Archive
Employment in the software business: we know nothing
Tens of millions of people get paid to work on the creation and maintenance of software systems, by companies employing thousands of developers to those employing a single developer (in the UK there are almost 300K registered software companies; 5% of registered companies).
This huge ecosystem is almost completely ignored by the software engineering research community. Academics in computing/software are more interested in technical issue, and industry is an ecosystem they rarely interact with (some claim that student employment keeps them in contact with industry).
There are researchers in business and economics departments who study employment, e.g., careers, organization of workers and companies. The scientific study of work started at the beginning of the 1900s, originally focused on the manufacturing and included office work as that grew to employ a significant percentage of the workforce. Until recently, the percentage of the workforce employed to create/maintain software was not large enough to attract the attention of these researchers, and even now it’s often lumped together with other jobs that mostly involve some form of intellectual activity.
Employee related issues of interest to those involved in managing work on software systems are heavily influenced by the characteristics of the business ecosystem in which they work. The software driven business ecosystems are continually changing, with companies growing, merging and going bust as new markets emerge, grow, saturate, and sometime disappear. This constant change creates employment uncertainty, and lots of opportunities for competent people (creating a staff retention problem). For more stable industries, it’s possible for researchers to model employee start/promotion/leaving transitions using Markov models (example of ChatGPT 1o-preview solving a recurrence model of the staffing relationships in a 3-level employment hierarchy). The book “Stochastic Models for Social Processes” by D. J. Bartholomew gives a practical introduction to the use of Markov models for this kind of analysis.
The evolution and constant introduction of new technologies can make it difficult to find people with the appropriate skills. Companies may tune the wording of job adverts to give the impress of using ‘modern’ technologies, or post fake job adverts (to increase their attractiveness and suggest a feeling of growth), and people tune their CV to appeal to employers (some out right lie about their skills; many managers have told me that around 90% of applicants don’t have the primary skill sought by the employer). Well paid jobs can attract lots of applicants, filtering/interviewing can be an expensive process (not least because the same job title can denote different seniority in different companies). Matching CVs to job requirements sounds like the perfect use case for LLMs. I suspect that LLM tuning of CVs/adverts will just increase costs/uncertainty.
The constant churn of technologies forces employees to make decisions about whether to happily spend many years being well paid to become an expert in a niche with decreasing industry demand, or to invest in starting again as a non-expert doing something new (and initially less well paid).
What is the best to organize engineering employees at a company-wide scale? Matrix management was once the standard answer, but these days, scaled agile is a fashionable answer. An evidence-based answer will have to wait until the lawyers in a large organization allow somebody with the necessary skills access to the appropriate data.
With the contents of job sites being scraped, along with LinkedIn, I’m optimistic that some meaningful employment data will slowly become available. Will the analysis of this data uncover patterns of practical use (other than interesting blog posts) to employers/employees? We will have to wait and see.
Software companies in the UK
How many software companies are there in the UK, and where are they concentrated?
This question begs the question of what kinds of organization should be counted as a software company. My answer to this question is driven by the available data. Companies House is the executive agency of the British Government that maintains the register of UK companies, and basic information on 5,562,234 live companies is freely available.
The Companies House data does not include all software companies. A very small company (e.g., one or two people) might decide to save on costs and paperwork by forming a partnership (companies registered at Companies House are required to file audited accounts, once a year).
When registering, companies have to specify the business domain in which they operate by selecting the appropriate Standard Industrial Classification (SIC) code, e.g., Section J: INFORMATION AND COMMUNICATION, Division 62: Computer programming, consultancy and related activities, Class 62.01: Computer programming activities, Sub-class 62.01/2: Business and domestic software development. A company’s SIC code can change over time, as the business evolves.
Searching the description associated with each SIC code, I selected the following list of SIC codes for companies likely to be considered a ‘software company’:
62011 Ready-made interactive leisure and entertainment
software development
62012 Business and domestic software development
62020 Information technology consultancy activities
62030 Computer facilities management activities
62090 Other information technology service activities
63110 Data processing, hosting and related activities
63120 Web portals |
There are 287,165 companies having one of these seven SIC codes (out of the 1,161 SIC codes currently used); 5.2% of all currently live companies. The breakdown is:
All 62011 62012 62020 62030 62090 63110 63120 5,562,234 7,217 68,834 134,461 3,457 57,132 7,839 8,225 100% 0.15% 1.2% 2.4% 0.06% 1.0% 0.14% 0.15% |
Only one kind of software company (SIC 62020) appears in the top ten of company SIC codes appearing in the data:
Rank SIC Companies 1 68209 232,089 Other letting and operating of own or leased real estate 2 82990 213,054 Other business support service activities n.e.c. 3 70229 211,452 Management consultancy activities other than financial management 4 68100 194,840 Buying and selling of own real estate 5 47910 165,227 Retail sale via mail order houses or via Internet 6 96090 134,992 Other service activities n.e.c. 7 62020 134,461 Information technology consultancy activities 8 99999 130,176 Dormant Company 9 98000 118,433 Residents property management 10 41100 117,264 Development of building projects |
Is the main business of a company reflected in its registered SIC code?
Perhaps a company started out mostly selling hardware with a little software, registered the appropriate non-software SIC code, but over time there was a shift to most of the income being derived from software (or the process ran in reverse). How likely is it that the SIC code will change to reflect the change of dominant income stream? I have no idea.
A feature of working as an individual contractor in the UK is that there were/are tax benefits to setting up a company, say A Ltd, and be employed by this company which invoices the company, say B Ltd, where the work is actually performed (rather than have the individual invoice B Ltd directly). IR35 is the tax legislation dealing with so-called ‘disguised’ employees (individuals who work like payroll staff, but operate and provide services via their own limited company). The effect of this practice is that what appears to be a software company in the Companies House data is actually a person attempting to be tax efficient. Unfortunately, the bulk downloadable data does not include information that might be used to filter out these cases (e.g., number of employees).
Are software companies concentrated in particular locations?
The data includes a registered address for each company. This address may be the primary business location, or its headquarters, or the location of accountants/lawyers working for the business, or a P.O. Box address. The latitude/longitude of the center of each address postcode is available. The first half of the current postcode, known as the outcode, divides the country into 2,951 areas; these outcode areas are the bins I used to count companies.
Are there areas where the probability of a company being a software company is much higher than the national average (5.265%)? The plot below shows a heat map of outcode areas having a higher than average percentage of software companies (36 out of 2,277 outcodes were at least a factor of two greater than the national average; BH7 is top with 5.9 times more companies, then RG6 with 3.7 times, BH21 with 3.6); outcodes having fewer than 10 software companies were excluded (red is highest, green lowest; code+data):
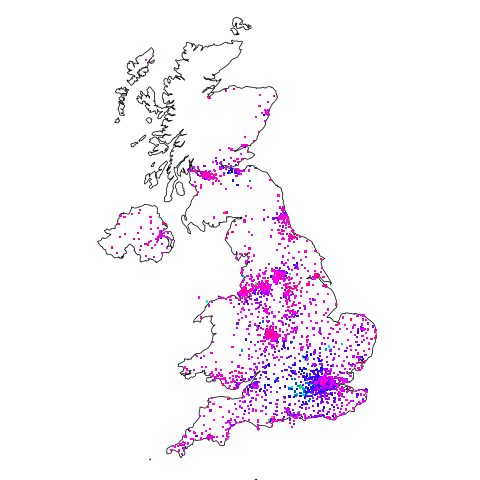
The higher concentrations are centered around the country’s traditional industrial towns and cities, with a cluster sprawling out from London. Cambridge is often cited as a high-tech region, but its highest outcode, CB4, is ranked 39th, at twice the national average (presumably the local high-tech is primarily non-software oriented).
Which outcode areas contain the most software companies? The following list shows the top ten outcodes, by number of registered companies (only BN3 and CF14 are outside London):
Rank Outcode Software companies
1 WC2H 10,860
2 EC1V 7,449
3 N1 6,244
4 EC2A 3,705
5 W1W 3,205
6 BN3 2,410
7 CF14 2,326
8 WC1N 2,223
9 E14 2,192
10 SW19 1,516 |
I’m surprised to see west-central London with so many software companies. Perhaps these companies are registered at their accountants/lawyers, or they are highly paid contractors who earn enough to afford accommodation in WC2. East-central London is the location of nearly all the computer companies I know in London.
Analysis of Cost Performance Index for 338 projects
Project are estimated using a variety of resources. For those working at the sharp end, time is the pervasive resource. From the business perspective, the primary resource focus is on money; spending money to develop software that will make/save money.
Cost estimation data is much rarer than time estimation data (which itself is very thin on the ground).
The paper “An empirical study on a single company’s cost estimations of 338 software projects” (no public pdf currently available) by Christian Schürhoff, Stefan Hanenberg (who kindly sent me a copy of the data), and Volker Gruhn immediately caught my attention. What I am calling the Adesso dataset contains 4,713 rows relating to 338 fixed-price software projects implemented by Adesso SE (a German software and consulting company) between 2011 and the middle of 2016.
Cost estimation data is so very rare because of its commercial sensitivity. This paper deals with the commercial sensitivity issue by not releasing actual cost data, but by releasing data on a ratio of costs; the Cost Performance Index (CPI):

where:  are the actual costs (i.e., money spent) up to the current time, and
are the actual costs (i.e., money spent) up to the current time, and  is the earned value (a marketing term for the costs estimated for the planned work that has actually been completed up to the current time).
is the earned value (a marketing term for the costs estimated for the planned work that has actually been completed up to the current time).
if  , then more was spent than estimated (i.e., project is behind schedule or was underestimated), while if
, then more was spent than estimated (i.e., project is behind schedule or was underestimated), while if  , then less was spent than estimated (i.e., project is ahead of schedule or was overestimated).
, then less was spent than estimated (i.e., project is ahead of schedule or was overestimated).
The progress of a project’s implementation, in monetary terms, can be tracked by regularly measuring its CPI.
The Adesso dataset lists final values for each project (number of days being the most interesting), and each project’s CPI at various percent completed points. The plot below shows the number of CPI estimates for each project, against project duration; the assigned project numbers clustered into four bands and four colors are used to show projects in each band (code+data):
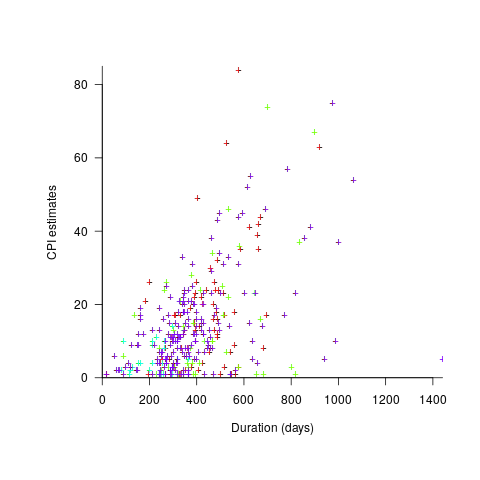
Presumably, projects that made only a handful of CPI estimates used other metrics to monitor project progress.
What are the patterns of change in a project’s CPI during its implementation? The plot below shows every CPI for each of 15 projects, with at least 44 CPI estimates, during implementation (code+data):

A commonly occurring theme, that will be familiar to those who have worked on projects, is that large changes usually occur at the start of the project, and then things settle down.
To continue as a going concern, a commercial company needs to make a profit. Underestimating a project may result in its implementation losing money. Losing money on some projects is not a problem, provided that the loses are cancelled out by overestimated projects making more money than planned.
While the mean CPI for the Adesso projects is 1.02 (standard deviation of 0.3), projects vary in size (and therefore costs). The data does not include project man-hours, but it does include project duration. The weighted mean, using duration as a proxy for man-hours, is 0.96 (standard deviation 0.3).
Companies cannot have long sequences of underestimated projects, creditors and shareholders will eventually call a halt. The Adesso dataset does not include any date information, so it is not possible to estimate the average CPI over shorter durations, e.g., one year.
I don’t have any practical experience of tracking project progress using earned value or CPI, and have only read theory papers on the subject (many essentially say that earned value is a great metric and everybody ought to be using it). Tips and suggestions welcome.
How to use intellectual property tax rules to minimise corporation tax
I recently bought the book Valuing Intellectual Capital by Gio Wiederhold because I thought it might provide some useful information for a book I am working on. A better title for the book might have been “How to use intellectual property tax rules to minimise corporation tax”, not what I was after but a very interesting read none the less.
If you run a high-tech company that operates internationally, don’t know anything about finance, and want to learn about the various schemes that can be used to minimise the tax your company pays to Uncle Sam this book is for you.
This book is also an indispensable resource for anybody trying to unravel the financial structure of an international company.
On the surface this book is a detailed and readable how-to on using IP tax rules to significantly reduce the total amount of corporation tax an international company pay on their profits, but its real message is the extent to which companies have to distort their business and engage in ‘unproductive’ activities to achieve this goal.
Existing tax rules are spaghetti code and we all know how much effect tweaking has on this kind of code. Gio Wiederhold’s recommended rewrite (chapter 10) is the ultimate in simplicity: set corporation tax to zero (the government will get its cut by taxing the dividends paid out to shareholders).
Software developers will appreciate the “here’s how to follow the rules to achieve this effect” approach; this book could also be read as an example of how to write good software documentation.
Recent Comments