Archive
Estimating the quality of a compiler implemented in mathematics
How can you tell if a language implementation done using mathematical methods lives up to the claims being made about it, without doing lots of work? Answers to the following questions should give you a good idea of the quality of the implementation, from a language specification perspective, at least for C.
- How long did it take you to write it? I have yet to see any full implementation of a major language done in less than a man year; just understanding and handling the semantics, plus writing the test cases will take this long. I would expect an answer of at least several man years
- Which professional validation suites have you tested the implementation against? Many man years of work have gone into the Perennial and PlumHall C validation suites and correctly processing either of them is a non-trivial task. The gcc test suite is too light-weight to count. The C Model Implementation passed both
- How many faults have you found in the C Standard that have been accepted by WG14 (DRs for C90 and C99)? Everybody I know who has created a full implementation of a C front end based on the text of the C Standard has found faults in the existing wording. Creating a high quality formal definition requires great attention to detail and it is to be expected that some ambiguities/inconsistencies will be found in the Standard. C Model Implementation project discoveries include these and these.
- How many ‘rules’ does the implementation contain? For the C Model Implementation (originally written in Pascal and then translated to C) every if-statement it contained was cross referenced to either a requirement in the C90 standard or to an internal documentation reference; there were 1,327 references to the Environment and Language clauses (200 of which were in the preprocessor and 187 involved syntax). My C99 book lists 2,043 sentences in the equivalent clauses, consistent with a 70% increase in page count over C90. The page count for C1X is around 10% greater than C99. So for a formal definition of C99 or C1X we are looking for at around 2,000 language specific ‘rules’ plus others associated with internal housekeeping functions.
- What percentage of the implementation is executed by test cases? How do you know code/mathematics works if it has not been tested? The front end of the C Model Implementation contains 6,900 basic blocks of which 87 are not executed by any test case (98.7% coverage); most of the unexecuted basic blocks require unusual error conditions to occur, e.g., disc full, and we eventually gave up trying to figure out whether a small number of them were dead code or just needed the right form of input (these days genetic programming could be used to help out and also to improve the quality of coverage to something like say MC/DC, but developing on a PC with a 16M hard disc does limit what can be done {the later arrival of a Sun 4 with 32M of RAM was mind blowing}).
Other suggested questions or numbers applicable to other languages most welcome. Some forms of language definition do not include a written specification, which makes any measurement of implementation conformance problematic.
Simple generator for compiler stress testing source
Since writing my C book I have been interested in the problem of generating source that has the syntactic and semantic statistical characteristics of human written code.
Generating code that obeys a language’s syntax is straight forward. Take a specification of the syntax (say is some yacc-like form) and ‘generate’ each of the terminals/nonterminals on the right-hand-side of the start symbol. Nonterminals will lead to rules having right-hand-sides that in turn need to be ‘generated’, a random selection being made when a nonterminal has more than one possible rhs rule. Output occurs when a terminal is ‘generated’.
For the code to mimic human written code it is necessary to bias the random selection process; a numeric value at the start of each rhs rule can be used to specify the percentage probability of that rule being chosen for the corresponding nonterminal.
The following example generates a subset of C expressions; nonterminals in lowercase, terminals in uppercase and implemented as a call to a function having that name:
%grammar first_rule : def_ident " = " expr " ;n" END_EXPR_STMT ; def_ident : MK_IDENT ; constant : MK_CONSTANT ; identifier : KNOWN_IDENT ; primary_expr : 30 constant | 60 identifier | 10 " (" expr ") " ; multiplicative_expr : 50 primary_expr | 40 multiplicative_expr " * " primary_expr | 10 multiplicative_expr " / " primary_expr ; additive_expr : 50 multiplicative_expr | 25 additive_expr " + " multiplicative_expr | 25 additive_expr " - " multiplicative_expr ; expr : START_EXPR additive_expr FINISH_EXPR ; |
A 250 line awk program (awk only because I use it often enough for simply text processing that it is second nature) translates this into two Python lists:
productions = [ [0], [ 1, 1, 1, # first_rule 0, 5, [2, 1001, 3, 1002, 1003, ], ], [ 2, 1, 1, # def_ident 0, 1, [1004, ], ], [ 4, 1, 1, # constant 0, 1, [1005, ], ], [ 5, 1, 1, # identifier 0, 1, [1006, ], ], [ 6, 3, 0, # primary_expr 30, 1, [4, ], 60, 1, [5, ], 10, 3, [1007, 3, 1008, ], ], [ 7, 3, 0, # multiplicative_expr 50, 1, [6, ], 40, 3, [7, 1009, 6, ], 10, 3, [7, 1010, 6, ], ], [ 8, 3, 0, # additive_expr 50, 1, [7, ], 25, 3, [8, 1011, 7, ], 25, 3, [8, 1012, 7, ], ], [ 3, 1, 1, # expr 0, 3, [1013, 8, 1014, ], ], ] terminal = [ [0], [ STR_TERM, " = "], [ STR_TERM, " ;n"], [ FUNC_TERM, END_EXPR_STMT], [ FUNC_TERM, MK_IDENT], [ FUNC_TERM, MK_CONSTANT], [ FUNC_TERM, KNOWN_IDENT], [ STR_TERM, " ("], [ STR_TERM, ") "], [ STR_TERM, " * "], [ STR_TERM, " / "], [ STR_TERM, " + "], [ STR_TERM, " - "], [ FUNC_TERM, START_EXPR], [ FUNC_TERM, FINISH_EXPR], ] |
which can be executed by a simply interpreter:
def exec_rule(some_rule) : rule_len=len(some_rule) cur_action=0 while (cur_action < rule_len) : if (some_rule[cur_action] > term_start_base) : gen_terminal(some_rule[cur_action]-term_start_base) else : exec_rule(select_rule(productions[some_rule[cur_action]])) cur_action+=1 productions.sort() start_code() ns=0 while (ns < 2000) : # Loop generating lots of test cases exec_rule(select_rule(productions[1])) ns+=1 end_code() |
Naive syntax-directed generation results in a lot of code that violates one or more fundamental semantic constraints. For instance the assignment (1+1)=3 is syntactically valid in many languages, which invariably specify a semantic constraint on the lhs of an assignment operator being some kind of modifiable storage location. The simplest solution to this problem is to change the syntax to limit the kinds of constructs that can be generated on the lhs of an assignment.
The hardest semantic association to get right is the connection between variable declarations and references to those variables in expressions. One solution is to mimic how I think many developers write code, that is to generate the statements first and then generate the required definitions for the appropriate variables.
A whole host of minor semantic issues require the syntax generated code to be tweaked, e.g., division by zero occurs more often in untweaked generated code than human code. There are also statistical patterns within the semantics of human written code, e.g., frequency of use of local variables, that need to be addressed.
A few weeks ago the source of Csmith, a C source generator designed to stress the code generation phase of a compiler, was released. Over the years various people have written C compiler stress testers, most recently NPL implemented one in Java, but this is the first time that the source has been released. Imagine my disappointment on discovering that Csmith contained around 40 KLOC of code, only a bit smaller than a C compiler I had once help write. I decided to see if my ‘human characteristics’ generator could be used to create a compiler code generator stress tester.
The idea behind compiler code generator stress testing is to generate a program containing some complicated sequence of code, compile and run it, comparing the value produced against the value that is supposed to be produced.
I modified the human characteristics generator to produce pairs of statements like the following:
i = i_3 * i_6 & i_2 << i_7 ; chk_result(i, 3 * 6 & 2 << 7, __LINE__); |
the second argument to chk_result is the value that i should contain (while generating the expression to assign to i the corresponding constant expression with the variables replaced by their known values is also created).
Having the compiler evaluate the constant expression simplifies the stress tester and provides another check that the compiler gets things right (or gets two different things wrong in the same way, in which case we probably don’t get to see any failure message). The first gcc bug I found concerned this constant expression (in fact this same compiler bug crops up with alarming regularity in the generated code).
As previously mentioned connecting variables in expressions to a corresponding definition is a lot of work. I simplified this problem by assuming that an integer variable i would be predefined in the surrounding support code and that this would be the only variable ever assigned to in the generated code.
There is some simple house-keeping that wraps everything within a program and provides the appropriate variable definitions.
The grammar used to generate full C expressions is 228 lines, the awk translator 252 lines and the Python interpreter 55 lines; just over 1% of Csmith in LOC and it is very easy to configure. However, an awful lot functionality needs to be added before it starts to rival Csmith, not least of which is support for assignment to more than one integer variable!
A change of guard in the C standard’s world?
I have just gotten back from the latest ISO C meeting (known as WG14 in the language standard’s world) which finished a whole day ahead of schedule; always a good sign that things are under control. Many of the 18 people present in London were also present when the group last met in London four years ago and if memory serves this same subset of people were also attending meetings 20 years ago when I traveled around the world as UK head of delegation (these days my enthusiasm to attend does not extend to leaving the country).
The current convenor, John Benito, is stepping down after 15 years and I suspect that many other active members will be stepping back from involvement once the current work on revising C99 is published as the new C Standard (hopefully early next year meaning it will probably be known as C12).
From the very beginning the active UK participants in WG14 have held one important point of view that has consistently been at odds with a view held by the majority of US participants; we in the UK have believed that it should be possible to deduce the requirements contained in the C Standard without reference to any deliberations of WG14, while many US participants have actively argued against what they see as over specification. I think one of the problems with trying to change US minds has been that the opinion leaders have been involved for so long and know the issues so well they cannot see how anybody could possible interpret wording in the standard in anything other than the ‘obvious’ way.
An example of the desire to not over specify is provided by a defect report I submitted 18 years ago, in particular question 19; what does:
#define f(a) a*g #define g(a) f(a) f(2)(9) |
expand to? There are two possibilities and WG14 came to the conclusion that both were valid macro expansions, making the behavior unspecified. However, when it came to a vote the consensus came down on the side of saying nothing about this case in the normative body of the standard, the only visible evidence for this behavior being a bulleted item added to the annex containing the list of unspecified behaviors.
A new member of WG14 (he has only been involved for a few years) spotted this bulleted item that had no corresponding text in the main body of the standard, tracked down the defect report that generated it and submitted a new defect report asking for wording to be added. At the meeting today the straw poll of those present was in favor of adding an appropriate example to C12 {I will link to the appropriate paper once it appears on the public WG14 site}. A minor victory on the road to a full and complete specification.
It will be interesting to see what impact a standing down of the old guard, after the publication of C12, has C2X (the revision of C that is likely to be published around 10 years from now).
For those of you still scratching their head, the two possibilities are:
2*f(9) |
or
2*9*g |
ISO Standards, the beauty and the beast
Standards is one area where a monopoly can provide a worthwhile benefit. After all the primary purpose of a standard for something is having just the one document for everybody to follow (having multiple standards because they are so useful is not a good idea). However, a common problem with monopolies is that charge a very inflated price for their product.
Many years ago the International Standard Organization settled on a pricing scheme for ISO Standards based on document page count. Most standards are very short and have a very small customer base, so there is commercial logic to having a high cost per page (especially since most are bought by large companies who need a copy if they do business in the corresponding application domain). Programming language standards do not fit this pattern, often being very long and potentially having a very large customer base.
With over 18,500 standards in their catalogue ISO might be forgiven for overlooking the dozen or so language standards, or perhaps they figured there is as much profit in charging a few hundred pounds on a few sales as charging less on more sales.
How does the move to electronic distribution effect prices? For a monopoly electronic distribution is an opportunity to make more profit, not to reduce prices. The recently published revision of the Fortran Standard is available for 338 Swiss francs (around £232) from ISO and £356 from BSI (at $351 the price from ANSI in the US is similar to ISO’s). Many years ago, at the dawn of the Internet, members of the US C Standard committee were able to convince ANSI to sell electronic copies at a reasonable rate ($30) and this practice has continued ever since (and now includes C++).
The market for the C and C++ Standards is sufficiently large that a commercial publisher (Wiley) was willing to take the risk of publishing them in book form (after some prodding and leg work by the likes of Francis Glassborow). It will be interesting to see if a publisher is willing to take a chance on a print run of the revised C Standard due out in a few years (I think the answer for the revised C++ Standard is more obvious).
Don’t Standards bodies care about computer languages? Unfortunately we are thorn in their side and they would be happy to be rid of us (but their charter’s do not allow them to do this). Our standards take much longer to produce than other standards, they are large and sales are almost non-existent (at ISO/BSI prices). What is more many of those involved in creating these standards actively subvert ISO/BSI sales by making draft documents, that are very close to the final copyrighted versions, freely available over the Internet.
In a sense ISO programming language standards exist because the organizational structure requires them to accept our work proposals and what we do does not have a large enough impact within the standards world for them to try and be rid of those tiresome people whose work is so far removed from what everybody else does.
Language usage in Google’s ngram viewer
I thought I would join the fun that people are having with Google’s new ngram viewer. The raw data (only a subset for bigrams and longer ngrams) was also enticing, but at 35+ gigabytes for the compressed 1/2/3-grams of English-all I decided to forgo the longer n-grams.
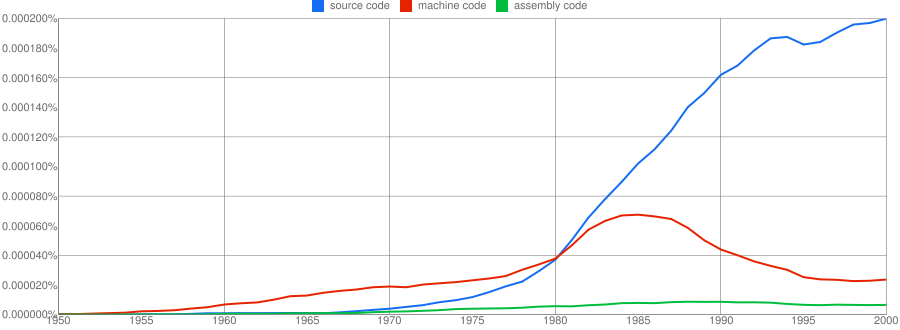
We all know that in the dim and distant past most programmers wrote in machine code, but it was not until 1980 that “source code” appeared more frequently in books that “machine code”.
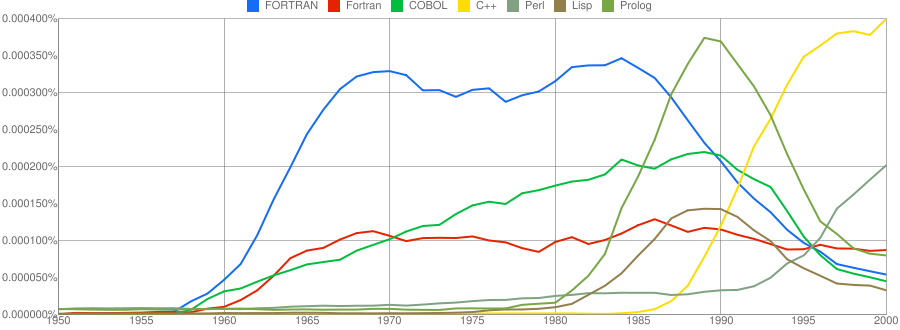
Computer language popularity is a perennial question. Fortran and Cobol address very different markets and I would have expected their usage to follow similar patterns, with “COBOL” having the obvious usage pattern for them both to follow. Instead, both “FORTRAN” and “Fortran” peaked within 10 years, with one staying there for another 20 years before declining and the other still going strong in 2000 (and still ahead of “PHP” and “Python” in 2000; neither shown to keep the clutter down). I am surprised to see “Prolog” usage being so much greater than “Lisp” and I would have expected “Lisp” to have a stronger presence in the 1970s.
I think the C++ crowd will be surprised to see that in 2000 usage was not much greater than what “FORTRAN” had enjoyed for 20 years.
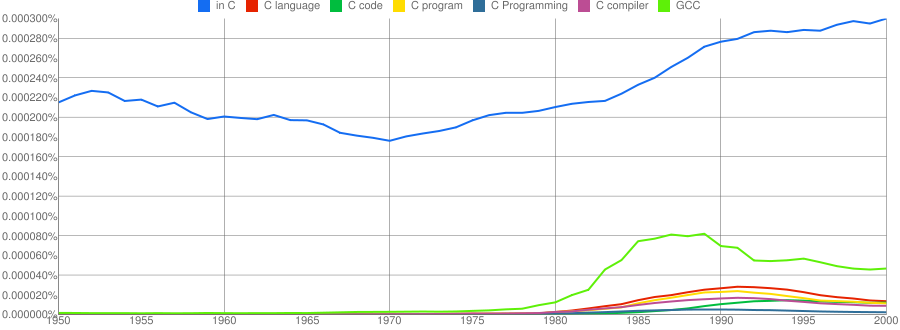
“C”, as in language, usage is obviously different to reliably measure. I have tried the obvious bigrams. Looking at some of the book matches for the phrase “in C” shows that the OCR process has sometimes inserted spaces that probably did not exist in the original, the effect being to split words and create incorrect bigrams. The phrase “in C” would also appear in books on music.
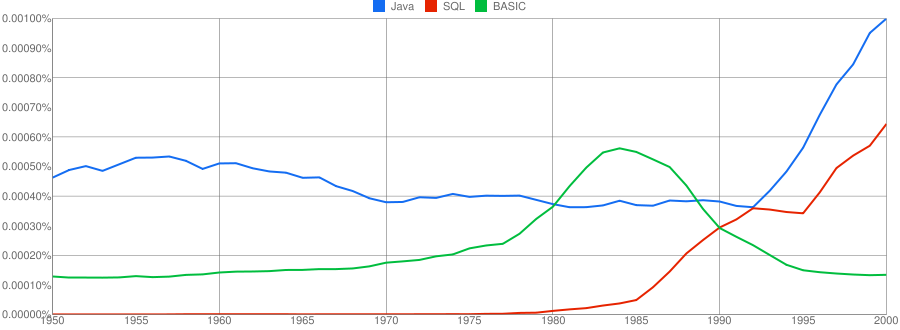
I have put the three words “Java”/”SQL”/”BASIC” in a separate plot because their usage swamps that of the other languages. Java obviously has multiple non-computer related uses and subtracting the estimated background usage suggests a language usage similar to that of “SQL”. There is too much noise for the usage of “Basic” to tell us much.
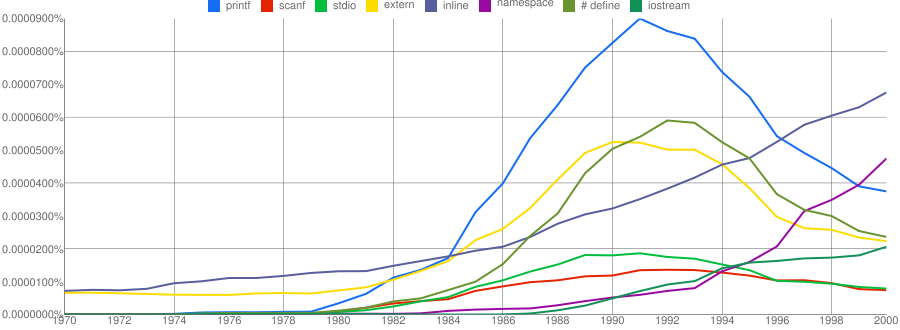
One way of comparing C/C++ language usage is to look source code usage where they are likely to differ. I/O, in the form of printf/scanf and stdio/iostream, is one obvious choice and while the expected C usage starts to declines in the 1990s the C++ usage just shows a stead growth (perhaps the <</>> usage, which does not appear in the Google viewer, has a dramatic growth during this time period).
Surprisingly #define also follows a similar pattern of decline. Even allowing for the rabid anti-macro rhetoric of the C++ in-crowd I would not have expected such a rapid decline. Perhaps this is some artifact of the book selection process used by Google; but then "namespace" shows a healthy growth around this time period.
The growth of "inline" over such a long period of time is a mystery. Perhaps some of this usage does not relate to a keyword appearing within source code examples but to text along the lines of "put this inline to make it faster".
What usage should we expect for the last decade? A greater usage of "PHP" and "Python" is an obvious call to make, along with the continuing growth of SQL, I think "UML" will also feature prominently. Will "C++" show a decline in favor or "Java" and what about "C#"? We will have to wait and see.
Build an ISO Standard and the world will beat a path to your door
An email I received today, announcing the release of version 1.0 of the GNU Modula-2 compiler, reminded me of some plans I had to write something about a proposal to add some new definitions to the next version of the ISO C Standard.
In the 80s I was heavily involved in the Pascal community and some of the leading members of this community thought that the successor language designed by Niklaus Wirth, Modula-2, ought to be the next big language. Unfortunately for them this view was not widely shared and after much soul searching it was decided that the lack of an ISO standard for the language was responsible for holding back widespread adoption. A Modula-2 ISO Standard was produced and, as they say, the rest is history.
The C proposal involves dividing the existing definition undefined behavior into two subcategories; bounded undefined behavior and critical undefined behavior. The intent is to provide guidance to people involved with software assurance. My long standing involvement with C means that I find the technical discussions interesting; I have to snap myself out of getting too involved in them with the observation that should the proposals be included in the revised C Standard they will probably have the same impact as the publication of the ISO Standard had on Modula-2 usage.
The only way for changes to an existing language standard to have any impact on developer usage is for them to require changes to existing compiler behavior or to specify additional runtime library functionality (e.g., Extensions to the C Library Part I: Bounds-checking interfaces).
What language was an executable originally written in?
Apple have recently added an unusual requirement to the iPhone developer agreement “Applications must be originally written in Objective-C, C, C++, or JavaScript …”. As has been pointed out elsewhere the real purpose is stop third party’s from acquiring any control over application development on Apple’s products; the banning of other languages is presumably regarded as acceptable collateral damage.
Is it possible to tell by analyzing an executable what language it was originally written in?
There are two ways in which executables contain source language ‘signatures’. Detecting these signatures requires knowledge of specific compiler behavior, i.e., a database of information about the behavior of compilers capable of creating the executables is needed.
Runtime library. Most compilers make use of a language specific runtime library, rather than generating inline code for some kinds of functionality. For instance, setjmp/longjmp in C and vtables in C++.
The presence of a known C runtime library does not guarantee that the application was originally written in C; it could have been written in Java and converted to C source.
The absence of a known C runtime library could mean that the source was compiled by a C compiler using a runtime system unknown to the analyzer.
The presence of a known Java, for instance, runtime library would suggest that the original source contained some Java. This kind of analysis would obviously require that the runtime library database not restrict itself to the ‘C’ languages.
Compiler behavior patterns. There is usually more than one way in which a source language construct can be translated to machine code and a compiler has to pick one of them. The perfect optimizing compiler would always make the optimal choice, but real compilers follow a fixed pattern of code generation for at least some language constructs (e.g., initialization of registers on function entry).
The presence of known code patterns in an executable is evidence that a particular compiler has been used; how much depends on the likelihood it could have been generated by other means and how many other patterns suggest the same compiler. In the case of the GNU Compiler Collection the source language might also be Fortran, Java or Ada; I don’t know enough about the behavior of GCC to provide an informed estimate of whether it is possible to recognize the source language from the translated form of constructs shared by several languages, I suspect not.
The fact that an executable can be decompiled to C is not a guarantee that it was originally written in C.
Some languages support source language constructs whose corresponding machine code is unlikely to ever be generated by source from another language. The Fortran computed goto allows constructs to be written that have no equivalent in the other languages supported by GCC (none of them allow statement labels appearing in a multi-way jump to appear before the jump test):
10 I=I+1 20 J=J+1 goto (10, 20, 30, 40) J 30 I=I+3 40 I=I*2 |
The presence of a compiled form of this kind of construct in the executable would be very suggestive of Fortran source.
Apple are famously paranoid and control freakery. It will be very interesting to see what level of compliance checking they decide to perform on executables submitted to the App Store.
On another note: What does “originally written” mean? For instance, many of the mathematical functions (e.g., sine, log, gamma, etc) contained in R were originally written in Fortran and translated to C for use in R; this C source is what is now maintained. Does this historical implementation decision mean that R cannot be legally ported to the iPhone?
Dimensional analysis of source code
The idea of restricting the operations that can be performed on a variable based on attributes appearing in its declaration is actually hundreds of years old and is more widely known as dimensional analysis. Readers are probably familiar with the concept of type checking where, for instance, a value having a floating-point type is not allowed to be added to a value having a pointer type. Unfortunately, many of those computer languages that support the functionality I am talking about (e.g., Ada) also refer to it as type checking and differentiate it from the more common usage by calling it strong typing. The concept would be much easier for people to understand if a different term were used, e.g., unit checking or even dimension checking.
Dimensional analysis, as used in engineering and the physical sciences, relies on the fact that quantities are often expressed in terms of a small number of basic attributes, e.g., mass, length and time; velocity is calculated by dividing a length by a time,  and area is calculated by multiplying two lengths,
and area is calculated by multiplying two lengths,  . Adding a length quantity to a velocity has no physical meaning and suggests that something is wrong with the calculation, while dividing velocity by time,
. Adding a length quantity to a velocity has no physical meaning and suggests that something is wrong with the calculation, while dividing velocity by time,  , can be interpreted as acceleration. Dividing two quantities that have the same units results in what is known as a dimensionless number.
, can be interpreted as acceleration. Dividing two quantities that have the same units results in what is known as a dimensionless number.
Dimensional analysis can be used to check a calculation involving physical quantities for internal consistency and as a method for trying to deduce the combinations of quantities that an unknown equation might contain based on the physical units the result is known to be represented in.
The frink language has units of measure checking built into it.
How might dimensional analysis be used to check source code for internal consistency? Consider the following code:
x = a / b; c = a; y = c / b; if (x + y ... ... z = x + b; |
c is assigned a‘s value and is therefore assumed to have the same units of measurement. The value assigned to y is calculated by dividing c by b and the train of reasoning leading to the assumption that it has the same units of measurement as x is easy to follow. Based on this analysis, there is nothing suspicious about adding x and y, but adding x and b looks wrong (it would be perfectly ok if all of the variables in this code were dimensionless).
A number of tools have been written to check source code expressions for internal consistency e.g., Fortran (Automated computation and consistency checking of physical dimensions and units in scientific programs), C++ (Applied Template Metaprogramming in SI units) and C (Annotation-less Unit Type Inference for C), but so far only one PhD.
Providing a mechanism for developers to add unit information to variable declarations would enable compilers to perform consistency checks and reduce the likelihood of false positives being reported (because dimensionless values can generally be combined in any way). It is too late in the day for such a major feature to be added to the next revision of the C++ standard; the C standard is also being revised, but the committee is currently being very conservative and insists that any proposed new constructs already be implemented in at least one compiler.
Assuming compilers are clever enough (part 1)
Developers often assume the compiler they use will do all sorts of fancy stuff for them. Is this because they are lazy and happy to push responsibility for parts of the code they write on to the compiler, or do they actually believe that their compiler does all the clever stuff they assume?
An example of unmet assumptions about compiler performance is the use of const in C/C++, final in Java or readonly in other languages. These are often viewed as a checking mechanism, i.e., the developer wants the compiler to check that no attempt is made to, accidentally, change the value of some variable, perhaps via code added during maintenance.
The surprising thing about variables in source code is that approximately 50% of them don’t change once they have been assigned a value (A Theory of Type Qualifiers for C measurements and Automatic Inference of Stationary Fields for Java).
Developers don’t use const/final qualifiers nearly as often as they could. Most modern compilers can deduce if a locally defined variable is only assigned a value once and make use of this fact during optimization. It takes a lot more resources to deduce this information for non-local variables; developers want their compiler to be fast and so implementors don’t won’t them waiting around while whole program analysis is performed.
Why don’t developers make more use of const/final qualifiers? Is this usage, or lack of, an indicator that developers don’t have an accurate grasp of variable usage, or that they don’t see the benefit of using these qualifiers or perhaps they pass responsibility on to the compiler (program size seems to grow sufficiently fast that whole program optimization often consumes more memory than likely to be available; and when are motherboards going to break out of the 4G limit?)
Recent Comments