Archive
Extracting named entities from a change log using an LLM
The Change log of a long-lived software system contains many details about the system’s evolution. Two years ago I tried to track the evolution of Beeminder by extracting the named entities in its change log (named entities are the names of things, e.g., person, location, tool, organization). This project was pre-LLM, and encountered the usual problem of poor or non-existent appropriately trained models.
Large language models are now available, and these appear to excel at figuring out the syntactic structure of text. How well do LLMs perform, when asked to extract named entities from each entry in a software project’s change log?
For this analysis I’m using the publicly available Beeminder change log. Organizations may be worried about leaking information when sending confidential data to a commercially operated LLM, so I decided to investigate the performance of a couple of LLMs running on my desktop machine (code+data).
The LLMs I used were OpenAI’s ChatGPT plus (the $20 month service), and locally: Google’s Gemma (the ollama 7b model), a llava 7b model (llava-v1.5-7b-q4.llamafile), and a Mistral 7b model (mistral-7b-instruct-v0.2.Q8_0.llamafile). I used 7 billion parameter models locally because this is the size that is generally available for Open sourced models. There are a few models supporting the next step-up, at 13 billion parameters, and a few at 30 billion.
All the local models start a server at localhost:8080, and provide various endpoints. Mozilla’s llamafile based system is compatible with OpenAI’s python package openai. The documentation for the Gemma based system I installed uses the ollama package. In both cases, the coding required is trivial; just add a few statements to create a question based on command line input:
import openai import sys prefix='List the named entities in the following sentences: ' input_str=sys.argv[1] # change log entry from command line client = openai.OpenAI( base_url="http://localhost:8080/v1", # "http://<Your api-server IP>:port" api_key = "sk-no-key-required" ) stream = client.chat.completions.create( model="gpt-4", stream=True, temperature=0, seed=19, messages=[ {"role": "system", "content": "You are ChatGPT, an AI assistant. Your top priority is achieving user fulfilment via helping them with their requests."}, {"role": "user", 'content': prefix+ input_str } ] ) # Print response for chunk in stream: print(chunk.choices[0].delta.content or "", end="") print() |
How well did the models perform?
For rapid iteration, I used the web interface to ChatGPT. The responses started to appear within a few seconds and were displayed at a readable rate.
ChatGPT 3.5
When given a single change log entry, ChatGPT also provides a brief description of the named entity. In the following example, ‘twitter acct‘ and ‘blog posts‘ are not flagged as named entities:
User
print the named entities in the following quoted text "Created
this twitter acct to log user-visible improvements (UVIs) to
Beeminder. (Yes, this is a UVI. Everything counts no matter how
small!) Very first UVI! Back then this counted but nowadays we
don't count things that are too ancillary like making Twitter
accounts or writing blog posts. We did count a few UVIs for
creating this fancy changelog but decided that's too ancillary
now too."
ChatGPT
To identify named entities in the quoted text, we need to look for
proper nouns, which typically include names of specific people,
organizations, locations, and sometimes unique entities. In the
provided text, here are the named entities:
Beeminder - Refers to a specific service or product.
Twitter - Refers to a specific social media platform.
UVI (User-Visible Improvement) - Refers to a specific type of improvement.
changelog - Refers to a specific type of document or record. |
When asked to list the named entities in each of multiple lines, ChatGTP 3.5 performance drops. In the following response, the first line is identical to the example above; the response contains three, not four names entities. The second line contains named entities, but ChatGTP claims there are none. The response to the third line is accurate:
ChatGPT
Here are the named entities in each of the three lines:
"Created this twitter acct" line:
Twitter - Refers to a specific social media platform.
UVIs (User-Visible Improvements) - Refers to a specific
type of improvement.
Beeminder - Refers to a specific service or product.
"Added ridiculous dog-dressed-as-a-bee picture" line:
None
"Now suppressing reminder emails" line:
reminder emails - Refers to a specific type of communication.
bug fixes - Refers to a specific type of improvement aimed
at resolving software issues.
UVIs (User-Visible Improvements) - Refers to a specific
type of improvement. |
ChatGPT 4.0
ChatGPT 4.0 can handle multiple change log entries. The following is the response to the first three entries (the same three entries given the ChatGPT 3.5):
ChatGPT
To thoroughly identify the named entities within each line,
I'll systematically parse each one, focusing on extracting
specific types of entities such as organizations, people,
locations, dates, websites, and any other identifiable proper
nouns.
Beeminder, Twitter, UVI: Organizations or products.
dog-dressed-as-a-bee: Concept, not a proper noun but unique
enough to note.
reminder emails: Concept, referring to a feature. |
While it is possible to input 100 change log entries into the ChatGPT input box, the response contained no more than about 25 of them (there is a maximum limit on the number of input and output tokens).
Running locally
The machine I used locally contains 64G memory and an Intel Core i5-7600K running at 3.80GHz, with four cores. The OS is Linux Mint 21.1, running the kernel 5.15.0-76-generic. I don’t have any GPUs installed.
A GPU would probably significantly improve performance. On Amazon, the price of the NVIDIA Tesla A100 is now just under £7,000, an order of magnitude more than I am interested in paying (let alone the electricity costs). I have not seen any benchmarks comparing GPU performance on running LLMs locally, but then this is still a relatively new activity.
Overall, Gemma produced the best responses and was the fastest model. The llava model performed so poorly that I gave up trying to get it to produce reasonable responses (code+data). Mistral ran at about a third the speed of Gemma, and produced many incorrect named entities.
As a very rough approximation, Gemma might be useful. I look forward to trying out a larger Gemma model.
Gemma
Gemma took around 15 elapsed hours (keeping all four cores busy) to list named entities for 3,749 out of 3,839 change log entries (there were 121 “None” named entities given). Around 3.5 named entities per change log entry were generated. I suspect that many of the nonresponses were due to malformed options caused by input characters I failed to handle, e.g., escaping characters having special meaning to the command shell.
For around about 10% of cases, each named entity output was bracketed by “**”.
The table below shows the number of named entities containing a given number of ‘words’. The instances of more than around three ‘words’ are often clauses within the text, or even complete sentences:
# words 1 2 3 4 5 6 7 8 9 10 11 12 14 Occur 9149 4102 1077 210 69 22 10 9 3 1 3 5 4 |
A total of 14,676 named entities were produced, of which 6,494 were unique (ignoring case and stripping **).
Mistral
Mistral took 20 hours to process just over half of the change log entries (2,027 out of 3,839). It processed input at around 8 tokens per second and output at around 2.5 tokens per second.
When Mistral could not identify a named entity, it reported this using a variety of responses, e.g., “In the given …”, “There are no …”, “In this sentence …”.
Around 5.8 named entities per change log entry were generated. Many of the responses were obviously not named entities, and there were many instances of it listing clauses within the text, or even complete sentences. The table below shows the number of named entities containing a given number of ‘words’:
# words 1 2 3 4 5 6 7 8 9 10 11 12 13 14 Occur 3274 1843 828 361 211 130 132 90 69 90 68 46 49 27 |
A total of 11,720 named entities were produced, of which 4,880 were unique (ignoring case).
Tracking software evolution via its Changelog
Software that is used evolves. How fast does software evolve, e.g., much new functionality is added and how much existing functionality is updated?
A new software release is often accompanied by a changelog which lists new, changed and deleted functionality. When software is developed using a continuous release process, the changelog can be very fine-grained.
The changelog for the Beeminder app contains 3,829 entries, almost one per day since February 2011 (around 180 entries are not present in the log I downloaded, whose last entry is numbered 4012).
Is it possible to use the information contained in the Beeminder changelog to estimate the rate of growth of functionality of Beeminder over time?
My thinking is driven by patterns in a plot of the Renzo Pomodoro dataset. Renzo assigned a tag-name (sometimes two) to each task, which classified the work involved, e.g., @planning. The following plot shows the date of use of each tag-name, over time (ordered vertically by first use). The first and third black lines are fitted regression models of the form  , where:
, where:  is a constant and
is a constant and  is the number of days since the start of the interval fitted; the second (middle) black line is a fitted straight line.
is the number of days since the start of the interval fitted; the second (middle) black line is a fitted straight line.
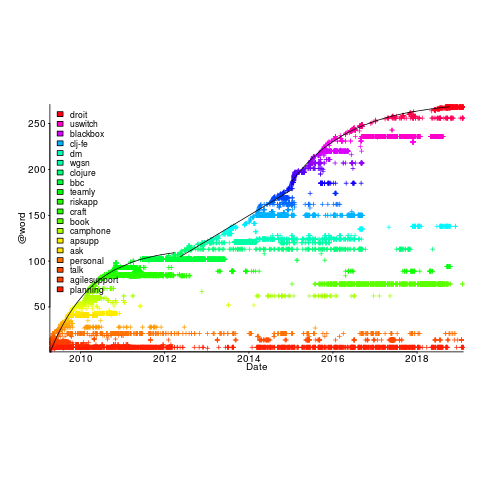
How might a changelog line describing a day’s change be distilled to a much shorter description (effectively a tag-name), with very similar changes mapping to the same description?
Named-entity recognition seemed like a good place to start my search, and my natural language text processing tool of choice is still spaCy (which continues to get better and better).
spaCy is Python based and the processing pipeline could have all been written in Python. However, I’m much more fluent in awk for data processing, and R for plotting, so Python was just used for the language processing.
The following shows some Beeminder changelog lines after stripping out urls and formatting characters:
Cheapo bug fix for erroneous quoting of number of safety buffer days for weight loss graphs. Bugfix: Response emails were accidentally off the past couple days; fixed now. Thanks to user bmndr.com/laur for alerting us! More useful subject lines in the response emails, like "wrong lane!" or whatnot. Clearer/conciser stats at bottom of graph pages. (Will take effect when you enter your next datapoint.) Progress, rate, lane, delta. Better handling of significant digits when displaying numbers. Cf stackoverflow.com/q/5208663 |
The code to extract and print the named-entities in each changelog line could not be simpler.
import spacy import sys nlp = spacy.load("en_core_web_sm") # load trained English pipelines count=0 for line in sys.stdin: count += 1 print(f'> {count}: {line}') # doc=nlp(line) # do the heavy lifting # for ent in doc.ents: # iterate over detected named-entities print(ent.lemma_, ent.label_) |
To maximize the similarity between named-entities appearing on different lines the lemmas are printed, rather than original text (i.e., words appear in their base form).
The label_ specifies the kind of named-entity, e.g., person, organization, location, etc.
This code produced 2,225 unique named-entities (5,302 in total) from the Beeminder changelog (around 0.6 per day), and failed to return a named-entity for 33% of lines. I was somewhat optimistically hoping for a few hundred unique named-entities.
There are several problems with this simple implementation:
- each line is considered in isolation,
- the change log sometimes contains different names for the same entity, e.g., a person’s full name, Christian name, or twitter name,
- what appear to be uninteresting named-entities, e.g., numbers and dates,
- the language does not know much about software, having been training on a corpus of general English.
Handling multiple names for the same entity would a lot of work (i.e., I did nothing), ‘uninteresting’ named-entities can be handled by post-processing the output.
A language processing pipeline that is not software-concept aware is of limited value. spaCy supports adding new training models, all I need is a named-entity model trained on manually annotated software engineering text.
The only decent NER training data I could find (trained on StackOverflow) was for BERT (another language processing tool), and the data format is very different. Existing add-on spaCy models included fashion, food and drugs, but no software engineering.
Time to roll up my sleeves and create a software engineering model. Luckily, I found a webpage that provided a good user interface to tagging sentences and generated the json file used for training. I was patient enough to tag 200 lines with what I considered to be software specific named-entities. … and now I have broken the NER model I built…
The following plot shows the growth in the total number of named-entities appearing in the changelog, and the number of unique named-entities (with the 1,996 numbers and dates removed; code+data);
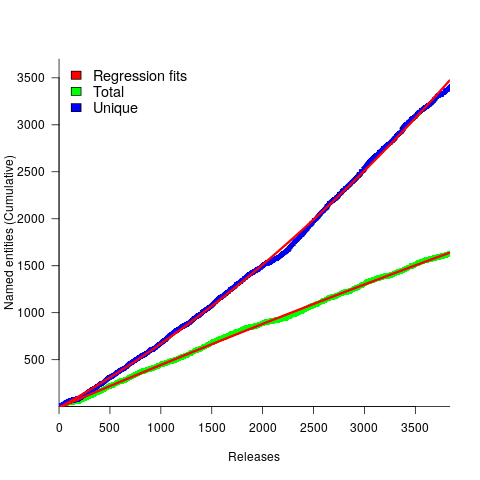
The regression fits (red lines) are quadratics, slightly curving up (total) and down (unique); the linear growth components are: 0.6 per release for total, and 0.46 for unique.
Including software named-entities is likely to increase the total by at least 15%, but would have little impact on the number of unique entries.
This extraction pipeline processes one release line at a time. Building a set of Beeminder tag-names requires analysing the changelog as a whole, which would take a lot longer than the day spent on this analysis.
The Beeminder developers have consistently added new named-entities to the changelog over more than eleven years, but does this mean that more features have been consistently added to the software (or are they just inventing different names for similar functionality)?
It is not possible to answer this question without access to the code, or experience of using the product over these eleven years.
However, staying in business for eleven years is a good indicator that the developers are doing something right.
Recent Comments