then it is possible to write  visually different expressions containing 100 binary operators. Some of these expressions will be mathematically equivalent (adopting the convention of leaving out the operands), e.g.,
visually different expressions containing 100 binary operators. Some of these expressions will be mathematically equivalent (adopting the convention of leaving out the operands), e.g., + * can also be written as * + (the appropriate operands will also have the be switched around).
If we just consider expressions created using the commutative operators (i.e., +, *, &, |, ^), then with these five operators it is possible to write 1170671511684728695563295535920396 mathematically different expressions containing 100 operators (assuming the common case that the five operators have different precedence levels, which means the different expressions have a one to one mapping to a rooted tree of height five); this  is a lot smaller than
is a lot smaller than  .
.
Had the approximately  computers/smart phones in the world generated expressions at the rate of
computers/smart phones in the world generated expressions at the rate of  per second since the start of the Universe,
per second since the start of the Universe,  seconds ago, then the
seconds ago, then the  created so far would be almost half of the total possible.
created so far would be almost half of the total possible.
Once we start including the non-commutative operators such a minus and divide the number of possible combinations really starts to climb and the calculation of the totals is real complicated. Since the Universe is not yet half way through the commutative operators I will leave working this total out for another day.
Update (later in the day)
To get some idea of the huge jump in number of functionally different expressions that occurs when operator ordering is significant, with just the three operators -, / and % is is possible to create  mathematically different expressions. This is a factor of
mathematically different expressions. This is a factor of  greater than generated by the five operators considered above.
greater than generated by the five operators considered above.
If we consider expressions containing just one instance of the five commutative operators then the number of expressions jumps by another two orders of magnitude to  . This count will continue to increase for a while as more commutative operators are added and then start to decline; I have not yet worked things through to find the maxima.
. This count will continue to increase for a while as more commutative operators are added and then start to decline; I have not yet worked things through to find the maxima.
Update (April 2012).
Sequence A140606 in the On-Line Encyclopedia of Integer Sequences lists the number of inequivalent expressions involving n operands; whose first few values are: 1, 6, 68, 1170, 27142, 793002, 27914126, 1150212810, 54326011414, 2894532443154, 171800282010062, 11243812043430330, 804596872359480358, 62506696942427106498, 5239819196582605428254, 471480120474696200252970, 45328694990444455796547766, 4637556923393331549190920306
Information content of expressions
Software developers read source code to obtain information. How might the information content of source code be quantified?
Both of the following functions assign the same value to x and if that is the only information a reader of that code is interested in, then the information content of both assignment statements could be said to be the same.
int foo(void) { x = 5; ... } int bar(void) { x = 2 + 3; ... |
A reader seeking deeper understanding of the above code would ask why the value 5 is built from two values in bar. One reason might be that the author of the function wanted to explicitly call out background information about how the value 5 was derived (this is often done using symbolic names, but the use of literals themselves is sometimes encountered). Perhaps the author of foo did not see the need to expose this information or perhaps the shared value is purely coincidental.
If the two representations denote the same quantity doesn’t the second have a greater information content for a reader seeking deeper understanding?
In the following example:
... x + y & z ... ... ... num_red + num_white & lower_bits ... |
an experienced developer with a knowledge of English is likely to interpret the expression as adding the number of occurrences of two quantities and using bit-wise AND to extract the lower bits. For some readers the second expression has a higher information content. Would use of the names number_of_red further increase the information content?
In the following example the first expression has not added any information that was not already present in the first expression above (except perhaps that the author was not certain of the precedence or perhaps did not expect subsequent readers to be certain).
... ( x + y ) & z ... ... ... x + ( y & z ) ... |
The second expression uses parenthesis to achieve an operand/operator binding that is different from the default. Has this changed the information content of the expression?
There is experimental evidence that developers extract information from the names of variables to help them make decisions about operator precedence. To me the name all_32_bits_one suggests a sequence of bits and I would expect such a representation to be associated with the bit-wise AND operator, not binary plus. With no knowledge of the relative precedence of the two operators in the following expression the name of the middle operand would cause me to misinterpret the code. Does this change the information content of the expression? Does knowledge of the experimental evidence and the correct operator precedence change the information content (i.e., there is a potential fault in the code because the author may have assumed the incorrect precedence)?
... num_red + all_32_bits_one & sign_bit ... |
There is experimental evidence that people use the amount of whitespace appearing between operands and their operators to visually highlight operator precedence
The relative quantities of whitespace used in the following two expressions appear to tell very different stories. Do the two expressions have a different information content?
... x + y & z ... ... ... x + y & z ... |
The idea of measuring the information content of source code is very enticing. However, an accurate measure requires knowledge of the kind of information a reader is trying to obtain and of information that already exists in their brain.
Another question is the easy with which information can be extracted from code. Something that might be labeled as readability, except that readability has connotations of there being an abundant supply of information to extract.
Recent Comments