Archive
Extracting information from duplicate fault reports
Duplicate fault reports (that is, reports whose cause is the same underlying coding mistake) are an underused source of information. I sometimes email the authors of a paper analysing fault data asking for information about duplicates. Duplicate information is rarely available, because the authors don’t bother to record it.
If a program’s coding mistakes are a closed population, i.e., no new ones are added or existing ones fixed, duplicate counts might be used to estimate the number of remaining mistakes.
However, coding mistakes in production software systems are invariably open populations, i.e., reported faults are fixed, and new functionality (containing new coding mistakes) is added.
A dataset made available by Sadat, Bener, and Miranskyy contains 18 years worth of information on duplicate fault reports in Apache, Eclipse and KDE. The following analysis uses the KDE data.
Fault reports are created by users, and changes in the rate of reports whose root cause is the same coding mistake provides information on changes in the number of active users, or changes in the functionality executed by the active users. The plot below shows, for 10 unique faults (different colors), the number of days between the first report and all subsequent reports of the same fault (plus character); note the log scale y-axis (code+data):

Changes in the rate at which duplicates are reported are visible as changes in the slope of each line formed by plus signs of the respective color. Possible reasons for the change include: the coding mistake appears in a new release which users do not widely install for some time, 2) a fault become sufficiently well known, or workaround provided, that the rate of reporting for that fault declines. Of course, only some fault experiences are ever reported.
Almost all books/papers on software reliability that model the occurrence of fault experiences treat them as-if they were a Non-Homogeneous Poisson Process (NHPP); in most cases, authors are simply repeating what they have read elsewhere.
Some important assumptions made by NHPP models do not apply to software faults. For instance, NHPP models assume that the probability of encountering a fault experience is the same for different coding mistakes, i.e., they are all equally likely. What does the evidence show about this assumption? If all coding mistakes had the same probability of producing a fault experience, the mean time between duplicate fault reports would be the same for all fault reports. The plot below shows the interval, in days, between consecutive duplicate fault reports, for the 392 faults whose number of duplicates was between 20 and 100, sorted by interval (out of a total of 30,377; code+data):
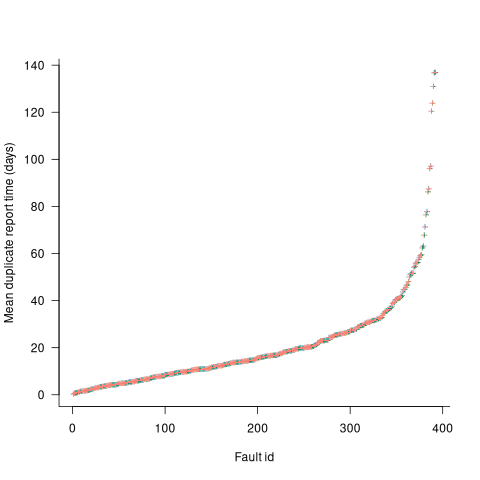
The variation in mean time between duplicate fault reports, for different faults, is evidence that different coding mistakes have different probabilities of producing a fault experience. This behavior is consistent with the observation that mistakes in deeply nested if-statements are less likely to be executed than mistakes contained in less-deeply nested code. However, this observation invalidating assumptions made by NHPP models has not prevented them dominating the research literature.
SEC wants prospectus source code to be published
The US Securities and Exchange Commission are proposing new rules involving the prospectuses for public offerings of asset-backed securities including publishing the source code used to calculate the contractual cash flow provisions.
Requiring that the source code used to perform the financial modeling for a prospectus be made available is an excellent idea. A prospectus document contains a huge number of technical details and more importantly for anybody trying to understand the thinking behind it, a lots of assumption. Writing a program requires that all necessary details be enumerated and appropriately connected together and more importantly creating code that can be meaningfully executed usually means making explicit any assumptions that were previously implicit.
There are parallels here with having access to the source code and data used to make climate predictions.
The authors of the proposals are naive to think that simply requiring source to be written in a language for which there is an open source implementation (i.e., Python) is all they need to specify for others to duplicate the program output generated by the proposer (I have submitted some suggestions to the SEC about the issues that need to be addressed). The suggestions that a formally defined language be used is equally naive.
The availability of this source code opens up some interesting commercial prospects. No, not selling analysis tools to financial institutions but selling them program fault information, e.g., under circumstance X the program incorrectly predicts A will happen when in fact B will actually happen. Of course companies know this will happen and will put a lot more effort into ensuring that their models/code is correct.
Will these disclosure rules change the characteristics of financial software? One characteristic that I’m sure will change is the percentage of swear words in the comments and identifiers.
Recent Comments