Matching context sensitive rules and generating output using regular expressions
I have previously written about generating words that sound like an input word. My interest in reimplementing this project from many years ago was fueled by a desire to find out exactly how flexible modern regular expression libraries are (the original used a bespoke tool). I had a set of regular expressions describing a mapping from one or more letters to one or more phonemes and I wanted to use someone else’s library to do all the heavy duty matching.
The following lists some of the mapping rules. The letters between [] are the ones that are ‘consumed’ by the match and any letters/characters either side are the context required for the rule to match. The characters between // are phonemes represented using the Arpabet phonetic transcription.
@[ew]=/UW/ [giv]=/G IH V/ [g]i^=/G/ [ge]t=/G EH/ su[gges]=/G JH EH S/ [gg]=/G/ b$[g]=/G/ [g]+=/JH/ # space - start of word # $ - one or more vowels # ! - two or more vowels # + - one front vowel # : - zero or more consonants # ^ - one consonant # ; - one or more consonants # . - one voiced consonant # @ - one special consonant # & - one sibilant # % - one suffix |
After some searching I settled on using the PCRE (Perl Compatible Regular Expressions) library, which contains more functionality than you can shake a stick at.
My plan was to translate each of the 300+ rules, using awk, into a regular expression, concatenate all of these together using alternation and let PCRE handle all of the matching details; which is what I did and it worked. Along the way a few problems had to be solved…
How can the appropriate phoneme(s) be generated when a rule matches? The solution is to use what PCRE calls callouts. During matching if the sequence (?C77) is encountered in the pattern a developer defined function (set up prior to calling pcre_execute) is called with information about the current state of the match. In this example the information would include the value 77 (values between 0 and 255 are supported). By embedding a unique number in the subpattern for each rule (and writing the appropriate phoneme sequence out to a configuration file that is read on program startup) it is possible to generate the appropriate output (because there are more than 255 rules a pair of callouts are needed to specify larger values).
How can the left/right letter context be handled? Most regular expression matching works by consuming all of the matched characters, making them unavailable for matching by other parts of the regular expression during that match. PCRE supports what it calls left and right assertions, which require a pattern to match but don’t consume the matched characters, leaving them to be matched by some other part of the pattern. So the rule [ge]t is mapped to the regular expression ge(?=t) which consumes a ge followed by a t but leaves the t for matching by another part of the pattern.
One problem occurs for backward assertions, which are restricted to matching the same number of characters for all alternatives of the pattern. For example the backward assertion (?<=(a|ab)e) is not supported because one path through the pattern is two characters long while the other is three characters long. The rule @[ew] cannot be matched using a backward assertion because @ includes letter sequences of different length (e.g., N, J, TH). The solution is to use a callout to perform a special left context match (specified by the callout number) which works by reversing the word being matched and the left context pattern and performing a forward (rather than backward) match.
The final pattern is over 10,000 characters long and looks something like (notice that everything is enclosed in () and terminated by a + to force the longest possible match, i.e., the complete word:
(((a(?=$)(?C51)))|((?<=^)(are(?=$)(?C52)))| ... |(z(?C106)(?C55)))+ |
Now we need a method of using the letter to phoneme rules to map phonemes to letters. In some cases a phoneme sequence can be mapped to multiple letter sequences and I wanted to generate all of the possible letter sequences (e.g., cat -> K AE T -> cat, kat, qat). PCRE does support a matching function capable of returning all possible matches. However this function does not support some of the functionality required, so I decided to 'force' the single match function to generate all possible sequences by using a callout to make it unconditionally fail as the last operation of every otherwise successful match, causing the matching process to backtrack and try to find an alternative match. Not the most efficient of solutions but it saved me having to learn a lot more about the functionality supported by PCRE.
For a given sequence of phonemes it is simple enough to match it using a regular expression created from the existing rules. However, any match also needs to meet any left/right letter context requirements. Because we are generating letters left to right we have a left context that can be matched, but no right context.
The left context is matched by applying the technique used for variable length left contexts, described above, i.e., the letters generated so far are reversed and these are matched using a reversed left context pattern.
An efficient solution to matching right context would be very fiddly to implement. I took the simple approach of ignoring the right letter context until the complete phoneme sequence had been matched; the generated letter sequence out of this matching process is feed as input to the letter-to-phoneme function and the returned phoneme sequence compared against the original generating phoneme sequence. If the two phoneme sequences are identical the generated letter sequence is included in the final set of returned letter sequences. Not very computer efficient, but an efficient use of my time.
I could not resist including some optimzations. For instance, if a letter sequence only matches at the start or end of a word then the corresponding phonemes can only match at the start/end of the sequence.
I have skipped some of the minor details, which you can read about in the source of the tool.
I would be interested to hear about the libraries/tools used by readers with experience matching patterns of this complexity.
Generating sounds-like and accented words
I have always been surprised by the approaches other people have taken to generating words that sound like a particular word or judging whether two words sound alike. The aspell program letter sequence is in its dictionary; the Soundex algorithm is often used to compare whether two words sound alike and has the advantage of being very simple and delivers results that many people seem willing to accept. Over 25 years ago I wrote some software that used a phoneme based approach and while sorting through a pile of papers recently I came across an old report used as the basis for that software. I decided to implement a word sounds-like tool to show people how I think sounds-like should be done. To reduce the work involved this initial tool is based on what I already know, which in some cases is very out of date.
Phonemes are the basic units of sound and any sounds-like software needs to operate on a word’s phoneme sequence, not its letter sequence. The way to proceed is to convert a word’s letter sequence to its phoneme sequence, manipulate the phoneme sequence to create other sequences that have a spoken form similar to the original word and then convert these new sequences back to letter sequences.
A 1976 report by Elovitz, Johnson, McHugh and Shore contains a list of 329 rules for converting a word’s letter sequence into a phoneme sequence. It seemed to me that this same set of rules could be driven in reverse to map a phoneme sequence back to a letter sequence (the complications involved in making this simple idea work will be discussed in another article).
Once we have a phoneme sequence how might it be modified to create similar sounding words?
The distinctive feature theory assigns ten or so features to every phoneme, these denote details such as such things as manner and place of articulation. I decided to use these features as the basis of a distance metric between two phonemes (e.g., the more features two phonemes had in common the more similar they sounded). The book “Phonology theory and analysis” by Larry M. Hyman contains the required table of phoneme/distinctive features. Yes, I am using a theory from the 1950s and a book from the 1970s, but to start with I want to recreate what I know can be done before moving on to use more modern theories/data.
In practice this approach generates too many letter sequences that just don’t look like English words. The underlying problem is that the letter/phoneme rules were not designed to be run in reverse. Rather than tune the existing rules to do a better job when run in reverse I used the simpler method of filtering using letter bigrams to remove non-English letter sequences (e.g., ‘ck’ is not acceptable at the start of a word letter sequence). In preInternet times word bigram information was obtained from specialist cryptographic publishers, but these days psychologists researching human reading are a very good source of reliable information (or at least one I am familiar with).
I have implemented this approach and the system currently supports the generation of:
- letter sequences that sound the same as the input word, e.g., cowd, coad, kowd, koad.
- letter sequences that sound similar to the input word, e.g., bite, dight, duyt, gight, guyt, might, muyt, pight, puyt, bit, byt, bait, bayt, beight, beet, beat, beit, beyt, boyt, boit, but, bied, bighd, buyd, bighp, buyp, bighng, buyng, bighth, buyth, bight, buyt
- letter sequences that sound like the input word said with a German accent, e.g., one, vun and woven, voughen, vuphen.
The output can be piped through a spell checker to remove nondictionary letter sequences.
How accurate are the various sequence translations? Based on a comparison against manual translation of several thousand words from the Brown corpus Elovitz et al claim around 90% of words in random text will be correctly translated to phonemes. I have not done any empirical analysis of the performance of the rules when used to convert phoneme sequences to letters; it will obviously be less than 90%.
The source code of the somewhat experimental tool is available for download. Please note that the code has only been built on Linux, is likely to be fragile in various places and needs a recent copy of the pcre library. Bug reports welcome.
Some of the uses for a word’s phoneme sequence include:
- matching names contained in information transcribed using different conventions or by different people (i.e., slight spelling differences).
- better word splitting at the end of line in LaTeX. Word splitting decisions are best made using sound units.
- better spell checking, particularly for non-native English speakers when coupled with a sound model of common mistakes made by speakers of other languages.
- aid to remembering partially forgotten words whose approximate sound can be remembered.
- inventing trendy spellings for words.
Where next?
Knowledge of the written and spoken word had moved forward in the last 25 years and various other techniques that might improve the performance of the tool are now available. My interest in the written, rather than the spoken, form of code means I have only followed written/sound conversion at a superficial level; reader suggestions on more modern theories, models and data sources that might be used to improve the tools performance are most welcome. A few of my own thoughts:
- As I understand it modern text to speech systems are driven by models derived through machine learning (i.e., some learning algorithm has processed lots of data). There might be existing models out there that can be used, otherwise the MRC Psycholinguistic Database is a good source for lots for word phoneme sequences and perhaps might be used to learn rules for both letter to phoneme and phoneme to letter conversion.
- Is Distinctive feature theory the best basis for a phoneme sounds-like metric? If not which theory should be used and where can the required detailed phoneme information be found? Hyman gives yes/no values for each feature while the first edition of Ladeforded’s “A Course in Phonetics” gives percentage contribution values for the distinctive features of some phonemes; subsequent editions don’t include this information. Is a complete table of percentage contribution of each feature to every phoneme available somewhere?
- A more sophisticated approach to sounds-like would take phoneme context into account. A slightly less crude approach would be to make use of phoneme bigram information extracted from the MRC database. What is really needed is a theory of sounds-like and some machine usable rules; this would hopefully support the adding and removal of phonemes and not just changing existing ones.
As part of my R education I plan to create an R sounds-like package.
In the next article I will talk about how I used and abused the PCRE (Perl Compatible Regular Expressions) library to recognize a context dependent set of rules and generate corresponding output.
The fatal programming language research mistake
There is a fatal mistake often made by those involved in academic programming language research and a recent blog post (by an academic) asking if programming language research has a future has spurred me into writing about this mistake.
As an aside, I would agree with much of what the academic (Cristina (Crista) Videira Lopes) says about many popular modern programming languages being hacked together by kids who did not know much, if anything about, language design. However, this post is not a lament about the poor design quality of the languages commonly used in the commercial world; it is about the most common fatal mistake academics make when researching programming languages and a suggestion about how they can avoid making this mistake. What really endeared me to Crista was her critic of academic claims of language ‘betterness’ being completely unfounded (i.e., not being based on any empirical research).
The most common fatal mistake made by researchers in programing language design is to invent a new language. Creating an implementation for any language is a big undertaking and a new language has the added hurdles of convincing developers it is worth learning, providing the learning/reference materials and porting to multiple platforms. Researchers spend nearly all their time creating an implementation and a small percentage of their time actively researching the ‘new idea’.
The attraction of designing a new language is that it is regarded as ‘sexy’ activity and the first (and usually only) time around the work needed to create an implementations does not look that great.
If a researcher really does feel that their idea is so revolutionary it is worth creating a whole new language for and they want me, and others, to start using it, then they need to make sure they can answer yes to the following questions:
- Have you, or your students, created an implementation of the language that provides reasonable diagnostics, executes programs at an acceptable rate and is available free of charge on the operating systems I use for software development?
- Is sufficient documentation available for me to learn the language and act as a reference manual once I become more expert?
- For the next five years will you, or your students, be providing, free of charge, prompt bug fixes to errors in your implementation?
- Will you and your students spend the time necessary to build an active user community for your language?
- For the next five years will you, or your students knowledgeable in the language, provide prompt support (via an email group or bulletin board) to user queries?
Some new languages from academia have managed to answer yes to these questions (Haskell, R and OCaml spring to mind, but only R looks like it will have any significant industrial take-up).
In practice most new languages fail to get past fragile implementations only ever used by their designer, with minimal new research to show for all the effort that went into them.
What programming language researchers need to do, at least if they want people outside of their own department to pay any attention to their ideas, is to experiment by adding functionality to an existing language. Using an existing language as a base has the advantages:
- modifying an existing implementation is significantly less work than creating a new one,
- having to address all of the features present in real world languages will help weed out poor designs that only look good on paper (I continue to be amazed that people can be involved in programming language research without knowing any language very well),
- documentation for most of the language already exists,
- more likely to attract early adopters, developers tend to treat existing language+extensions as being a much smaller jump than a new language.
Programming language research is something of a fashion industry and I can well imagine people objecting to having to deal with a messy existing language. Well yes, the real world is a messy place and if a new design idea cannot handle that it deserves to be lost to posterity.
One cannot blame students for being idealistic and thinking they can create a language that will take over the world. It is the members of staff who should be ridiculed for being either naive or intellectually shallow.
Parsing R code: Freedom of expression is not always a good idea
With my growing interest in R it was inevitable that I would end up writing a parser for it. The fact that the language is relatively small (the add-on packages do the serious work) hastened the event because it did not look like much work; famous last words. I knew about R’s design and implementation being strongly influenced by the world view of functional programming and this should have set alarm bells ringing; this community have a history of willfully ignoring some of the undesirable consequences of their penchant of taking simple ideas and over generalizing them (i.e., I should have expected hidden complications).
While the official R language definition only contains a tiny fraction of the information needed to create a full implementation I decided to use it rather than ‘cheat’ and look at the R project implementation sources. I took as my oracle of correctness the source code of the substantial amount of R in its 3,000+ package library. This approach would help me uncover some of the incorrect preconceived ideas I have about how R source fits together.
I started with a C lexer and chopped and changed (it is difficult to do decent error recovery in automatically generated lexers and I prefer to avoid them). A few surprises cropped up ** is supported as an undocumented form of ^ and by default ]] must be treated as two tokens (e.g., two ] in a[b[c]] but one ]] in d[[e]], an exception to the very commonly used maximal munch rule).
The R grammar is all about expressions with some statement bits and pieces thrown in. R operator precedence follows that of Fortran, except the precedence of unary plus/minus has been increased to be above multiply/divide (instead of below). Easy peasy, cut and paste an existing expression grammar and done by tea time :-). Several tea times later I have a grammar that parses all of the R packages (apart from 80+ real syntax errors contained therein and a hand full of kinky operator combinations I’m not willing to contort the grammar to support). So what happened?
Two factors accounts for most of the difference between my estimate of the work required and the actual work required:
- my belief that a well written grammar has no ambiguities (while zero is a common goal for many projects a handful might be acceptable if the building is on fire and I have to leave). A major advantage of automatic generation of parser tables from a grammar specification is being warned about ambiguities in the grammar (either shift/reduce or reduce/reduce conflicts). At an early stage I was pulling my hair out over having 59 conflicts and decided to relent and look at the R project source and was amazed to find their grammar has 81 ambiguities!
I have managed to get the number of ambiguities down to the mid-30s, not good at all but it will have to do for the time being.
- some of my preconceptions about of how R syntax worked were seriously wrong. In some cases I spotted my mistake quickly because I recognized the behavior from other languages I know, other misconceptions took a lot longer to understand and handle because I did not believe anybody would design expression evaluation to work that way.
The root cause of the difference can more concretely be traced to the approach to specifying language syntax. The R project grammar is written using the form commonly seen in functional language implementations and introductory compiler books. This form has the advantage of being very short and apparently simple; the following is a cut down example in a form of BNF used by many parser generators:
expr : expr op expr | IDENTIFIER ; op : &' | '==' | '>' | '+' | '-' | '*' | '/' | '^' ; |
This specifies a sequence of IDENTIFIERs separated by binary operators and is ambiguous when the expression contains more than two operators, e.g., a + b * c can be parsed in more than one way. Parser generators such as Yacc will complain and flag any ambiguity and pick one of the possibilities as the default behavior for handling a given ambiguity; developers can specify additional grammar information in the file read by Yacc to guide its behavior when deciding how to resolve specific ambiguities. For instance, the relative precedence of operators can be specified and this information would be used by Yacc to decide that the ambiguous expression a + b * c should be parsed as-if it had been written like a + (b * c) rather than like (a + b) * c. The R project grammar is short, highly ambiguous and relies on the information contained in the explicitly specified relative operator precedence and associativity directives to resolve the ambiguities.
An alternative method of specifying the grammar is to have a separate list of grammar rules for each level of precedence (I always use this approach). In this approach there is no ambiguity, the precedence and associativity are implicitly specified by how the grammar is written. Obviously this approach creates much longer grammars, there will be at least two rules for every precedence level (19 in R, many with multiple operators). The following is a cut down example containing just multiple, divide, add and subtract:
... multiplicative_expression: cast_expression | multiplicative_expression '*' cast_expression | multiplicative_expression '/' cast_expression ; additive_expression: multiplicative_expression | additive_expression '+' multiplicative_expression | additive_expression '-' multiplicative_expression ; ... |
The advantages of this approach are that, because there are no ambiguities, the developer can see exactly how the grammar behaves and if an ambiguity is accidentally introduced when editing the source it should be noticed when the parser generator reports a problem where previously there were none (rather than the new ambiguity being hidden in the barrage of existing ones that are ignored because they are so numerous).
My first big misconception about R syntax was to think that R had statements, it doesn’t. What other languages would treat as statements R always treats as expressions. The if, for and while constructs have values (e.g., 2*(if (x == y) 2 else 4)). No problem, I used Algol 68 as an undergraduate, which supports this kind of usage. I assumed that when an if appeared as an operand in an expression it would have to be bracketed using () or {} to avoid creating a substantial number of parsing ambiguities; WRONG. No brackets need be specified, the R expression if (x == y) 2 else 4+1 is ambiguous (it could be treated as-if it had been written if (x == y) 2 else (4+1) or (if (x == y) 2 else 4)+1) and the R project grammar relies on its precedence specification to resolve the conflict (in favor of the first possibility listed above).
My next big surprise came from the handling of unary operators. Most modern languages give all unary operators the same precedence, generally higher than any binary operator. Following Fortran the R unary operators have a variety of different precedence levels; however R did not adopt the restrictions Fortran places on where unary operators can occur.
I assumed that R had adopted the restrictions used by other languages containing unary operators at different precedence levels, e.g., not allowing a unary operator token to follow a binary operator token (i.e., there has to be an intervening opening parenthesis); WRONG. R allows me to write 1 == !1 < 0, while Fortran (and Ada, etc) require that a parenthesis be inserted between the operands == ! (hopefully resulting in the intent being clearer).
I had to think a bit to come up with an explicit set of grammar rules to handle R unary operator's freedom of expression (without creating any ambiguities).
Stepping back from the details. My view is that programming language syntax should be designed to reduce the number of mistakes developers make. Requiring that brackets appear in certain contexts helps prevent mistakes by the original author and subsequent readers of the code.
Claims that R (or any other language) syntax is 'natural' is clearly spurious and really no more than a statement of preference by the speaker. Our DNA has not yet been found to equip us to handle one programming language better than another.
Over the coming months I hope to have the time to analyse R source looking for faults that might not have occurred had brackets been used. Also how much code might be broken if R started to require brackets in certain contexts?
An example of the difference that brackets can make is provided by the handling of the unary ! operator in R and C/C++/Java/etc. Take the expression !x > y, which R parses as-if written !(x > y) and C/C++/Java/etc as if written (!x) > y. I would not claim that either is better than the other from the point of view of developers getting the behavior right, I know that some C programmers get it wrong and I suspect that some R programmers do too.
By increasing the precedence of unary plus/minus the R designers ensured that 8/-2/2 was parsed like (8/-2)/2 rather than 8/(-2/2).
Number of possible different one line programs
Writing one line programs is a popular activity in some programming languages (e.g., awk and Perl). How many different one line programs is it possible to write?
First we need to get some idea of the maximum number of characters that written on one line. Microsoft Windows XP or later has a maximum command line length of 8191 characters, while Windows 2000 and Windows NT 4.0 have a 2047 limit. POSIX requires that _POSIX2_LINE_MAX have a value of at least 2048.
In 2048 characters it is possible to assign values to and use at least once 100 different variables (e.g., a1=2;a2=2.3;....; print a1+a2*a3...). To get a lower bound lets consider the number of different expressions it is possible to write. How many functionally different expressions containing 100 binary operators are there?
If a language has, say, eight binary operators (e.g., +, -, *, /, %, &, |, ^), then it is possible to write  visually different expressions containing 100 binary operators. Some of these expressions will be mathematically equivalent (adopting the convention of leaving out the operands), e.g.,
visually different expressions containing 100 binary operators. Some of these expressions will be mathematically equivalent (adopting the convention of leaving out the operands), e.g., + * can also be written as * + (the appropriate operands will also have the be switched around).
If we just consider expressions created using the commutative operators (i.e., +, *, &, |, ^), then with these five operators it is possible to write 1170671511684728695563295535920396 mathematically different expressions containing 100 operators (assuming the common case that the five operators have different precedence levels, which means the different expressions have a one to one mapping to a rooted tree of height five); this  is a lot smaller than
is a lot smaller than  .
.
Had the approximately  computers/smart phones in the world generated expressions at the rate of
computers/smart phones in the world generated expressions at the rate of  per second since the start of the Universe,
per second since the start of the Universe,  seconds ago, then the
seconds ago, then the  created so far would be almost half of the total possible.
created so far would be almost half of the total possible.
Once we start including the non-commutative operators such a minus and divide the number of possible combinations really starts to climb and the calculation of the totals is real complicated. Since the Universe is not yet half way through the commutative operators I will leave working this total out for another day.
Update (later in the day)
To get some idea of the huge jump in number of functionally different expressions that occurs when operator ordering is significant, with just the three operators -, / and % is is possible to create  mathematically different expressions. This is a factor of
mathematically different expressions. This is a factor of  greater than generated by the five operators considered above.
greater than generated by the five operators considered above.
If we consider expressions containing just one instance of the five commutative operators then the number of expressions jumps by another two orders of magnitude to  . This count will continue to increase for a while as more commutative operators are added and then start to decline; I have not yet worked things through to find the maxima.
. This count will continue to increase for a while as more commutative operators are added and then start to decline; I have not yet worked things through to find the maxima.
Update (April 2012).
Sequence A140606 in the On-Line Encyclopedia of Integer Sequences lists the number of inequivalent expressions involving n operands; whose first few values are: 1, 6, 68, 1170, 27142, 793002, 27914126, 1150212810, 54326011414, 2894532443154, 171800282010062, 11243812043430330, 804596872359480358, 62506696942427106498, 5239819196582605428254, 471480120474696200252970, 45328694990444455796547766, 4637556923393331549190920306
Birth month for compiler writers
Today is my birthday and an event from a long ago project springs to mind. All four of us from the UK arm of the team were born in February, one person on the same day as me (Happy Birthday Mick, where ever you are). This clustering of birth months led us to the obvious conclusion that the best compiler writers are born in February. Over the years I have retold this story to other compiler writers and found out their birth month. Now I will try and be a bit more scientific and have set up a survey (see below).
What counts as a compiler and what does somebody have to do to be considered a compiler writer (lets stay away from the issue of quality)? I would include software that performs computer language translation to another language (i.e., not just intermediate code or assembler) and static analysis of source provided it involved a lot of semantics (i.e., not working on the GUI that presents the data). I would exclude writing test cases, documentation, project management and maintenance (i.e., only fixing faults and dealing with customer queries).
I would classify a compiler writer as somebody who spent a substantial amount of their time working almost exclusively on writing a compiler. How substantial? Well, I think it ought o be possible to do something useful in about 4 months (I thought about saying 6 months, but decided to be generous.
Please take part, even if you do not consider yourself to be a compiler writer. A control group is always useful (perhaps readers of this blog have a preferred birth month)
I will make the numbers available and discuss them in a future article (probably in March).
[SURVEYS 1]
If anybody else is interested in running a survey, the surveys WordPress plugin allows more than one question to be specified and worked better than the other popular plugins for me (there is one bug that needs to be fixed: show_survey.php, line 51 should be:
$email_body = t("Hi,\nThere is a new result for the survey at %s...\n", $_SERVER['REQUEST_URI']); ).
February 2012 news in the programming language standard’s world
Yesterday I was at the British Standards Institute for a meeting of the programming languages committee. Some highlights and commentary:
- The first Technical Corrigendum (bug fixes, 47 of them) for Fortran 2008 was approved.
- The Lisp Standard working group was shutdown, through long standing lack of people interested in taking part; this happened at the last SC22 meeting, the UK does not have such sole authority.
- WG14 (C Standard) has requested permission to start a new work item to create a new annex to the standard containing a Secure Coding Standard. Isn’t this the area of expertise of WG23 (Language vulnerabilities)? Well, yes; but when the US Department of Homeland Security is throwing money at cyber security increasing the number of standards’ groups working on the topic creates more billable hours for consultants.
- WG21 (C++ Standard) had 73 people at their five day meeting last week (ok, it was in Hawaii). Having just published a 1,300+ page Standard which no compiler yet comes close to implementing they are going full steam ahead creating new features for a revised standard they aim to publish in 2017. Does the “Hear about the upcoming features in C++” blogging/speaker circuit/consulting gravy train have that much life left in it? We will see.
The BSI building has new lifts (elevators in the US). To recap, lifts used to work by pressing a button to indicate a desire to change floors, a lift would arrive, once inside one or more people needed press buttons specifying destination floor(s). Now the destination floor has to be specified in advance, a lift arrives and by the time you have figured out there are no buttons to press on the inside of the lift the doors open at the desired floor. What programming language most closely mimics this new behavior?
Mimicking most languages of the last twenty years the ground floor is zero (I could not find any way to enter a G). This rules out a few languages, such as Fortran and R.
A lift might be thought of as a function that can be called to change floors. The floor has to be specified in advance and cannot be changed once in the lift, partial specialization of functions and also the lambda calculus springs to mind.
In a language I just invented:
// The lift specified a maximum of 8 people lift = function(p_1, p_2="", p_3="", p_4="", p_5="", p_6="", p_7="", p_8="") {...} // Meeting was on the fifth floor first_passenger_5th_floor = function lift(5); second_passenger_4th_floor = function first_passenger_fifth_floor(4); |
the body of the function second_passenger_4th_floor is a copy of the body of lift with all the instances of p_1 and p_2 replaced by the 5 and 4 respectively.
Few languages have this kind of functionality. The one that most obviously springs to mind is Lisp (partial specialization of function templates in C++ does not count because they are templates that are still in need of an instantiation). So the ghost of the Lisp working group lives on at BSI in their lifts.
O Cobol, Cobol! wherefore art thou Cobol?
Programming language popularity has been in the news again and as always Cobol is nowhere to be seen in the rankings. Even back in the day, when people in the know generally considered Cobol to be the most widely used language it often failed to appear, or appeared very low down, in language rankings. I think Cobol’s unrepresentative rankings occur because users of Cobol are assumed to hang out in the same places as users of other programming languages. The letters bo in the name is the clue, business oriented people are not usually interested in technical stuff and tend not to read the magazines (and these days web sites) that users of the other popular languages read.
Cobol is very business domain specific and does not contain functionality that makes it a reasonable choice for writing applications in other domains (it is possible to write a compiler in Cobol, for instance the Micro Focus compiler is written in Cobol). It has very sophisticated languages constructs for handling data having the most convoluted formats imaginable, essential in the business world which has to process data whose format has evolved over the years into a tangled mess (developers have to deal with spaghetti code, business has to deal with spaghetti data formats). Cobol’s control flow and code structuring facilities are primitive (all variables are global and the perform statement is very similar to the gosub statement found in Basic’s that are line number based) because business data processing tends to be relatively simple and programs to handle them are generally small (the large Cobol programs of legend are invariably made up of lots of small programs run in series with complicated data format dependencies between them).
I started to realise just how different Cobol is when working on my first Cobol code generator (yes it was written in Cobol). If a processor has lots of registers it is usually worthwhile to dedicate one to holding the value zero (of the 32 registers supported by most RISC processors, often only 31 can hold different values, one is dedicated to returning zero when read from and ignores any value written to it), in the case of Cobol it is considered worthwhile to dedicate a register to hold 0x20202020 (four space characters) rather than zero.
Is Cobol still the most widely used language today? No, I don’t think so. Business people love spreadsheets which means developers have switched to writing pre/post data format processing code, previously in Cobol, in Visual Basic (to convert input data into a form accepted by the spreadsheet and then print the results of the spreadsheet calculations in a presentable format); this Visual Basic source can often have a Cobol-like feel to it. This spreadsheet usage also resulted in the comma separated list becoming a widely used format for data representation, eroding Cobol’s unique selling point of sophisticated input/output data format processing.
What does language popularity mean? Does using a language you don’t like count towards it being popular? There are several languages I like and very rarely get to use, does this mean I don’t get to contribute to their popularity?
In these tough financial times the number of job adverts requiring knowledge of a specified language is probably of more interest than number of posts to web sites. One job search site lists 3,032 Cobol jobs and counting job ad hits for the top languages listed in a recent popularity poll puts Cobol at the bottom end of the cluster of highest ranked languages.
On mainframes I think Cobol is likely to still be No. 1; it is probably impossible to replace the dominant language in a niche market.
Correlation between risk attitude and willingness to refer back
What is the connection between a software developer’s risk attitude and the faults they insert in code they write or fail to detect in code they review? This is a very complicated question and in an experiment performed at the 2011 ACCU conference I investigated one particular instance; the connection between risk attitude and recall of previously seen information.
The experiment consisted of a series of problems having the same format (the identifiers used varied between problems). Each problem involved remembering information on four assignment statements of the form:
p = 6 ; b = 4 ; r = 9 ; k = 8 ; |
performing some other unrelated task for a short time (hopefully long enough for them to forget some of the information they had previously seen) and then having to recognize the variables they had previously seen within a list containing five identifiers and recall the numeric value assigned to each variable.
When reading code developers have the option of referring back to previously read code and this option was provided to subject. Next to each identifier listed in the recall part of the problem was space to write the numeric value previously seen and a “would refer back” box. Subjects were told to tick the “would refer back” box if, in real life” they would refer back to the previously seen assignment statements rather than rely on their memory.
As originally conceived this experimental format is investigating the impact of human short term memory on recall of previously seen code. Every time I ran this kind of experiment there was a small number of subjects who gave a much higher percentage of “would refer back” answers than the other subjects. One explanation was that these subjects had a smaller short term memory capacity than other subjects (STM capacity does vary between people), another explanation is that these subjects are much more risk averse than the other subjects.
The 2011 ACCU experiment was designed to test the hypothesis that there was a correlation between a subject’s risk attitude and the percentage of “would refer back” answers they gave. The Domain-Specific Risk-Taking (DOSPERT) questionnaire was used to measure subject’s risk attitude. This questionnaire and the experimental findings behind it have been published and are freely available for others to use. DOSPERT measures risk attitude in six domains: social, recreation, gambling, investing health and ethical.
The following scatter plot shows each (of 30) subject’s risk attitude in the six domains (x-axis) plotted against percentage of “would refer back” answers (y-axis).
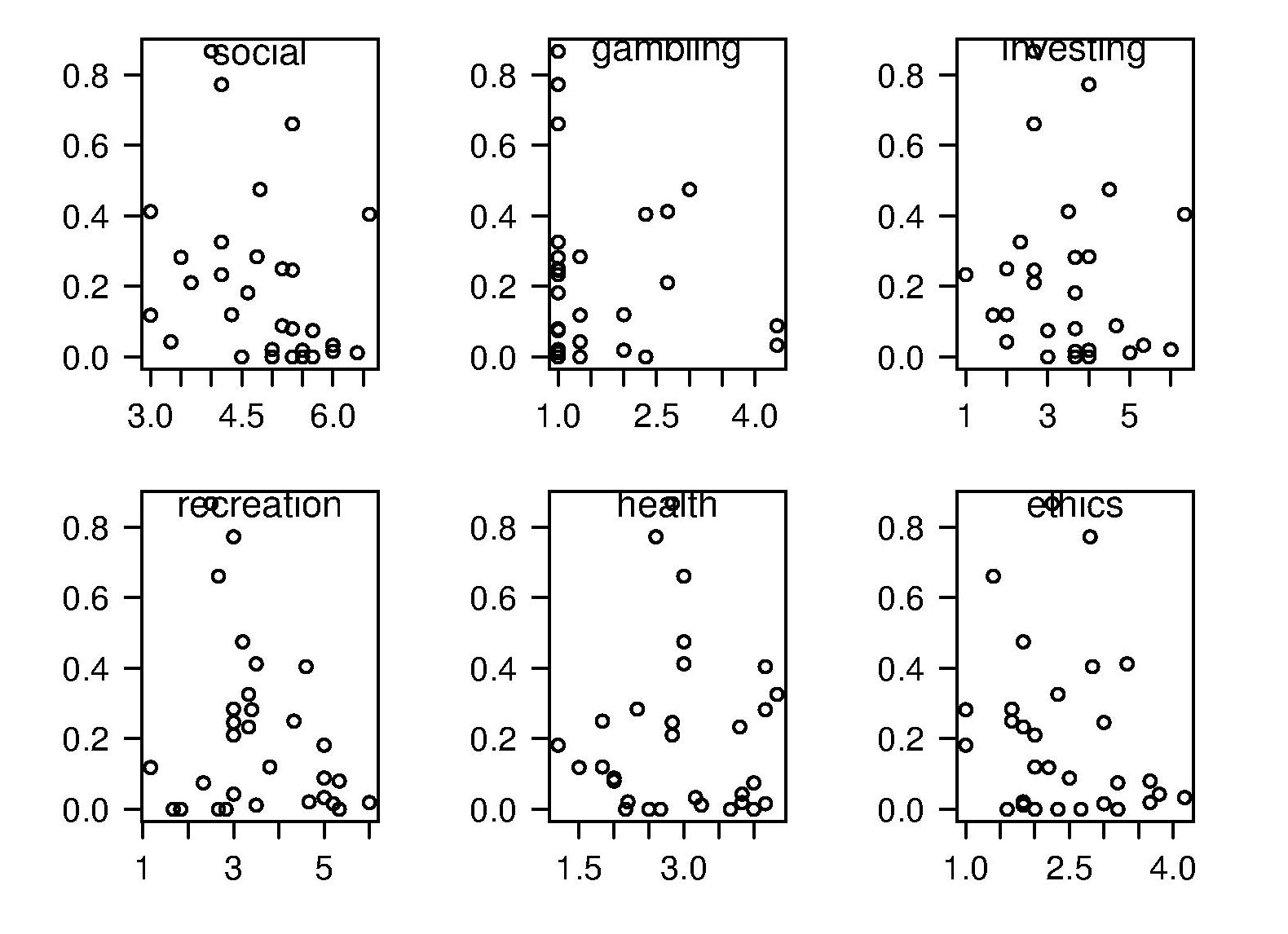
A Spearman rank correlation test confirms what is visibly apparent, there is no correlation between the two quantities. Scatter plots using percentage of correct answers and total number of questions answers show a similar lack of correlation.
The results suggest that risk attitude (at least as measured by DOSPERT) is not a measurable factor in subject recall performance. Perhaps the subjects that originally caught my attention (there were three in 2011) really do have a smaller STM capacity compared to other subjects. The organization of the experiment (one hour during a one lunchtime of the conference) does not allow for a more extensive testing of subject cognitive characteristics.
Relative spacing of operands affects perception of operator precedence
What I found most intriguing about Google Code Search (shutdown Nov 2011) was how quickly searches involving regular expressions returned matches. A few days ago Russ Cox, the implementor of Code Search not only explained how it worked but also released the source and some precompiled binaries. Google’s database of source code did not include the source of R, so I decided to install CodeSearch on my local machine and run some of my previous searches against the latest (v2.14.1) R source.
In 2007 I ran an experiment that showed developers made use of variable names when making binary operator precedence decisions. At about the same time two cognitive psychologists, David Landy and Robert Goldstone, were investigating the impact of spacing on operator precedence decisions (they found that readers showed a tendency to pair together the operands that were visibly closer to each other, e.g., a with b in a+b * c rather than b with c).
As somebody very interested in finding faults in code the psychologists research findings on spacing immediately suggested to me the possibility that ‘incorrectly’ spaced expressions were a sign of failure to write code that had the intended behavior. Feeding some rather complicated regular expressions into Google’s CodeSearch threw up a number of ‘incorrectly’ spaced expressions. However, this finding went no further than an interesting email exchange with Landy and Goldstone.
Time to find out whether there are any ‘incorrectly’ spaced expressions in the R source. cindex (the tool that builds the database used by csearch) took 3 seconds on a not very fast machine to process all of the R source (56M byte) and build the search database (10M byte; the Linux database is a factor of 5.5 smaller than the sources).
The search:
csearch "w(+|-)w +(*|/) +w" |
returned a few interesting matches:
... modules/internet/nanohttp.c: used += tv_save.tv_sec + 1e-6 * tv_save.tv_usec; modules/lapack/dlapack0.f: $ ( T*( ONE+SQRT( ONE+S / T ) ) ) ) modules/lapack/dlapack2.f: S = Z( 3 )*( Z( 2 ) / ( T*( ONE+SQRT( ONE+S / T ) ) ) ) modules/lapack/dlapack4.f: $ ( T*( ONE+SQRT( ONE+S / T ) ) ) ) |
There were around 15 matches of code like 1e-6 * var (because the pattern w is for alphanumeric sequences and that is not a superset of the syntax of floating-point literals).
The subexpression ONE+S / T is just the sort of thing I was looking for. The three instances all involved code that processed tridiagonal matrices in various special cases. Google search combined with my knowledge of numerical analysis was not up to the task of figuring out whether the intended usage was (ONE+S)/T or ONE+(S/T).
Searches based on various other combination of operator pairs failed to match anything that looked suspicious.
There was an order of magnitude performance difference for csearch vs. grep -R -e (real 0m0.167s vs. real 0m2.208s). A very worthwhile improvement when searching much larger code bases with more complicated patterns.
Recent Comments