Archive
Small business programs: A dataset in the research void
My experience is that most of the programs created within organizations are very short, i.e., around 50–100 lines. Sometimes entire businesses are run using many short programs strung together in various ways. These short programs invariably make extensive use of the functionality provided by a much larger package that handles all the complicated stuff.
In the software development world, these short programs are likely to be shell scripts, but in the much larger ecosystem that is the business world these programs will be written in what used to be called a fourth generation language (4GL). These 4GLs are essentially domain specific languages for specific business tasks, such as report generation, or database query products, and for some time now spreadsheets.
The business software ecosystem is usually only studied by researchers in business schools, but short programs, business or otherwise, are rarely studied by any researchers. The source of such short programs is rarely publicly available; even if the information is not commercially confidential, the program likely addresses one group’s niche problem which is of no interest to anybody else, i.e., there is no rationale to publishing it. If source were available, there might not be enough of it to do any significant analysis.
I recently came across Clive Wrigley’s 1988 PhD thesis, which attempts to build a software estimation model. It contains summary data of 26 transaction processing systems written in the FOCUS language (an automated code generator).
For many organizations, there is a fundamental difference between business related problems and scientific/engineering problems, in that business problems tend to involve simple operations on lots of distinct data items (e.g., payroll calculation for each company employee), while scientific/engineering often involves a complicated formula operating on one set of data. There are exceptions.
4GLs enable technically proficient business users to create and maintain good enough applications without needing software engineering skills (yes, many do create spaghetti code), because they are not writing thousands of lines of code. The applications often contain many semi-self-contained subcomponents, which can be shared or swapped in/out. The small size makes it easier to change quickly, and there is direct access to the business users, it’s an agile process decades before this process took off in the world of non-4GL languages.
A major claim made by fans of 4GL is that it is much cheaper to create applications equivalent to those created using a 3GL, e.g., Cobol/C/C++/Java/Python/etc. I would agree that this true for small applications that fit the use-case addressed by a particular 4GL, but I think the domain specific nature of a 4GL will limit what can be done and likely need to be done in larger applications.
How do 4GL applications written in FOCUS compare against application written in Cobol? A 1987 paper by Chris Kemerer provides some manpower/LOC data for Cobol applications. I have no information on the amount of functionality in any of the applications. The plot below shows developer hours consumed creating 26 systems containing a given number of lines of code for FOCUS (green) and 15 COBOL (blue) programs, with fitted regression models in red (code+data):
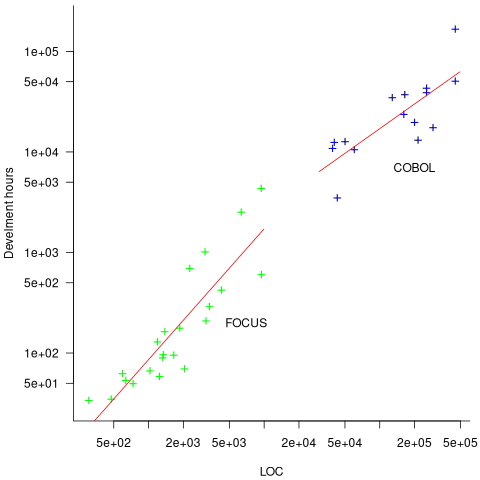
The two samples of applications differ by two orders of magnitude in LOC and developer hours, however, there is no information on the functionality provided by the applications.
Why did organizations fund the creation of the first computers?
What were the events that drove organizations to fund the creation of the first computers?
I suspect that many readers do not appreciate how long scientific/engineering calculations took before electronic computers became available, or the huge number of clerical staff employed to process the paperwork associated with running any sizeable business.
If somebody wanted to know the logarithm of some value, or the sine/cosine of an angle, they looked up the answer in a table. Individuals owned small booklets of tables supplying some level of granularity and number of significant digits. My school boy booklet contains 60-pages of tables, all to five digits of output accuracy, with logarithm supporting four-digit input values and the sine/cosine/tangent tables having an input granularity of hundredth of a degree.
The values in these tables were calculated by human computers; with the following being among the most well known (for more details, see Calculation and Tabulation in the Nineteenth Century: Airy versus Babbage by Doron Swade, and The History of Mathematical Tables: from Sumer to Spreadsheets edited by Campbell-Kelly, Croarken, Flood, and Robson):
- In 1624 Henry Briggs published logarithms for the integer ranges 1-20,000 and 90,001-100,000 (to 14 decimal places), followed some years later by tables of sine and logarithm of sine; in 1628 Adriaan Vlacq publishing tables that filled in the missing values (to 10 decimal places). In 1783 Jurij Vega published a bug-fixed and extended version of Vlacq’s tables.
In 1827 Charles Babbage (that Babbage) published Table of Logarithms of the Natural Numbers from 1 to 10800. These tables were based on corrected versions of these tables, a rigorous nine-stage proofreading process was followed to prevent new mistakes creeping in.
Today, one person can publish A reconstruction of the tables of Briggs’ Arithmetica logarithmica (1624), with an appendix containing 300 pages of calculated values,
- between 1794 and 1799, Gaspard de Prony employed sixty to eighty computers to calculate the logarithms of the integers from 1 to 200,000 to fifteen significant digits (rounding issues sometimes required calculating 25 decimal digits; published in eighteen volumes). Around 400 man-years.
Logarithms and trigonometric functions are very widely used, creating incentives for investing in calculating and publishing tables. While it may be financially worthwhile investing in producing tables for some niche markets (e.g. Life tables for insurance companies), there is an unmet demand that will only be filled by a dramatic drop in the cost of computing simple expressions.
Babbage’s Difference engine was designed to evaluate polynomial expressions and print the results; perfect for publishing tables. While Babbage did not build a Difference engine, starting in 1837, engines based on Babbage’s design were built and sold commercially by the Swede Per Georg Scheutz.
Mechanical calculators improve accuracy and speed the process up. Vacuum tubes are invented in 1904 and become widely used to process analogue signals. World War II created an urgent demand for the results of a variety of time-consuming calculations, e.g., accurate ballistic tables, and valve computers were built. The plot below shows the cost per million operations for manual, mechanical and valve computers (code+data):
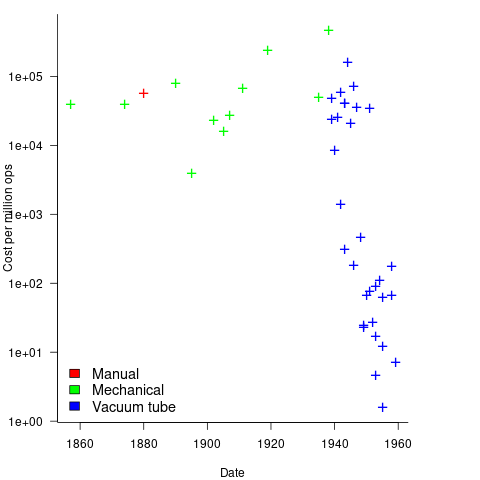
To many observers at the start of the 1950s, the market for electronic computers appeared to be organizations who needed to perform large amounts of scientific/engineering calculation.
Most businesses perform simple calculations on many unrelated values, e.g., banks have to credit/debit the appropriate account when money is deposited/withdrawn. There is no benefit in having a machine that can perform hundreds of calculations per second unless it can be fed data fast enough to keep it busy.
It so happened that, at the start of the 1950s, the US banking system was facing a crisis, the growth in the number of cheques being written meant that it would soon take longer than one day to process all the cheques that arrived in one day. In 1950 Bank of America managed 4.6 million checking accounts, and were opening 23,000 new account per month. Bank of America was then the largest bank in the world, and had a keen interest in continued growth. They funded the development of a bespoke computer system for processing cheques, the ERMA Banking system, which went live in 1959. The plot below shows the number of cheques processed per year by US banks (code+data):
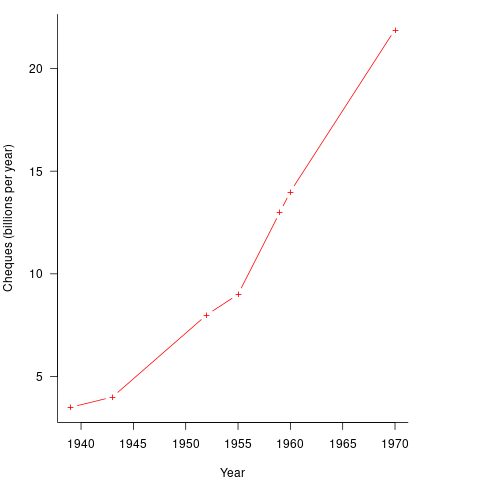
The ERMA system included electronic storage for holding account details, and data entry was speeded up by encoding account details on a magnetic strip included within every cheque.
Businesses are very interested in an integrated combination of input devices plus electronic storage plus compute. There are more commerce oriented businesses than scientific/engineering businesses, and commercial businesses usually have a lot more money to spend, i.e., the real money to be made by selling computers was the business data processing market.
The plot below shows the decreasing cost of hard disc storage (blue, right axis), along with the decreasing computing cost of valve based computers (red, left axis; code+data):
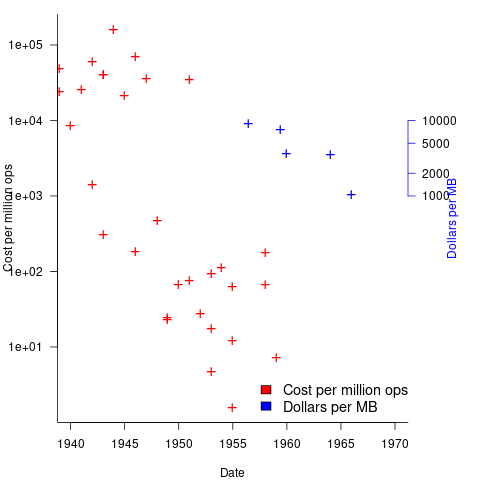
There was a larger business demand to be able to store information electronically, and the hard disc was invented by IBM, roughly 15 years after the first electronic computers.
The very different application demands of data processing and scientific/engineering are reflected in the features supported by the two languages designed in the 1950s, and widely used for the rest of the century: Cobol and Fortran.
Data processing involves simple operations on large quantities of data stored in a potentially huge number of different combinations (the myriad of mechanical point-of-sale terminals stored data in a myriad of different formats, which evolved over time, and the demand for backward compatibility created spaghetti data well before spaghetti code existed). Cobol has extensive functionality supporting the layout and format of input and output data, and simplistic coding constructs.
Scientific/engineering code involves complex calculations on some amount of input. Fortran has extensive functionality supporting program control flow, and relatively basic support for data input/output.
A third major application domain is real-time processing, such as SAGE. However, data on this domain is very hard to find, so it is not discussed.
Some data on the size of Cobol programs/paragraphs
Before the internet took off in the 1990s, COBOL was the most popular language, measured in lines of code in production use. People who program in Cobol often have a strong business focus, and don’t hang out on sites used aggregated by surveys of programming language use; use of the language is almost completely invisible to those outside the traditional data processing community. So who knows how popular Cobol is today.
Despite the enormous quantity of Cobol code that has been written, very little Cobol source is publicly available (Open source or otherwise; the NIST compiler validation suite is not representative). The reason for the sparsity of source code is that Cobol programs are used to process business data, and the code is useless without the appropriate data (even with the data, the output is only likely to be of interest to a handful of people).
Program and function/method size (in LOC) are basic units of source code measurement. Until open source happened, published papers containing these measurements were based on small sample sizes and the languages covered was somewhat spotty. Cobol oriented research usually has a business orientation, rather than being programming oriented, and now there is a plentiful supply of source code written in non-Cobol languages.
I recently discovered appendix B of 1st Lt Richard E. Boone’s Master’s thesis An investigation into the use of software product metrics for COBOL systems (it’s post Rome period). Several days/awk scripts and editor macros later, LOC data for 178 programs containing 2,682 paragraphs containing 53,255 statements is now online (code+data).
A note on terminology: Cobol functions/methods are called paragraphs.
A paragraph is created by attaching a label to the first statement of the paragraph (there are no variables local to a paragraph; all variables are global). The statement PERFORM NAME-OF-PARAGRAPH ‘calls’ the paragraph labelled by NAME-OF-PARAGRAPH, somewhat like gosub number in BASIC.
It is possible to specify a sequence of paragraphs to be executed, in a PERFORM statement. The statement PERFORM NAME-OF-P1 THRU NAME-OF-P99 causes all paragraphs appearing textually in the code between the start of paragraph NAME-1 and the end of paragraph NAME-99 to be executed.
As far as I can tell, Boone’s measurements are based on individual paragraphs, not any sequences of paragraphs that are PERFORMed (it is likely that some labelled paragraphs are never PERFORMed in isolation).
Appendix B lists for each program: the paragraphs it contains, and for each paragraph the number of statements, McCabe’s complexity, maximum nesting, and Henry and Kafura’s Information flow metric
There are, based on naming, many EXIT paragraphs (711 or 26%); these are single statement paragraphs containing the statement EXIT. When encountered as the last paragraph of a PERFORM THU statement, the EXIT effectively acts like a procedure return statement; in other contexts, the EXIT statement acts like a continue statement.
In the following code the developer could have written PERFORM PARA-1 THRU PARA-4, but if a related paragraph was added between PARA-4 and PARA-END_EXIT all PERFORMs explicitly referencing PARA-4 would need to be checked to see if they needed updating to the new last paragraph.
START. PERFORM PARA-1 THRU PARA-END-EXIT. PARA-1. DISPLAY 'PARA-1'. PARA-2. DISPLAY 'PARA-2'. PARA-3. DISPLAY 'PARA-3'. P3-EXIT. EXIT. PARA-4. DISPLAY 'PARA-4'. PARA-END-EXIT. EXIT. |
The plot below shows the number of paragraphs containing a given number of statements, the red dot shows the count with EXIT paragraphs are ignored (code+data):

How does this distribution compare with that seen in C and Java? The plot below shows the Cobol data (in black, with frequency scaled-up by 1,000) superimposed on the same counts for C and Java (C/Java code+data):
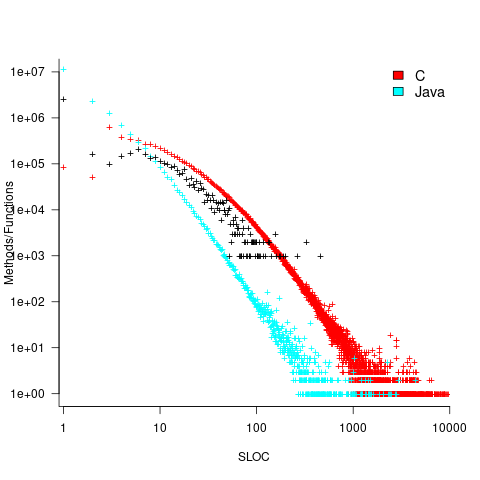
The distribution of statements per paragraph/function distribution for Cobol/C appears to be very similar, at least over the range 10-100. For less than 10-LOC the two languages have very different distributions. Is this behavior particular to the small number of Cobol programs measured? As always, more data is needed.
How many paragraphs does a Cobol program contain? The plot below shows programs ranked by the number of paragraphs they contain, including and excluding EXIT statements (code+data):
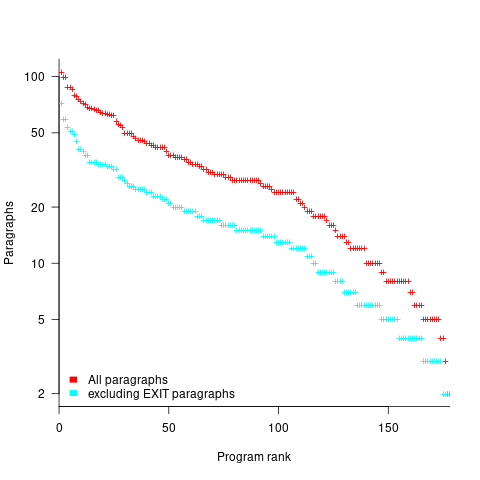
If you squint, it’s possible to imagine two distinct exponential declines, with the switch happening around the 100th program.
It’s tempting to draw some conclusions, but the sample size is too small.
Pointers to large quantities of Cobol source welcome.
2023 in the programming language standards’ world
Two weeks ago I was on a virtual meeting of IST/5, the committee responsible for programming language standards in the UK. IST/5 has a new chairman, Guy Davidson, whose efficiency is very unstandard’s like.
It’s been 18 months since I last reported on the programming language standards’ world, what has been going on?
2023 is going to be a bumper year for the publication of revised Standards of long-established programming language: COBOL, Fortran, C, and C++ (a revised Standard for Ada was published last year).
Yes, COBOL; a new COBOL Standard was published in January. Reports of its death were premature, e.g., my 2014 post suggesting that the latest version would be the last version of the Standard, and the closing of PL22.4, the US Cobol group, in 2017. There has even been progress on the COBOL front end for gcc, which now supports COBOL 85.
The size of the COBOL Standard has leapt from 955 to 1,229 pages (around new 200 pages in the normative text, 100 in the annexes). Comparing the 2014/2023 documents, I could not see any major additions, just lots of small changes spread throughout the document.
Every Standard has a project editor, the person tasked with creating a document that reflects the wishes/votes of its committee; the project editor sends the agreed upon document to ISO to be published as the official ISO Standard. The ISO editors would invariably request that the project editor make tiresome organizational changes to the document, and then add a front page and ISO copyright notice; from time to time an ISO editor took it upon themselves to reformat a document, sometimes completely mangling its contents. The latest diktat from ISO requires that submitted documents use the Cambria font. Why Cambria? What else other than it is the font used by the Microsoft Word template promoted by ISO as the standard format for Standard’s documents.
All project editors have stories to tell about shepherding their document through the ISO editing process. With three Standards (COBOL lives in a disjoint ecosystem) up for publication this year, ISO editorial issues have become a widespread topic of discussion in the bubble that is language standards.
Traditionally, anybody wanting to be actively involved with a language standard in the UK had to find the contact details of the convenor of the corresponding language panel, and then ask to be added to the panel mailing list. My, and others, understanding was that provided the person was a UK citizen or worked for a UK domiciled company, their application could not be turned down (not that people were/are banging on the door to join). BSI have slowly been computerizing everything, and, as of a few years ago, people can apply to join a panel via a web page; panel members are emailed the CV of applicants and asked if “… applicant’s knowledge would be beneficial to the work programme and panel…”. In the US, people pay an annual fee for membership of a language committee ($1,340/$2,275). Nobody seems to have asked whether the criteria for being accepted as a panel member has changed. Given that BSI had recently rejected somebodies application to join the C++ panel, the C++ panel convenor accepted the action to find out if the rules have changed.
In December, BSI emailed language panel members asking them to confirm that they were actively participating. One outcome of this review of active panel membership was the disbanding of panels with ‘few’ active members (‘few’ might be one or two, IST/5 members were not sure). The panels that I know to have survived this cull are: Fortran, C, Ada, and C++. I did not receive any email relating to two panels that I thought I was a member of; one or more panel convenors may be appealing their panel being culled.
Some language panels have been moribund for years, being little more than bullet points on the IST/5 agenda (those involved having retired or otherwise moved on).
Widely used programming languages: past, present, and future
Programming languages are like pop groups in that they have followers, fans and supporters; new ones are constantly being created and some eventually become widely popular, while those that were once popular slowly fade away or mutate into something else.
Creating a language is a relatively popular activity. Science fiction and fantasy authors have been doing it since before computers existed, e.g., the Elf language Quenya devised by Tolkien, and in the computer age Star Trek’s Klingon. Some very good how-to books have been written on the subject.
As soon as computers became available, people started inventing programming languages.
What have been the major factors influencing the growth to widespread use of a new programming languages (I’m ignoring languages that become widespread within application niches)?
Cobol and Fortran became widely used because there was widespread implementation support for them across computer manufacturers, and they did not have to compete with any existing widely used languages. Various niches had one or more languages that were widely used in that niche, e.g., Algol 60 in academia.
To become widely used during the mainframe/minicomputer age, a new language first had to be ported to the major computers of the day, whose products sometimes supported multiple, incompatible operating systems. No new languages became widely used, in the sense of across computer vendors. Some new languages were widely used by developers, because they were available on IBM computers; for several decades a large percentage of developers used IBM computers. Based on job adverts, RPG was widely used, but PL/1 not so. The use of RPG declined with the decline of IBM.
The introduction of microcomputers (originally 8-bit, then 16, then 32, and finally 64-bit) opened up an opportunity for new languages to become widely used in that niche (which would eventually grow to be the primary computing platform of its day). This opportunity occurred because compiler vendors for the major languages of the day did not want to cannibalize their existing market (i.e., selling compilers for a lot more than the price of a microcomputer) by selling a much lower priced product on microcomputers.
BASIC became available on practically all microcomputers, or rather some dialect of BASIC that was incompatible with all the other dialects. The availability of BASIC on a vendor’s computer promoted sales of the hardware, and it was not worthwhile for the major vendors to create a version of BASIC that reduced portability costs; the profit was in games.
The dominance of the Microsoft/Intel partnership removed the high cost of porting to lots of platforms (by driving them out of business), but created a major new obstacle to the wide adoption of new languages: Developer choice. There had always been lots of new languages floating around, but people only got to see the subset that were available on the particular hardware they targeted. Once the cpu/OS (essentially) became a monoculture most new languages had to compete for developer attention in one ecosystem.
Pascal was in widespread use for a few years on micros (in the form of Turbo Pascal) and university computers (the source of Wirth’s ETH compiler was freely available for porting), but eventually C won developer mindshare and became the most widely used language. In the early 1990s C++ compiler sales took off, but many developers were writing C with a few C++ constructs scattered about the code (e.g., use of new, rather than malloc/free).
Next, the Internet took off, and opened up an opportunity for new languages to become dominant. This opportunity occurred because Internet related software was being made freely available, and established compiler vendors were not interested in making their products freely available.
There were people willing to invest in creating a good-enough implementation of the language they had invented, and giving it away for free. Luck, plus being in the right place at the right time resulted in PHP and Javascript becoming widely used. Network effects prevent any other language becoming widely used. Compatible dialects of PHP and Javascript may migrate widespread usage to quite different languages over time, e.g., Facebook’s Hack.
Java rode to popularity on the coat-tails of the Internet, and when it looked like security issues would reduce it to niche status, it became the vendor supported language for one of the major smart-phone OSs.
Next, smart-phones took off, but the availability of Open Source compilers closed the opportunity window for new languages to become dominant through lack of interest from existing compiler vendors. Smart-phone vendors wanted to quickly attract developers, which meant throwing their weight behind a language that many developers were already familiar with; Apple went with Objective-C (which evolved to Swift), Google with Java (which evolved to Kotlin, because of the Oracle lawsuit).
Where does Python fit in this grand scheme? I don’t yet have an answer, or is my world-view wrong to treat Python usage as being as widespread as C/C++/Java?
New programming languages continue to be implemented; I don’t see this ever stopping. Most don’t attract more users than their implementer, but a few become fashionable amongst the young, who are always looking to attach themselves to something new and shiny.
Will a new programming language ever again become widely used?
Like human languages, programming languages experience strong networking effects. Widely used languages continue to be widely used because many companies depend on code written in it, and many developers who can use it can obtain jobs; what company wants to risk using a new language only to find they cannot hire staff who know it, and there are not many people willing to invest in becoming fluent in a language with no immediate job prospects.
Today’s widely used programmings languages succeeded in a niche that eventually grew larger than all the other computing ecosystems. The Internet and smart-phones are used by everybody on the planet, there are no bigger ecosystems to provide new languages with a possible route to widespread use. To be widely used a language first has to become fashionable, but from now on, new programming languages that don’t evolve from (i.e., be compatible with) current widely used languages are very unlikely to migrate from fashionable to widely used.
It has always been possible for a proficient developer to dedicate a year+ of effort to create a new language implementation. Adding the polish need to make it production ready used to take much longer, but these days tool chains such as LLVM supply a lot of the heavy lifting. The problem for almost all language creators/implementers is community building; they are terrible at dealing with other developers.
It’s no surprise that nearly all the new languages that become fashionable originate with language creators who work for a company that happens to feel a need for a new language. Examples include:
- Go created by Google for internal use, and attracted an outside fan base. Company languages are not new, with IBM’s PL/1 being the poster child (or is there a more modern poster child). At the moment Go is a trendy language, and this feeds a supply of young developers willing to invest in learning it. Once the trendiness wears off, Google will start to have problems recruiting developers, the reason: Being labelled as a Go developer limits job prospects when few other companies use the language. Talk to a manager who has tried to recruit developers to work on applications written in Fortran, Pascal and other once-widely used languages (and even wannabe widely used languages, such as Ada),
- Rust a vanity project from Mozilla, which they have now
abandonedcast adrift. Did Rust become fashionable because it arrived at the right time to become the not-Google language? I await a PhD thesis on the topic of the rise and fall of Rust, - Microsoft’s C# ceased being trendy some years ago. These days I don’t have much contact with developers working in the Microsoft ecosystem, so I don’t know anything about the state of the C# job market.
Every now and again a language creator has the social skills needed to start an active community. Zig caught my attention when I read that its creator, Andrew Kelley, had quit his job to work full-time on Zig. Two and a-half years later Zig has its own track at FOSEM’21.
Will Zig become the next fashionable language, as Rust/Go popularity fades? I’m rooting for Zig because of its name, there are relatively few languages whose name starts with Z; the start of the alphabet is over-represented with language names. It would be foolish to root for a language because of a belief that it has magical properties (e.g., powerful, readable, maintainable), but the young are foolish.
Influential programming languages: some of the considerations
Which programming languages have been the most influential?
Let’s define an influential language as one that has had an impact on lots of developers. What impact might a programming language have on developers?
To have an impact a language needs to be used by lots of people, or at least have a big impact on a language that is used by lots of people.
Figuring out the possible impacts a language might have had is very difficult, requiring knowledge of different application domains, software history, and implementation techniques. The following discussion of specific languages illustrate some of the issues.
Simula is an example of a language used by a handful of people, but a few of the people under its influence went on to create Smalltalk and C++. Some people reacted against the complexity of Algol 68, creating much simpler languages (e.g., Pascal), while others thought some of its feature were neat and reused them (e.g., Bourne shell).
Cobol has been very influential, at least within business computing (those who have not worked in business computing complain about constructs handling uses that it was not really designed to handle, rather than appreciating its strengths in doing what it was designed to do, e.g., reading/writing and converting a wide range of different numeric data formats). RPG may have been even more influential in this usage domain (all businesses have to specific requirements on formatting reports).
I suspect that most people could not point to the major influence C has had on almost every language since. No, not the use of { and }; if a single character is going to be used as a compound statement bracketing token, this pair are the only available choice. Almost every language now essentially uses C’s operator precedence (rather than Fortran‘s, which is slightly different; R follows Fortran).
Algol 60 has been very influential: until C came along it was the base template for many languages.
Fortran is still widely used in scientific and engineering software. Its impact on other languages may be unknown to those involved. The intricacies of floating-point arithmetic are difficult to get right, and WG5 (the ISO language committee, although the original work was done by the ANSI committee, J3). Fortran code is often computationally intensive, and many optimization techniques started out optimizing Fortran (see “Optimizing Compilers for Modern Architectures” by Allen and Kennedy).
BASIC showed how it was possible to create a usable interactive language system. The compactness of its many, and varied, implementations were successful because they did not take up much storage and were immediately usable.
Forth has been influential in the embedded systems domain, and also people fall in love with threaded code as an implementation technique (see “Threaded Interpretive Languages” by Loeliger).
During the mid-1990s the growth of the Internet enabled a few new languages to become widely used, e.g., PHP and Javascript. It’s difficult to say whether these were more influenced by what their creators ate the night before or earlier languages. PHP and Javascript are widely used, and they have influenced the creation of many languages designed to fix their myriad of issues.
2019 in the programming language standards’ world
Last Tuesday I was at the British Standards Institute for a meeting of IST/5, the committee responsible for programming language standards in the UK.
There has been progress on a few issues discussed last year, and one interesting point came up.
It is starting to look as if there might be another iteration of the Cobol Standard. A handful of people, in various countries, have started to nibble around the edges of various new (in the Cobol sense) features. No, the INCITS Cobol committee (the people who used to do all the heavy lifting) has not been reformed; the work now appears to be driven by people who cannot let go of their involvement in Cobol standards.
ISO/IEC 23360-1:2006, the ISO version of the Linux Base Standard, has been updated and we were asked for a UK position on the document being published. Abstain seemed to be the only sensible option.
Our WG20 representative reported that the ongoing debate over pile of poo emoji has crossed the chasm (he did not exactly phrase it like that). Vendors want to have the freedom to specify code-points for use with their own emoji, e.g., pineapple emoji. The heady days, of a few short years ago, when an encoding for all the world’s character symbols seemed possible, have become a distant memory (the number of unhandled logographs on ancient pots and clay tablets was declining rapidly). Who could have predicted that the dream of a complete encoding of the symbols used by all the world’s languages would be dashed by pile of poo emoji?
The interesting news is from WG9. The document intended to become the Ada20 standard was due to enter the voting process in June, i.e., the committee considered it done. At the end of April the main Ada compiler vendor asked for the schedule to be slipped by a year or two, to enable them to get some implementation experience with the new features; oops. I have been predicting that in the future language ‘standards’ will be decided by the main compiler vendors, and the future is finally starting to arrive. What is the incentive for the GNAT compiler people to pay any attention to proposals written by a bunch of non-customers (ok, some of them might work for customers)? One answer is that Ada users tend to be large bureaucratic organizations (e.g., the DOD), who like to follow standards, and might fund GNAT to implement the new document (perhaps this delay by GNAT is all about funding, or lack thereof).
Right on cue, C++ users have started to notice that C++20’s added support for a system header with the name version, which conflicts with much existing practice of using a file called version to contain versioning information; a problem if the header search path used the compiler includes a project’s top-level directory (which is where the versioning file version often sits). So the WG21 committee decides on what it thinks is a good idea, implementors implement it, and users complain; implementors now have a good reason to not follow a requirement in the standard, to keep users happy. Will WG21 be apologetic, or get all high and mighty; we will have to wait and see.
2018 in the programming language standards’ world
I am sitting in the room, at the British Standards Institution, where today’s meeting of IST/5, the committee responsible for programming languages, has just adjourned (it’s close to where I have to be in a few hours).
BSI have downsized us, they no longer provide a committee secretary to take minutes and provide a point of contact. Somebody from a service pool responds (or not) to emails. I did not blink first to our chair’s request for somebody to take the minutes 🙂
What interesting things came up?
It transpires that reports of the death of Cobol standards work may be premature. There are a few people working on ‘new’ features, e.g., support for JSON. This work is happening at the ISO level, rather than the national level in the US (where the real work on the Cobol standard used to be done, before being handed on to the ISO). Is this just a couple of people pushing a few pet ideas or will it turn into something more substantial? We will have to wait and see.
The Unicode consortium (a vendor consortium) are continuing to propose new pile of poo emoji and WG20 (an ISO committee) were doing what they can to stay sane.
Work on the Prolog standard, now seems to be concentrated in Austria. Prolog was the language to be associated with, if you were on the 1980s AI bandwagon (and the Japanese were going to take over the world unless we did something about it, e.g., spend money); this time around, it’s machine learning. With one dominant open source implementation and one commercial vendor (cannot think of any others), standards work is a relic of past glories.
In pre-internet times there was an incentive to kill off committees that were past their sell-by date; it cost money to send out mailings and document storage occupied shelf space. In an electronic world there is no incentive to spend time killing off such committees, might as well wait until those involved retire or die.
WG23 (programming language vulnerabilities) reported lots of interest in their work from people involved in the C++ standard, and for some reason the C++ committee people in the room started glancing at me. I was a good boy, and did not mention bored consultants.
It looks like ISO/IEC 23360-1:2006, the ISO version of the Linux Base Standard is going to be updated to reflect LBS 5.0; something that was not certain few years ago.
Compiler validation is now part of history
Compiler validation makes sense in a world where there are many different hardware platforms, each with their own independent compilers (third parties often implemented compilers for popular platforms, competing against the hardware vendor). A large organization that spends hundreds of millions on a multitude of computer systems (e.g., the U.S. government) wants to keep prices down, which means the cost of porting its software to different platforms needs to be kept down (or at least suppliers need to think it will not cost too much to switch hardware).
A crucial requirement for source code portability is that different compilers be able to compile the same source, generating code that produces the same behavior. The same behavior requirement is an issue when the underlying word-size varies or has different alignment requirements (lots of code relies on data structures following particular patterns of behavior), but management on all sides always seems to think that being able to compile the source is enough. Compilers vendors often supported extensions to the language standard, and developers got to learn they were extensions when porting to a different compiler.
The U.S. government funded a conformance testing service, and paid for compiler validation suites to be written (source code for what were once the Cobol 85, Fortran 78 and SQL validation suites). While it was in business, this conformance testing service was involved C compiler validation, but it did not have to fund any development because commercial test suites were available.
The 1990s was the mass-extinction decade for companies selling non-Intel hardware. The widespread use of Open source compilers, coupled with the disappearance of lots of different cpus (porting compilers to new vendor cpus was always a good money spinner, for the compiler writing cottage industry), meant that many compilers disappeared from the market.
These days, language portability issues have been essentially solved by a near monoculture of compilers and cpus. It’s the libraries that are the primary cause of application portability problems. There is a test suite for POSIX and Linux has its own tests.
There are companies selling compiler C/C++ test suites (e.g., Perennial and PlumHall); when maintaining a compiler, it’s cost-effective to have a set of third-party tests designed to exercise all the language.
The OpenGroup offer to test your C compiler and issue a brand certificate if it passes the tests.
Source code portability requires compilers to have the same behavior and traditionally the generally accepted behavior has been defined by an ISO Standard or how one particular implementation behaved. In an Open source world, behavior is defined by what needs to be done to run the majority of existing code. Does it matter if Open source compilers evolve in a direction that is different from the behavior specified in an ISO Standard? I think not, it makes no difference to the majority of developers; but be careful, saying this can quickly generate a major storm in a tiny teacup.
2017 in the programming language standards’ world
Yesterday I was at the British Standards Institution for a meeting of IST/5, the committee responsible for programming languages.
The amount of management control over those wanting to get to the meeting room, from outside the building, has increased. There is now a sensor activated sliding door between the car-park and side-walk from the rear of the building to the front, and there are now two receptions; the ground floor reception gets visitors a pass to the first floor, where a pass to the fifth floor is obtained from another reception (I was totally confused by being told to go to the first floor, which housed the canteen last time I was there, and still does, the second reception is perched just inside the automatic barriers to the canteen {these barriers are also new; the food is reasonable, but not free}).
Visitors are supposed to show proof that they are attending a meeting, such as a meeting calling notice or an agenda. I have always managed to look sufficiently important/knowledgeable/harmless to get in without showing any such documents. I was asked to show them this time, perhaps my image is slipping, but my obvious bafflement at the new setup rescued me.
Why does BSI do this? My theory is that it’s all about image, BSI is the UK’s standard setting body and as such has to be seen to follow these standards. There is probably some security standard for rules to follow to prevent people sneaking into buildings. It could be argued that the name British Standards is enough to put anybody off wanting to enter the building in the first place, but this does not sound like a good rationale for BSI to give. Instead, we have lots of sliding doors/gates, multiple receptions (I suspect this has more to do with a building management cat fight over reception costs), lifts with no buttons ‘inside’ for selecting floors, and proof of reasons to be in the building.
There are also new chairs in the open spaces. The chairs have very high backs and side-baffles that surround the head area, excellent for having secret conversations and in-tune with all the security. These open areas are an image of what people in the 1970s thought the future would look like (BSI is a traditional organization after all).
So what happened in the meeting?
Cobol standard’s work becomes even more dead. PL22.4, the US Cobol group is no more (there were insufficient people willing to pay membership fees, so the group was closed down).
People are continuing to work on Fortran (still the language of choice for supercomputer Apps), Ada (some new people have started attending meetings and support for @ is still being fought over), C, Internationalization (all about character sets these days). Unprompted somebody pointed out that the UK C++ panel seemed to be attracting lots of people from the financial industry (I was very professional and did not relay my theory that it’s all about bored consultants wanting an outlet for their creative urges).
SC22, the ISO committee responsible for programming languages, is meeting at BSI next month, and our chairman asked if any of us planned to attend. The chair’s response, to my request to sell the meeting to us, was that his vocabulary was not up to the task; a two-day management meeting (no technical discussions permitted at this level) on programming languages is that exciting (and they are setting up a special reception so that visitors don’t have to go to the first floor to get a pass to attend a meeting on the ground floor).
Recent Comments