Archive
Estimating using a granular sequence of values
When asked for an estimate of the time needed to complete a task, should developers be free to choose any numeric value, or should they be restricted to selecting from a predefined set of values (e.g, the Fibonacci numbers, or T-shirt sizes)?
Allowing any value to be chosen would appear to provide the greatest flexibility to make an accurate estimate. However, estimating is an intrinsically uncertain process (i.e., the future is unknown), and it is done by people with varying degrees of experience (which might be used to help guide their prediction about the future).
Restricting the selection process to one of the values in a granular sequence of numbers has several benefits, including:
- being able to adjust the gaps between permitted values to match the likely level of uncertainty in the task effort, or the best accuracy resolution believed possible,
- reducing the psychological stress of making an estimate, by explicitly giving permission to ignore the smaller issues (because they are believed to require a total effort that is less than the sequence granularity),
- helping to maintain developer self-esteem, by providing a justification when an estimate turning out to be inaccurate, e.g., the granularity prevented a more accurate estimate being made.
Is there an optimal sequence of granular values to use when making task estimates for a project?
The answer to this question depends on what is attempting to be optimized.
Given how hard it is to get people to produce estimates, the first criterion for an optimal sequence has to be that people are willing to use it.
I have always been struck by the ritualistic way in which the Fibonacci sequence is described by those who use it to make estimates. Rituals are an effective technique used by groups to help maintain members’ adherence to group norms (one of which might be producing estimates).
A possible reason for the tendency to use round numbers might estimate-values is that this usage is common in other social interactions involving numeric values, e.g., when replying to a request for the time of day.
The use of round numbers, when developers have the option of selecting from a continuous range of values, is a developer imposed granular sequence. What form do these round number sequences take?
The plot below shows the values of each of the six most common round number estimates present in the BrightSquid, SiP, and CESAW (project 615) effort estimation data sets, plus the first six Fibonacci numbers (code+data):
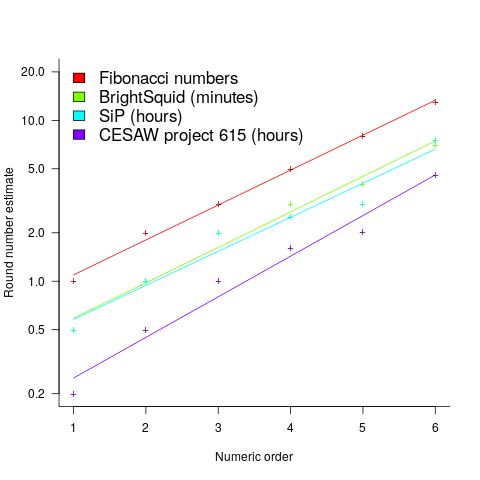
The lines are fitted regression models having the form:  (there is a small variation in the value of the constant; the smallest value for project 615 was probably calculated rather than being human selected).
(there is a small variation in the value of the constant; the smallest value for project 615 was probably calculated rather than being human selected).
This plot shows a consistent pattern of use across multiple projects (I know of several projects that use Fibonacci numbers, but don’t have any publicly available data). Nothing is said about this pattern being (near) optimal in any sense.
The time unit of estimation for this data was minutes or hours. Would the equation have the same form if the time unit was days, would the constant still be around  . I await the data needed to answer this question.
. I await the data needed to answer this question.
This brief analysis looked at granular sequences from the perspective of the distribution of estimates made. Perhaps it makes more sense to base a granular estimation sequence on the distribution of actual task effort. A topic for another post.
What is known about software effort estimation in 2021
What do we know about software effort estimation, based on evidence?
The few publicly available datasets (e.g., SiP, CESAW, and Renzo) involve (mostly) individuals estimating short duration tasks (i.e., rarely more than a few hours). There are other tiny datasets, which are mostly used to do fake research. The patterns found across these datasets include:
- developers often use round-numbers,
- the equation:
 , where
, where  is a constant that varies between projects, often explains around 50% of the variance present in the data. This equation shows that developers under-estimate short tasks and over-estimate long tasks. The exponent,
is a constant that varies between projects, often explains around 50% of the variance present in the data. This equation shows that developers under-estimate short tasks and over-estimate long tasks. The exponent,  , applies across most projects in the data,
, applies across most projects in the data, - individuals tend to either consistently over or under estimate,
- developer estimation accuracy does not change with practice. Possible reasons for this include: variability in the world prevents more accurate estimates, developers choose to spend their learning resources on other topics.
Does social loafing have an impact on actual effort? The data needed to answer this question is currently not available (the available data mostly involves people working on their own).
When working on a task, do developers follow Parkinson’s law or do they strive to meet targets?
The following plot suggests that one or the other, or both are true (data):
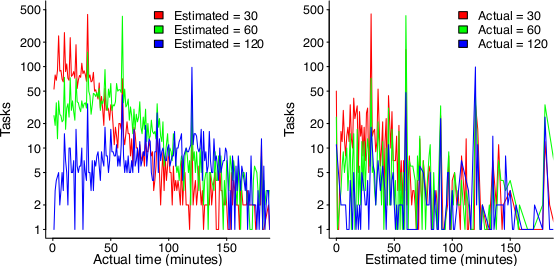
On the left: Each colored lines shows the number of tasks having a given actual implementation time, when they were estimated to take 30, 60 or 120 minutes (the right plot reverses the role of estimate/actual). Many of the spikes in the task counts are at round numbers, suggesting that the developer has fixated on a time to finish and is either taking it easy or striving to hit it. The problem is distinguishing them mathematically; suggestions welcome.
None of these patterns of behavior appear to be software specific. They all look like generic human behaviors. I have started emailing researchers working on project analytics in other domains, asking for data (no luck so far).
Other patterns may be present for many projects in the existing data, we have to wait for somebody to ask the right question (if one exists).
It is also possible that the existing data has some unusual characteristics that don’t apply to most projects. We won’t know until data on many more projects becomes available.
Delphi and group estimation
A software estimate is a prediction about the future. Software developers were not the first people to formalize processes for making predictions about the future. Starting in the last 1940s, the RAND Corporation’s Delphi project created what became known as the Delphi method, e.g., An Experiment in Estimation, and Construction of Group Preference Relations by Iteration.
In its original form experts were anonymous; there was a “… deliberate attempt to avoid the disadvantages associated with more conventional uses of experts, such as round-table discussions or other milder forms of confrontation with opposing views.”, and no rules were given for the number of iterations. The questions involved issues whose answers involved long term planning, e.g., how many nuclear weapons did the Soviet Union possess (this study asked five questions, which required five estimates). Experts could provide multiple answers, and had to give a probability for each being true.
One of those involved in the Delphi project (Helmer-Hirschberg) co-founded the Institute for the Future, which published reports about the future based on answers obtained using the Delphi method, e.g., a 1970 prediction of the state-of-the-art of computer development by the year 2000 (Dalkey, a productive member of the project, stayed at RAND).
The first application of Delphi to software estimation was by Farquhar in 1970 (no pdf available), and Boehm is said to have modified the Delphi process to have the ‘experts’ meet together, rather than be anonymous, (I don’t have a copy of Farquhar, and my copy of Boehm’s book is in a box I cannot easily get to); this meeting together form of Delphi is known as Wideband Delphi.
Planning poker is a variant of Wideband Delphi.
An assessment of Delphi by Sackman (of Grant-Sackman fame) found that: “Much of the popularity and acceptance of Delphi rests on the claim of the superiority of group over individual opinions, and the preferability of private opinion over face-to-face confrontation.” The Oracle at Delphi was one person, have we learned something new since that time?
Group dynamics is covered in section 3.4 of my Evidence-based software engineering book; resource estimation is covered in section 5.3.
The likelihood that a group will outperform an individual has been found to depend on the kind of problem. Is software estimation the kind of problem where a group is likely to outperform an individual? Obviously it will depend on the expertise of those in the group, relative to what is being estimated.
What does the evidence have to say about the accuracy of the Delphi method and its spinoffs?
When asked to come up with a list of issues associated with solving a problem, groups generate longer lists of issues than individuals. The average number of issues per person is smaller, but efficient use of people is not the topic here. Having a more complete list of issues ought to be good for accurate estimating (the validity of the issues is dependent on the expertise of those involved).
There are patterns of consistent variability in the estimates made by individuals; some people tend to consistently over-estimate, while others consistently under-estimate. A group will probably contain a mixture of people who tend to over/under estimate, and an iterative estimation process that leads to convergence is likely to produce a middling result.
By how much do some people under/over estimate?
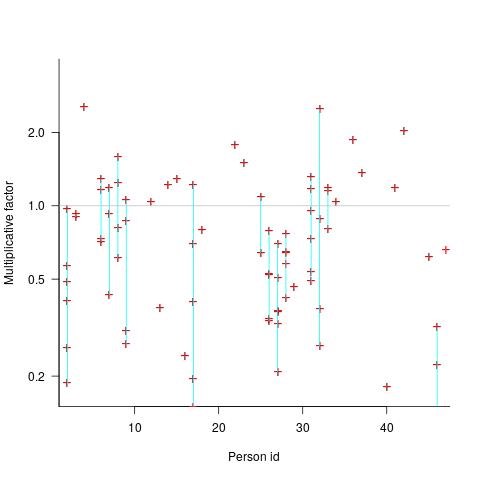
The multiplicative factor values (y-axis) appearing in the plot below are from a regression model fitted to estimate/actual implementation time for a project involving 13,669 tasks and 47 developers (data from a study Nichols, McHale, Sweeney, Snavely and Volkmann). Each vertical line, or single red plus, is one person (at least four estimates needed to be made for a red plus to occur); the red pluses are the regression model’s multiplicative factor for that person’s estimates of a particular kind of creation task, e.g., design, coding, or testing. Points below the grey line are overestimation, and above the grey line the underestimation (code+data):
What is the probability of a Delphi estimate being more accurate than an individual’s estimate?
If we assume that a middling answer is more likely to be correct, then we need to calculate the probability that the mix of people in a Delphi group produces a middling estimate while the individual produces a more extreme estimate.
I don’t have any Wideband Delphi estimation data (or rather, I only have tiny amounts); pointers to such data are most welcome.
Estimate variability for the same task
If 100 people estimate the time needed to implement a feature, in software, what is the expected variability in the estimates?
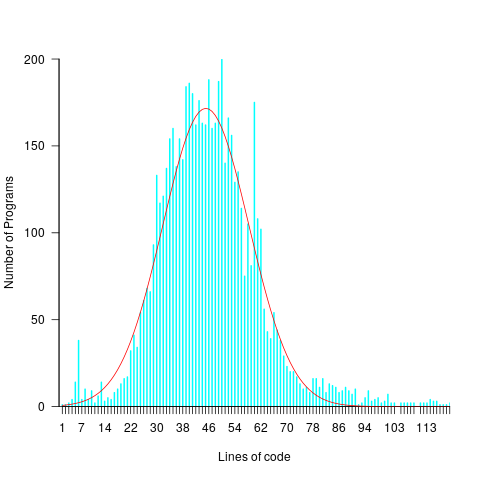
Studies of multiple implementations of the same specification suggest that standard deviation of the mean number of lines across implementations is 25% of the mean (based on data from 10 sets of multiple implementations, of various sizes).
The plot below shows lines of code against the number of programs (implementing the 3n+1 problem) containing that many lines (red line is a Normal distribution fitted by eye, code and data):
Might any variability in the estimates for task implementation be the result of individuals estimating their own performance (which is variable)?
To the extent that an estimate is based on a person’s implementation experience, a developer’s past performance will have some impact on their estimate. However, studies have found a great deal of variability between individual estimates and their corresponding performance.
One study asked 14 companies to bid on implementing a system (four were eventually chosen to implement it; see figure 5.2 in my book). The estimated elapsed time varied by a factor of ten. Until the last week this was the only study of this question for which the data was available (and may have been the only such study).
A study by Alhamed and Storer investigated crowd-sourcing of effort estimates, structured by use of planning poker. The crowd were workers on Amazon’s Mechanical Turk, and the tasks estimated came from the issue trackers of JBoss, Apache and Spring Integration (using issues that had been annotated with an estimate and actual time, along with what was considered sufficient detail to make an estimate). An initial set of 419 issues were whittled down to 30, which were made available, one at a time, as a Mechanical Turk task (i.e., only one issue was available to be estimated at any time).
Worker estimates were given using a time-based category (i.e., the values 1, 4, 8, 20, 40, 80), with each value representing a unit of actual time (i.e., one hour, half-day, day, half-week, week and two weeks, respectively).
Analysis of the results from a pilot study were used to build a model that detected estimates considered to be low quality, e.g., providing a poor justification for the estimate. These were excluded from any subsequent iterations.
Of the 506 estimates made, 321 passed the quality check.
Planning poker is an iterative process, with those making estimates in later rounds seeing estimates made in earlier rounds. So estimates made in later rounds are expected to have some correlation with earlier estimates.
Of the 321 quality check passing estimates, 153 were made in the first-round. Most of the 30 issues have 5 first-round estimates each, one has 4 and two have 6.
Workers have to pick one of five possible value as their estimate, with these values being roughly linear on a logarithmic scale, i.e., it is not possible to select an estimate from many possible large values, small values, or intermediate values. Unless most workers pick the same value, the standard deviation is likely to be large. Taking the logarithm of the estimate maps it to a linear scale, and the plot below shows the mean and standard deviation of the log of the estimates for each issue made during the first-round (code+data):

The wide spread in the standard deviations across a spread of mean values may be due to small sample size, or it may be real. The only way to find out is to rerun with larger sample sizes per issue.
Now it has been done once, this study needs to be run lots of times to measure the factors involved in the variability of developer estimates. What would be the impact of asking workers to make hourly estimates (they would not be anchored by experimenter specified values), or shifting the numeric values used for the categories (which probably have an anchoring effect)? Asking for an estimate to fix an issue in a large software system introduces the unknown of all kinds of dependencies, would estimates provided by workers who are already familiar with a project be consistently shifted up/down (compared to estimates made by those not familiar with the project)? The problem of unknown dependencies could be reduced by giving workers self-contained problems to estimate, e.g., the 3n+1 problem.
The crowdsourcing idea is interesting, but I don’t think it will scale, and I don’t see many companies making task specifications publicly available.
To mimic actual usage, research on planning poker (which appears to have non-trivial usage) needs to ensure that the people making the estimates are involved during all iterations. What is needed is a dataset of lots of planning poker estimates. Please let me know if you know of one.
Recent Comments