Archive
Experiment, replicate, replicate, replicate,…
Popular science writing often talks about how one experiment proved this-or-that theory or disproved ‘existing theories’. In practice, it takes a lot more than one experiment before people are willing to accept a new theory or drop an existing theory. Many, many experiments are involved, but things need to be simplified for a popular audience and so one experiment emerges to represent the pivotal moment.
The idea of one experiment being enough to validate a theory has seeped into the world view of software engineering (and perhaps other domains as well). This thinking is evident in articles where one experiment is cited as proof for this-or-that and I am regularly asked what recommendations can be extracted from the results discussed in my empirical software book (which contains very few replications, because they rarely exist). This is a very wrong.
A statistically significant experimental result is a positive signal that the measured behavior might be real. The space of possible experiments is vast and any signal that narrows the search space is very welcome. Multiple replication, by others and with variations on the experimental conditions (to gain an understanding of limits/boundaries), are needed first to provide confidence the behavior is repeatable and then to provide data for building practical models.
Psychology is currently going through a replication crisis. The incentive structure for researchers is not to replicate and for journals not to publish replications. The Reproducibility Project is doing some amazing work.
Software engineering has had an experiment problem for decades (the problem is lack of experiments), but this is slowly starting to change. A replication problem is in the future.
Single experiments do have uses other than helping to build a case for a theory. They can be useful in ruling out proposed theories; results that are very different from those predicted can require ideas to be substantially modified or thrown away.
In the short term (i.e., at least the next five years) the benefit of experiments is in ruling out possibilities, as well as providing general pointers to the possible shape of things. Theories backed by substantial replications are many years away.
Ability to remember code improves with experience
What mental abilities separate an expert from a beginner?
In the 1940s de Groot studied expertise in Chess. Players were shown a chess board containing various pieces and then asked to recall the locations of the pieces. When the location of the chess pieces was consistent with a likely game, experts significantly outperformed beginners in correct recall of piece location, but when the pieces were placed at random there was little difference in recall performance between experts and beginners. Also players having the rank of Master were able to reconstruct the positions almost perfectly after viewing the board for just 5 seconds; a recall performance that dropped off sharply with chess ranking.
The interpretation of these results (which have been duplicated in other areas) is that experts have learned how to process and organize information (in their field) as chunks, allowing them to meaningfully structure and interpret board positions; beginners don’t have this ability to organize information and are forced to remember individual pieces.
In 1981 McKeithen, Reitman, Rueter and Hirtle repeated this experiment, but this time using 31 lines of code and programmers of various skill levels. Subjects were given two minutes to study 31 lines of code, followed by three minutes to write (on a blank sheet of paper) all the code they could recall; this process was repeated five times (for the same code). The plot below shows the number of lines correctly recalled by experts (2,000+ hours programming experience), intermediates (just finished programming course) and beginners (just started programming course), left performance using ‘normal’ code and right is performance viewing code created by randomizing lines from ‘normal’ code; only the mean values in each category are available (code+data):
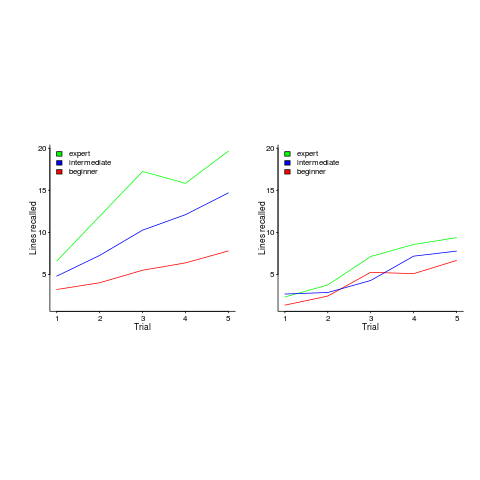
Experts start off remembering more than beginners and their performance improves faster with practice.
Compared to the Power law of practice (where experts should not get a lot better, but beginners should improve a lot), this technique is a much less time consuming way of telling if somebody is an expert or beginner; it also has the advantage of not requiring any application domain knowledge.
If you have 30 minutes to spare, why not test your ‘expertise’ on this code (the .c file, not the .R file that plotted the figure above). It’s 40 odd lines of C from the Linux kernel. I picked C because people who know C++, Java, PHP, etc should have no trouble using existing skills to remember it. What to do:
- You need five blank sheets of paper, a pen, a timer and a way of viewing/not viewing the code,
- view the code for 2 minutes,
- spend 3 minutes writing down what you remember on a clean sheet of paper,
- repeat until done 5 times.
Count how many lines you correctly wrote down for each iteration (let’s not get too fussed about exact indentation when comparing) and send these counts to me (derek at the primary domain used for this blog), plus some basic information on your experience (say years coding in language X, years in Y). It’s anonymous, so don’t include any identifying information.
I will wait a few weeks and then write up the data o this blog, as well as sharing the data.
Update: The first bug in the experiment has been reported. It takes longer than 3 minutes to write out all the code. Options are to stick with the 3 minutes or to spend more time writing. I will leave the choice up to you. In a test situation, maximum time is likely to be fixed, but if you have the time and want to find out how much you remember, go for it.
Power law of practice in software implementation
People get better with practice. The power law of practice specifies  , where:
, where:  is the response time,
is the response time,  the amount of practice and
the amount of practice and  ,
,  and
and  are constants. However, sometimes an exponential equation is a better fit for to the data:
are constants. However, sometimes an exponential equation is a better fit for to the data: } + c") . There are theoretical reasons for liking a power law (e.g., it can be derived from the chunking of information), but it is difficult to argue with the exponential fitting so much data better than a power law.
. There are theoretical reasons for liking a power law (e.g., it can be derived from the chunking of information), but it is difficult to argue with the exponential fitting so much data better than a power law.
The plot below, from a study by Alteneder, shows the time taken to solve the same jig-saw puzzle, for 35 trials (red); followed by a two week pause and another 35 trials (in blue; if anybody else wants to try this, a dedicated weekend should be long enough to complete over 20 trials). The lines are fitted power law and exponential equations (code+data). Can you tell which is which?
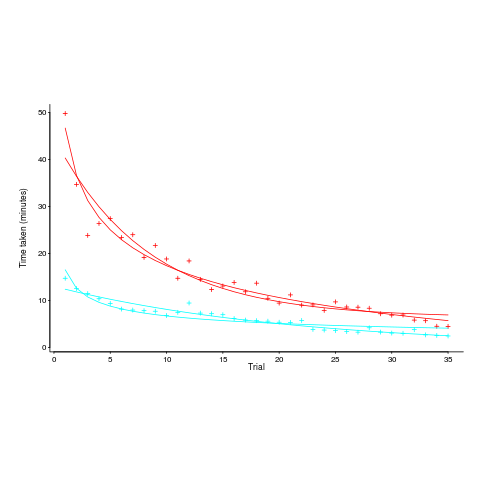
To find out if the same behavior occurs with software we need data on developers implementing the identical applications multiple times. I know of two experiments where the same application has been implemented multiple times by the same people, and where the data is available. Please let me know if you know of any others.
Zislis timed himself implementing 12 algorithms from the CACM collection in each of three languages, iterating four times (my copy came from the Purdue library, which as I write this is not listing the report). The large number of different programs implemented, coupled with the use of multiple languages, makes it difficult to separate out learning effects.
Lui and Chan ran an experiment where 24 developers (8 pairs {pair programming} and 8 singles) implemented the same application four times. The plot below shows the time taken to complete each implementation (singles top, pairs bottom, with black cross showing predictions made by a power law fit).
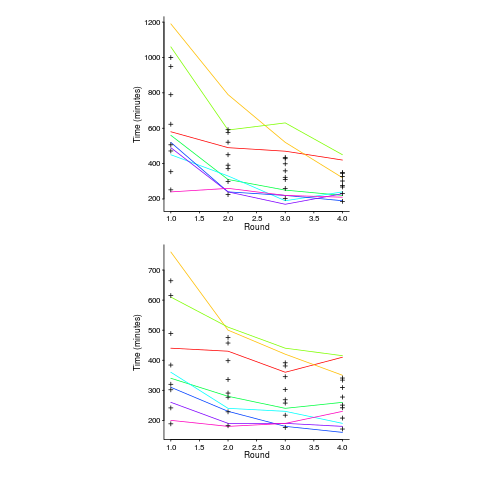
Different subjects start the experiment with different amounts of ability and past experience. Before starting, subjects took a multiple choice test of their knowledge. If we take the results of this test as a proxy for the ability/knowledge at the start of the experiment, then the power law equation becomes (a similar modification can be made to the exponential equation):
^{-b} + c")
That is, the test score is treated as equivalent to performing some number of rounds of implementation). A power law is a better fit than exponential to this data (code+data); the fit captures the general shape, but misses lots of what look like important details.
The experiment was run over successive weekends. So there was opportunity for some forgetting to occur during the week days, and the amount forgotten will vary between people. It is easy to think of other issues that could have influenced subject performance.
This experiment must rank as one of the most interesting software engineering experiments performed to date.
Least Recently Used: The experiment that made its reputation
Today we all know that least recently used is the best page replacement algorithm for virtual memory systems (actually paging is complicated in today’s intertwined computing world).
Virtual memory was invented in 1959 and researchers spent the 1960s trying to figure out the best page replacement algorithm.
Programs were believed to spend most of their time in loops and this formed the basis for the rationale for why FIFO, First In First Out, was the best page replacement algorithm (widely used at the time).
Least recently used, LRU, was on people’s radar as a possible technique and was mathematically analysed, along with various other techniques. The optimal technique was known and given the name OPT; a beautifully simple technique with one implementation drawback, it required knowledge of future memory usage behavior (needless to say some researchers set to work trying to predict future memory usage, so this algorithm could be used).
An experiment by Tsao, Comeau and Margolin, published in 1972, showed that LRU outperformed FIFO and random replacement. The rest, as they say, is history; in this case almost completely forgotten history.
The paper “A multifactor paging experiment: I. The experiment and the conclusions” was published as one of a collection of papers in “Statistical Computer Performance Evaluation” edited by Freiberger. A second paper by two of the authors in the same book outlines the statistical methodology. Appearing in a book means this paper can be very hard to track down. I recently bought a copy of the book on Amazon for one penny (the postage was £2.80).
The paper contains a copy of the experimental results and below are the page swap numbers:
loadseq group group group freq freq freq alpha alpha alpha Pages 24 20 16 24 20 16 24 20 16 LRU S 32 48 538 52 244 998 59 536 1348 LRU M 53 81 1901 112 776 3621 121 1879 4639 LRU L 142 197 5689 262 2625 10012 980 5698 12880 FIFO S 49 67 789 79 390 1373 85 814 1693 FIFO M 100 134 3152 164 1255 4912 206 3394 5838 FIFO L 233 350 9100 458 3688 13531 1633 10022 17117 RAND S 62 100 1103 111 480 1782 111 839 2190 RAND M 96 245 3807 237 1502 6007 286 3092 7654 RAND L 265 2012 12429 517 4870 18602 1728 8834 23134 |
Three Fortran programs were used, Small (55 statements), Medium (215 statements) and Large (595 statements). These programs were loaded by group (sequences of frequently called subroutines grouped together), freq (subroutines causing the most page swaps were grouped together), alpha (subroutines were grouped alphabetically).
The system was configured with either 24, 20 or 16 pages of 4,096 bytes; it had a total of 256K of memory (a lot of memory back then). The experiment consumed 60 cpu hours.
Looking at the table, it is easy to see that LRU has the best performance. In places random replacement beats FIFO. A regression model (code and data) puts numbers on the performance advantage.
The paper says that the only interaction was between memory size (i.e., number of pages) and how the programs were loaded. I found pairwise interaction between all variables, but then I am using a technique that was being invented as this paper was being published (see code for details).
Number of page swaps was one of three techniques used for measuring performed. The other two were activity count (average number of pages in main memory referenced at least once between page swaps) and inactivity count (average time, measured in page swaps, of a page in secondary storage after it had been swapped out). See data for details.
I vividly remember dropping in on a randomly chosen lecture in computer science in the mid-70s (I studied physics and electronics), the subject was page selection algorithms and there were probably only a dozen people in the room (physics and electronics sometimes had close to 100). The lecturer regaled those present with how surprising it was that LRU was the best and somebody had actually done an experiment showing this. Having a physics/electronics background, the experimental approach to settling questions was second nature to me.
The Empirical Investigation of Perspective-Based Reading: Data analysis
Questions about the best way to perform code reviews go back almost to the start of software development. The perspective-based reading approach focuses reviewers’ attention on the needs of the users of the document/code, e.g., tester, user, designer, etc, and “The Empirical Investigation of Perspective-Based Reading” is probably the most widely cited paper on the subject. This paper is so widely cited I decided it was worth taking the time to email the authors of a 20 year old paper asking if the original data was available and could I have a copy to use in a book I am working on. Filippo Lanubile’s reply included two files containing the data (original files, converted files+code)!
How do you compare the performance of different approaches to finding problems in documents/code? Start with experienced subjects, to minimize learning effects during the experiment (doing this also makes any interesting results an easier sell; professional developers know how unrealistic student performance tends to be); the performance of subjects using what they know has to be measured first, learning another technique first would contaminate any subsequent performance measurements.
In this study subjects reviewed four documents over two days; the documents were two NASA specifications and two generic domain specifications (bank ATM and parking garage); the documents were seeded with faults. Subjects were split into two groups and read documents in the following sequences:
Group 1 Group 2 Day 1 NASA A NASA B ATM PG Day 2 Perspective-based reading training PG ATM NASA B NASA A |
The data contains repeated measurements of the same subject (i.e., their performance on different documents using one of two techniques), so mixed-model regression has to be used to build a model.
I built two models, one for number of faults detected and the another for the number of false positive faults flagged (i.e., something that was not a fault flagged as a fault).
The two significant predictors of percentage of known faults detected were kind of document (higher percentage detected in the NASA documents) and order of document processing on each day (higher percentage reported on the first document; switching document kind ordering across groups would have enabled more detail to be teased out).
The false positive model was more complicated, predictors included number of pages reviewed (i.e., more pages reviewed more false positive reports; no surprise here), perspective-based reading technique used (this also included an interaction with number of years of experience) and kind of document.
So use of perspective-based reading did not make a noticeable difference (the false positive impact was in amongst other factors). Possible reasons that come to mind include subjects not being given enough time to switch reading techniques (people need time to change established habits) and some of the other reading techniques used may have been better/worse than perspective-based reading and overall averaged out to no difference.
This paper is worth reading for the discussion of the issues involved in trying to control factors that may have a noticeable impact on experimental results and the practical issues of using professional developers as subjects (the authors clearly put a lot of effort into doing things right).
Please let me know if you build any interesting model using the data.
Joke: Student subjects in software engineering experiments
Most academic experiments in software engineering use the students available to the researcher as subjects, often classifying first year as novices and final year or postgrads as experts. If professional developers (i.e., non-student) subjects are used the paper will trumpet this fact; talk of comparing novices and experts is the give-away for an all undergraduate subject line-up. Most computing academics don’t write much software, so they are blissfully ignorant that they and their students are novices compared to a professional developer with a couple of years experience.
Results from well designed and executed experiments can reasonably be extended to cover people who share the skills used by subjects in the experiment. Becoming an expert programmer takes several years of continuous (i.e., several hours a day) practice. Using real experts in a programming experiment means that no measurable change in programming skill will occur during the experiment, while novices are likely to noticeably learn during the experiment and thus introduce unwanted sources of variation into the results. Of course novices will also take longer and are likely to have patterns of behavior that are not yet been selectively tuned to something that works in practice.
There is also an elephant in the room of student subjects in software engineering; some of the students are never going to get jobs in software engineering because they are completely useless at it. How does a student manage to get a degree in a software related subject and be unemployable as a software engineer? Money. Students are attracted by the money and lifestyle they hear a job in software engineering will offer and many Universities are happy to treat the computing department as a cash cow by offering courses that allow students to concentrate on “strategic” subjects and avoid having to get involved in nitty gritty details like programming. The University is probably defrauding some students by accepting them for a software related degree course.
My experience is that professional developers are happy to donate some time to taking part in a software engineering experiment. They just have to be asked, of course I do have the advantage of actually knowing some professional software developers.
Evidence for the benefits of strong typing, where is it?
It is often claimed that writing software using a strongly typed programming language bestows worthwhile benefits. Those making the claims can sometimes be rather vague about exactly what the benefits are, while at other times appear willing to claim almost any benefit. What does the empirical evidence have to say (let’s ignore the what languages are strongly typed elephant in the room)?
Until recently there had been two empirical studies (plus a couple of language comparison experiments; one of the better ones involves the researcher timing himself implementing various algorithms in various languages; Zislis “An Experiment in Algorithm Implementation”), while in the last few years a group has been experimenting away in Germany (three’ish published data sets).
Measuring changes in developer performance caused by the use of different programming languages is very hard, some of the problems include:
- every person is different: a way needs to be found to take account of differences in subject ability/knowledge/characteristics,
- every problem is different: it may be easier to write a program to solve a problem using language X than using language Y,
- it is difficult to obtain experimental subjects.
The experimental procedure adopted by all the experiments discussed here is to:
- select two different languages or the same language modified to not support some type constructs,
- get students (mostly upper-undergraduates+graduates) to volunteer as experimental subjects,
- have each subject use one language to solve a problem and then use the other language to solve the same problem. Each subject is randomly assigned to a group using a given language order (the experiments start out with an equal number of subjects in each group, but not all subjects complete every problem),
- in some cases the previous step is repeated for new problems.
Having subjects solve the same problem twice creates the opportunity for learning to occur during the implementation of the first program and for this learning to improve performance during the second implementation. The experimental procedures employed generate information that can be used during the analysis of the data (in my case using a mixed-model in R; download code and all data) to factor this ordering effect into the created model.
So what are the results? In chronological order we have (if you know of anymore published work please tell me):
- Gannon “An Experimental Evaluation of Data Type Conversions”: Implemented compilers for two simple languages (think BCPL and BCPL+a string type and simple structures; by today’s standards one language is not quiet as weakly typed as the other). One problem had to be solved and this was designed to require the use of features available in both languages, e.g., a string oriented problem (final programs were between 50-300 lines). The result data included number of errors during development and number of runs needed to create a working program (this all happened in 1977, well before the era of personal computers, when batch processing was king).
There was a small language difference in number of errors/batch submissions; the difference was about half the size of that due to the order in which languages were used by subjects, both of which were small in comparison to the variation due to subject performance differences. While the language effect was small, it exists. To what extent Can the difference be said to be due to stronger typing rather than only one language having built in support for a string type? Who knows, no more experiments like this were performed for 20 years
- Prechelt & Tichy A Controlled Experiment to Assess the Benefits of Procedure Argument Type Checking: Used two C compilers, one K&R C (i.e., no argument checking of function calls) and the other ANSI C, with subjects solving one problem using both compilers; available output data was time taken by subjects to solve the problem.
Using the no argument checking compiler slowed implementation time by around 10%, about five times smaller than the variation in subject performance (there was an ordering effect of around 30%).
- Mayer, Kleinschmager & Hanenberg: Two experiments used different languages (Java and Groovy) and multiple problems; result data was time for subjects to complete the task (Do Static Type Systems Improve the Maintainability of Software Systems? An Empirical Study and An Empirical Study of the Influence of Static Type Systems on the Usability of Undocumented Software). No significant difference due to just language (surprisingly) but differences due to language order, but big differences due to language/problem interaction with some problems solved more quickly in Java and other more quickly in Groovy. Again large variation due to subject performance.
Another experiment used a single language (Java) and multiple problems involving making use of either Java’s generic types or non-generic types (“Do Developers Benefit from Generic Types?”). Again the only significant language difference effects occurred through interaction with other variables in the experiment (e.g., the problem or the language ordering) and again there were large variations in subject performance.
In summary, when a language typing/feature effect has been found its contribution to overall developer performance has been small.
I think some reasons that the effects of typing have been so small, or non-existent, include (I should declare my belief that strong typing is useful):
- the use of students as subjects. Most students have very little programming experience relative to professional developers (i.e., under 100 hours vs. thousands of hours). I can easily imagine many student subjects often finding the warnings produced by the type system more confusing than helpful. More experienced developers are in a position to make full use of what a type system offers, and researchers should try to use professional developers as subjects (it is not that hard to obtain such volunteers)
- the small size of the problems. Typing comes into its own when used to organize and control large amounts of code. I understand the constraints of running an experiment limit the amount of code involved.
Will incorrect answers be biased towards one arm of an if-statement?
Sometimes it is possible to deduce which arm of a nested if-statement will be executed by looking at the form of the conditional expression in the outer if-statement, as in:
if ((L < M) && (M < H)) if (L < H) ; // Execution always end up here else ; // dead code |
but not in:
if ((L > M) && (M < H)) if (L < H) ; // Could end up here else ; // or here |
I ran an experiment at the 2012 ACCU conference where subjects saw nested if-statements like those above and had to specify which arm of the nested if-statement would be executed.
Sometimes subjects gave an answer specifying one arm when in fact both arms are possible. Now dear reader, do you think these incorrect answers will specify the then arm 50% of the time and the else arm 50% or do you think that that incorrect answers will more often specify one particular arm?
Of course I should have thought about this before I started to analyse the data, but this question is unrelated to the subject of the experiment and has only just cropped up because of the unexpectedly high percentage of this kind of incorrect answer. I had an idea what the answer would be but did not stop and think about relative percentages, rushing off to write a few lines of code to print the actual totals, so now my mind is polluted by knowing the answer (well at least for one group of subjects in one experiment).
Why does this “one arm preference” issue matter? The Bayesians out there will insist that the expected distribution (the prior in Bayesian terminology) of incorrectly chosen arms be factored in to the calculation of the probability of getting the numbers seen in the results. The paper Belgian euro coins: 140 heads in 250 tosses – suspicious? gives a succinct summary of the possibilities.
So I have decided to appeal to my experienced readership, yes YOU!
For those questions where the actual execution cannot be predicted in advance, from knowledge of the relative values of variables appearing in the outer if-statement, when an incorrect answer is given should the analysis assume:
- a 50/50 split of incorrect answers between each arm, or
- subjects are more likely to pick one arm; please specify a percentage breakdown between arms.
No pressure, but the submission deadline is very late tomorrow.
The results from the whole experiment will get written up here in future posts.
Update (three days later): Nobody was willing to stick their head above the parapet 🙁
There were 69 correct answers and 16 incorrect answers to questions whose answer was “both arm”. Ten of those incorrect answers specified the ‘then’ arm and 6 the ‘else’; my gut feeling was that there should be even more ‘then’ answers. If there was no “first arm” there is an equal probability of a subject’s incorrect answer appearing in either arm; in this case the probability of a 10/6 split is 12% (so my gut feeling was just hunger pangs after all).
Agreement between code readability ratings given by students
I have previously written about how we know nothing about code readability and questioned how the information content of expressions might be calculated. Buse and Weimer ran a very interesting experiment that asked subjects to rate short code snippets for readability (somebody please rerun this experiment using professional software developers).
I’m interested in measuring how well different students subjects agree with each other (I have briefly written about this before).
Short answer: Very little agreement between individual pairs, good agreement between rankings aggregated by year.
The longer answer is below as another draft section from my book Empirical software engineering with R book. As always comments welcome. R code and data here.
Readability
Source code is often said to have an attribute known as
A study by Buse and Weimer <book Buse_08> asked Computer Science students to rate short snippets of Java source code on a scale of 1 to 5. Buse and Weimer then searched for correlations between these ratings and various source code attributes they obtained by measuring the snippets.
Humans hold diverse opinions, have fragmented knowledge and beliefs about many topics and vary in their cognitive abilities. Any study involving human evaluation that uses an open ended problem on which subjects have had little experience is likely to see a wide range of responses.
Readability is a very nebulous term and students are unlikely to have had much experience working with source code. A wide range of responses is to be expected and the analysis performed here aims to check the degree of readability rating agreement between the subjects.
Data
The data made available by Buse and Weimer are the ratings, on a scale of 1 to 5, given by 121 students to 100 snippets of source code. The student subjects were drawn from those taking first, second and third/fourth year Computer Science degree courses and postgraduates at the researchers’ University (17, 65, 31 and 8 subjects respectively).
The postgraduate data was not used in this analysis because of the small number of subjects.
The source of the code snippets is also available but not used in this analysis.
Is the data believable?
The subjects were not given any instructions on how to rate the code snippets for readability. Also we don’t know what outcome they were trying to achieve when rating, e.g., where they rating on the basis of how readable they personally found the snippets to be, or rating on the basis of the answer they would expect to give if they were being tested in an exam.
The subjects were students who are learning about software development and many of them are unlikely to have had any significant development experience outside of the teaching environment. Experience shows that students vary significantly in their ability to read and write source code and a non-trivial percentage do not go on to become software developers.
Because the subjects are at an early stage of learning about code it is to be expected that their opinions about readability will change while they are rating the 100 snippets. The study did not include multiple copies of some snippets, this would have enabled the consistency of individual subject responses to be estimated.
The results of many studies <book Annett_02> has shown that most subject ratings are based on an ordinal scale (i.e., there is no fixed relationship between the difference between a rating of 2 and 3 and a rating of 3 and 4), that some subjects are be overly generous or miserly in their rating and that without strict rating guidelines different subjects apply different criteria when making their judgements (which can result a subject providing a list of ratings that is inconsistent with every other subject).
Readability is one of those terms that developers use without having much idea what they and others are really referring to. The data from this study can at most be regarded as treating readability to be whatever each subject judges it to be.
Predictions made in advance
Is the readability rating given to code snippets consistent between different students on a computer science course?
The hypothesis is that the between student consistency of the readability rating given to code snippets improves as students progress through the years of attending computer science courses.
Applicable techniques
There are a variety of techniques for estimating rater agreement. <Krippendorff’s alpha> can be applied to ordinal ratings given by two or more raters and is used here.
Subjects do not have to give the same rating to share some degree of consistent response. Two subjects may share a similar pattern of increasing/decreasing/stay the same ratings across snippets. The <Spearman rank correlation> coefficient can be used to measure the correlation between the rank (i.e., relative value within sequence) of two sequences.
Results
When creating the snippets the researchers had no method of estimating what rating subjects would give to them and so there is no reason to expect a uniform distribution of rating values or any other kind of distribution of rating values.
The figure below is a boxplot of the rating of the first 50 code snippets rated by second year students and suggests that many subject ratings are within ±1 of each other.
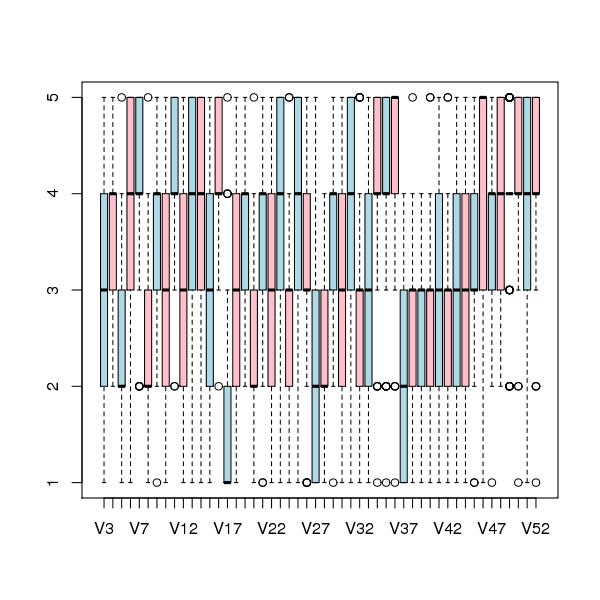
Figure 1. Boxplot of ratings given to snippets 1 to 50 by second year students (colors used to help distinguish boxplots for each snippet).
Between subject rating agreement
The Krippendorff alpha and mean Spearman rank correlation coefficient (the coefficient is calculated for every pair of subjects and the mean value taken) was obtained using the kripp.alpha and meanrho functions from the irr package (a <Jackknife> was used to obtain the following 95% confidence bounds):
Krippendorff's alpha cs1: 0.1225897 0.1483692 cs2: 0.2768906 0.2865904 cs4: 0.3245399 0.3405599 mean Spearman's rho cs1: 0.1844359 0.2167592 cs2: 0.3305273 0.3406769 cs4: 0.3651752 0.3813630 |
Taken as a whole there is a little of agreement. Perhaps there is greater consensus on the readability rating for a subset of the snippets. Recalculating using only using those snippets whose rated readability across all subjects, by year, has a standard deviation less than 1 (around 22, 51 and 62% of snippets respectively) shows some improvement in agreement:
Krippendorff's alpha cs1: 0.2139179 0.2493418 cs2: 0.3706919 0.3826060 cs4: 0.4386240 0.4542783 mean Spearman's rho cs1: 0.3033275 0.3485862 cs2: 0.4312944 0.4443740 cs4: 0.4868830 0.5034737 |
Between years comparison of ratings
The ratings from individual subjects is only available for one of their years at University. Aggregating the answers from all subjects in each year is one method of obtaining readability information that can be used to compare the opinions of students in different years.
How can subject ratings be aggregated to rank the 100 code snippets in order of what a combined group consider to be readability? The relatively large variation in mean value of the snippet ratings across subjects would result in wide confidence bounds for an aggregate based on ratings. Mapping each subject’s rating to a ranking removes the uncertainty caused by differences in mean subject ratings.
With 100 snippets assigned a rating between 1 and 5 by each subject there are going to be a lot of tied rankings. If, say, a subject gave 10 snippets a rating of 5 the procedure used is to assign them all the rank that is the mean of the ranks the 10 of them would have occupied if their ratings had been very slightly different, i.e., (1+2+3+4+5+6+7+8+9+10)/10 = 5.5. This process maps each students readability ratings to readability rankings, the next step is to aggregate these individual rankings.
The R_package[RankAggreg] package contains a variety of functions for aggregating a collection rankings to obtain a group ranking. However, these functions use the relative order of items in a vector to denote rank, and this form of data representations prevents them supporting ranked lists containing items having the same rank.
For this analysis a simple aggregate ranking algorithm using Borda’s method <book lin_10> was implemented. Borda’s method for creating an aggregate ranking operates on one item at a time, combining all of the subject ranks for that item into a single rank. Methods for combining ranks include taking their mean, their geometric mean and the square-root of the sum of their squares; the mean value was used for this analysis.
An aggregate ranking was created for subjects in years one, two and four and the plot below compares the ranking between 1st/2nd year students (left) and 2nd/4th year students (right). The order of the second year student snippet rankings have been sorted and the other year rankings for the snippets mapped to the corresponding position.
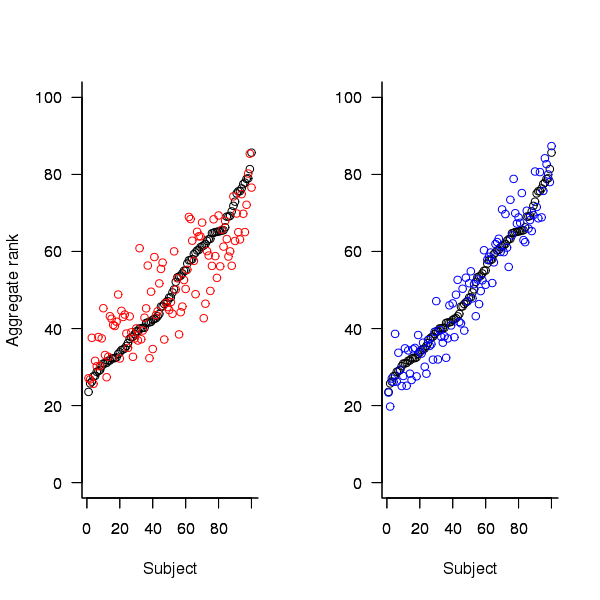
Figure 2. Aggregated ranking of snippets by subjects in years 1 and 2 (red and black) and years 2 and 4 (black and blue). Snippets have been sorted by year 2 ranking.
The above plot seems to show that at the aggregated year level there is much greater agreement between the 2nd/4th years than any other year pairing and measuring the correlation between each of the years using <Kendall’s tau>:
cs1.tau cs2.tau cs3.tau 0.6627602 0.6337914 0.8199636 |
confirms the greater agreement between this aggregate year pair.
Individual subject correlation to year aggregate ranking
To what extend to subject ratings correlate with their corresponding year aggregate? The following plot gives the correlation, using Kendall’s tau, between each subject and their corresponding year aggregate ranking.
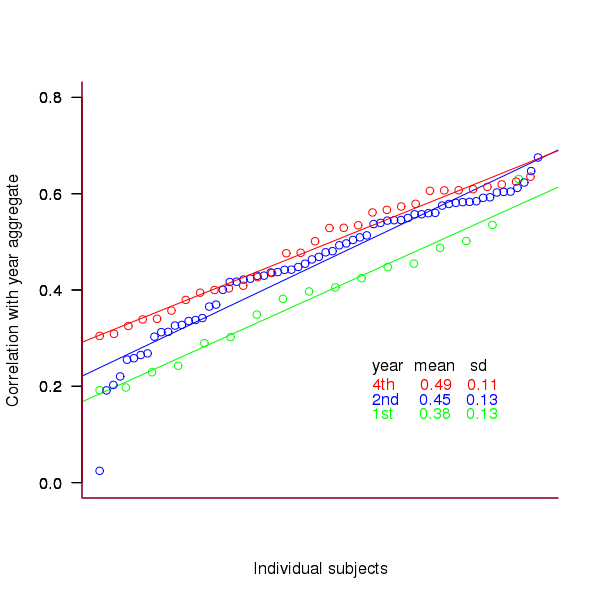
Figure 3. Correlation, using Kendall’s tau, between each subject and their corresponding year aggregate ranking.
The least squares fit shows that the variation in correlation across subjects in any year is very similar (removal of outliers in year 2 would make the lines almost parallel); the mean again shows a correlation that increases with year.
Discussion
The extent to which this study’s calculated values of rater agreement and correlation are considered worthy of further attention depends on the use to which the results will be put.
- From the perspective of trained raters the subject agreement in this study is very low and the rating have no further use.
- From the research perspective the results show that the concept of readability in the computer science student population has some non-zero substance to it that might be worth further study.
- From an overall perspective this study provides empirical evidence for a general lack of consensus on what constitutes readability.
It is not surprising that there is little agreement between student subjects on their readability rating, they are unlikely to have had much experience reading code and have not had any training in rating code for readability.
Professional developers will have spent years working with code and this experience is likely to have resulted in the creation of stable opinions on code readability. While developers usually work with code that is much longer than the few lines contained in the snippets used by Buse and Weimer, this experiment format is easy to administer and supports a fine level of control, i.e., allows a small set of source attributes of interest to be presented while excluding those not of interest. Repeating this study using such people as subjects would show whether this experience results in convergence to general agreement on the readability rating of code.
Summary of findings
The agreement between students readability ratings, for short snippets of code, improves as the students progress through course years 1 to 4 of a computer science degree.
While there is very good aggregated group agreement on the relative ranking of the readability of code snippets there is very little agreement between pairs of individuals.
- Two students chosen at random from within a year will have a low Spearman rank correlation coefficient for their rating of code snippet readability.
- Taken as a yearly aggregate there is a high degree of agreement between years two and four and less, but still good agreement between year 1 and other years.
- There is a broad range of correlations, from poor to good, between year aggregates and student subjects in the corresponding year.
Impact of hardware characteristics on detectable fault behavior
Preface. This is the first of what I hope will be many posts analysing experimental data, that will eventually end up in my empirical software engineering with R book (this experiment was chosen because it happens to be the one I am currently working on; having just switched to using Asciidoc I have a backlog of editing to do on previously written analysis, also I have to figure out a way to fix [bracketed words]).
Don’t worry if you don’t know anything about the statistics used. I am aiming to provide information to meet the needs of two audiences (whether or not I fail on both counts remains to be seen):
- Those who want to some idea of what facts are known about a particular software engineering topic. Hopefully reading the introduction+conclusion will enable these readers to form an opinion about the current state of knowledge (taking my statistical analysis on trust).
- Those who are looking for ideas that can be used to analyse a problem they are trying to solve. Hopefully, somewhere among my many analyses will be something that looks like it could be applied to the reader’s problem and motivates them to go off and learn something about the statistics (if they are not already familiar with it; once written the book will obviously help out here).
Forward. The following analysis produces a negative result, something that happens a lot in experiments in all fields of research. It has been included to illustrate the importance of checking the statistical power of an experiment, i.e., how likely the experiment will detect an effect if one is present; it is very easy to fall into the trap of thinking that because lots of tests were done any effect that exists will be detected.
The authors ran an interesting experiment which as far as I know is the only published empirical analysis of intermittent software faults (please let me know if you are aware of other work) and made some mistakes in their statistical analysis. I have made plenty of mistakes in experiments I have run, some of which have found there way into the published write up. The key attribute of an experimentalist is to learn and move on.
A fault does not always noticeably change the behavior of a program when it is executed, apparently correct program execution can occur in the presence of serious faults.
A study by Syed, Robinson and Williams <book Syed_10> investigated how the number of noticeable failures caused by known faults in Mozilla’s Firefox browser varied with processor speed, system memory, hard disc size and system load. A total of 11 known faults causing intermittent failure were selected and nine different hardware configurations were selected. The conditions required to exhibit each fault were replicated and Firefox was executed 10 times for each of hardware configuration, counting the number of noticeable program failures; the seven faults and nine hardware configurations listed in the table below generated a total of 10*7*9 = 630 different executions (four faults either always or never resulted in an observed failure during the 10 runs).
Data
The following table contains the observed number of failures of Firefox for the given fault number when run on the specified hardware configuration.
| Mhz-Mb-Gb | 124750 | 380417 | 410075 | 396863 | 494116 | 264562 | 332330 |
|---|---|---|---|---|---|---|---|
|
667-128-2.5 |
4 |
10 |
6 |
5 |
2 |
3 |
5 |
|
667-256-10 |
4 |
8 |
8 |
6 |
4 |
3 |
8 |
|
667-1000-2.5 |
4 |
7 |
3 |
4 |
3 |
1 |
8 |
|
1000-128-10 |
3 |
10 |
3 |
6 |
0 |
1 |
1 |
|
1000-256-2.5 |
3 |
9 |
0 |
6 |
0 |
1 |
2 |
|
1000-1000-10 |
2 |
9 |
4 |
5 |
0 |
0 |
1 |
|
2000-128-2.5 |
0 |
10 |
5 |
6 |
0 |
0 |
0 |
|
2000-256-10 |
2 |
8 |
5 |
7 |
0 |
0 |
0 |
|
2000-1000-10 |
1 |
7 |
3 |
5 |
0 |
0 |
0 |
Predictions made in advance
There is no prior theory suggesting how the selected hardware characteristics might influence the outcome from this experiment. The analysis is based on searching for a pattern in the results and so the significance level needs to be adjusted to take account of the number of possible patterns that could exist (e.g., using the [Bonferroni correction]).
If we simplify the failure counts by labelling them as one of Low/Medium/High, then there are two arrangements of the failure counts (i.e., low/medium/high and high/medium/low) that would result in a strong correlation for cpu_speed, two arrangements for memory and two for disc size; a total of 6 combinations that would result in a strong correlation being found.
The [Bonferroni correction] adjusts the significance level by dividing by the number of tests, in this case 0.05/6 = 0.0083.
If the failure counts occurred in a random order what is the probability of a strong correlation between failure count and one of the hardware attributes being found? Based on the Low/Medium/High labelling scheme there are 9!/(3! 3! 3!) = 1680 combinations of these counts over 9 slots, giving a 1 in 1680/6 = 280 chance of purely random behavior producing a strong correlation.
The experiment investigated the characteristics of 11 faults. If there is a 1 in 280 chance of finding a strong correlation when analyzing one fault there is approximately a 1 in 24 chance of finding at least one strong correlation when analysing 11 different faults.
Response variable
The response variable takes the form of a proportion whose value varies between 0 and 1, the number of failures out of 10 executions.
Applicable techniques
The following techniques might be used to analyse this data:
- [Factorial design]. This is a way of organizing experiment configurations that is designed to extract the most information for the total number of program runs made. It would be inefficient not to use the results from some hardware configurations just because they are not needed in the factorial design and no results are available for some configurations required by a factorial design (or a [Plackett-Burman] design).
-
Fitting the data using a linear model. A standard linear model, created using R’s lm function, would not be appropriate because of the following two problems:
- this kind of model is likely to make predictions that fall outside the range 0 to 1, something that cannot happen for proportional data,
- this approach assumes that the variance is constant across measurements and unless the proportions involved are very close to each other this requirement will not be met ([proportional data] from a [binomial distribution] has variance p(1-p)).
However, a generalised linear model would not suffer from these problems. There are several [link functions] that could be used:
- the Poisson distribution, is widely used for modelling faults but requires that the mean and variance have the same value, a property that does not apply to proportional data.
- the Binomial distribution, can handle data having the characteristics present here.
The proportional data is specified in the call to the glm function by having the response variable contain two columns, one containing the number of failures (that is what is being predicted in this case) and the other the number of non-failures. The code looks something like the following (see complete example and data):
y=cbind(fail_count, 10-fail_count) glm(y ~ cpu_speed+memory+disk_size, data=ff_data, family=binomial) |
In this kind of GLM it is assumed that the [residual deviance] is the same as the [residual degrees of freedom]. If the residual deviance is greater than the residual degrees of freedom then [overdispersion] has occurred, which happens for fault 380417. To handle overdispersion the family needs to be changed from binomial to quasibinomial, which in the case of fault 380417 changes the p-value of the fit from 0.0348 to 0.0749.
The analysis of each fault finds that only one of them, 332330, has a significance level within the specified acceptable bounds; this has a negative correlation with CPU speed (i.e., observed failures decrease with clock speed).
With only one faults found to have any significant hardware configuration effects we have to ask about the probability of this experiment finding an effect if one was present.
An analysis of the [statistical power] of an experiment investigating the difference between proportions for two hardware configurations (i.e., the percentage of observed failures) needs to know the value of those proportions, the number of runs (10 in this case) and the desired p-value (0.05); to simplify things the plot below is based on using the value of the lowest proportion and the difference between it and the higher proportion. The left plot shows the power achieved (y-axis) there does exist a given difference in proportions (x-axis), the three lowest proportions of 0.05, 0.25 and 0.5 are shown (the result is symmetric about 0.5 and so the plot for 0.75 and 0.95 would be the same as 0.25 and 0.05 respectively), and where there were 10 and 50 runs involving the same fault case.
It can be seen that unless a change in the hardware configuration causes a large change in the number of visible failures then the chance of a difference being detected in results from 10 runs is well below 0.5 (i.e., less than a 50% chance of detecting a difference at a p-value of 0.05 or better).
The right plot in the figure gives the number of runs that need to be made to have a 80% chance of detecting, between two different hardware configurations, the difference in proportion listed on the x-axis, at a significance of 0.05.
It can be seen that if hardware charactersitics account for only 10% of the difference in failure rate over 100 runs would be needed to detect it.
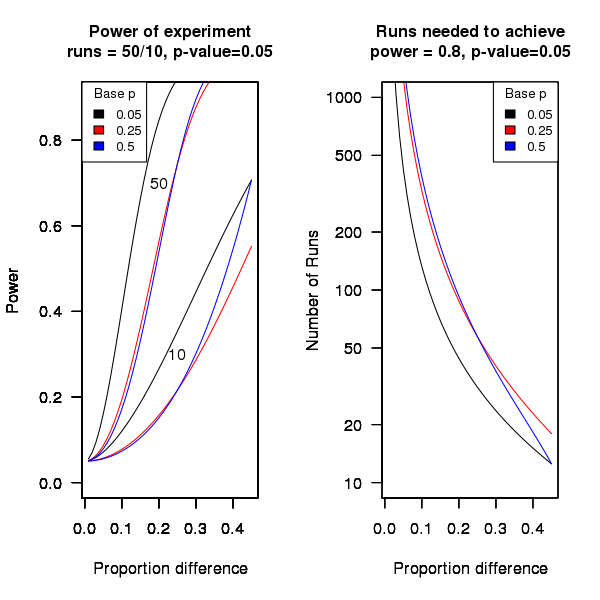
Conclusion
Faults in Firefox that caused intermittent failures were investigated looking for a correlation with system cpu speed, memory or disc size. One fault showed a strong correlation with cpu speed (there is a 1 in 24 chance that one of the investigated faults would have some kind of strong correlation). This experiment may not have found a significant correlation between observed failure rate and hardware configuration because the number of separate runs for each fault (i.e., 10) had [low power].
Recent Comments