Archive
Christmas books for 2021
This year, my list of Christmas books is very late because there is only one entry (first published in 1950), and I was not sure whether a 2021 Christmas book post was worthwhile.
The book is “Planning in Practice: Essays in Aircraft planning in war-time” by Ely Devons. A very readable, practical discussion, with data, on the issues involved in large scale planning; the discussion is timeless. Check out second-hand book sites for low costs editions.
Why isn’t my list longer?
Part of the reason is me. I have not been motivated to find new topics to explore, via books rather than blog posts. Things are starting to change, and perhaps the list will be longer in 2022.
Another reason is the changing nature of book publishing. There is rarely much money to be made from the sale of non-fiction books, and the desire to write down their thoughts and ideas seems to be the force that drives people to write a book. Sites like substack appear to be doing a good job of diverting those with a desire to write something (perhaps some authors will feel the need to create a book length tomb).
Why does an author need a publisher? The nitty-gritty technical details of putting together a book to self-publish are slowly being simplified by automation, e.g., document formatting and proofreading. It’s a win-win situation to make newly written books freely available, at least if they are any good. The author reaches the largest readership (which helps maximize the impact of their ideas), and readers get a free electronic book. Authors of not very good books want to limit the number of people who find this out for themselves, and so charge money for the electronic copy.
Another reason for the small number of good new, non-introductory, books, is having something new to say. Scientific revolutions, or even minor resets, are rare (i.e., measured in multi-decades). Once several good books are available, and nothing much new has happened, why write a new book on the subject?
The market for introductory books is much larger than that for books covering advanced material. While publishers obviously want to target the largest market, these are not the kind of books I tend to read.
Electronic Evidence and Electronic Signatures: book
Electronic Evidence and Electronic Signatures by Stephen Mason and Daniel Seng is not the sort of book that I would normally glance at twice (based on its title). However, at this start of the year I had an interesting email conversation with the first author, a commentator who worked for the defence team on the Horizon IT project case, and he emailed with the news that the fifth edition was now available (there’s a free pdf version, so why not have a look; sorry Stephen).
Regular readers of this blog will be interested in chapter 4 (“Software code as the witness”) and chapter 5 (“The presumption that computers are ‘reliable'”).
Legal arguments are based on precedent, i.e., decisions made by judges in earlier cases. The one thing that stands from these two chapters is how few cases have involved source code and/or reliability, and how simplistic the software issues have been (compared to issues that could have been involved). Perhaps the cases involving complicated software issues get simplified by the lawyers, or they look like they will be so difficult/expensive to litigate that the case don’t make it to court.
Chapter 4 provided various definitions of source code, all based around the concept of imperative programming, i.e., the code tells the computer what to do. No mention of declarative programming, where the code specifies the information required and the computer has to figure out how to obtain it (SQL being a widely used language based on this approach). The current Wikipedia article on source code is based on imperative programming, but the programming language article is not so narrowly focused (thanks to some work by several editors many years ago 😉
There is an interesting discussion around the idea of source code as hearsay, with a discussion of cases (see 4.34) where the person who wrote the code had to give evidence so that the program output could be admitted as evidence. I don’t know how often the person who wrote the code has to give evidence, but these days code often has multiple authors, and their identity is not always known (e.g., author details have been lost, or the submission effectively came via an anonymous email).
Chapter 5 considers the common law presumption in the law of England and Wales that ‘In the absence of evidence to the contrary, the courts will presume that mechanical instruments were in order. Yikes! The fact that this is presumption is nonsense, at least for computers, was discussed in an earlier post.
There is plenty of case law discussion around the accuracy of devices used to breath-test motorists for their alcohol level, and defendants being refused access to the devices and associated software. Now, I’m sure that the software contained in these devices contains coding mistakes, but was a particular positive the result of a coding mistake? Without replicating the exact conditions occurring during the original test, it could be very difficult to say. The prosecution and Judges make the common mistake of assuming that because the science behind the test had been validated, the device must produce correct results; ignoring the fact that the implementation of the science in software may contain implementation mistakes. I have lost count of the number of times that scientist/programmers have told me that because the science behind their code is correct, the program output must be correct. My retort that there are typos in the scientific papers they write, therefore there may be typos in their code, usually fails to change their mind; they are so fixated on the correctness of the science that possible mistakes elsewhere are brushed aside.
The naivety of some judges is astonishing. In one case (see 5.44) a professor who was an expert in mathematics, physics and computers, who had read the user manual for an application, but had not seen its source code, was considered qualified to give evidence about the operation of the software!
Much of chapter 5 is essentially an overview of software reliability, written by a barrister for legal professionals, i.e., it is not always a discussion of case law. A barristers’ explanation of how software works can be entertainingly inaccurate, but the material here is correct in a broad brush sense (and I did not spot any entertainingly inaccuracies).
Other than breath-testing, the defence asking for source code is rather like a dog chasing a car. The software for breath-testing devices is likely to be small enough that one person might do a decent job of figuring out how it works; many software systems are not only much, much larger, but are dependent on an ecosystem of hardware/software to run. Figuring out how they work will take multiple (expensive expert) people a lot of time.
Legal precedents are set when both sides spend the money needed to see a court case through to the end. It’s understandable why the case law discussed in this book is so sparse and deals with relatively simple software issues. The costs of fighting a case involving the complexity of modern software is going to be astronomical.
Christmas books for 2020
A very late post on the interesting books I read this year (only one of which was actually published in 2020). As always the list is short because I did not read many books and/or there is lots of nonsense out there, but this year I have the new excuses of not being able to spend much time on trains and having my own book to finally complete.
I have already reviewed The Weirdest People in the World: How the West Became Psychologically Peculiar and Particularly Prosperous, and it is the must-read of 2020 (after my book, of course :-).
The True Believer by Eric Hoffer. This small, short book provides lots of interesting insights into the motivational factors involved in joining/following/leaving mass movements. Possible connections to software engineering might appear somewhat tenuous, but bits and pieces keep bouncing around my head. There are clearer connections to movements going mainstream this year.
The following two books came from asking what-if questions about the future of software engineering. The books I read suggesting utopian futures did not ring true.
“Money and Motivation: Analysis of Incentives in Industry” by William Whyte provides lots of first-hand experience of worker motivation on the shop floor, along with worker response to management incentives (from the pre-automation 1940s and 1950s). Developer productivity is a common theme in discussions I have around evidence-based software engineering, and this book illustrates the tangled mess that occurs when management and worker aims are not aligned. It is easy to imagine the factory-floor events described playing out in web design companies, with some web-page metric used by management as a proxy for developer productivity.
Labor and Monopoly Capital: The Degradation of Work in the Twentieth Century by Harry Braverman, to quote from Wikipedia, is an “… examination the nature of ‘skill’ and the finding that there was a decline in the use of skilled labor as a result of managerial strategies of workplace control.” It may also have discussed management assault of blue-collar labor under capitalism, but I skipped the obviously political stuff. Management do want to deskill software development, if only because it makes it easier to find staff, with the added benefit that the larger pool of less skilled staff increases management control, e.g., low skilled developers knowing they can be easily replaced.
Exercises in Programming Style: the python way
Exercises in Programming Style by Cristina Lopes is an interesting little book.
The books I have previously read on programming style pick a language, and then write various programs in that language using different styles, idioms, or just following quirky rules, e.g., no explicit loops, must use sets, etc. “Algorithms in Snobol 4” by James F. Gimpel is a fascinating read, but something of an acquired taste.
EPS does pick a language, Python, but the bulk of the book is really a series of example programs illustrating a language feature/concept that is central to a particular kind of language, e.g., continuation-passing style, publish-subscribe architecture, and reflection. All the programs implement the same problem: counting the number of occurrences of each word in a text file (Jane Austin’s Pride and Prejudice is used).
The 33 chapters are each about six or seven pages long, and contain a page or two or code. Everything is very succinct, and does a good job of illustrating one main idea.
While the first example does not ring true, things quickly pick up and there are lots of interesting insights to be had. The first example is based on limited storage (1,024 bytes), and just does not make efficient use of the available bits (e.g., upper case letters can be represented using 5-bits, leaving three unused bits or 37% of available storage; a developer limited to 1K would not waste such a large amount of storage).
Solving the same problem in each example removes the overhead of having to learn what is essentially housekeeping material. It also makes it easy to compare the solutions created using different ideas. The downside is that there is not always a good fit between the idea being illustrated and the problem being solved.
There is one major omission. Unstructured programming; back in the day it was just called programming, but then structured programming came along, and want went before was called unstructured. Structured programming allowed a conditional statement to apply to multiple statements, an obviously simple idea once somebody tells you.
When an if-statement can only be followed by a single statement, that statement has to be a goto; an if/else is implemented as (using Fortran, I wrote lots of code like this during my first few years of programming):
IF (I .EQ. J) GOTO 100 Z=1 GOTO 200 100 Z=2 200 |
Based on the EPS code in chapter 3, Monolithic, an unstructured Python example might look like (if Python supported goto):
for line in open(sys.argv[1]): start_char = None i = 0 for c in line: if start_char != None: goto L0100 if not c.isalnum(): goto L0300 # We found the start of a word start_char = i goto L0300 L0100: if c.isalnum(): goto L0300 # We found the end of a word. Process it found = False word = line[start_char:i].lower() # Ignore stop words if word in stop_words: goto L0280 pair_index = 0 # Let's see if it already exists for pair in word_freqs: if word != pair[0]: goto L0210 pair[1] += 1 found = True goto L0220 L0210: pair_index += 1 L0220: if found: goto L0230 word_freqs.append([word, 1]) goto L0300 L0230: if len(word_freqs) <= 1: goto L0300: # We may need to reorder for n in reversed(range(pair_index)): if word_freqs[pair_index][1] <= word_freqs[n][1]: goto L0240 # swap word_freqs[n], word_freqs[pair_index] = word_freqs[pair_index], word_freqs[n] pair_index = n L0240: goto L0300 L0280: # Let's reset start_char = None L0300: i += 1 |
If you do feel a yearning for the good ol days, a goto package is available, enabling developers to write code such as:
from goto import with_goto @with_goto def range(start, stop): i = start result = [] label .begin if i == stop: goto .end result.append(i) i += 1 goto .begin label .end return result |
Christmas books for 2019
The following are the really, and somewhat, interesting books I read this year. I am including the somewhat interesting books to bulk up the numbers; there are probably more books out there that I would find interesting. I just did not read many books this year, what with Amazon recommends being so user unfriendly, and having my nose to the grindstone finishing a book.
First the really interesting.
I have already written about Good Enough: The Tolerance for Mediocrity in Nature and Society by Daniel Milo.
I have also written about The European Guilds: An economic analysis by Sheilagh Ogilvie. Around half-way through I grew weary, and worried readers of my own book might feel the same. Ogilvie nails false beliefs to the floor and machine-guns them. An admirable trait in someone seeking to dispel the false beliefs in current circulation. Some variety in the nailing and machine-gunning would have improved readability.
Moving on to first half really interesting, second half only somewhat.
“In search of stupidity: Over 20 years of high-tech marketing disasters” by Merrill R. Chapman, second edition. This edition is from 2006, and a third edition is promised, like now. The first half is full of great stories about the successes and failures of computer companies in the 1980s and 1990s, by somebody who was intimately involved with them in a sales and marketing capacity. The author does not appear to be so intimately involved, starting around 2000, and the material flags. Worth buying for the first half.
Now the somewhat interesting.
“Can medicine be cured? The corruption of a profession” by Seamus O’Mahony. All those nonsense theories and practices you see going on in software engineering, it’s also happening in medicine. Medicine had a golden age, when progress was made on finding cures for the major diseases, and now it’s mostly smoke and mirrors as people try to maintain the illusion of progress.
“Who we are and how we got here” by David Reich (a genetics professor who is a big name in the field), is the story of the various migrations and interbreeding of ‘human-like’ and human peoples over the last 50,000 years (with some references going as far back as 300,000 years). The author tries to tell two stories, the story of human migrations and the story of the discoveries made by his and other people’s labs. The mixture of stories did not work for me; the story of human migrations/interbreeding was very interesting, but I was not at all interested in when and who discovered what. The last few chapters went off at a tangent, trying to have a politically correct discussion about identity and race issues. The politically correct class are going to hate this book’s findings.
“The Digital Party: Political organization and online democracy” by Paolo Gerbaudo. The internet has enabled some populist political parties to attract hundreds of thousands of members. Are these parties living up to their promises to be truly democratic and representative of members wishes? No, and Gerbaudo does a good job of explaining why (people can easily join up online, and then find more interesting things to do than read about political issues; only a few hard code members get out from behind the screen and become activists).
Suggestions for books that you think I might find interesting welcome.
Three books discuss three small data sets
During the early years of a new field, experimental data relating to important topics can be very thin on the ground. Ever since the first computer was built, there has been a lot of data on the characteristics of the hardware. Data on the characteristics of software, and the people who write it, has been (and often continues to be) very thin on the ground.
Books are sometimes written by the researchers who produce the first data associated with an important topic, even if the data set is tiny; being first often generates enough interest for a book length treatment to be considered worthwhile.
As a field progresses lots more data becomes available, and the discussion in subsequent books can be based on findings from more experiments and lots more data
Software engineering is a field where a few ‘first’ data books have been published, followed by silence, or rather lots of arm waving and little new data. The fall of Rome has been followed by a 40-year dark-age, from which we are slowly emerging.
Three of these ‘first’ data books are:
- “Man-Computer Problem Solving” by Harold Sackman, published in 1970, relating to experimental data from 1966. The experiments investigated the impact of two different approaches to developing software, on programmer performance (i.e., batch processing vs. on-line development; code+data). The first paper on this work appeared in an obscure journal in 1967, and was followed in the same issue by a critique pointing out the wide margin of uncertainty in the measurements (the critique agreed that running such experiments was a laudable goal).
Failing to deal with experimental uncertainty is nothing compared to what happened next. A 1968 paper in a widely read journal, the Communications of the ACM, contained the following table (extracted from a higher quality scan of a 1966 report by the same authors, and available online).
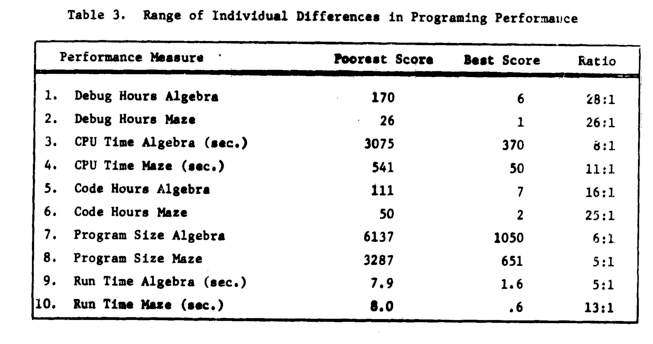
The tale of 1:28 ratio of programmer performance, found in an experiment by Grant/Sackman, took off (the technical detail that a lot of the difference was down to the techniques subjects’ used, and not the people themselves, got lost). The Grant/Sackman ‘finding’ used to be frequently quoted in some circles (or at least it did when I moved in them, I don’t know often it is cited today). In 1999, Lutz Prechelt wrote an expose on the sorry tale.
Sackman’s book is very readable, and contains lots of details and data not present in the papers, including survey data and a discussion of the intrinsic uncertainties associated with the experiment; it also contains the table above.
- “Software Engineering Economics” by Barry W. Boehm, published in 1981. I wrote about the poor analysis of the data contained in this book a few years ago.
The rest of this book contains plenty of interesting material, and even sounds modern (because books moving the topic forward have not been written).
- “Program Evolution: Process of Software Change” edited by M. M. Lehman and L. A. Belady, published in 1985, relating to experimental data from 1977 and before. Lehman and Belady managed to obtain data relating to 19 releases of an IBM software product (yes, 19, not nineteen-thousand); the data was primarily the date and number of modules contained in each release, plus less specific information about number of statements. This data was sliced and diced every which way, and the book contains many papers with the same data appearing in the same plot with different captions (had the book not been a collection of papers it would have been considerably shorter).
With a lot less data than Isaac Newton had available to formulate his three laws, Lehman and Belady came up with five, six, seven… “laws of software evolution” (which themselves evolved with the publication of successive papers).
The availability of Open source repositories means there is now a lot more software system evolution data available. Lehman’s laws have not stood the test of more data, although people still cite them every now and again.
Natural elimination, or the survival of the good enough
Thanks to Darwin, the world is full of people who think that evolution, in nature, works by: natural selection, or the survival of the fittest. I thought this until I read “Good Enough: The Tolerance for Mediocrity in Nature and Society” by Daniel Milo.
Milo makes a very convincing case that nature actually works by: natural elimination, or the survival of the good enough.
Why might Darwin have gone with natural selection in his book, On the Origin of Species? Milo makes the point that the only real evidence that Darwin had to work with was artificial selection, that is the breeding of farm animals and domestic pets to select for traits that humans found desirable. Darwin’s visit to the Galápagos islands triggered a way of thinking, it did not provide him with the evidence he needed; Darwin’s Finches have become a commonly cited example of natural selection at work, but while Darwin made the observations it was not until 80 years later that somebody else spotted their relevance.
The Origin of Species, or to use its full title: “On the Origin of Species by means of natural selection, or the preservation of favored races in the struggle for life.” is full of examples and terminology relating to artificial selection.
Natural selection, or natural elimination, isn’t the result the same?
Natural selection implies an optimization process, e.g., breeders selecting for a strain of cows that produce the most milk.
Natural elimination is a good enough process, i.e., a creature needs a collection of traits that are good enough for them to create the next generation.
A long-standing problem with natural selection is that it fails to explain the diversity present in a natural population of some breed of animal (there is very little diversity in each breed of farm animal, they have been optimized for consistency). Diversity is not a problem for natural elimination, which does not reduce differences in its search for fitness.
The diversity produced as a consequence of natural elimination creates a population containing many neutral traits (i.e., characteristics that have no positive or negative impact on continuing survival). When a significant change in the environment occurs, one or more of the neutral traits may suddenly have positive or negative survival consequences; the creatures with the positive traits have opportunity time to adapt to the changed environment. A population whose members possess a diverse range of neutral traits has a higher chance of long-term survival than a population where diversity has been squeezed in the quest for the fittest.
I think that natural elimination also applies within software ecosystems. Commercial products survive if enough customers buy them, software developers need good enough know-how to get the job done.
I’m sure customers would prefer software ecosystems to operate on the principle of survival of the fittest (it reduces their costs). Over the long term is society best served by diverse software ecosystems or softwaremonocultures? Diversity is a way of encouraging competition, but over time there is diminishing returns on the improvements.
Christmas books for 2018
The following are the really interesting books I read this year (only one of which was actually published in 2018, everything has to work its way through several piles). The list is short because I did not read many books and/or there is lots of nonsense out there.
The English and their history by Robert Tombs. A hefty paperback, at nearly 1,000 pages, it has been the book I read on train journeys, for most of this year. Full of insights, along with dull sections, a narrative that explains lots of goings-on in a straight-forward manner. I still have a few hundred pages left to go.
The mind is flat by Nick Chater. We experience the world through a few low bandwidth serial links and the brain stitches things together to make it appear that our cognitive hardware/software is a lot more sophisticated. Chater’s background is in cognitive psychology (these days he’s an academic more connected with the business world) and describes the experimental evidence to back up his “mind is flat” model. I found that some of the analogues dragged on too long.
In the readable social learning and evolution category there is: Darwin’s unfinished symphony by Leland and The secret of our success by Henrich. Flipping through them now, I cannot decide which is best. Read the reviews and pick one.
Group problem solving by Laughin. Eye opening. A slim volume, packed with data and analysis.
I have already written about Experimental Psychology by Woodworth.
The Digital Flood: The Diffusion of Information Technology Across the U.S., Europe, and Asia by Cortada. Something of a specialist topic, but if you are into the diffusion of technology, this is surely the definitive book on the diffusion of software systems (covers mostly hardware).
Practical ecosystem books for software engineers
So you have read my (draft) book on evidence-based software engineering and want to learn more about ecosystems. What books do I suggest?
Biologists have been studying ecosystems for a long time, and more recently social scientists have been investigating cultural ecosystems. Many of the books written in these fields are oriented towards solving differential equations and are rather subject specific.
The study of software ecosystems has been something of a niche topic for a long time. Problems for researchers have included gaining access to ecosystems and the seeming proliferation of distinct ecosystems. The state of ecosystem research in software engineering is rudimentary; historians are starting to piece together what has happened.
Most software ecosystems are not even close to being in what might be considered a steady state. Eventually most software will be really old, and this will be considered normal (“Shock Of The Old: Technology and Global History since 1900” by Edgerton; newness is a marketing ploy to get people to buy stuff). In the meantime, I have concentrated on the study of ecosystems in a state of change.
Understanding ecosystems is about understanding how the interaction of participant’s motivation, evolves the environment in which they operate.
“Modern Principles of Economics” by Cowen and Tabarrok, is a very readable introduction to economics. Economics might be thought of as a study of the consequences of optimizing the motivation of maximizing return on investment. “Principles of Corporate Finance” by Brealey and Myers, focuses on the topic in its title.
“The Control Revolution: Technological and Economic Origins of the Information Society” by Beniger: the ecosystems in which software ecosystems coexist and their motivations.
“Evolutionary dynamics: exploring the equations of life” by Nowak, is a readable mathematical introduction to the subject given in the title.
“Mathematical Models of Social Evolution: A Guide for the Perplexed” by McElreath and Boyd, is another readable mathematical introduction, but focusing on social evolution.
“Social Learning: An Introduction to Mechanisms, Methods, and Models” by Hoppitt and Laland: developers learn from each other and from their own experience. What are the trade-offs for the viability of an ecosystem that preferentially contains people with specific ways of learning?
“Robustness and evolvability in living systems” by Wagner, survival analysis of systems built from components (DNA in this case). Rather specialised.
Books with a connection to technology ecosystems.
“Increasing returns and path dependence in the economy” by Arthur, is now a classic, containing all the basic ideas.
“The red queen among organizations” by Barnett, includes a chapter on computer manufacturers (has promised me data, but busy right now).
“Information Foraging Theory: Adaptive Interaction with Information” by Pirolli, is an application of ecosystem know-how, i.e., how best to find information within a given environment. Rather specialised.
“How Buildings Learn: What Happens After They’re Built” by Brand, yes building are changed just like software and the changes are just as messy and expensive.
Several good books have probably been omitted, because I failed to spot them sitting on the shelf. Suggestions for books covering topics I have missed welcome, or your own preferences.
Practical psychology books for software engineers
So you have read my (draft) book on evidence-based software engineering and want to learn more about human psychology. What books do I suggest?
I wrote a book about C that attempted to use results from cognitive psychology to understand developer characteristics. This work dates from around 2000, and some of my book choices may have been different, had I studied the subject 10 years later. Another consequence is that this list is very weak on social psychology.
I own all the following books, but it may have been a few years since I last took them off the shelf.
There are two very good books providing a broad introduction: “Cognitive psychology and its implications” by Anderson, and “Cognitive psychology: A student’s handbook” by Eysenck and Keane. They have both been through many editions, and buying a copy that is a few editions earlier than current, saves money for little loss of content.
“Engineering psychology and human performance” by Wickens and Hollands, is a general introduction oriented towards stuff that engineering requires people to do.
Brain functioning: “Reading in the brain” by Dehaene (a bit harder going than “The number sense”). For those who want to get down among the neurons “Biological psychology” by Kalat.
Consciouness: This issue always comes up, so let’s kill it here and now: “The illusion of conscious will” by Wegner, and “The mind is flat” by Chater.
Decision making: What is the difference between decision making and reasoning? In psychology those with a practical orientation study decision making, while those into mathematical logic study reasoning. “Rational choice in an uncertain world” by Hastie and Dawes, is a general introduction; “The adaptive decision maker” by Payne, Bettman and Johnson, is a readable discussion of decision making models. “Judgment under Uncertainty: Heuristics and Biases” by Kahneman, Slovic and Tversky, is a famous collection of papers that kick started the field at the start of the 1980s.
Evolutionary psychology: “Human evolutionary psychology” by Barrett, Dunbar and Lycett. How did we get to be the way we are? Watch out for the hand waving (bones can be dug up for study, but not the software of our mind), but it weaves a coherent’ish story. If you want to go deeper, “The Adapted Mind: Evolutionary Psychology and the Generation of Culture” by Barkow, Tooby and Cosmides, is a collection of papers that took the world by storm at the start of the 1990s.
Language: “The psychology of language” by Harley, is the book to read on psycholinguistics; it is engrossing (although I have not read the latest edition).
Memory: I have almost a dozen books discussing memory. What these say is that there are a collection of memory systems having various characteristics; which is what the chapters in the general coverage books say.
Modeling: So you want to model the human brain. ACT-R is the market leader in general cognitive modeling. “Bayesian cognitive modeling” by Lee and Wagenmakers, is a good introduction for those who prefer a more abstract approach (“Computational modeling of cognition” by Farrell and Lewandowsky, is a big disappointment {they have written some great papers} and best avoided).
Reasoning: The study of reasoning is something of a backwater in psychology. Early experiments showed that people did not reason according to the rules of mathematical logic, and this was treated as a serious fault (whose fault it was, shifted around). Eventually most researchers realised that the purpose of reasoning was to aid survival and reproduction, not following the recently (100 years or so) invented rules of mathematical logic (a few die-hards continue to cling to the belief that human reasoning has a strong connection to mathematical logic, e.g., Evans and Johnson-Laird; I have nearly all their books, but have not inflicted them on the local charity shop yet). Gigerenzer has written several good books: “Adaptive thinking: Rationality in the real world” is a readable introduction, also “Simple heuristics that make us smart”.
Social psychology: “Social learning” by Hoppitt and Laland, analyzes the advantages and disadvantages of social learning; “The Secret of Our Success: How Culture Is Driving Human Evolution, Domesticating Our Species, and Making Us Smarter” by Henrich, is a more populist book (by a leader in the field).
Vision: “Visual intelligence” by Hoffman is a readable introduction to how we go about interpreting the photons entering our eyes, while “Graph design for the eye and mind” by Kosslyn is a rule based guide to visual presentation. “Vision science: Photons to phenomenology” by Palmer, for those who are really keen.
Several good books have probably been omitted, because I failed to spot them sitting on the shelf. Suggestions for books covering topics I have missed welcome, or your own preferences.
Recent Comments