How to avoid being a victim of Brooks’ law
The oft cited book The Mythical Man Month contains a statement that has become known as Brooks’ Law: “Adding manpower to a late software project makes it later”.
When people join a project they need to learn project specific information, this is information that can only be obtained from people already working on the project. Training up new staff (e.g., developers, documentation writers) reduces the amount of effort being directly invested in building the system; it is an investment in people whose benefit is the post-training productivity of those people adding their effort to the project.
Let’s assume that a newbie diverts from the project they are joining an amount of effort units of time,  , in training without contributing anything, and that this training/investment lasts for
, in training without contributing anything, and that this training/investment lasts for  units of time after which the trained person contributes an average of
units of time after which the trained person contributes an average of  of effort per unit of time until the project deadline. This investment in a newbie will cause the project to be delayed unless the following inequality holds:
of effort per unit of time until the project deadline. This investment in a newbie will cause the project to be delayed unless the following inequality holds:
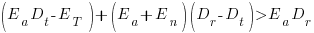
where  is the average daily project effort available before a newbie joins and
is the average daily project effort available before a newbie joins and  is the number of units of time between the start of training and the delivery date/time.
is the number of units of time between the start of training and the delivery date/time.
This simplifies to:
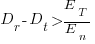
an equation that makes the obvious point that as the deadline approaches the amount of time and effort spent training newbies needs to decrease if a worthwhile payback is to be achieved in the available time.
The quantity  is the amount of time remaining after the newbie finishes training (in practice this is rarely a well defined point in time, but let’s keep things simple) and is the only easily obtained information in the equation.
is the amount of time remaining after the newbie finishes training (in practice this is rarely a well defined point in time, but let’s keep things simple) and is the only easily obtained information in the equation.
The effort contribution of the newbie, , could be approximated using information on the effort contribution of other people doing a similar job on the project. At least it could be if data was available on what their effort contribution was, and we overlooked the possible 5:1 difference in performance found between software developers. In practice a newbie’s effort contribution ramps up from zero, perhaps even starting during the training period, to a relatively constant long term daily average. How long does it take for to reach the long term average? I have no idea.
How much effort, , goes into training a newbie? A very important factor will obviously be their existing level of expertise with the application domain, tools being used, coding skills, etc (pretty much everything was new, back in the day, for the project analysed by Brooks, so was probably very high). There is also the somewhat nebulous but very important ability, or lack of, to pick things up quickly.
Could data on be obtained by recording every encounter the newbie has with existing project members? This would certainly enable information on first order time interactions to be obtained, but it would not tell us anything about the knock on effects caused by the work of an existing project member being delayed because they were investing in the newbie.
If many people are being added to a project at the same time it is easy to imagine it grinding to a halt because of all the minor congestion that occurs within the network of dependencies that project progress is waiting on.
I have not been able to locate any applicable data relating to training on software development projects, but then this area is at the edge of what I know about. Pointers to data most welcome.
Compiler writing is for hedgehogs
It is said that a fox knows many thing, but the hedgehog knows one big thing. An insightful article by Venkatesh Rao (Venkat) showed how foxes and hedgehogs uniquely map to the two contrasting philosophical points of view of those having weak views that are strongly held (a fox) and those having strong views that are weakly held (a hedgehog).
Venkat observes that the many things the fox knows are acquired from multiple sources and that this disparate collection of knowledge is not connected together by any consistent set of core principles; the one big thing that a hedgehog knows consists of knowledge that is connected by a small set of consistent core principles.
An average developer’s knowledge of a language is very fox-like, i.e., it is culled from many particular instances with each snippet of knowledge being accompanied by the experience around which it was obtained. Back in the day, the ‘advanced’ courses I used to give to developers who had 2-3 years experience were really designed to show how the components of a language fitted together, i.e., to provide a structure to what they already knew about the language. Switching developers from an approach based on their experience of particular instances for each language feature to a rule based approach was often hard work, some developers seem to be naturally driven by itemized personal experiences.
Of necessity a compiler writer spends a lot of time studying one programming language (I’m excluding those who invent their own language as they write the compiler for it) and/or hardware cpu. This extended period of study, assuming the developer has sufficient cognitive capacity (the drop out rate is high), creates a heavily interconnected knowledge of the language in the compiler writer’s head, i.e., they understand one thing very deeply and have strong views created by the core rules they have created to organize this knowledge. These views are weakly held because experience shows that every now and again a major insight is achieved that changes the developer’s perspective completely.
This fox-like characteristic of developer language knowledge goes a long way towards explaining why religious language wars go on for so long and can be so ferocious. A fox is arguing from personal experience that is not based on a set of core principles; every point has to be argued because there is nothing connecting them, undermining one idea does not affect the status of the beliefs about anything else.
I am not arguing that being a fox is a good or a bad thing, and I am certainly not arguing that everybody should spend the huge amount of time needed to become a hedgehog (it is not a cost effective use of time). I am simply making an observation about a state of affairs, and one that is likely to continue because there are no incentives in trying to change things.
I think being a major contributor in the creation of any large and complex software system requires that somebody be or become a hedgehog.
I think that many software developers are foxes; of course to people looking in developers appear to be hedgehogs in the world of software.
Agile and the sound of one hand clapping
There is an interesting report out on Surrey Police’s SIREN project (Surrey Integrated Reporting Enterprise Network; a crime record storage and a data analytics software system).
The system was to be produced using an Agile methodology. The Notes in Appendix 1 highlight that one party in the development was not using Agile: “Modules are delivered in accordance with schedule and agreed Agile development methodology. However, no modules undergo formal acceptance (nether now or at any future point in the project).”
If you are the supplier on a £3.3 million software development project (the total project was £14.86 million) and the customer is not doing the work that Agile assumes will happen (e.g., use the software, provide feedback, etc) what do you do? One thing you are unlikely to do is to stop work. But what do you do?
What happened on the customer side? I imagine that those involved in software procurement at the Police did the usual thing of nodding as the buzz words were thrown at them, not really paying attention and not noticing that Agile requires them to do a lot of work throughout the development process. If I was working for Surrey Police and somebody sent me a load of software to install and beta test, without giving me the funding to do it, I would just ignore what I had been sent.
Paragraph 31 lists the grisly details of what happens when a customer has no interest in signing up to the Agile way of doing things. Or to be exact, (paragraph 91) “The Force’s corporate change and project management structures were based on the PRINCE 2 methodology.”
Paragraph 81 says something surprising “The Agile development process did not have all the necessary checks and balances to control a growth in scope as the products progressed.” Presumably this is referring to a consequence of using Agile on a fixed price contract.
Would the Police have gone down an Agile route if they had understood the work needed from them? I don’t have any figures for the customer costs of using Agile, but I suspect that initial costs will be a lot higher than a deliver everything in one installment at the end approach (the benefits being a system tuned to requirements). Also finding customer champions with the time and expertise to make new systems a success is always hard.
Socrates 2014 unconference in the UK
I was at the Socrates unconference at the end of last week. An unconference is a conference with no prearranged speakers, the attendees turn up and some of them volunteer to talk about a topic of their choosing on the day. The talks were structured as half a dozen parallel sessions of an hour each in rooms dotted around two different buildings.
I had previously been to half a dozen or so of the London Software Craftsmanship meetups (there is a large overlap in the organizers of the two groups) and thought I had some understanding of how the community went about building software engineering knowledge. At the end of the first day this understanding underwent a major revamp (the arts and craft movement struck me as something of a parallel).
Based on the experience of one meeting I would say that the Socrates’ community approach to achieving the goals laid out in the Manifesto for Software Craftsmanship (as exemplified by those present at unconference) is primarily a social one based on personal experiences and shared experiences communicated through meetings and pair programming (yes, pair programming).
A great deal of pair programming was constantly going on and a person’s recent experience of pairing with somebody-or-other was a perfectly natural topic to bring up in casual conversation. I have never seen this kind of widespread community practice of interaction on a detailed before; I think it is great and I hope it spreads.
I volunteered to talk Friday morning about “When is it worth investing in reducing maintenance costs?” (I now have more data than used in my blog post on the topic). The talk did not go well in the sense that while people appeared to understood the analysis they did not seem to understand why anybody would want to use the decision making approach proposed. I got the same impression from people who asked me about the topic during food breaks (I had given a lightening talk Thursday evening with about half the attendees present).
The argument I made was that improving software is an investment intended to reduce future maintenance activities; like all investments the person making it wants receive a worthwhile return on the risk they are taking. The talk derived a requirement on the investment/benefit ratio needed for a code improvement activity to at least break even.
Now I am not always the world’s greatest communicator, so peoples’ lack of understanding may have been down to poor presentation on my part. But, in the evening, thinking about everything I had seen during the day I realised that my proposal for driving code improvement decisions using an economic model ran counter to the spirit of software craftsmanship as practiced by those present. This is not to say that the software craftsman are anti-economics, but that they want to be proud of their work and require that it meet certain personal and community standards, which may mean being less than economically efficient in some cases. At your average developer conference I would have expected zero interest, but here I had made the mistake of underestimating the strong craft influence and the socially derived approach (rather than trying to use experimental evidence) to finding solutions to software engineering problems.
There were a handful of people at the meeting interested in working towards a scientific approach to obtaining solutions to software engineering problems, i.e., using evidence derived from experiments. At one of the sessions a small group of us talked about how the software craftsman community might help researchers interested in experimental research (perhaps by helping to find professional subjects or by being willing to spend time discussing industry problems). I made my usual appeal for data that could be made public.
I suspect that many software craftsman would be interested in monitoring their own performance and that it would be worthwhile providing pointers to tools and techniques that might be used. Watch this space for progress.
The most interesting session I went to was by Steve Hayes who talked about his experience of starting and running a transparent company (this involves making information that companies usually keep confidential, such as employee, public). I had read about such companies before but this was my first encounter with somebody who had done it in practice.
The event appeared to run itself very smoothly, probably as much due to the invisible hard work of the organizers as much as the more visible attendee work. I would recommend the host venue, Farncombe conference centre, to anyone wanting to run a conference with lots of breakout rooms and social spaces. The food was high quality and artistically presented, demanding that both desserts on the menu be consumed.
Anybody who is in a rush to experience a Socrates unconference can visit Germany in August (a contingent from the UK are already booked).
Source code will soon need to be radiation hardened
I think I have discovered a new kind of program testing that may soon need to be performed by anybody wanting to create ultra-reliable software.
A previous post discussed the compiler related work being done to reduce the probability that a random bit-flip in the memory used by an executing program will result in a change in behavior. At the moment 4G of ram is expected to experience 1 bit-flip every 33 hours due to cosmic rays and the rate of occurrence is likely to increase.
Random corrupts on communications links are protected by various kinds of CRC checks. But these checks don’t catch every corruption, some get through.
Research by Artem Dinaburg looked for, and found, occurrences of bit-flips in domain names appearing within HTTP requests, e.g., a page from the domain ikamai.net being requested rather than from akamai.net. A subsequent analysis of DNS queries to VERISIGN’S name servers found “… that bit-level errors in the network are relatively rare and occur at an expected rate.” (the  bit error rate was thought to occur inside routers and switches).
bit error rate was thought to occur inside routers and switches).
Javascript is the web scripting language supported by all the major web browsers and the source code of JavaScript programs is transmitted, along with the HTML, for requested web pages. The amount of JavaScript source can dwarf the amount of HTML in a web page; measurements from four years ago show users of Facebook, Google maps and gmail receiving 2M bytes of Javascript source when visiting those sites.
If all the checksums involved in TCP/IP transmission are enabled the theoretical error rate is 1 in  bits. Which for 1 billion users visiting Facebook on average once per day and downloading 2M of Javascript per visit is an expected bit flip rate of once every 5 days somewhere in the world; not really something to worry about.
bits. Which for 1 billion users visiting Facebook on average once per day and downloading 2M of Javascript per visit is an expected bit flip rate of once every 5 days somewhere in the world; not really something to worry about.
There is plenty of evidence that the actual error rate is much higher (because, for instance, some checksums are not always enabled; see papers linked to above). How much worse does the error rate have to get before developers need to start checking that a single bit-flip to the source of their Javascript program does not result in something nasty happening?
What we really need is a way of automatically radiation hardening source code.
Oh, I did not know that [about R]
I recently saw a post about something called ValidR and as somebody with a long standing professional interest in language validation immediately read the article and referenced links. I was disappointed to find that what was being validated was the installation, not the behavior of the implementation. In the context of what I understand ValidR’s target market to be, drug testing, obtaining reproducible results is very important and so it is necessary to know exact what software has been installed (e.g., packages and their versions).
Implementation validation involves checking that the implementation of a language adheres to the requirements specified in the appropriate language standard. While International standards exist for many of the widely used languages, some have standard’s developed through other means and some have no recognized specification at all (e.g., PHP, Perl and R).
Not having a recognized specification is a problem for PHP because there are multiple implementations in common use. Perl and R both have a dominant implementation, which means the definition of the language is accepted as being whatever that implementation does.
Now, anybody who claims that having an open source implementation is as good as having a specification written in English (i.e., people can read the code to discover the behavior) clearly have not done much, if any, reading of language implementations. Over the years I have worked with the source of a fare few language implementations and my general experience is that the fastest and most reliable way of finding out what an implementation does is to write test case, only reading the source when test cases cannot be found that answer the questions.
Does it matter that there is no complete English specification of R (the current specification is very much a work in progress, with lots of progress remaining)?
Who reads computer language specifications (apart from language wonks like me)? Creators of implementations is the most obvious answer. But an R implementation already exists, why should the R team spend time making it easier to create alternative implementations? Actually I see the main customers of an R language specification being the R-core team.
An example of the benefits to the owner of source code in having a specification is provided by the EU/Microsoft competition court case. I was an adviser to the Monitoring Trustee appointed by the Commission to oversee the documentation of the specification of these protocols (no previous documentation existed). A frequently heard comment from the senior Microsoft developers we dealt with, on reading their own new specifications, was “Oh, I did not know that”.
A written specification is much more compact than source code or test cases and is (or should be) organized in a way that helps readers understand what is being said (this is often a stated aim for source code but is rare achieved). There are probably lots of behaviors that the R team are unaware of which, if they get to find out about them, might be interested in ‘fixing’ or at least discussing whether it is a desirable behavior. Or perhaps the R team’s strategy is to make life difficult for competing implementations.
APIs can, for the time being, be copyrighted
There was an interesting turn of events in the Oracle vs. Google Java API lawsuit last friday. The original trial judge had ruled that an API are not copyrightable; last week the US federal Court of appeals reversed this decision, APIs are copyrightable. This legal battle is not over and the ruling can flip and flop its way up to the US supreme court, and not being a lawyer I’m happy to leave the legal discussion to others. Let’s assume that Oracle eventually win their Java API copyright claim, what does that mean for computer language usage and software developers?
If Oracle’s API copyright claim is upheld then they are potentially in line for a huge payout (Google might get to wiggle out of paying much via a fair use justification). I’m sure that some people will claim that this ‘win’ will kill off Java, even if this is true (I don’t think it is), what do the suits care? Give me a billion dollars and I will happily support the removal of any computer language from planet Earth.
In the early days of Android Google needed Java compatibility more than Java needed anything to do with Android. Now Android has such a commanding market share Google does not need to worry so much about Java compatibility. If Oracle had any interest in the future of Java they would be worried that this court case could result in Google switching the Android ecosystem to using a slightly incompatible Java-like language. In practice this court case is the only real opportunity for Oracle to make serious money from their Java intellectual property and they are not that excited about a steady stream of peanuts from future goings on.
What does Oracle winning the API copyright claim mean for developers?
If Google do launch a Java-like language then Java’s “write once run anywhere” mantra will be less true than it currently is (by avoiding a few traps and not straying too far from the well trodden path Java developers can create programs that are remarkable portable). In its market niche there is no other language that comes close to providing the kind of portability that Java offers, so existing users will be annoyed at having to worry about one more portability issue but are unlikely to jump ship.
The much more interesting question is the impact an Oracle win has on other companies producing products that include an API; they now have something to wave at competitors who have API-alike (I just made that word up) products. Any developer using an API that has its very own copyright discussion thread is likely to become a bit twitchy. The general result will be a cloud of uncertainty over some existing APIs from some providers.
Anybody introducing a new API will have to answer the ‘copyright’ question: “Do you claim copyright on your API?” In practice a very very small percentage of APIs ever get copied/cloned, because most fail or the competition comes up with what they think is a better API.
Would I care if a company claims copyright on its API and says it will sue anybody who copies/clones it? Obviously I have to use that API if it is the only way to get a job done, but what if I had a choice between it and a non-copyrighted API? I don’t think the question of copyright would be an issue for me, but I would be concerned if any company was being overly legalistic; do I really want to deal with a company more interested in legal matters than supporting developers? I think not.
MyFloodPlan: The personalized flood plan App
I took part in the HackTheTownHall flood-relief hackathon at the weekend. Team MyFloodPlan (me, Manoj, Lusine, Anthony and Sanjeet) built an App (try it) that created personalised flood plans; tell us where you live and we tell you number of hours before the flood water reaches you, plus providing a list of recommended actions for that time frame, with the timing of the recommended actions being influenced by personal circumstances such as age (older people likely to take longer to do things than younger people), medical situation and risk aversion. The App has five prespecified users at various locations in the worst hit flooding areas around west London in February 2014. UK Government recommendations are basically to move things to higher ground (e.g., upstairs) and just as the water arrives at your door turn off the gas and electric.
The App used the Ordnance Survey Terrain 50 data (height above sea level of 50 meter squares covering the whole UK and accurate to 0.01 0.1 meters) to find the difference in height between the user’s location and the last reported local flood height (we faked this number), multiplied this by how fast the flood water is rising (we picked 100 10 cm per hour) to find out how many minutes it would take for the flood to reach the user’s location. In practice it would be easy to get the current flood height, the user could simply walk to the current edge of the flood and tell the App where it was; data on rate of height increase/decrease could come from the Environment agency flood warning site.
The Ordnance survey has height data at 5 meter square resolution and supplied a sample for an area near Bristol. The accuracy of GPS is nowhere near good enough for obtaining height data. Altitude data for most of the world is available thanks to the Shuttle Radar Topography Mission; the grid resolution is 30 meters in the US and 90 meters outside the US.
I thought of creating a 2-D equation that interpolated between all known points (using say, cubic splines), this would smooth out height discontinuities and probably improve the estimates for most locations. But given the large unknowns in rate of change of flood water height, interpolation seemed like over-kill (given how smooth the data is over much of the UK this approach might be away of reducing data storage/access).
The big unknown in all of this is modeling changes in flood water level. In February there were announcements that gave maximum levels. The ideal situation is for the Environment agency to provide a predicted flood water level time line API. They probably have the predictions, but given the degree of uncertainties present in all models I would understand any reluctance in making this information available in real time.
On the ground monitoring the progress of a flood would only take a few people on bikes to cover a whole town, reporting back to a local system that kept everybody updated. Real-time flood level tracking is not a big data problem (prediction and maintaining historical data are) and a handful of people using modest computer resources could easily provide a personalized flood warning service to locals.
Team MyFloodPlan was made up of Team prompt Parking (minus Bob), from a previous hackathon, plus two other people, and these provided a useful reminder of the mindset needed for a hackathon. Producing a working App in 24 hours requires keeping things simple and doing what needs to be done; sometimes outrageous simplifications have to be made and the most awful coding solutions have to be lived with. Our two new members (a business consultant and very clever technical guy) were into considering all the issues and how they connected, and looking to keep all potential customers happy; all good stuff to do when there is plenty of time and resources available, but fatal mistakes in a short hackathon. We spent all day going in circles around the original idea (team Prompt Parking are very laid back and prone to gossiping about tech with anybody who happens to wonder by), when the two left for the night the circling died down and within a few hours we had the basic core of the App coded and working.
The oversimplifications made by team PromptParking, along with our willingness to ignore ‘low volume’ customers left our two newbies exasperated and baffled. However, the aim is to produce the best minimum viable product, not an impressive report covering all the issues
How can flood data be monetized using an App? Floods are too rare for the MyFloodPlan App to provide a regular income. Perhaps during a flood it could cheer people up by displaying adds for holidays in sunny destinations, provide suggestions for new furniture, decorating ideas, etc and if the flood had not yet reached them the best place to sell their home.
The best money making App I could think of was one that provides flooding information to potential home buyers. The DoesThisLocationFlood App would show pictures of previous floods in the area (picture gathering would be so much easier if Twitter did not remove location information from posted pictures), along with height above local water features and distance from them. It would be great to tie in with online home purchase sites, but these make money from the seller and so are unlikely to see any added value in the DoesThisLocationFlood App.
The MyFloodPlan App came second, beaten by an App that allowed users to report and see events in a flood affected area (and made great use of text messaging). Our App was not very interactive, i.e., flood arrives in x hours, do these things. We should have been more adventurous; having been gone down the route planning rabbit hole before I shied away from figuring out which road were flooded and suggesting alternative routes (the route planners in OpenStreetMap do seem to be improving).
Thanks to Milverton for organizing the event and the knowledgeable and helpful people from the Environment agency and Ordnance survey.
A request for future events: A method of turning off the lights so people don’t have to sleep under the tables to stop the motion detectors turning the lights on.
C++ vs. Ada: Which language is more strongly typed?
Programming languages are sometimes categorized as being either weakly or strongly typed. I’m not going to join the often rabid debates over which category a particular language belongs to, but rather discuss the relative type strengths of two languages, C++ and Ada, to see if it is possible to claim that one of them is more strongly typed than the other.
Most programming languages support variables having more than one type (e.g., integer and float are two very common types) and have rules specifying which combinations of differently typed values/variables are permitted to occur in a given context, e.g., C++ allows a value of type int to be assigned to a variable of type float (an implicit conversion is performed), but Ada not perform this implicit conversion and the integer value has to be explicit converted to float before it can be assigned (otherwise a compile time error will be generated).
The more implicit type conversions a language supports the weaker its type system is said to be.
C++ supports more implicit conversions than Ada (others include boolean/int and char/int) and loose type strength points because of this (there is plenty of scope for debate about whether some implicit conversions are more evil than others, but cost/benefit debates are harder to come by).
While C++/Ada differ in their support for implicit conversions they are pretty equal in their support for explicit conversions (e.g., in Ada the code float(23) would convert the integer 23 to a float type). In some cases Ada requires that various hoops be jumped through to make the conversion happen (representation clauses are a great topic to bring up when being lectured about how type safe Ada is, a bit like telling somebody being snobbish that they go to the bathroom like everybody else).
The underlying idea is that the compilation errors generated by these ‘undesirable’ attempted implicit conversions alert the developer to a possible mistake in what they have written. These kinds of messages from the compiler have certainly caught errors in my code, but often the error has been a failure to write the required explicit conversion; every now and again a ‘real’ error is flagged. But I digress, this discussion is about what weak/strong typing is, not about what its costs and benefits might be.
Does Ada have any other feature that increases its type strength with respect to C++?
Both languages allow names to be given to existing types: typedef length_t int; in C++ and subtype length_t is integer; in Ada both define length_t to be a synonym for the integer type, but without resulting in any extra type checks occurring. However, Ada supports a kind of type definition mechanism that does result in extra checks being made by the compiler. In the following code:
subtype length_t is integer; type time_t is integer; a : integer; b : length_t; c : time_t; begin a := b; -- OK a := c; -- Error, type mismatch a := integer(c); -- OK, explicit conversion |
time_t is defined to have a type that is not compatible with integer, even although its underlying representation is the same as the integer type. Mixing variables having types integer and time_t results in a compile time error.
The intended purpose for defining a ‘new’ type and creating variables having that type is to restrict operations on those variables to being with other variables having the same type, e.g., assignment and addition between any variables having type time_t is fine but involving other types results in a compile time error (there are special rules that allow integer literals to general get mixed in). I find that the errors flagged by this kind of checking are mostly very useful.
It is also possible to achieve the same kind of type checking in C++ using template metaprogramming, e.g., the SIunits library. In fact using this technique enables C++ to support a much more general and user friendly range of of ‘strong type’ functionality than is supported by the built-in Ada functionality (it is also possible to use general language functionality in Ada to implement the kind of checking possible in C++, however prior to the 2012 Ada standard the checks occurred at runtime but it now looks like there is a mechanism for doing them at compile time {because it is often possible to switch off runtime checks some people consider them to be weaker than compile time checks})
Fans of subranges (I dearly miss this feature when using C-like languages) can get their fix here.
Is there a rule that extra type strength points are given if a language contains explicit type creation syntax (Ada contains a menagerie of syntax and semantics for doing this kind of stuff), compared to languages that require the use of constructs having many other uses? I don’t see why there should be. The fact that template metaprogramming makes a lot of C++ developers’ head’s hurt means that many will limit themselves to using what others have created, rather than growing project specific libraries; but since when have usability and frequency of use been a major issue in the weak/string type debate?
The score so far is that C++ has lots points to Ada because of its greater support for implicit type conversions, but has held its ground everywhere else.
Can either language pick up any more points?
There is the culture angle. Ada developers have a culture of making use of the type checking functionality provided by the language; this is a skill that has to be learned, you get some type checking for free but the rest has to be designed into the code. C++ developers also have a culture of making use of the type checking functionality provided by the language, i.e., most do not use add-on packages like SIunits.
I am not aware of any studies that have investigated the extent to which developers make use of type checking functionality; pointers to such studies welcome. If there is more ‘strongly typed’ C++ than Ada code out there it is only because there is a lot more C++ code out there.
It is my experience that culture and existing code do color developers’ position on where to draw the line in the weak/strong debate, but don’t effect relative language orderings.
The conclusion is that Ada is more strongly typed than C++, but how much more strongly typed remaines an open question. Both languages require effort from the developer to make full use of the typing functionality that is available.
The Shattered Windows App: How much will an asteroid impact cost you?
I was at the Space Apps Challenge in London yesterday. I was part of a group of people interested in the Asteroid challenges with my subgroup (i.e., me) trying to estimate the financial consequences of an impact of a given size at a given location. These open ended hackathons involve a lot of upfront data collection, which for this problem required engineering/physics knowledge and my fellow asteroid enthusiasts included an undergraduate and four web developers (finding one good one is usually hard and here I was surrounded by them).
I worked out a plan for calculating the financial consequences of an asteroid impact and found out lots of useful stuff, but did not get to write any code. So this is a paper implementation.
The Shattered Windows App deals with the impact of asteroids of the kind recently experienced by the Russians in Chelyabinsk Oblast. Most of the existing published work concentrates on the much larger global impact events, which are great for dramatic TV programs and films but make for a boring App (global catastrophes wiping out whole countries have limited scope for localizations that allow users to understand the consequences in their community).
Recently declassified military satellite data and data from the Infrasound network has shown that asteroid impacts generating kiloton airbursts are surprisingly common ( impacts per annum, where
impacts per annum, where  is energy in kilotons; a megaton event around every 15 years or so).
is energy in kilotons; a megaton event around every 15 years or so).
The energy from an airburst (explosion in the air) generates a shock wave that travels through the atmosphere. The overpressure from this shock wave, if large enough, will smash things, including windows, roofs (the Chelyabinsk event took out a few of these) and complete buildings; people are remarkably resistant to overpressure. I decided to concentrate on windows since these are the most likely to be smashed and flying glass is a huge health hazard.
The Bishopsgate bombing is a good illustration of the impact of a blast on windows, in this case just over 1 ton of equivalent TNT breaking 500 tonnes of glass (£1.4 billion of damage in 2014 money).
The sequence of calculations needed to generate the information that can be fed into a web front end displaying a map of financial cost contours for an event at a given location include:
- Calculate likely asteroid mass and velocity. Asterank presents a stunning amount of information on known asteroids and all the code is available on github.
- Calculate the size of the airburst, in kilotons, generated by the impact of an asteroid having a given mass, velocity and angle of atmosphere entry. The paper Earth Impact Effects Program: A Web-based computer program for calculating the regional environmental consequences of a meteoroid impact on Earth follows the herd in discussing huge global events but contains the needed equations (ignore the stuff about crater size and seismic events).
- Calculate the overpressure at a given distance from the atmospheric airburst. The book The Effects of Nuclear Weapons contains the necessary charts and methods (starting around page 113). The Nuclear Weapons Frequently Asked Questions is also worth reading.
- Calculate the number of windows/area of glass present at a given distance from the airburst. My thinking here is population density data from the last census to estimate the number of dwellings in a given area and housing window data from the English Housing Survey (69% of dwellings have PVC-U double glazed units) to estimate window/glass totals per dwelling. I am currently assuming that commercial windows can be handled by multiplying the residential totals by some small value (this won’t work for large city centers like London). Pointers to commercial building window data welcome.
- Calculate value of smashed windows/glass. Previously cited sources give rough figures for the range of overpressures needed to break windows; more accurate information on overpressure needed to smash particular kinds of windows would be useful. A rough calculation can be made by combining all the above calculated information.
All that is needed now is a fancy web front end that allows users to select a known asteroid, select a location (the location reported by a phone’s gps being the default) and display an easy to digest damage map.
Data for other countries, e.g., the US, could also be added.
Thanks to the hosts who kept us well fed and watered. A note for future events: bigger tables would be good and comfier chairs for those not yet experienced enough to have developed the ninja skills needed to hack sitting for long period on hard plastic chairs.
Update: The folks at B612 have paper plans for a more upmarket App in mind; they want to nudge the asteroid so it misses the Earth. I wonder if they will sell ads on the side of the rocket?
Recent Comments