Archive
Writing language standards is a cottage industry
In the beginning programming language standards were written by one country’s National Standards body (e.g., ANSI did C/Cobol/Fortran for the USA and BSI did Pascal for the UK) and other countries were free to write their own version, adopt the existing work or do nothing (I don’t know of any country writing their own version, a few countries sometimes stuck their own front page on an existing document and the majority did nothing; update 4 Dec 2012, thanks to David Muxworthy for pointing out that around 1974 the UK, US, Japan and ECMA were all independently developing a standard for BASIC, by 1982 this had evolved to just ANSI and ECMA).
The UK people who created the Pascal Standard wanted the rest of the world (i.e., the US) to adopt it, and the way to do this was to have it adopted as an ISO Standard. The experience of making this happen convinced the folk at BSI that in future, language standards should be produced as an international effort within ISO (those pesky Americans wanted changes made to the document before they would vote for it).
During the creation of the first C Standard various people from Europe joined the ANSI committee, X3J11, so they could take part. Initially the US members were not receptive to the European request for a mechanism to handle keyboards that did not contain certain characters (e.g., left/right square brackets) but responded promptly on hearing that those (pesky) Europeans planned to publish an ISO C Standard that would contain those changes to the ANSI Standard needed to support trigraphs; the published ANSI Standard included support for trigraphs. The C ANSI committee were very receptive to the idea of future work being done at the ISO level; Bill Plauger/Tom Plum did a lot of good work to ensure it happened.
The C++ language came along and long story short an ISO committee was set up to create an ISO Standard for it, then Java came along and the Java Study Group failed to become an ISO committee and then various non-specific language committees happened.
A look at the SC22 website shows that ISO Standards exist for Forth and ECMAscript (it has not yet been updated to include Ruby) with no corresponding ISO committees. What is going on?
One could be cynical and say that special interests are getting a document of their choosing accepted by ECMA and then abusing the ISO fast track procedure to sidestep the need to set up an international committee that has the authority to create a document of its choosing. The reality is that unless a language is very widely used by lots of people (e.g., in the top five or so most commonly used languages) there are unlikely to be enough people (or employers) willing and able to commit the time and money needed to be actively involved in an ISO Standard committee.
Once a document has been fast tracked to become ISO Standard, any updates to it are supposed to be carried out under ISO rules (i.e., an ISO committee). In practice this is not happening with ECMAscript which continues to be very active (I don’t know what is happening with Forth or how the Ruby people plan to handle any updates), holding bi-monthly meetings; over the years they have fast tracked two revisions to the original fast tracked document (the UK did raise the issue during balloting but nothing came of it, I don’t think anybody really cares).
Would moving the ECMAscript development work from ECMA to ISO make a worthwhile difference? There might be a few people out there who would attend an ISO meeting who are not currently attending ECMA meetings (to join ECMA companies with five or fewer employees pay an annual fee of 3,500 Swiss francs {about the same number of US dollars} and larger companies pay a lot more) but I suspect the number would not be large enough to make up for the extra hassle of running an ISO committee (e.g., longer ISO balloting timescales).
Production of programming language standards is really a cottage industry that relies on friends in high places (e.g., companies with an existing membership of ECMA or connections into the local country standards’ body) for them to appear on the international stage.
Would you buy second hand software from a formal methods researcher?
I have been reading a paper on formally proving software correct (Bridging the Gap: Automatic Verified Abstraction of C by Greenaway, Andronick and Klein) and as often the case with papers on this topic the authors have failed to reach the level of honest presentation required by manufacturers of soap power in their adverts.
The Greenaway et al paper describes a process that uses a series of translation steps to convert a C program into what is claimed to be a high level specification in Isabelle/HOL (a language+support tool for doing formal proofs).
The paper was published by an Australian research group; I could not find an Australian advertising standards code dealing with soap power but did find one covering food and beverages. Here is what the Australian Association of National Advertisers has to say in their Food & Beverages Advertising & Marketing Communications Code:
“2.1 Advertising or Marketing Communications for Food or Beverage Products shall be truthful and honest, shall not be or be designed to be misleading or deceptive or otherwise contravene Prevailing Community Standards, and shall be communicated in a manner appropriate to the level of understanding of the target audience of the Advertising or Marketing Communication with an accurate presentation of all information…”
So what claims and statements do Greenaway et al make?
2.1 “Before code can be reasoned about, it must first be translated into the theorem prover.” A succinct introduction to one of the two main tasks, the other being to prove the correctness of these translations.
“In this work, we consider programs in C99 translated into Isabelle/HOL using Norrish’s C parser … As the parser must be trusted, it attempts to be simple, giving the most literal translation of C wherever possible.”
“As the parser must be trusted”? Why must it be trusted? Oh, because there is no proof that it is correct, in fact there is not a lot of supporting evidence that the language handled by Norrish’s translator is an faithful subset of C (ok, for his PhD Norrish wrote a formal semantics of a subset of C; but this is really just a compiler written in mathematics and there are umpteen PhDs who have written compilers for a subset of C; doing it using a mathematical notation does not make it any more fault free).
The rest of the paper describes how the output of Norrish’s translator is generally massaged to make it easier for people to read (e.g., remove redundant statements and rename variables).
Then we get to the conclusion which starts by claiming: “We have presented a tool that automatically abstracts low-level C semantics into higher-level specifications with automatic proofs of correctness for each of the transformation steps.”
Oh no you didn’t. There is no proof for the main transformation step of C to Isabelle/HOL. The only proofs described in the paper are for the post processing fiddling about that was done after the only major transformation step.
And what exactly is this “high-level specification”? The output of the Norrish translator was postprocessed to remove the clutter that invariably gets generated in any high-level language to high-level language translator. Is the result of this postprocessing a specification? Surely it is just a less cluttered representation of the original C?
Actually this paper does contain a major advance in formally proving software correct, tucked away at the start it says “As the parser must be trusted…”. There it is in black and white, if you have some software that must be trusted don’t bother with formal proofs just simply follow the advice given here.
But wait a minute you say, I am ignoring the get out of jail wording “… shall be communicated in a manner appropriate to the level of understanding of the target audience …”. What is the appropriate level of understanding of the target audience, in fact who is the target audience? Is the target audience other formal methods researchers who are familiar with the level of intellectual honesty within their field and take claims made by professional colleagues with a pinch of salt? Are non-formal methods researchers not the target audience and so have no redress to being misled by the any claims made by papers in this field?
A free pdf that is not the C++ Standard
One of the most annoying things about working on programming language standards is to see the exorbitant price ISO charge for the final published document created by experts toiling away for free over many years. This practice is unlikely to change.
Once a document has been through a successfully ballot (i.e., accepted for publication as a Standard) ISO has very strict rules about what changes can be made to it prior to actual publication (only typos of the most very innocuous kind can be fixed). Of course programming language committees live on after the publication of a Standard by ISO and it is very useful for them if the document they start deliberating on is one that has had all the typos corrected, not just the really innocuous ones.
The list of typos in the 2011 C++ Standard have been fixed in the freely down loadable committee document N3337 that is not the official C++ Standard, however uncannily similar it may look (no ISO gobbledygook at the front for instance). The equivalent committee document for C is not yet available on the WG14 site.
If you really do need a copy of the C++ Standard the 2011 (i.e., latest) document in pdf form is available for $30 from ANSI; the 2011 C Standard is also available for the same price. Don’t worry about the ANSI version being dated 2012 rather than 2011; National Standards bodies must sell the ISO version at ISO prices but are allowed to publish localized versions for which they can set their own price (so you pay less and get various US specific acronyms and verbiage printed on the front cover).
Generating code that looks like it is human written
I am very interested in understanding the patterns of developer behavior that lead to the human characteristics that can be found in code. To help me get some idea of how well I understand this behavior I have decided to build a tool that generates source code that appears to be written by human programmers. I hope to reach a point where I can offer a challenge to tell the difference between generated code and human written code.
The three main production techniques I plan to use are, in increasing order of relatedness to humans production techniques, are:
- Random generation based on percentage occurrence of language constructs obtained from measurements of existing source. This is the simplest approach and the one furthest away from common developer behavior; even so there are things that can be learned from this information. For instance, the theory that developers are more likely to create a function once code becomes heavily nested code implies that the probability of encountering an if-statement decreases as nesting depth increases; measurements show the probability of encountering an if-statement remaining approximately constant as depth of nesting increases.
- Behavior templates. People have habits in everyday life and also when writing software. While some habits are idiosyncratic and not encountered very often there are some that appear to be generally used. For instance, developers tend to assign a fixed role to every variable they define (e.g., stepper for stepping through a succession of values and most-recent holder holding the latest value encountered in going through a succession of values).
I am expecting/hoping that generation by behavioral templates will result in code having some of the probabilistic properties seen in human code, removing the need for purely random generation driven by low level language probability measurements. For instance, the probability of a local variable appearing in a function is proportional to the percentage of its previous occurrences up to that point in the source of the function (
percentage = occurrences_of_X / occurrences_of_all_local_variables) and I am hoping that this property appears as emergent behavior from generating using the role of variable template. - Story telling. A program is like the plot of a story, it has a cast of characters (e.g., classes, functions, libraries) that perform various actions and interact with each other in order to achieve various goals, there are subplots (intermediate results are calculated, devices are initialized, etc), there are resource limits, etc.
While a lot of stories are application domain specific there are subplots common to many stories; also how a story is told can be heavily influenced by the language used, for instance Prolog programs have a completely different structure than those written in procedural languages such as Java. I want to stay away from being application specific and I don’t plan to tackle languages too far outside the common-or-garden procedural variety.
Researchers have created automatic story generators; the early generators were template based while more recent systems have used an agent based approach. Story based generation of code is my ideal, but I am a long way away from having enough knowledge of developer behavior to be more than template based.
In a previous post I described a system for automatically generating very simply C programs. I plan to build on this system to incrementally improve the ‘humanness’ of the generated code. At some point, hopefully before the end of this year, I will challenge people to tell the difference between automatically generated and human written code.
The language I have studied the most is C and this will be the main target. I don’t want to be overly C specific and am trying to decide on a good second language (i.e., lots of source available for measurement, used by lots of developers and not too different from C). JavaScript is the current front runner, it is a class-less object oriented language which is not ‘wildly’ OO (the patterns of usage in human written OO code continue to evolve at a rapid rate which can make a lot of human C++/Java code look automatically generated).
As well as being a test bed for understanding of human generated code other uses for an automatic generator include compiler stress testing and providing code snippets to an automated fault fixing tool.
What I know of Dennis Ritchie’s involvement with C
News that Dennis Ritchie died last weekend surfaced today. This private man was involved in many ground breaking developments; I know something about one of the languages he designed, C, so I will write about that. Ritchie has written about the development of C language.
Like many language designers the book he wrote “The C Programming Language” (coauthored with Brian Kernighan in 1978) was the definitive reference for users; universally known as K&R. The rapid growth in C’s popularity led to lots of compilers being written, exposing the multiple ways it was possible to interpret some of the wording in K&R.
In 1983 ANSI set up a committee, X3J11, to create a standard for C. With one exception Ritchie was happy to keep out of the fray of standardization; on only one occasion did he feel strongly enough to step in and express an opinion and the noalias keyword disappeared from the draft (the restrict keyword surfaced in C99 as a different kind of beast).
A major contribution to the success of the C Standard was the publication of an “ANSI Standard” version of K&R (there was a red “ANSI C” stamp on the front cover and the text made use of updated constructs like function prototypes and enumeration types), its second edition in 1988. Fans of the C Standard could, and did, claim that K&R C and ANSI C were the same language (anybody using the original K&R was clearly not keeping up with the times).
Ritchie publicly admitted to making one mistake in the design of C. He thinks that the precedence of the & and | binary operators should have been greater than the == operator. I can see his point, but an experiment I ran a few years ago suggested it is amount of experience using a set of operator precedence rules that is the primary contributor to developer knowledge of the subject.
Some language designers stick with their language, enhancing it over the years (e.g., Stroustrup with C++), while others move on to other languages (e.g., Wirth with Pascal, Modula-2 and Oberon). Ritchie had plenty of other interesting projects to spend his time on and took neither approach. As far as I can tell he made little or no direct contribution to C99. As head of the research department that created Plan 9 he must have had some input to the non-Standard features of their C compiler (e.g., no support for #if and support for unnamed structures).
While the modern C world may not be affected by his passing, his ability to find simple solutions to complicated problems will be a loss to the projects he was currently working on.
Ruby becoming an ISO Standard
The Ruby language is going through the process of becoming an ISO Standard (it has been assigned the document number ISO/IEC 30170).
There are two ways of creating an ISO Standard, a document that has been accepted by another standards’ body can be fast tracked to be accepted as-is by ISO or a committee can be set up to write the document. In the case of Ruby a standard was created under the auspices of JISC (Japanese Industrial Standards Committee) and this has now been submitted to ISO for fast tracking.
The fast track process involves balloting the 18 P-members of SC22 (the ISO committee responsible for programming languages), asking for a YES/NO/ABSTAIN vote on the submitted document becoming an ISO Standard. NO votes have to be accompanied by a list of things that need to be addressed for the vote to change to YES.
In most cases the fast tracking of a document goes through unnoticed (Microsoft’s Office Open XML being a recent high profile exception). The more conscientious P-members attempt to locate national experts who can provide worthwhile advice on the country’s response, while the others usually vote YES out of politeness.
Once an ISO Standard is published future revisions are supposed to be created using the ISO process (i.e., a committee attended by interested parties from P-member countries proposes changes, discusses and when necessary votes on them). When the C# ECMA Standard was fast tracked through ISO in 2005 Microsoft did not start working with an ISO committee but fast tracked a revised C# ECMA Standard through ISO; the UK spotted this behavior and flagged it. We will have to wait and see where work on any future revisions takes place.
Why would any group want to make the effort to create an ISO Standard? The Ruby language designers reasons appear to be “improve the compatibility between different Ruby implementations” (experience shows that compatibility is driven by customer demand not ISO Standards) and government procurement in Japan (skip to last comment).
Prior to the formal standards work the Rubyspec project aimed to create an executable specification. As far as I can see this is akin to some of the tools I wrote about a few months ago.
IST/5, the committee at British Standards responsible for language standards is looking for UK people (people in other countries have to contact their national standards’ body) interested in getting involved with the Ruby ISO Standard’s work. I am a member of IST/5 and if you email me I will pass your contact details along to the chairman.
Quality of data analysis: two recent papers
Software engineering research has and continues to suffer from very low quality data analysis. The underlying problem is that practitioners are happy to go along with the status quo, not bothering to learn basic statistics or criticize data analysis in papers they are asked to review. Two recent papers I have read spring out as being at opposite ends of the spectrum.
In their paper A replicated survey of IT software project failures Khaled El Emam and A. Günes Koru don’t just list the mean values for the responses they get they also give the 95% confidence bounds on those values. At a superficial level this has the effect of making their results look much less interesting; for instance a quick glance at Table 3 “Reasons for project cancellation” suggests there is a significant difference between “Lack of necessary technical skills” at 22% and “Over schedule” at 17% but a look at the 95% confidence bounds, (6%–48%) and (4%–41%) respectively, shows that almost nothing can be said about the relative contribution of these two reasons (why publish these numbers, because nothing else has been published and somebody has to start somewhere). The authors understand the consequences of using a small sample size and have the integrity to list the confidence bounds rather than leave the reader to draw completely unjustified conclusions. I wish everybody was as careful and upfront about their analysis as these authors.
The paper Assessing Programming Language Impact on Development and Maintenance: A Study on C and C++ by Pamela Bhattacharya and Iulian Neamtiu takes some interesting ideas and measurements and completely mangles the statistical analysis (something the conference’s reviewers should have picked up on).
I encourage everybody to measure code and do statistical analysis. It looks like what happened here is that a PhD student got in over her head and made lots of mistakes, something that happens to us all when learning a new subject. The problem is that these mistakes made it through into a published paper and its conclusions are likely to repeated (these conclusions may or may not be true and it may or may not be possible to reliably test them from the data gathered, but the analysis presented in the paper faulty and so its conclusions cannot be trusted). I hope the authors will reanalyze their data using the appropriate techniques and publish an updated version of the paper.
Some of the hypothesis being tested include:
- C++ is replacing C as a main development language. The actual hypothesis tested is the more interesting question: “Is the percentage of C++ in projects that also contain substantial amounts of C growing at the expense of C?”
So the unit of measurement is the project and only four of these are included in the study; an extremely small sample size that must have an error bound of around 50% (no mention of error bounds in the paper). The analysis of the data claims to use linear regression but seems completely confused, lets not get bogged down in the details but move on to other more obvious mistakes.
- C++ code is of higher internal quality than C code. The data consists of various source code metrics, ignoring whether these are a meaningful measure of quality, lets look at how the numbers are analysed. I was somewhat surprised to read: “the distributions of complexity values … are skewed, thus arithmetic mean is not the right indicator of an ongoing trend. Therefore, …, we use the geometric mean …” While the arithmetic mean might not be a useful indicator (I have trouble seeing why not), use of the geometric mean is bizarre and completely wrong. Because of its multiplicative nature the geometric mean of a set of values having a fixed arithmetic mean decreases as its variance increases. For instance, the two sets of values (40, 60) and (20, 80) both have an arithmetic mean of 50, while their geometric means are 48.98979 (i.e.,
^0.5") ) and 40 (i.e.,
) and 40 (i.e., ^0.5") ) respectively.
) respectively.
So if anything can be said about the bizarre idea of comparing the geometric mean of complexity metrics as they change over time, it is that increases/decreases are an indicator of decrease/increase in variance of the measurements.
- C++ code is less prone to bugs than C code. The statistical analysis here made a common novice mistake. The null hypothesis tested was: “C code has lower or equal defect density than C++ code.” and this was rejected. The incorrect conclusion drawn was that “C++ code is less prone to bugs than C code.” Statistically one does not follow from the other, the data could be inconclusive and the researchers should have tested this question as the null hypothesis if this is the claim they wanted to make. There are also lots of question marks over other parts of the analysis, but this is the biggest blunder.
Fibonacci and JIT compilers
To maximize a compiler’s ability to generate high quality code many programming language standards do not specify the order in which the operands of a binary operator are evaluated. Most of the time the order of operand evaluation does not matter because all orders produce same final result. For instance in x + y the value of x may be obtained followed by obtaining the value of y and the two values added, alternatively the value of y may be obtained first followed by obtaining the value of x and the two values added; optimizers make use of local context information (e.g., holding one of the values in a register so it is immediately available for use in the evaluation of multiple instances of x) to work out which order produces the highest quality code.
If one of the operands is a function call that modifies the value of the other operand the result may depend on the order of evaluation. For instance, in:
int x; int set_x(void) { x=1; return 1; } int two_values(void) { x=0; return x + set_x(); } |
a left to right evaluation order of the return expression in two_values produces the value 1, while a right to left evaluation order produces the value 2. Every now and again developers accidentally write code that does something like this and are surprised to see program behavior change when they use different compiler options, a new version of the compiler or a different compiler (all things that can result in the order of evaluation changing for a given expression).
It is generally assumed that two calls to two_values within the same program will always produce the same answer, i.e., the decision on which order of evaluation to use is made at compile time and never changes while a program is running. Neither the C++ or C Standard requires that the evaluation order be fixed prior to program execution and use of a just-in-time compiler could result in the value returned by two_values alternating between 1 and 2. Some languages (e.g., Java) for which JIT compilers are expected to be used specify the exact order in which operands have to be evaluated.
One possible way of finding out whether a JIT compiler is being used for your C/C++ program is to test the values returned by two calls to two_values. A JIT compiler may, but is not required, to return different values on each call. Of course a decide-prior-to-execution C/C++ compiler does have the option of optimizing the following function to return true or false on the basis that the standard permits this behavior, but I would be very surprised to see this occur in practice:
bool Schrödinger(void) { return two_values() == two_values(); } |
The runtime variability offered by JIT compilers makes it possible to write a program whose output can be any value between  and
and  (the
(the  ‘th Fibonacci number, where
‘th Fibonacci number, where n is read from the input):
#include <stdio.h> int x; int set_x(int ret_val) { x=1; return ret_val; } int two_unspec(void) { x=0; return x + set_x(1); } int add_zero(val) { x=0; return val - x + set_x(0); } int fib(int fib_num) { if (fib_num > 3) return fib(fib_num-2) + add_zero(fib(fib_num-1)); else if (fib_num == 3) return two_unspec(); else return 1; } int main(void) { int n; scanf("%d", &n); printf("Fibonacci %d = %d\n", n, filb(n)); } |
The C-semantics tool will ‘execute’ this program and produce a list of the possible outputs (a PhD project under active development; the upper limit is currently around the 6th Fibonacci number which requires 11 hours and produces a 50G log file).
A decide-prior-to-execution compiler has a maximum choice of four possible outputs for a given input value and for a given executable the output produced by different input values will be perfectly correlated.
Fingerprinting the author of the ZeuS Botnet
The source code of the ZeuS Botnet is now available for download. I imagine there are a few organizations who would like to talk to the author(s) of this code.
All developers have coding habits, that is they usually have a particular way of writing each coding construct. Different developers have different sets of habits and sometimes individual developers have a way of writing some language construct that is rarely used by other developers. Are developer habits sufficiently unique that they can be used to identify individuals from their code? I don’t have enough data to answer that question. Reading through the C++ source of ZeuS I spotted a few unusual usage patterns (I don’t know enough about common usage patterns in PHP to say much about this source) which readers might like to look for in code they encounter, perhaps putting name to the author of this code.
The source is written in C++ (32.5 KLOC of client source) and PHP (7.5KLOC of server source) and is of high quality (the C++ code could do with more comments, say to the level given in the PHP code), many companies could increase the quality of their code by following the coding standard that this author seems to be following. The source is well laid out and there are plenty of meaningful variable names.
So what can we tell about the person(s) who wrote this code?
- There is one author; this is based on consistent usage patterns and nothing jumping out at me as being sufficiently different that it could be written by somebody else,
- The author is fluent in English; based on the fact that I did not spot any identifiers spelled using unusual word combinations that often occur when a developer has a poor grasp of English. Update 16-May: skier.su spotted four instances of the debug message “Request sended.” which suggests the author is not as fluent as I first thought.
- The usage that jumped out at me the most is:
for(;; p++)if(*p == '\\' || *p == '/' || *p == 0) { ...
This is taking to an extreme the idea that if a ‘control header’ has a single statement associated with it, then they both appear on the same line; this usage commonly occurs with if-statements and this for/while-statement usage is very rare (this usage also occurs in the PHP code),
- The usage of
true/falsein conditionals is similar to that of newbie developers, for instance writing:return CWA(kernel32, RemoveDirectoryW)(path) == FALSE ? false : true; // and return CWA(shlwapi, PathCombineW)(dest, dir, p) == NULL ? false : true; // also return CWA(kernel32, DeleteFileW)(file) ? true : false;
in a function returning
boolinstead of:return CWA(kernel32, RemoveDirectoryW)(path); //and return CWA(shlwapi, PathCombineW)(dest, dir, p) != NULL // and return CWA(kernel32, DeleteFileW)(file);
The author is not a newbie developer, perhaps sometime in the past they were badly bitten by a Microsoft C++ compiler bug, found that this usage worked around the problem and have used it ever since,
- The author vertically aligns the assignment operator in statement sequences but not in a sequence of definitions containing an initializer:
// = not vertically aligned here DWORD itemMask = curItem->flags & ITEMF_IS_MASK; ITEM *cloneOfItem = curItem; // but is vertically aligned here: desiredAccess |= GENERIC_WRITE; creationDisposition = OPEN_ALWAYS;
Vertical alignment is not common and I would have said that alignment was more often seen in definitions than statements, the reverse of what is seen in this code,
- Non-terminating loops are created using
for(;;)rather than the more commonly seenwhile(TRUE), - The author is happy to use
gototo jump to the end of a function, not a rare habit but lots of developers have been taught that such usage is bad practice (I would say it depends, but that discussion belongs in another post), - Unnecessary casts often appear on negative constants (unnecessary in the sense that the compiler is required to implicitly do the conversion). This could be another instance of a previous Microsoft compiler bug causing a developer to adopt a coding habit to work around the problem.
Could the source have been processed by an code formatter to remove fingerprint information? I think not. There are small inconsistencies in layout here and there that suggest human error, also automatic layout tends to have a ‘template’ look to it that this code does not have.
Update 16 May: One source file stands out as being the only one that does not make extensive use of camelCase and a quick search finds that it is derived from the ucl compression library.
Unused function parameters
I have started redoing the source code measurements that appear in my C book, this time using a lot more source, upgraded versions of existing tools, plus some new tools such as Coccinelle and R. The intent is to make the code and data available in a form that is easy for others to use (I am hoping that one or more people will measure the same constructs in other languages) and to make some attempt at teasing out relationships in the data (previously the data was simply plotted with little or no explanation).
While it might be possible to write a paper on every language construct measured, I don’t have the time to do the work. Instead, I will use this blog to make a note of the interesting things that crop up during the analysis of each construct I measure.
First up are unused function parameters (code and data), which at around 11% of all parameters are slightly more common than unused local variables (Figure 190.1). In the following plot black circles are the total number of functions having a given number of parameters, red circles a given number of unused parameters, blue line a linear regression fit of the red circles, and the green line is derived from black circle values using a formula I concocted to fit the data and have no theoretical justification for it.
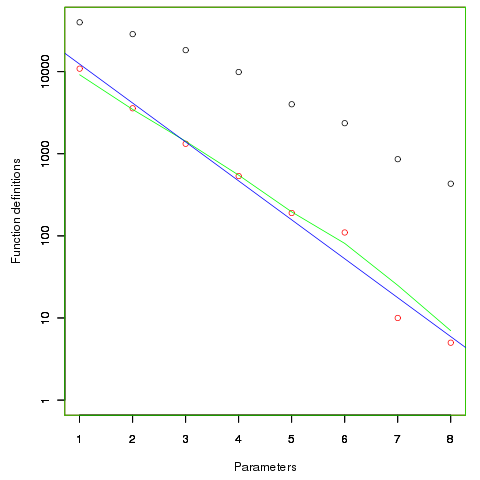
The number of functions containing a given number of unused parameters drops by around a factor of three for each additional unused parameter. Why is this? The formula I came up with for estimating the number of functions containing  unused parameters is:
unused parameters is:  , where
, where  is the total number of function definitions containing
is the total number of function definitions containing  parameters.
parameters.
Which parameter, for those functions defined with more than one, is most likely to be unused? My thinking was that the first parameter might either hold the most basic information (and so rarely be unused) or hold information likely to be superseded when new parameters are added (and so commonly be unused), either way I considered later parameters as often being put there for later use (and therefore more likely to be unused). The following plot is for eight programs plus the sum of them all; for all functions defined with between one and eight parameters, the percentage of times the ‘th parameter is unused is given. The source measured contained 104,493 function definitions containing more than one parameter with 16,643 of these functions having one or more unused parameter, there were a total of 235,512 parameters with 25,886 parameters being unused.
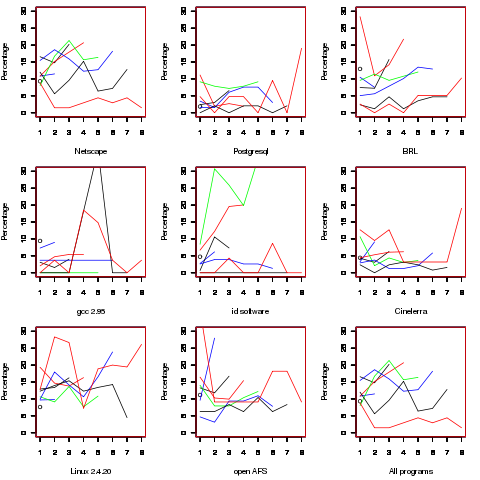
There is no obvious pattern to which parameters are likely to be unused, although a lot of the time the last parameter is more likely to be unused than the penultimate one.
Looking through the raw data I noticed that there seemed to be some clustering of names of unused parameters, in particular if the ‘th parameter was unused in two adjacent ‘unused parameter’ functions they often had the same name. The following plot is for all measured source and gives the percentage of same name occurrences; the matching process analyses function definitions in the order they occur within a source file and having found one unused parameter its name is compared against the corresponding parameter in the next function definition with the same number of parameters and having an unused parameter at the same position.
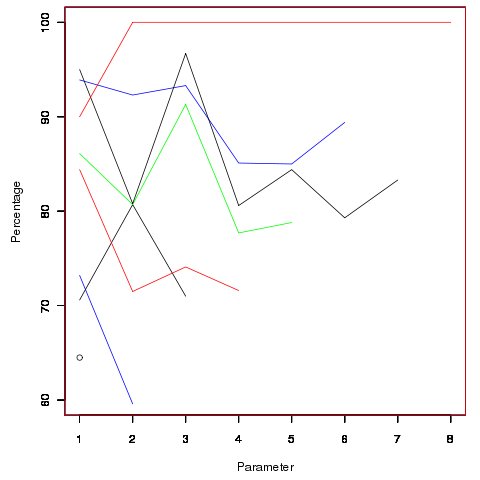
Before getting too excited about this pattern, we should ask if something similar exists for the used parameters. When I get around to redoing the general parameter measurements, I will look into this question. The numbers of occurrences for functions containing eight parameters is close to minimal.
The functions containing these same-name unused parameters appear to also have related function names. Is this a case of related function being grouped together, often sharing parameter names, and when one of them has an unused parameter the corresponding parameter in the others is also unused?
Is there a correlation between number of parameters and number of statements, are functions containing lots of statements less likely to have unused parameters? What effect does software evolution have (most of this kind of research measures executable code, not variable definitions)?
Recent Comments