Simple generator for compiler stress testing source
Since writing my C book I have been interested in the problem of generating source that has the syntactic and semantic statistical characteristics of human written code.
Generating code that obeys a language’s syntax is straight forward. Take a specification of the syntax (say is some yacc-like form) and ‘generate’ each of the terminals/nonterminals on the right-hand-side of the start symbol. Nonterminals will lead to rules having right-hand-sides that in turn need to be ‘generated’, a random selection being made when a nonterminal has more than one possible rhs rule. Output occurs when a terminal is ‘generated’.
For the code to mimic human written code it is necessary to bias the random selection process; a numeric value at the start of each rhs rule can be used to specify the percentage probability of that rule being chosen for the corresponding nonterminal.
The following example generates a subset of C expressions; nonterminals in lowercase, terminals in uppercase and implemented as a call to a function having that name:
%grammar first_rule : def_ident " = " expr " ;n" END_EXPR_STMT ; def_ident : MK_IDENT ; constant : MK_CONSTANT ; identifier : KNOWN_IDENT ; primary_expr : 30 constant | 60 identifier | 10 " (" expr ") " ; multiplicative_expr : 50 primary_expr | 40 multiplicative_expr " * " primary_expr | 10 multiplicative_expr " / " primary_expr ; additive_expr : 50 multiplicative_expr | 25 additive_expr " + " multiplicative_expr | 25 additive_expr " - " multiplicative_expr ; expr : START_EXPR additive_expr FINISH_EXPR ; |
A 250 line awk program (awk only because I use it often enough for simply text processing that it is second nature) translates this into two Python lists:
productions = [ [0], [ 1, 1, 1, # first_rule 0, 5, [2, 1001, 3, 1002, 1003, ], ], [ 2, 1, 1, # def_ident 0, 1, [1004, ], ], [ 4, 1, 1, # constant 0, 1, [1005, ], ], [ 5, 1, 1, # identifier 0, 1, [1006, ], ], [ 6, 3, 0, # primary_expr 30, 1, [4, ], 60, 1, [5, ], 10, 3, [1007, 3, 1008, ], ], [ 7, 3, 0, # multiplicative_expr 50, 1, [6, ], 40, 3, [7, 1009, 6, ], 10, 3, [7, 1010, 6, ], ], [ 8, 3, 0, # additive_expr 50, 1, [7, ], 25, 3, [8, 1011, 7, ], 25, 3, [8, 1012, 7, ], ], [ 3, 1, 1, # expr 0, 3, [1013, 8, 1014, ], ], ] terminal = [ [0], [ STR_TERM, " = "], [ STR_TERM, " ;n"], [ FUNC_TERM, END_EXPR_STMT], [ FUNC_TERM, MK_IDENT], [ FUNC_TERM, MK_CONSTANT], [ FUNC_TERM, KNOWN_IDENT], [ STR_TERM, " ("], [ STR_TERM, ") "], [ STR_TERM, " * "], [ STR_TERM, " / "], [ STR_TERM, " + "], [ STR_TERM, " - "], [ FUNC_TERM, START_EXPR], [ FUNC_TERM, FINISH_EXPR], ] |
which can be executed by a simply interpreter:
def exec_rule(some_rule) : rule_len=len(some_rule) cur_action=0 while (cur_action < rule_len) : if (some_rule[cur_action] > term_start_base) : gen_terminal(some_rule[cur_action]-term_start_base) else : exec_rule(select_rule(productions[some_rule[cur_action]])) cur_action+=1 productions.sort() start_code() ns=0 while (ns < 2000) : # Loop generating lots of test cases exec_rule(select_rule(productions[1])) ns+=1 end_code() |
Naive syntax-directed generation results in a lot of code that violates one or more fundamental semantic constraints. For instance the assignment (1+1)=3 is syntactically valid in many languages, which invariably specify a semantic constraint on the lhs of an assignment operator being some kind of modifiable storage location. The simplest solution to this problem is to change the syntax to limit the kinds of constructs that can be generated on the lhs of an assignment.
The hardest semantic association to get right is the connection between variable declarations and references to those variables in expressions. One solution is to mimic how I think many developers write code, that is to generate the statements first and then generate the required definitions for the appropriate variables.
A whole host of minor semantic issues require the syntax generated code to be tweaked, e.g., division by zero occurs more often in untweaked generated code than human code. There are also statistical patterns within the semantics of human written code, e.g., frequency of use of local variables, that need to be addressed.
A few weeks ago the source of Csmith, a C source generator designed to stress the code generation phase of a compiler, was released. Over the years various people have written C compiler stress testers, most recently NPL implemented one in Java, but this is the first time that the source has been released. Imagine my disappointment on discovering that Csmith contained around 40 KLOC of code, only a bit smaller than a C compiler I had once help write. I decided to see if my ‘human characteristics’ generator could be used to create a compiler code generator stress tester.
The idea behind compiler code generator stress testing is to generate a program containing some complicated sequence of code, compile and run it, comparing the value produced against the value that is supposed to be produced.
I modified the human characteristics generator to produce pairs of statements like the following:
i = i_3 * i_6 & i_2 << i_7 ; chk_result(i, 3 * 6 & 2 << 7, __LINE__); |
the second argument to chk_result is the value that i should contain (while generating the expression to assign to i the corresponding constant expression with the variables replaced by their known values is also created).
Having the compiler evaluate the constant expression simplifies the stress tester and provides another check that the compiler gets things right (or gets two different things wrong in the same way, in which case we probably don’t get to see any failure message). The first gcc bug I found concerned this constant expression (in fact this same compiler bug crops up with alarming regularity in the generated code).
As previously mentioned connecting variables in expressions to a corresponding definition is a lot of work. I simplified this problem by assuming that an integer variable i would be predefined in the surrounding support code and that this would be the only variable ever assigned to in the generated code.
There is some simple house-keeping that wraps everything within a program and provides the appropriate variable definitions.
The grammar used to generate full C expressions is 228 lines, the awk translator 252 lines and the Python interpreter 55 lines; just over 1% of Csmith in LOC and it is very easy to configure. However, an awful lot functionality needs to be added before it starts to rival Csmith, not least of which is support for assignment to more than one integer variable!
Quality comparison of floating-point maths libraries
What is the best way to compare the quality of floating-point math libraries (e.g., sin, cos and log)? The traditional approach for evaluating the quality of an algorithm implementing a mathematical function is based on mathematics; methods have been developed to calculate the maximum error between the calculated and the actual value. The answer produced by this approach does not say anything about how frequently this maximum error will occur, only that it occurs at least once.
The log (natural logarithm) is probably the most frequently used mathematical function and I decided to compare a few implementations; R statistical package version 2.11.1 and glibc (libm version 2.11.2) both running under Suse 11.3 on an AMD Athlon 64 X2, and Cygwin version 1.7.1 under Windows XP SP 2 on another AMD Athlon 64 X2.
The algorithm often used to implement mathematical functions involves evaluating a polynomial expression (e.g., Chebyshev polynomials) within a small range of values (various methods are used to map the argument into this range and then scale the calculated result). I decided to initially treat the implementations under test as black boxes and did not know the ranges they used; a range of 0.1 to 1.0 seemed like a good idea and I generated all single precision floating-point values between these two bounds (all 28,521,267 of them, with each adjacent pair still having  double precision values between them).
double precision values between them).
#include <math.h> #include <stdio.h> int main(int argc, char *argv[]) { float val = 0.1, max_val = 1.0; while (val < max_val) { printf("%12.10f\n", val); val=nextafterf(val, 1.1); } } |
This list of 28 million values was fed as input to three programs:
- bc, which was used to generate the list of assumed to be correct logarithm of these 28 million values. R supports 64-bit IEEE compliant floating-point values, as do the C compilers/libraries used, and the number of decimal digits supported in this representation is 15. To provide greater accuracy to compare against the values generated by bc contained 17 digits, an extra two decimal digits over the IEEE values.
scale=17 while ((val=read() > 0)) l(val)
- A C program.
#include <math.h> #include <stdio.h> int main(int argc, char *argv[]) { double val; while (!feof(stdin)) { scanf("%lf", &val); printf("%17.15f\n", log(val)); } }
- A R program.
base_range=file("stdin", open="r") base_val=as.numeric(readLines(base_range, n=1)) while (length(base_val) != 0) { cat(format(log(base_val), nsmall=15), file=stdout()) cat("\n", file=stdout()) base_val=as.numeric(readLines(base_range, n=1)) }
The output of the C and R programs was then compared against the output from bc; which unfortunately creates a dependency on the accuracy of the C & R binary to decimal output routines (the subsequent comparison process gets around the decimal-to-binary input problem by reading the log values as strings and comparing the last few digits of each respective value). Accurate floating-point I/O needs something like hexadecimal floating constants.
Plotting the number of computed values of log that differ by a given amount from the value computed by bc, we get (values whose error is below -50 will be rounded down and those above 50 rounded up, ignoring the issue of round to even):
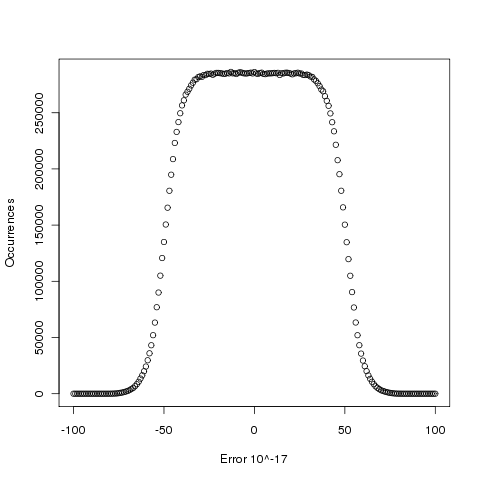
The results (raw data for R, Linux C and Cygwin C) show that around 5.6% of values are off by one in the last (15th) digit (Cygwin was slightly worse at 5.7%). The results for R/Linux C were almost identical and a quick check of the R source tree showed that R calls the C library function to evaluate log (it is a bit worrying that R is dependent on the host maths library, they should think about replacing this dependency by something like MPFR tout suite; even though the 64-bit glibc library is of very high quality it still has an environmental dependency).
Being off by one in the last decimal place is unlikely to keep many people awake at night. But if we want a measure of quality, is percentage of inaccurate values a useful measure of math library quality? Provided it is coupled with the amount of inaccuracy, I think this is a useful measure.
Empirical software engineering is five years old
Science and engineering are built on theoretical models that are tested against measurements of ‘reality’. Until around 10 years ago there was very little software engineering ‘reality’ publicly available; companies rarely made source available and were generally unforthcoming about any bugs that had been discovered. What happened around 10 years ago was the creation of public software repositories such as SourceForge and public fault databases such as Bugzilla. At last researchers had access to what could be claimed to be real world data.
Over the last five years there has been an explosion of papers using SourceForge/Bugzilla kinds of data looking for a connection between everything+kitchen sink and faults. The traditional measures such as Halstead and McCabe have not stood up well against this onslaught of data, hardly surprising given they were more or less conjured out of thin air. Some researchers are trying to extract information about developer characteristics from mailing lists; given that software is written by developers there is obviously a real need for the characteristics of major project contributors to play a significant role in any theory of software faults.
Software engineering data includes a lot more than what can be extracted from source code, bug lists and email lists. A growing number of repositories have been set up to hold measurement and experimental data, e.g., hardware failures, effort prediction (while some of this data is pre-2000 it tends to be low volume or poor quality), and file system related.
At the individual level a small number of researchers have made data available on their own web site, a few more will send a copy if asked and sadly there are many cases where the raw data has been lost. In two recent cases researchers have responded to my request for raw data by telling me they are working on additional papers and don’t want to make the data public yet. I can understand that obtaining interesting data requires a lot of work and researchers want to extract maximum benefit; I look forward to see the new papers and the eventual availability of the data.
My interest in all this data is that I have started work on a book covering empirical software engineering using R. Five years ago such book would have contained lots of equations, plenty of hand waving and if data sets were available they would probably have been small enough to print on one page. Today there are still plenty of equations (mostly relating to statistical this that and the other), no hand waving (well, none planned), data sets for everything covered (some in the gigabytes and a few that can still fit on a page) and pretty pictures (color graphs, as least for the pdf version).
When historians trace back the history of empirical software engineering I think they will say that it started for real sometime around 2005. Before then, any theories that were based on observation tended to have small, single study, data sets with little statistical significance or power.
A change of guard in the C standard’s world?
I have just gotten back from the latest ISO C meeting (known as WG14 in the language standard’s world) which finished a whole day ahead of schedule; always a good sign that things are under control. Many of the 18 people present in London were also present when the group last met in London four years ago and if memory serves this same subset of people were also attending meetings 20 years ago when I traveled around the world as UK head of delegation (these days my enthusiasm to attend does not extend to leaving the country).
The current convenor, John Benito, is stepping down after 15 years and I suspect that many other active members will be stepping back from involvement once the current work on revising C99 is published as the new C Standard (hopefully early next year meaning it will probably be known as C12).
From the very beginning the active UK participants in WG14 have held one important point of view that has consistently been at odds with a view held by the majority of US participants; we in the UK have believed that it should be possible to deduce the requirements contained in the C Standard without reference to any deliberations of WG14, while many US participants have actively argued against what they see as over specification. I think one of the problems with trying to change US minds has been that the opinion leaders have been involved for so long and know the issues so well they cannot see how anybody could possible interpret wording in the standard in anything other than the ‘obvious’ way.
An example of the desire to not over specify is provided by a defect report I submitted 18 years ago, in particular question 19; what does:
#define f(a) a*g #define g(a) f(a) f(2)(9) |
expand to? There are two possibilities and WG14 came to the conclusion that both were valid macro expansions, making the behavior unspecified. However, when it came to a vote the consensus came down on the side of saying nothing about this case in the normative body of the standard, the only visible evidence for this behavior being a bulleted item added to the annex containing the list of unspecified behaviors.
A new member of WG14 (he has only been involved for a few years) spotted this bulleted item that had no corresponding text in the main body of the standard, tracked down the defect report that generated it and submitted a new defect report asking for wording to be added. At the meeting today the straw poll of those present was in favor of adding an appropriate example to C12 {I will link to the appropriate paper once it appears on the public WG14 site}. A minor victory on the road to a full and complete specification.
It will be interesting to see what impact a standing down of the old guard, after the publication of C12, has C2X (the revision of C that is likely to be published around 10 years from now).
For those of you still scratching their head, the two possibilities are:
2*f(9) |
or
2*9*g |
Hexadecimal usage in Google’s scanned books
After investigating programming language name usage in Google’s ngram viewer, I decided to try something more specific. Hexadecimal literals are an interesting subproblem in optical character recognition; a little uncertainty in an image can result in a character sequence being equally viable as a word or a hexadecimal literal.
I downloaded all the Google books 1-grams and started to experiment. I eventually considered any character sequence matching the pattern ^[0oO][xX][0-9a-fA-FoOl] for further analysis; that is ohh, Ohh and ell were treated as the corresponding digits.
This prefix matching reduced 473 million possibilities down to 89 thousand.
Next any character sequence containing a non-hex character (again ohh, Ohh and ell were treated as special cases) was removed, bringing the possibilities down to 20 thousand.
When did the first hexadecimal literal appear in print? I settled on a generous view of history, 1945; also the sequence oxo seemed surprisingly common and looking at a few of the contexts in which it occurred I decided that most of the usage related to chemical formula and removed all matches. The post-1945 and oxo checks removed a third of remaining character sequences.
It seems to me that if any hexadecimal literal appears in a book, at least one more is likely to occur. Google does not provide a breakdown of each character sequence by book; for a given character sequence, the total count for each year is given, along with the number of pages it occurred on in that year and the number of different books it appeared within in the year. If the number of occurrences of a character sequence in a given year equalled the number of different books I excluded the usage count; this reduced the number of matches from 13,729 to 7,292; with 319 unique character sequences.
Are the remaining of character sequences a reasonably accurate list of hexadecimal literals appearing in the books that Google has scanned? Is 0.15 hexadecimal literals per million words a reasonable value?
A while back, I did some analysis of C source usage that included checking whether integer literals followed Benford’s law. Extracting the first non-zero digit from the character sequences extracted from Google books and comparing them with the C source hexadecimal data we get:
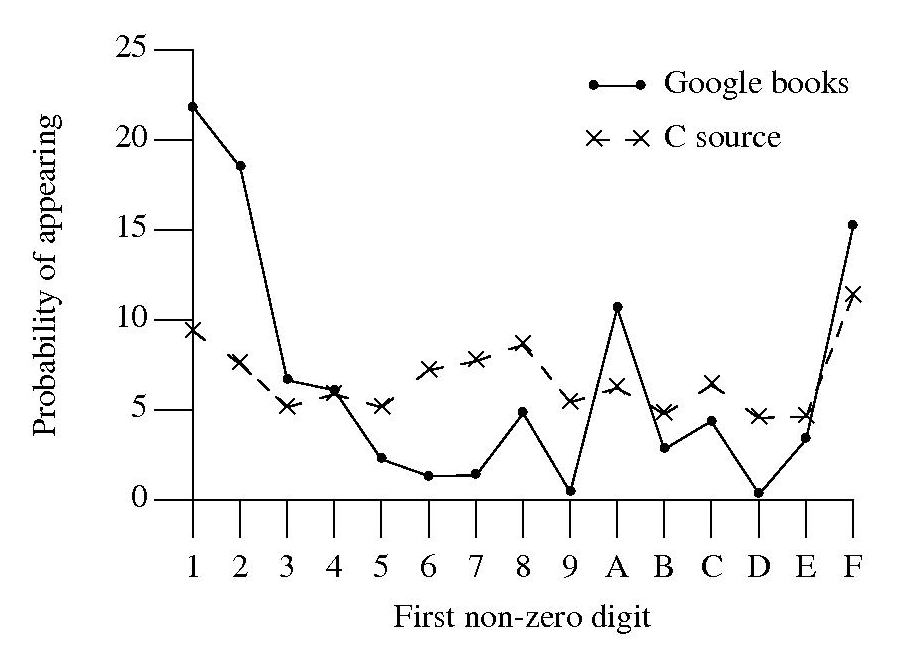
Both plots share ‘spikes’ at five values, but the pattern of relative sizes is different. Perhaps the pattern of hexadecimal literal usage in C source is slightly different from what occurs in other languages, or perhaps the relatively large percentage of 1 occurs because ell is accepted.
The context in which a character sequenced occurred would probably be a very good indicator of whether it was a hexadecimal literal or not. Google only provide a subset of their 2-grams and any analysis of these will have to wait for another time; however I did quickly check to see whether the OCR process had resulted in a single literal being split into two separate sequences, a manual check of the 95 possible sequences I found showed that most were not good candidates for a split literal.
The final list of ‘hexadecimal literal’s and their occurrence counts is available for download.
ISO Standards, the beauty and the beast
Standards is one area where a monopoly can provide a worthwhile benefit. After all the primary purpose of a standard for something is having just the one document for everybody to follow (having multiple standards because they are so useful is not a good idea). However, a common problem with monopolies is that charge a very inflated price for their product.
Many years ago the International Standard Organization settled on a pricing scheme for ISO Standards based on document page count. Most standards are very short and have a very small customer base, so there is commercial logic to having a high cost per page (especially since most are bought by large companies who need a copy if they do business in the corresponding application domain). Programming language standards do not fit this pattern, often being very long and potentially having a very large customer base.
With over 18,500 standards in their catalogue ISO might be forgiven for overlooking the dozen or so language standards, or perhaps they figured there is as much profit in charging a few hundred pounds on a few sales as charging less on more sales.
How does the move to electronic distribution effect prices? For a monopoly electronic distribution is an opportunity to make more profit, not to reduce prices. The recently published revision of the Fortran Standard is available for 338 Swiss francs (around £232) from ISO and £356 from BSI (at $351 the price from ANSI in the US is similar to ISO’s). Many years ago, at the dawn of the Internet, members of the US C Standard committee were able to convince ANSI to sell electronic copies at a reasonable rate ($30) and this practice has continued ever since (and now includes C++).
The market for the C and C++ Standards is sufficiently large that a commercial publisher (Wiley) was willing to take the risk of publishing them in book form (after some prodding and leg work by the likes of Francis Glassborow). It will be interesting to see if a publisher is willing to take a chance on a print run of the revised C Standard due out in a few years (I think the answer for the revised C++ Standard is more obvious).
Don’t Standards bodies care about computer languages? Unfortunately we are thorn in their side and they would be happy to be rid of us (but their charter’s do not allow them to do this). Our standards take much longer to produce than other standards, they are large and sales are almost non-existent (at ISO/BSI prices). What is more many of those involved in creating these standards actively subvert ISO/BSI sales by making draft documents, that are very close to the final copyrighted versions, freely available over the Internet.
In a sense ISO programming language standards exist because the organizational structure requires them to accept our work proposals and what we do does not have a large enough impact within the standards world for them to try and be rid of those tiresome people whose work is so far removed from what everybody else does.
SQL usage: schema evolution
My first serious involvement with SQL, about 15 years ago, was writing a parser for the grammar specified in the ISO SQL-92 Standard. One of the things that surprised me about SQL was how little source code was generally available (for testing) and the almost complete lack of any published papers on SQL usage (its always better to find out about where the pot-holes are from other peoples’ experience).
The source code availability surprie is largely answered by the very close coupling between source and data that occurs with SQL; most SQL source is closely tied to a database schema and unless you have a need to process exactly the same kind of data you are unlikely to have any interest having access to the corresponding SQL source. The growth in usage of MySQL means that these days it is much easier to get hold of large amounts of SQL (large is a relative term here, I suspect that there are probably many orders of magnitude fewer lines of SQL in existence than there is of other popular languages).
In my case I was fortunate in that NIST released their SQL validation suite for beta testing just as I started to test my parser (it had taken me a month to get the grammar into a manageable shape).
Published research on SQL usage continues to be thin on the ground and I was pleased to recently discover a paper combining empirical work on SQL usage with another rarely researched topic, declaration usage e.g., variables and types or in this case schema evolution (for instance, changes in the table columns over time).
The researchers only analyzed one database, the 171 releases of the schema used by Wikipedia between April 2003 and November 2007, but they also made their scripts available for download and hopefully the results of applying them to lots of other databases will be published.
Not being an experienced database person I don’t know how representative the Wikipedia figures are; the number of tables increased from 17 to 34 (100% increase) and the number of columns from 100 to 242 (142%). A factor of two increase sounds like a lot but I suspect that all but one these columns occupy a tiny fraction of the 14GB that is the current English Wikipedia.
Program optimization given 1,000 datasets
A recent paper reminded me of a consequence of widespread availability of multi-processor systems I had failed to mention in a previous post on compiler writing in the next decade. The wide spread availability of systems containing large numbers of processors opens up opportunities for both end users of compilers and compiler writers.
Some compiler optimizations involve making decisions about what parts of a program will be executed more frequently than other parts; usually speeding up the frequently executed at the expense of slowing down the less frequently executed. The flow of control through a program is often effected by the input it has been given.
Traditionally optimization tuning has been done by feeding a small number of input datasets into a small number of programs, with the lazy using only the SPEC benchmarks and the more conscientious (or perhaps driven by one very important customer) using a few more acquired over time. A few years ago the iterative compiler tuning community started to address this lack of input benchmark datasets by creating 20 datasets for each of their benchmark programs.
Twenty datasets was certainly a step up from a few. Now one group (Evaluating Iterative Optimization Across 1000 Data Sets; written by a team of six people) has used 1,000 different input data sets to evaluate the runtime performance of a program; in fact they test 32 different programs each having their own 1,000 data sets. Oh, one fact they forgot to mention in the abstract was that each of these 32 programs was compiled with 300 different combinations of compiler options before being fed the 1,000 datasets (another post talks about the problem of selecting which optimizations to perform and the order in which to perform them); so each program is executed 300,000 times.
Standing back from this one could ask why optimizers have to be ‘pre-tuned’ using fixed datasets and programs. For any program the best optimization results are obtained by profiling it processing large amounts of real life data and then feeding this profile data back to a recompilation of the original source. The problem with this form of optimization is that most users are not willing to invest the time and effort needed to collect the profile data.
Some people might ask if 1,000 datasets is too many, I would ask if it is enough. Optimization often involves trade-offs and benchmark datasets need to provide enough information to compiler writers that they can reliably tune their products. The authors of the paper are still analyzing their data and I imagine that reducing redundancy in their dataset is one area they are looking at. One topic not covered in their first paper, which I hope they plan to address, is how program power consumption varies across the different datasets.
Where next with the large multi-processor systems compiler writers now have available to them? Well, 32 programs is not really enough to claim reasonable coverage of all program characteristics that compilers are likely to encounter. A benchmark containing 1,000 different programs is the obvious next step. One major hurdle, apart from the people time involved, is finding 1,000 programs that have usable datasets associated with them.
Language usage in Google’s ngram viewer
I thought I would join the fun that people are having with Google’s new ngram viewer. The raw data (only a subset for bigrams and longer ngrams) was also enticing, but at 35+ gigabytes for the compressed 1/2/3-grams of English-all I decided to forgo the longer n-grams.
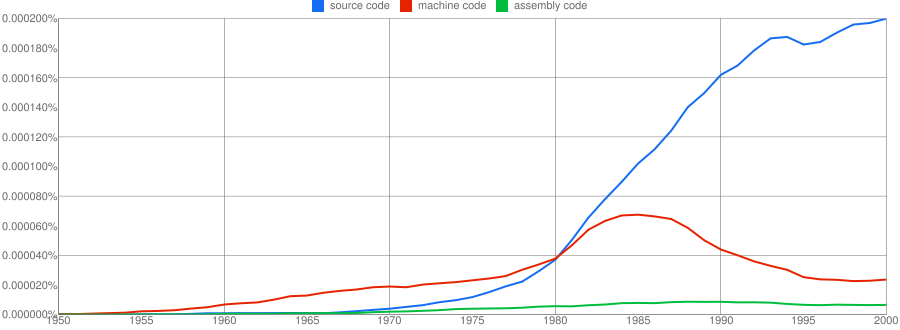
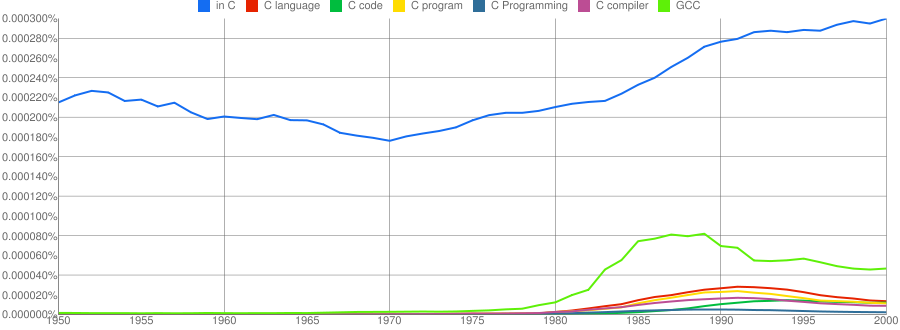
We all know that in the dim and distant past most programmers wrote in machine code, but it was not until 1980 that “source code” appeared more frequently in books that “machine code”.
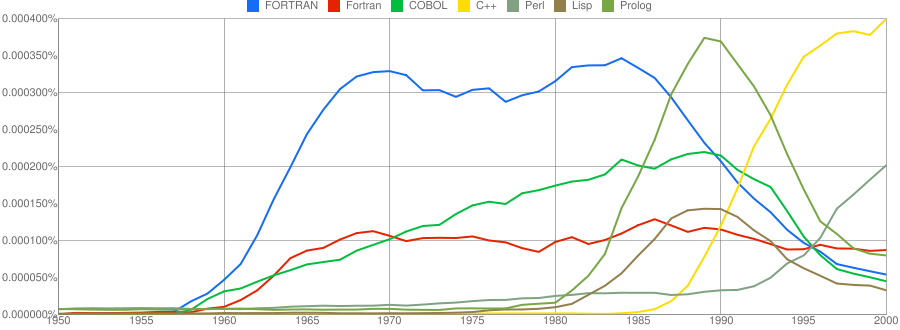
Computer language popularity is a perennial question. Fortran and Cobol address very different markets and I would have expected their usage to follow similar patterns, with “COBOL” having the obvious usage pattern for them both to follow. Instead, both “FORTRAN” and “Fortran” peaked within 10 years, with one staying there for another 20 years before declining and the other still going strong in 2000 (and still ahead of “PHP” and “Python” in 2000; neither shown to keep the clutter down). I am surprised to see “Prolog” usage being so much greater than “Lisp” and I would have expected “Lisp” to have a stronger presence in the 1970s.
I think the C++ crowd will be surprised to see that in 2000 usage was not much greater than what “FORTRAN” had enjoyed for 20 years.
“C”, as in language, usage is obviously different to reliably measure. I have tried the obvious bigrams. Looking at some of the book matches for the phrase “in C” shows that the OCR process has sometimes inserted spaces that probably did not exist in the original, the effect being to split words and create incorrect bigrams. The phrase “in C” would also appear in books on music.
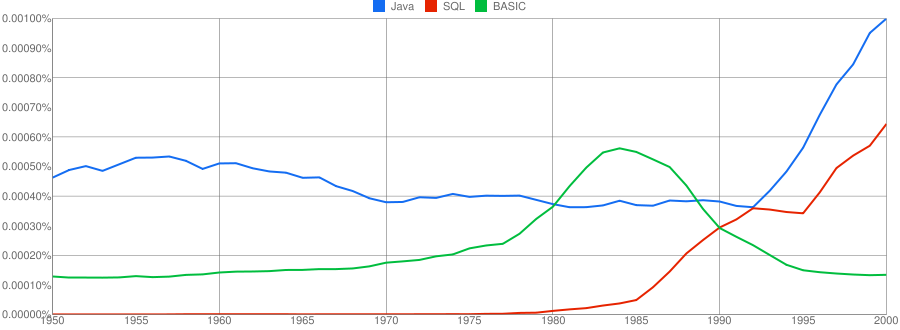
I have put the three words “Java”/”SQL”/”BASIC” in a separate plot because their usage swamps that of the other languages. Java obviously has multiple non-computer related uses and subtracting the estimated background usage suggests a language usage similar to that of “SQL”. There is too much noise for the usage of “Basic” to tell us much.
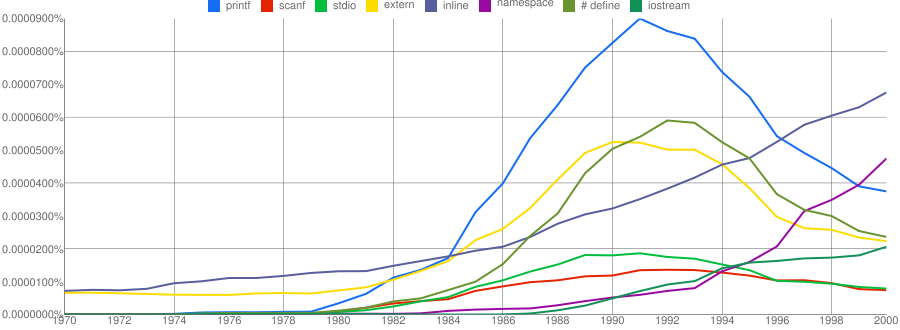
One way of comparing C/C++ language usage is to look source code usage where they are likely to differ. I/O, in the form of printf/scanf and stdio/iostream, is one obvious choice and while the expected C usage starts to declines in the 1990s the C++ usage just shows a stead growth (perhaps the <</>> usage, which does not appear in the Google viewer, has a dramatic growth during this time period).
Surprisingly #define also follows a similar pattern of decline. Even allowing for the rabid anti-macro rhetoric of the C++ in-crowd I would not have expected such a rapid decline. Perhaps this is some artifact of the book selection process used by Google; but then "namespace" shows a healthy growth around this time period.
The growth of "inline" over such a long period of time is a mystery. Perhaps some of this usage does not relate to a keyword appearing within source code examples but to text along the lines of "put this inline to make it faster".
What usage should we expect for the last decade? A greater usage of "PHP" and "Python" is an obvious call to make, along with the continuing growth of SQL, I think "UML" will also feature prominently. Will "C++" show a decline in favor or "Java" and what about "C#"? We will have to wait and see.
Has the seed that gets software development out of the stone-age been sown?
A big puzzle for archaeologists is why Stone Age culture lasted as long as it did (from approximately 2.5 millions years ago until the start of the copper age around 6.3 thousand years ago). Given the range of innovation rates seen in various cultures through-out human history, a much shorter Stone Age is to be expected. A recent paper proposes that low population density is what maintained the Stone Age status quo; there was not enough contact between different hunter gather groups for widespread take up of innovations. Life was tough, and the viable lifetime of individual groups of people may not have been long enough for them to be likely to pass on innovations (either their own ones encountered through contact with other groups).
Software development is often done by small groups that don’t communicate with other groups and regularly die out (well there is a high turn-over, with many of the more experienced people moving on to non-software roles). There are sufficient parallels between hunter gathers and software developers to suggest both were/are kept in a Stone Age for the same reason, lack of a method that enables people to obtain information about innovations and how worthwhile these might be within a given environment.
A huge barrier to the development of better software development practices is the almost complete lack of significant quantities of reliable empirical data that can be used to judge whether a claimed innovation is really worthwhile. Companies rarely make their detailed fault databases and product development history public; who wants to risk negative publicity and lawsuits just so academics have some data to work with.
At the start of this decade, public source code repositories like SourceForge and public software fault repositories like Bugzilla started to spring up. These repositories contain a huge amount of information about the characteristics of the software development process. Questions that can be asked of this data include: what are common patterns of development and which ones result in fewer faults, how does software evolve and how well do the techniques used to manage it work.
Empirical software engineering researchers are now setting up repositories, like Promise, containing the raw data from their analysis of Open Source (and some closed source) projects. By making this raw data available, they are reducing the effort needed by other researchers to investigate their own alternative ideas (I have just started a book on empirical software engineering using the R statistical language that uses examples based on this raw data).
One of the side effects of Open Source development could be the creation of software development practices that have been shown to be better (including showing that some existing practices make things worse). The source of these practices not being what the software developers themselves do or how they do it, but the footsteps they have left behind in the sand.
Recent Comments