Archive
Extreme value theory in software engineering
As its name suggests, extreme value theory deals with extreme deviations from the average, e.g., how often will rainfall be heavy enough to cause a river to overflow its banks.
The initial list of statistical topics I thought ought to be covered in my evidence-based software engineering book included extreme value theory. At the time, and even today, there were/are no books covering “Statistics for software engineering”, so I had no prior work to guide my selection of topics. I was keen to cover all the important topics, had heard of it in several (non-software) contexts and jumped to the conclusion that it must be applicable to software engineering.
Years pass: the draft accumulate a wide variety of analysis techniques applied to software engineering data, but, no use of extreme value theory.
Something else does not happen: I don’t find any ‘Using extreme value theory to analyse data’ books. Yes, there are some really heavy-duty maths books available, but nothing of a practical persuasion.
The book’s Extreme value section becomes a subsection, then a subsubsection, and ended up inside a comment (I cannot bring myself to delete it).
It appears that extreme value theory is more talked about than used. I can understand why. Extreme events are newsworthy; rivers that don’t overflow their banks are not news.
Just over a month ago a discussion cropped up on the UK’s C++ standards’ panel mailing list: was email traffic down because of COVID-19? The panel’s convenor, Roger Orr, posted some data on monthly volumes. Oh, data 🙂
Monthly data is a bit too granular for detailed analysis over relatively short periods. After some poking around Roger was able to send me the date&time of every post to the WG21‘s Core and Lib reflectors, since February 2016 (there have been various changes of hosts and configurations over the years, and date of posts since 2016 was straightforward to obtain).
During our email exchanges, Roger had mentioned that every now and again a huge discussion thread comes out of nowhere. Woah, sounds like WG21 could do with some extreme value theory. How often are huge discussion threads likely to occur, and how huge is a once in 10-years thread that they might have to deal with?
There are two techniques for analysing the distribution of extreme values present in a sample (both based around the generalized extreme value distribution):
- Generalized Extreme Value (GEV) uses block maxima, e.g., maximum number of daily emails sent in each month,
- Generalized Pareto (GP) uses peak over threshold: pick a threshold and extract day values for when more than this threshold number of emails was sent.
The plots below show the maximum number of monthly emails that are expected to occur (y-axis) within a given number of months (x-axis), for WG21’s Core and Lib email lists. The circles are actual occurrences, and dashed lines 95% confidence intervals; GEV was used for these fits (code+data):
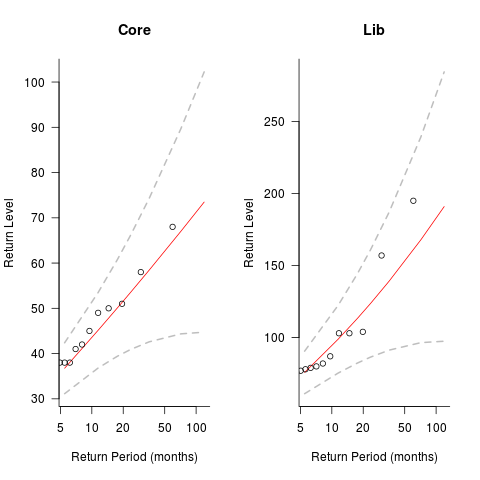
The 10-year return value for Core is around a daily maximum of 70 +-30, and closer to 200 +-100 for Lib.
The model used is very simplistic, and fails to take into account the growth in members joining these lists and traffic lost when a new mailing list is created for a new committee subgroup.
If any readers have suggests for uses of extreme value theory in software engineering, please let me know.
Postlude. This discussion has reordered events. My original interest in the mailing list data was the desire to find some evidence for the hypothesis that the volume of email increased as the date of the next WG21 meeting approached. For both Core and Lib, the volume actually decreases slightly as the date of the next meeting approaches; see code for details. Also, the volume of email at the weekend is around 60% lower than during weekdays.
C++ template usage
Generics are a programming construct that allow an algorithm to be coded without specifying the types of some variables, which are supplied later when a specific instance (for some type(s)) is instantiated. Generics sound like a great idea; who hasn’t had to write the same function twice, with the only difference being the types of the parameters.
All of today’s major programming languages support some form of generic construct, and developers have had the opportunity to use them for many years. So, how often generics are used in practice?
In C++, templates are the language feature supporting generics.
The paper: How C++ Templates Are Used for Generic Programming: An Empirical Study on 50 Open Source Systems contains lots of interesting data 🙂 The following analysis applies to the five largest projects analysed: Chromium, Haiku, Blender, LibreOffice and Monero.
As its name suggests, the Standard Template Library (STL) is a collection of templates implementing commonly used algorithms+other stuff (some algorithms were commonly used before the STL was created, and perhaps some are now commonly used because they are in the STL).
It is to be expected that most uses of templates will involve those defined in the STL, because these implement commonly used functionality, are documented and generally known about (code can only be reused when its existence is known about, and it has been written with reuse in mind).
The template instantiation measurements show a 17:1 ratio for STL vs. developer-defined templates (i.e., 149,591 vs. 8,887).
What are the usage characteristics of developer defined templates?
Around 25% of developer defined function templates are only instantiated once, while 15% of class templates are instantiated once.
Most templates are defined by a small number of developers. This is not surprising given that most of the code on a project is written by a small number of developers.
The plot below shows the percentage instantiations (of all developer defined function templates) of each developer defined function template, in rank order (code+data):
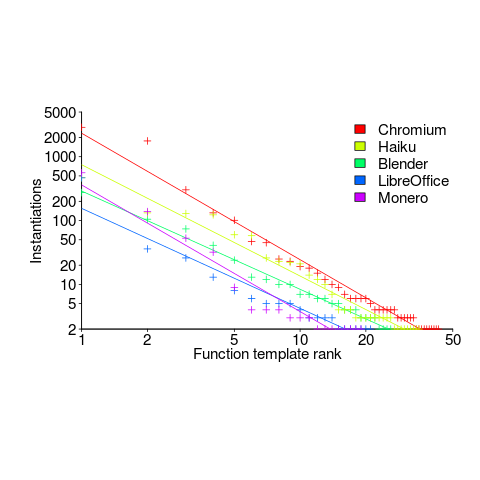
Lines are each a fitted power law, whose exponents vary between -1.5 and -2. Is it just me, or are these exponents surprising close?
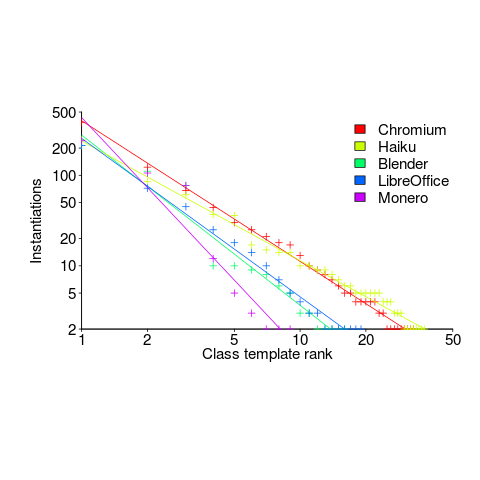
The following is for developer defined class templates. Lines are fitted power law, whose exponents vary between -1.3 and -2.6. Not so close here.
What processes are driving use of developer defined templates?
Every project has its own specific few templates that get used everywhere, by all developers. I imagine these are tailored to the project, and are widely advertised to developers who work on the project.
Perhaps some developers don’t define templates, because that’s not what they do. Is this because they work on stuff where templates don’t offer much benefit, or is it because these developers are stuck in their ways (if so, is it really worth trying to change them?)
How are C functions different from Java methods?
According to the right plot below, most of the code in a C program resides in functions containing between 5-25 lines, while most of the code in Java programs resides in methods containing one line (code+data; data kindly supplied by Davy Landman):
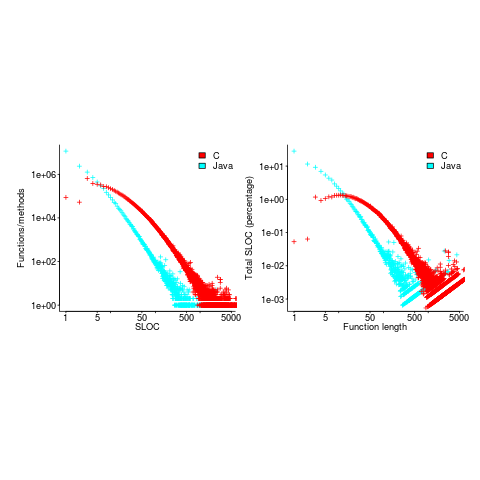
The left plot shows the number of functions/methods containing a given number of lines, the right plot shows the total number of lines (as a percentage of all lines measured) contained in functions/methods of a given length (6.3 million functions and 17.6 million methods).
Perhaps all those 1-line Java methods are really complicated. In C, most lines contain a few tokens, as seen below (code+data):
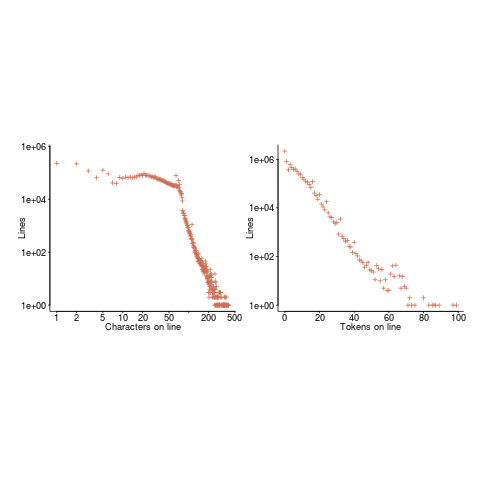
I don’t have any characters/tokens per line data for Java.
Is Java code mostly getters and setters?
I wonder what pattern C++ will follow, i.e., C-like, Java-like, or something else? If you have data for other languages, please send me a copy.
for-loop usage at different nesting levels
When reading code, starting at the first line of a function/method, the probability of the next statement read being a for-loop is around 1.5% (at least in C, I don’t have decent data on other languages). Let’s say you have been reading the code a line at a time, and you are now reading lines nested within various if/while/for statements, you are at nesting depth  . What is the probability of the statement on the next line being a
. What is the probability of the statement on the next line being a for-loop?
Does the probability of encountering a for-loop remain unchanged with nesting depth (i.e., developer habits are not affected by nesting depth), or does it decrease (aren’t developers supposed to using functions/methods rather than nesting; I have never heard anybody suggest that it increases)?
If you think the for-loop use probability is not affected by nesting depth, you are going to argue for the plot on the left (below, showing number of loops whose compound-statement contains appearing in C source at various nesting depths), with the regression model fitting really well after 3-levels of nesting. If you think the probability decreases with nesting depth, you are likely to argue for the plot on the right, with the model fitting really well down to around 10-levels of nesting (code+data).
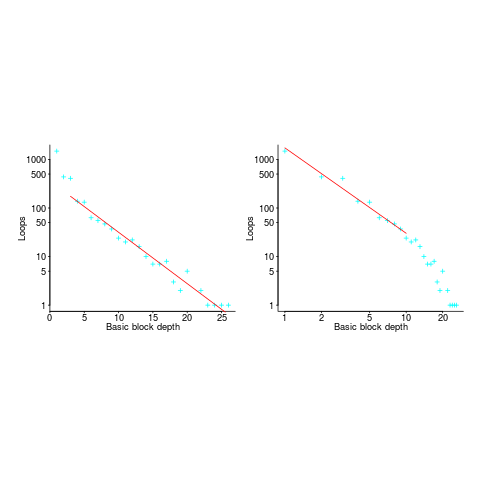
Both plots use the same data, but different scales are used for the x-axis.
If probability of use is independent of nesting depth, an exponential equation should fit the data (i.e., the left plot), decreasing probability is supported by a power-law (i.e, the right plot; plus other forms of equation, but let’s keep things simple).
The two cases are very wrong over different ranges of the data. What is your explanation for reality failing to follow your beliefs in for-loop occurrence probability?
Is the mismatch between belief and reality caused by the small size of the data set (a few million lines were measured, which was once considered to be a lot), or perhaps your beliefs are based on other languages which will behave as claimed (appropriate measurements on other languages most welcome).
The nesting depth dependent use probability plot shows a sudden change in the rate of decrease in for-loop probability; perhaps this is caused by the maximum number of characters that can appear on a typical editor line (within a window). The left plot (below) shows the number of lines (of C source) containing a given number of characters; the right plot counts tokens per line and the length effect is much less pronounced (perhaps developers use shorter identifiers in nested code). Note: different scales used for the x-axis (code+data).
I don’t have any believable ideas for why the exponential fit only works if the first few nesting depths are ignored. What could be so special about early nesting depths?
What about fitting the data with other equations?
A bi-exponential springs to mind, with one exponential driven by application requirements and the other by algorithm selection; but reality is not on-board with this idea.
Ideas, suggestions, and data for other languages, most welcome.
Comparing expression usage in mathematics and C source
Why does a particular expression appear in source code?
One reason is that the expression is the coded form of a formula from the application domain, e.g.,  .
.
Another reason is that the expression calculates an algorithm/housekeeping related address, or offset, to where a value of interest is held.
Most people (including me, many years ago) think that the majority of source code expressions relate to the application domain, in one-way or another.
Work on a compiler related optimizer, and you will soon learn the truth; most expressions are simple and calculate addresses/offsets. Optimizing compilers would not have much to do, if they only relied on expressions from the application domain (my numbers tool throws something up every now and again).
What are the characteristics of application domain expression?
I like to think of them as being complicated, but that’s because it used to be in my interest for them to be complicated (I used to work on optimizers, which have the potential to make big savings if things are complicated).
Measurements of expressions in scientific papers is needed, but who is going to be interested in measuring the characteristics of mathematical expressions appearing in papers? I’m interested, but not enough to do the work. Then, a few weeks ago I discovered: An Analysis of Mathematical Expressions Used in Practice, by Clare So; an analysis of 20,000 mathematical papers submitted to arXiv between 2000 and 2004.
The following discussion uses the measurements made for my C book, as the representative source code (I keep suggesting that detailed measurements of other languages is needed, but nobody has jumped in and made them, yet).
The table below shows percentage occurrence of operators in expressions. Minus is much more common than plus in mathematical expressions, the opposite of C source; the ‘popularity’ of the relational operators is also reversed.
Operator Mathematics C source = 0.39 3.08 - 0.35 0.19 + 0.24 0.38 <= 0.06 0.04 > 0.041 0.11 < 0.037 0.22 |
The most common single binary operator expression in mathematics is n-1 (the data counts expressions using different variable names as different expressions; yes, n is the most popular variable name, and adding up other uses does not change relative frequency by much). In C source var+int_constant is around twice as common as var-int_constant
The plot below shows the percentage of expressions containing a given number of operators (I’ve made a big assumption about exactly what Clare So is counting; code+data). The operator count starts at two because that is where the count starts for the mathematics data. In C source, around 99% of expressions have less than two operators, so the simple case completely dominates.
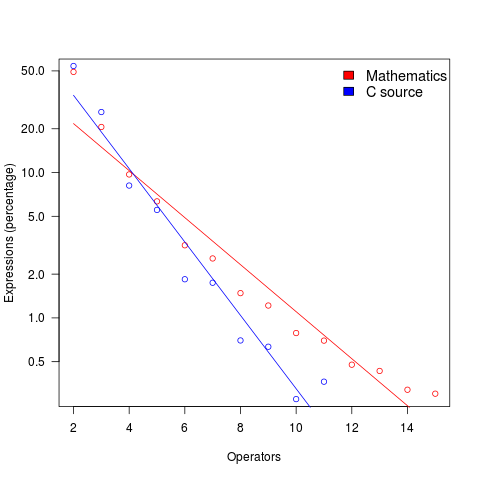
For expressions containing between two and five operators, frequency of occurrence is sort of about the same in mathematics and C, with C frequency decreasing more rapidly. The data disagrees with me again…
2019 in the programming language standards’ world
Last Tuesday I was at the British Standards Institute for a meeting of IST/5, the committee responsible for programming language standards in the UK.
There has been progress on a few issues discussed last year, and one interesting point came up.
It is starting to look as if there might be another iteration of the Cobol Standard. A handful of people, in various countries, have started to nibble around the edges of various new (in the Cobol sense) features. No, the INCITS Cobol committee (the people who used to do all the heavy lifting) has not been reformed; the work now appears to be driven by people who cannot let go of their involvement in Cobol standards.
ISO/IEC 23360-1:2006, the ISO version of the Linux Base Standard, has been updated and we were asked for a UK position on the document being published. Abstain seemed to be the only sensible option.
Our WG20 representative reported that the ongoing debate over pile of poo emoji has crossed the chasm (he did not exactly phrase it like that). Vendors want to have the freedom to specify code-points for use with their own emoji, e.g., pineapple emoji. The heady days, of a few short years ago, when an encoding for all the world’s character symbols seemed possible, have become a distant memory (the number of unhandled logographs on ancient pots and clay tablets was declining rapidly). Who could have predicted that the dream of a complete encoding of the symbols used by all the world’s languages would be dashed by pile of poo emoji?
The interesting news is from WG9. The document intended to become the Ada20 standard was due to enter the voting process in June, i.e., the committee considered it done. At the end of April the main Ada compiler vendor asked for the schedule to be slipped by a year or two, to enable them to get some implementation experience with the new features; oops. I have been predicting that in the future language ‘standards’ will be decided by the main compiler vendors, and the future is finally starting to arrive. What is the incentive for the GNAT compiler people to pay any attention to proposals written by a bunch of non-customers (ok, some of them might work for customers)? One answer is that Ada users tend to be large bureaucratic organizations (e.g., the DOD), who like to follow standards, and might fund GNAT to implement the new document (perhaps this delay by GNAT is all about funding, or lack thereof).
Right on cue, C++ users have started to notice that C++20’s added support for a system header with the name version, which conflicts with much existing practice of using a file called version to contain versioning information; a problem if the header search path used the compiler includes a project’s top-level directory (which is where the versioning file version often sits). So the WG21 committee decides on what it thinks is a good idea, implementors implement it, and users complain; implementors now have a good reason to not follow a requirement in the standard, to keep users happy. Will WG21 be apologetic, or get all high and mighty; we will have to wait and see.
Modeling visual studio C++ compile times
Last week I spotted an interesting article on the compile-time performance of C++ compilers running under Microsoft Windows. The author had obviously put a lot of work into gathering the data, and had taken care to have multiple runs to reduce the impact of random effects (128 runs to be exact); but, as if often the case, the analysis of the data was lackluster. I posted a comment asking for the data, and a link was posted the next day 🙂
The compilers benchmarked were: Visual Studio 2015, Visual Studio 2017 and clang 7.0.1; the compilers were configured to target: C++20, C++17, C++14, C++11, C++03, or C++98. The source code used was 100 system headers.
If we are interested in understanding the contribution of each component to overall compile-time, the obvious fist regression model to build is:

where:  are the different headers,
are the different headers,  the different compilers and
the different compilers and  the different target languages. There might be some interaction between variables, so something more complicated was tried first; the final fitted model was (code+data):
the different target languages. There might be some interaction between variables, so something more complicated was tried first; the final fitted model was (code+data):

where  is a constant (the
is a constant (the Intercept in R’s summary output). The following is a list of normalised numbers to plug into the equation (clang is the default compiler and C++03 the default language, and so do not appear in the list, the : symbol represents the multiplication; only a few of the 100 headers are listed, details are available):
Estimate Std. Error t value Pr(>|t|) (Intercept) headerany 1.000000000 0.051100398 headerarray headerassert.h 0.522336397 -0.654056185 ... headerwctype.h headerwindows.h -0.648095154 1.304270250 compilerVS15 compilerVS17 -0.185795534 -0.114590143 languagec++11 languagec++14 0.032930014 0.156363433 languagec++17 languagec++20 0.192301727 0.184274629 languagec++98 compilerVS15:languagec++11 0.001149643 -0.058735591 compilerVS17:languagec++11 compilerVS15:languagec++14 -0.038582437 -0.183708714 compilerVS17:languagec++14 compilerVS15:languagec++17 -0.164031495 NA compilerVS17:languagec++17 compilerVS15:languagec++20 -0.181591418 NA compilerVS17:languagec++20 compilerVS15:languagec++98 -0.193587045 0.062414667 compilerVS17:languagec++98 0.014558295 |
As an example, the (normalised) time to compile wchar.h using VS15 with languagec++11 is:
1-0.514807638-0.183862162+0.033951731-0.059720131
Each component adds/substracts to/from the normalised mean.
Building this model didn’t take long. While waiting for the kettle to boil, I suddenly realised that an additive model was probably inappropriate for this problem; oops. Surely the contribution of each component was multiplicative, i.e., components have a percentage impact to performance.
A quick change to the form of the fitted model:
 = k+header_x+compiler_y+language_z+compiler_y*language_z")
Taking the exponential of both side, the fitted equation becomes:

The numbers, after taking the exponent, are:
(Intercept) headerany 9.724619e+08 1.051756e+00 ... headerwctype.h headerwindows.h 3.138361e-01 2.288970e+00 compilerVS15 compilerVS17 7.286951e-01 7.772886e-01 languagec++11 languagec++14 1.011743e+00 1.049049e+00 languagec++17 languagec++20 1.067557e+00 1.056677e+00 languagec++98 compilerVS15:languagec++11 1.003249e+00 9.735327e-01 compilerVS17:languagec++11 compilerVS15:languagec++14 9.880285e-01 9.351416e-01 compilerVS17:languagec++14 compilerVS15:languagec++17 9.501834e-01 NA compilerVS17:languagec++17 compilerVS15:languagec++20 9.480678e-01 NA compilerVS17:languagec++20 compilerVS15:languagec++98 9.402461e-01 1.058305e+00 compilerVS17:languagec++98 1.001267e+00 |
Taking the same example as above: wchar.h using VS15 with c++11. The compile-time (in cpu clock cycles) is:
9.724619e+08*3.138361e-01*7.286951e-01*1.011743e+00*9.735327e-01
Now each component causes a percentage change in the (mean) base value.
Both of these model explain over 90% of the variance in the data, but this is hardly surprising given they include so much detail.
In reality compile-time is driven by some combination of additive and multiplicative factors. Building a combined additive and multiplicative model is going to be like wrestling an octopus, and is left as an exercise for the reader 🙂
Given a choice between these two models, I think the multiplicative model is probably closest to reality.
The first commercially available (claimed) verified compiler
Yesterday, I read a paper containing a new claim by some of those involved with CompCert (yes, they of soap powder advertising fame): “CompCert is the first commercially available optimizing compiler that is formally verified, using machine assisted mathematical proofs, to be exempt from miscompilation”.
First commercially available; really? Surely there are earlier claims of verified compilers being commercial availability. Note, I’m saying claims; bits of the CompCert compiler have involved mathematical proofs (i.e., code generation), so I’m considering earlier claims having at least the level of intellectual honesty used in some CompCert papers (a very low bar).
What does commercially available mean? The CompCert system is open source (but is not free software), so I guess it’s commercially available via free downloading licensing from AbsInt (the paper does not define the term).
Computational Logic, Inc is the name that springs to mind, when thinking of commercial and formal verification. They were active from 1983 to 1997, and published some very interesting technical reports about their work (sadly there are gaps in the archive). One project was A Mechanically Verified Code Generator (in 1989) and their Gypsy system (a Pascal-like language+IDE) provided an environment for doing proofs of programs (I cannot find any reports online). Piton was a high-level assembler and there was a mechanically verified implementation (in 1988).
There is the Danish work on the formal specification of the code generators for their Ada compiler (while there was a formal specification of the Ada semantics in VDM, code generators tend to be much simpler beasts, i.e., a lot less work is needed in formal verification). The paper I have is: “Retargeting and rehosting the DDC Ada compiler system: A case study – the Honeywell DPS 6” by Clemmensen, from 1986 (cannot find an online copy). This Ada compiler was used by various hardware manufacturers, so it was definitely commercially available for (lots of) money.
Are then there any earlier verified compilers with a commercial connection? There is A PRACTICAL FORMAL SEMANTIC DEFINITION AND VERIFICATION SYSTEM FOR TYPED LISP, from 1976, which has “… has proved a number of interesting, non-trivial theorems including the total correctness of an algorithm which sorts by successive merging, the total correctness of the McCarthy-Painter compiler for expressions, …” (which sounds like a code generator, or part of one, to me).
Francis Morris’s thesis, from 1972, proves the correctness of compilers for three languages (each language contained a single feature) and discusses how these features may be combined into a more “realistic” language. No mention of commercial availability, but I cannot see the demand being that great.
The definition of PL/1 was written in VDM, a formal language. PL/1 is a huge language and there were lots of subsets. Were there any claims of formal verification of a subset compiler for PL/1? I have had little contact with the PL/1 world, so am not in a good position to know. Anybody?
Over to you dear reader. Are there any earlier claims of verified compilers and commercial availability?
Adding a new scalar type to C
I think the time has arrived for a new scalar type in C, which for want of a better name I shall call the compendium type.
On today’s processors a compendium type behaves a lot like an integer type, except that nobody really wants to include it in the list of supported integer types, e.g., 128-bit scalars.
Why is a new scalar type needed? The Standard supports extended integer types, why not treat a scalar object that supports integer arithmetic as an integer type?
The C Standard says (section 6.2.5 Types):
“There are five standard signed integer types, designated as signed char, short int, int, long int, and long long int. (These and other types may be designated in several additional ways, as described in 6.7.2.) There may also be implementation-defined extended signed integer types.38) The standard and extended signed integer types are collectively called signed integer types.39)”
There is corresponding wording for unsigned integer types.
The standard header
“The typedef name intN_t designates a signed integer type with width N, no padding bits, and a two’s complement representation. Thus, int8_t denotes such a signed integer type with a width of exactly 8 bits.”
This all sounds very feasible, but there is a catch. The Standard defines a greatest-width integer type, section 7.20.1.5 Greatest-width integer types
“The following type designates a signed integer type capable of representing any value of any signed integer type:
intmax_t”
and various library functions have an argument type intmax_t (there is also an uintmax_t).
An ‘extra-large’ integer type is not something that can just sit there, in the list of available integer types, waiting to be used. Preprocessor arithmetic and a variety of library are based around the type intmax_t. An extra-large integer type would have a very visible impact on all developers, many of whom would want to ignore it.
GCC supports 128-bit integers, e.g., __int128. But some magic pixie dust is involved, this type has no connection with intmax_t.
What do developers do with these 128- and 256-bit scalar objects? Evaluating graphics algorithms, hashes and cryptographic calculations are obvious candidates; yes, perhaps even calculations involving integers that require this many bits. I have not seen any analysis of the uses of this kind of wide-integer-like type.
Extra-wide scalar types have a variety of uses and the term compendium type, captures this. Hardware support for such extra-width types is growing, with vendors looking to fill major niches.
Contorting existing wording, in the Standard, so accommodate these extra-wide types within the existing integer type machinery is a short term solution. Work on the upcoming revision of the C Standard should either do nothing and allow vendors to take the approach currently used by GCC, or create a new scalar type (perhaps using a TR).
Evolutionary pressures on C++, Java and Python
The future evolution of C++, Java and Python is being driven by very different interested parties, and it’s going to be interesting watching events unfold over the next 5-10 years.
I have previously written about how the C++ Standard’s committee is past its sell-by date, has taken off its ball and chain and is now in the hands of bored consultants.
Bjarne Stroustrup was once effectively treated as C++’s Benevolent Dictator For Life (during the production of the first C++ Standard some people were labeled as Bjarne groupees); things have moved on since then, but the ‘old-guard’ are trying to make a comeback. Suggesting that people ought to base their thinking on a book published almost 25-years ago (Stroustrup’s “The Design and Evolution of C++”; a very interesting book that is well worth reading) creates a rather backward looking image. Bored consultants are looking to work on exciting new ideas. The old-guard need to appear modern to attract followers (even if the ideas are old ideas with a fresh coat of paint).
The threat to C++ is from bored consultants, each adding their own pet idea to the language standard; a situation that Stroustrup thinks is starting to happen.
Java, the language, is owned by Oracle, the company (let’s not get too involved in exactly what they own, have copyright on, etc). Oracle are not shy about asking people for licensing fees. Java is now on a 6-month release cycle (at least the Oracle version, there are Open Source implementations) and the free support only applies to the current release; paying a license fee buys support for versions older than 6-months. In the short term, the cheapest solution is for companies to pay for support.
Oracle are always happy to send in the lawyers and if too many customers switch to non-Oracle implementations, I’m sure something can be found to introduce enough uncertainty to discourage work/distribution involving Open Source Java implementations.
Will Java survive Oracle’s licensing? It is not in their interest for Java to die; Oracle will adjust their terms to keep the money flowing in, but over the longer term I think willing Java developers are going to be hard to find.
Guido van Rossum recently removed himself from the post of Python’s Benevolent Dictator For Life. One of the jobs of a benevolent dictator is maintaining some degree of language coherence, which involves preventing people’s pet ideas from being added to the language. Does this mean that Python is slowly going to be become more and more bloated? Perhaps, but I think a more likely problem is a language fork, multiple implementations of slightly different (at first) languages all claiming to be Python.
These days, the strength of Python is its large collection of very useful, commercial grade, packages, and future language details may turn out to be irrelevant. There is a lot to learn from the Python 2/3 transition, but true believers like to think that things will turn out differently for them.
Recent Comments