Double exponential performance hit in C# compiler
Yesterday I was reading a blog post on the performance impact of using duplicated nested types in a C# generic class, such as the following:
class Class<A, B, C, D, E, F> { class Inner : Class<Inner, Inner, Inner, Inner, Inner, Inner> { Inner.Inner inner; } } |
Ah, the joys of exploiting a language specification to create perverse code 🙂
The author, Matt Warren, had benchmarked the C# compiler for increasing numbers of duplicate types; good man. However, the exponential fitted to the data, in the blog post, is obviously not a good fit. I suspected a double exponential might be a better fit and gave it a go (code+data).
Compile-time data points and fitted double-exponential below:
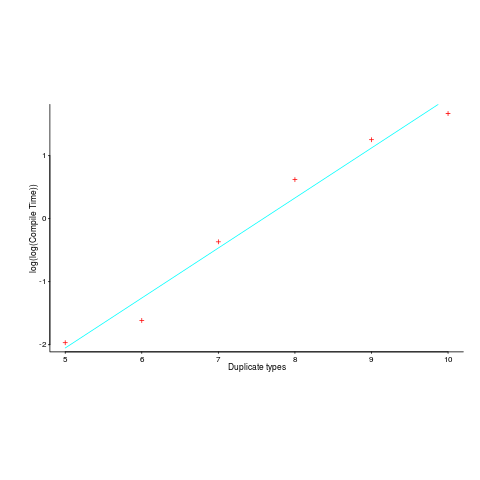
Yes, for compile time the better fit is:  and for binary size:
and for binary size:  , where
, where  ,
,  are some constants and
are some constants and  the number of duplicates.
the number of duplicates.
I had no idea what might cause this pathological compiler performance problem (apart from the pathological code) and did some rummaging around. No luck; I could not find any analysis of generic type implementation that might be used to shine some light on this behavior.
Ideas anybody?
Huge effort data-set for project phases
I am becoming a regular reader of software engineering articles written in Chinese and Japanese; or to be more exact, I am starting to regularly page through pdfs looking at figures and tables of numbers, every now and again cutting-and-pasting sequences of logograms into Google translate.
A few weeks ago I saw the figure below, and almost fell off my chair; it’s from a paper by Yong Wang and Jing Zhang. These plots are based on data that is roughly an order of magnitude larger than the combined total of all the public data currently available on effort break-down by project phase.
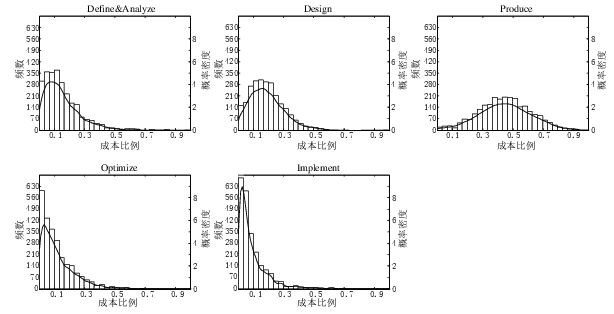
Projects are often broken down into phases, e.g., requirements, design, coding (listed as ‘produce’ above), testing (listed as ‘optimize’), deployment (listed as ‘implement’), and managers are interested in knowing what percentage of a project’s budget is typically spent on each phase.
Projects that are safety-critical tend to have high percentage spends in the requirements and testing phase, while in fast moving markets resources tend to be invested more heavily in coding and deployment.
Research papers on project effort usually use data from earlier papers. The small number of papers that provide their own data might list effort break-down for half-a-dozen projects, a few require readers to take their shoes and socks off to count, a small number go higher (one from the Rome period), but none get into three-digits. I have maybe a few hundred such project phase effort numbers.
I emailed the first author and around a week later had 2,570 project phase effort (man-hours) percentages (his co-author was on marriage leave, which sounded a lot more important than my data request); see plot below (code+data).
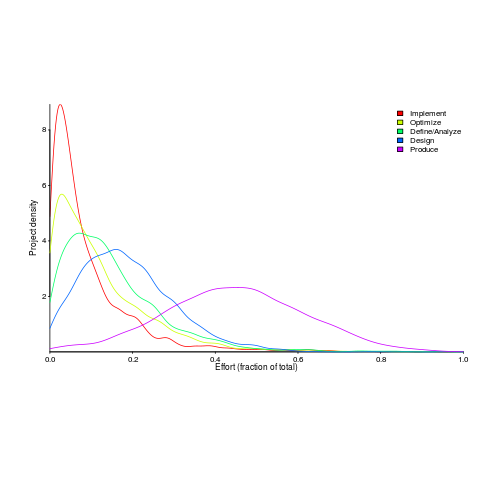
I have tried to fit some of the obvious candidate distributions to each phase, but none of the fits were consistently good across the phases (see code for details).
This project phase data is from small projects, i.e., one person over a few months to ten’ish people over more than a year (a guess based on the total effort seen in other plots in the paper).
A typical problem with samples in software engineering is their small size (apart from bugs data, lots of that is available, at least in uncleaned form). Having a sample of this size means that it should be possible to have a reasonable level of confidence in the results of statistical tests. Now we just need to figure out some interesting questions to ask.
Projects chapter added to “Empirical software engineering using R”
The Projects chapter of my Empirical software engineering book has been added to the draft pdf (download here).
This material turned out to be harder to bring together than I had expected.
Building software projects is a bit like making sausages in that you don’t want to know the details, or in this case those involved are not overly keen to reveal the data.
There are lots of papers on requirements, but remarkably little data (Soo Ling Lim’s work being the main exception).
There are lots of papers on effort prediction, but they tend to rehash the same data and the quality of research is poor (i.e., tweaking equations to get a better fit; no explanation of why the tweaks might have any connection to reality). I had not realised that Norden did all the heavy lifting on what is sometimes called the Putnam model; Putnam was essentially an evangelist. The Parr curve is a better model (sorry, no pdf), but lacked an evangelist.
Accurate estimates are unrealistic: lots of variation between different people and development groups, the client keeps changing the requirements and developer turnover is high.
I did turn up a few interesting data-sets and Rome came to the rescue in places.
I have been promised more data and am optimistic some will arrive.
As always, if you know of any interesting software engineering data, please tell me.
I’m looking to rerun the workshop on analyzing software engineering data. If anybody has a venue in central London, that holds 30 or so people+projector, and is willing to make it available at no charge for a series of free workshops over several Saturdays, please get in touch.
Reliability chapter next.
Is this fitted line believable? A visual answer
The only information contained in the statement that a straight line has been fitted to the data, is that the data contains two or more points; modern tools will find a fit to anything that is thrown at them, without raising a sweat; a quadratic equation requires three or more points and so on.
How believable is an equation that has been fitted to data?
There are various technical ways of answering this question, but as a first pass I prefer a simple visual approach. How believable do the lines in the plots below appear to you (code+data)?
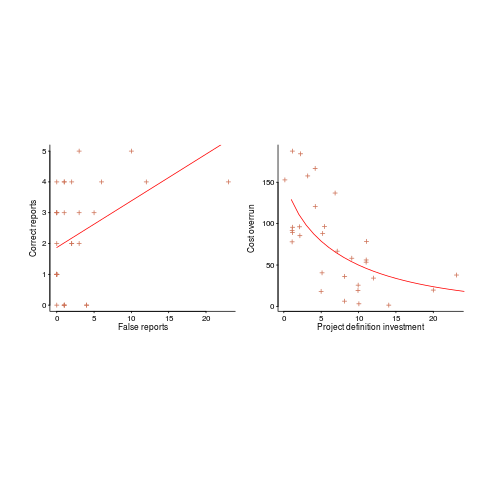
Now I could fire p-values at you, or show you various regression diagnostic plots. Would you be any the wiser? If you were it’s because you know some technical details and switched your brain on to use them. People hate having to switch their brain’s on; a technique that works with the brain switched off is much more practical.
Adding confidence intervals to a plot is one technique (below left uses the default 95% interval) and another is to draw the line of a LOESS fit (below right uses R’s loess function):
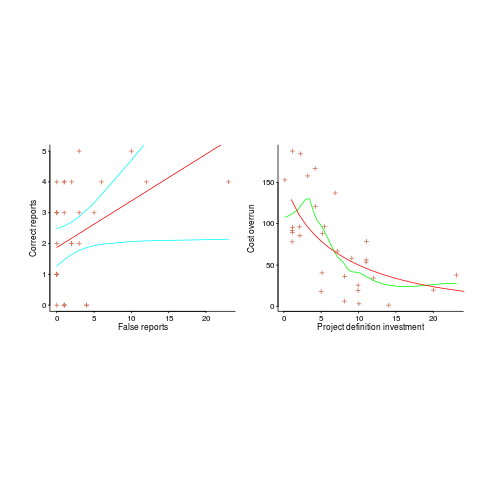
The confidence intervals (in blue) are showing us that there is huge uncertainty in the fitted equation; no technical details needed.
The Local in LOESS means that some local set of points are used to fit each part of the line. That green line is telling us that the mean value of the data does not continue to increase, but levels off (the data is from a NASA presentation that showed an ever-increasing fitted line; which is the view the speaker wanted people to believe).
If somebody shows you a line that has been fitted to the data, ask to see the confidence intervals and the loess from a fit. The willingness of the person to show you these, or their ability to do so, will tell you a lot.
Data analysis with a manual mindset
A lot of software engineering data continues to be analysed using techniques designed for manual implementation (i.e., executed without a computer). Yes, these days computers are being used to do the calculation, but they are being used to replicate the manual steps.
Statistical techniques are often available that are more powerful than the ‘manual’ techniques. They were not used during the manual-era because they are too computationally expensive to be done manually, or had not been invented yet; the bootstrap springs to mind.
What is the advantage of these needs-a-computer techniques?
The main advantage is not requiring that the data have a Normal distribution. While data having a Normal, or normal-like, distribution is common is the social sciences (a big consumer of statistical analysis), it is less common in software engineering. Software engineering data is often skewed (at least the data I have analysed) and what appear to be outliers are common.
It seems like every empirical paper I read uses a Mann-Whitney test or Wilcoxon signed-rank test to compare two samples, sometimes preceded by a statement that the data is close to being Normal, more often being silent on this topic, and occasionally putting some effort into showing the data is Normal or removing outliers to bring it closer to being Normally distributed.
Why not use a bootstrap technique and not have to bother about what distribution the data has?
I’m not sure whether the reason is lack of knowledge about the bootstrap or lack of confidence in not following the herd (i.e., what will everybody say if my paper does not use the techniques that everybody else uses?)
If you are living on a desert island and don’t have a computer, then you will want to use the manual techniques. But then you probably won’t be interested in analyzing software engineering data.
Histogram using log scale creates a visual artifact
The following plot appears in the paper Stack Overflow in Github: Any Snippets There?
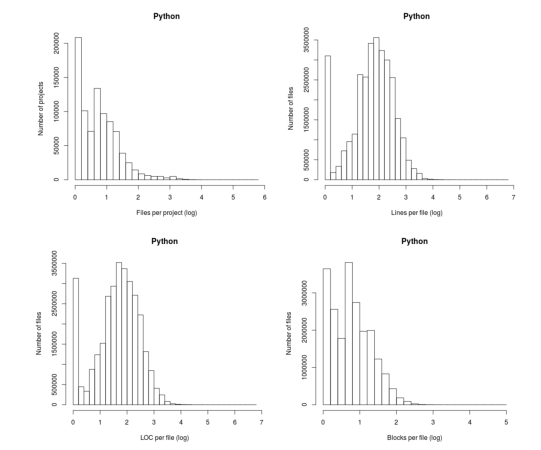
Don’t those twin peaks in the top-left/bottom-right plots reach out and grab your attention? I immediately thought of fitting a mixture of two Poisson distributions; No, No, No, something wrong here. The first question of data analysis is: Do I believe the data?
The possibility of fake data does not get asked until more likely possibilities have been examined first.
The y-axis is a count of things and the x-axis shows the things being counted; source files per project and functions per file, in this case.
All the measurements I know of show a decreasing trend for these things, e.g., lots of projects have a few files and a few projects have lots of files. Twin peaks is very unexpected.
I have serious problems believing this data, because it does not conform to my prior experience. What have the authors done wrong?
My first thought was that a measuring mistake had been made; for some reason values over a certain range were being incorrectly miscounted.
Then I saw the problem. The plot was of a histogram and the x-axis had a logarithmic scale. A logarithmic axis compresses the range in a non-linear fashion, which means that variable width bins have to be used for histograms and the y-axis represents density (not a count).
Taking logs and using the result to plot a histogram usually produces a curve having a distorted shape, not twin peaks. I think the twin peaks occur here because integer data are involved and the bin width just happened to have the ‘right’ value.
Looking at the plot below, the first bin contains values for x=1 (on an un-logged scale), the second bin for x=2, the third bin for x=3, but the fourth bin contains values for x=c(4, 5, 6). The nonlinear logarithmic compression, mapped to integers, means that the contents of three values are added to a single bin, creating a total that is larger than the third bin.
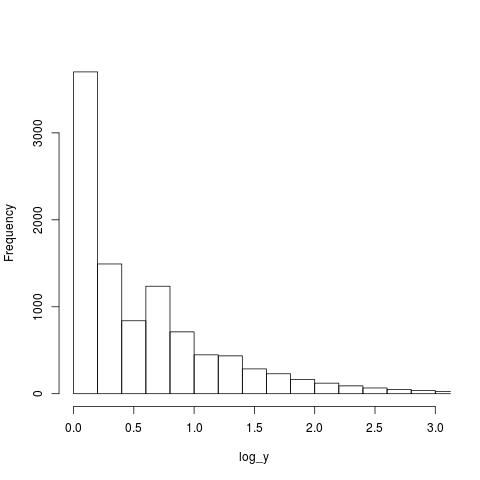
The R code that generated the above plot:
x=1:1e6 y=trunc(1e6/x^1.5) log_y=log10(y) hist(log_y, n=40, main="", xlim=c(0, 3)) |
I tried to mimic the pattern seen in the first histogram by trying various exponents of a power law (a common candidate for this kind of measurement), but couldn’t get anything to work.
Change the bin width can make the second peak disappear, or rather get smeared out. Still a useful pattern to look out for in the future.
Expected variability in a program’s SLOC
If 10 people independently implement the same specification in the same language, how much variation will there be in the length of their programs (measured in lines of code)?
The data I have suggests that the standard deviation of program length is one quarter of the mean length, e.g., 10k mean length, 2.5k standard deviation.
The plot below (code+data) shows six points from the samples I have. The point in the bottom left is based on 6,300 C programs from a programming contest question requiring solutions to the 3n+1 problem and one of the points on the right comes from five Pascal compilers for the same processor.
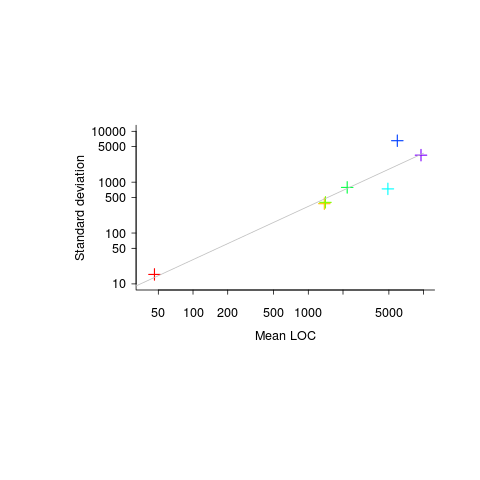
Multiple implementations of the same specification, in the same language, are very rare. If you know of any, please let me know.
Experimental method for measuring benefits of identifier naming
I was recently came across a very interesting experiment in Eran Avidan’s Master’s thesis. Regular readers will know of my interest in identifiers; while everybody agrees that identifier names have a significant impact on the effort needed to understand code, reliably measuring this impact has proven to be very difficult.
The experimental method looked like it would have some impact on subject performance, but I was not expecting a huge impact. Avidan’s advisor was Dror Feitelson, who kindly provided the experimental data, answered my questions and provided useful background information (Dror is also very interested in empirical work and provides a pdf of his book+data on workload modeling).
Avidan’s asked subjects to figure out what a particular method did, timing how long it took for them to work this out. In the control condition a subject saw the original method and in the experimental condition the method name was replaced by local and parameter names were replaced by single letter identifiers; in all cases the method name was replaced by xxx andxxx. The hypothesis was that subjects would take longer for methods modified to use ‘random’ identifier names.
A wonderfully simple idea that does not involve a lot of experimental overhead and ought to be runnable under a wide variety of conditions, plus the difference in performance is very noticeable.
The think aloud protocol was used, i.e., subjects were asked to speak their thoughts as they processed the code. Having to do this will slow people down, but has the advantage of helping to ensure that a subject really does understand the code. An overall slower response time is not important because we are interested in differences in performance.
Each of the nine subjects sequentially processed six methods, with the methods randomly assigned as controls or experimental treatments (of which there were two, locals first and parameters first).
The procedure, when a subject saw a modified method was as follows: the subject was asked to explain the method’s purpose, once an answer was given (or 10 mins had elapsed) either the local or parameter names were revealed and the subject had to again explain the method’s purpose, and when an answer was given the names of both locals and parameters was revealed and a final answer recorded. The time taken for the subject to give a correct answer was recorded.
The summary output of a model fitted using a mixed-effects model is at the end of this post (code+data; original experimental materials). There are only enough measurements to have subject as a random effect on the treatment; no order of presentation data is available to look for learning effects.
Subjects took longer for modified methods. When parameters were revealed first, subjects were 268 seconds slower (on average), and when locals were revealed first 342 seconds slower (the standard deviation of the between subject differences was 187 and 253 seconds, respectively; less than the treatment effect, surprising, perhaps a consequence of information being progressively revealed helping the slower performers).
Why is subject performance less slow when parameter names are revealed first? My thoughts: parameter names (if well-chosen) provide clues about what incoming values represent, useful information for figuring out what a method does. Locals are somewhat self-referential in that they hold local information, often derived from parameters as initial values.
What other factors could impact subject performance?
The number of occurrences of each name in the body of the method provides an opportunity to deduce information; so I think time to figure out what the method does should less when there are many uses of locals/parameters, compared to when there are few.
The ability of subjects to recognize what the code does is also important, i.e., subject code reading experience.
There are lots of interesting possibilities that can be investigated using this low cost technique.
Linear mixed model fit by REML ['lmerMod']
Formula: response ~ func + treatment + (treatment | subject)
Data: idxx
REML criterion at convergence: 537.8
Scaled residuals:
Min 1Q Median 3Q Max
-1.34985 -0.56113 -0.05058 0.60747 2.15960
Random effects:
Groups Name Variance Std.Dev. Corr
subject (Intercept) 38748 196.8
treatmentlocals first 64163 253.3 -0.96
treatmentparameters first 34810 186.6 -1.00 0.95
Residual 43187 207.8
Number of obs: 46, groups: subject, 9
Fixed effects:
Estimate Std. Error t value
(Intercept) 799.0 110.2 7.248
funcindexOfAny -254.9 126.7 -2.011
funcrepeat -560.1 135.6 -4.132
funcreplaceChars -397.6 126.6 -3.140
funcreverse -466.7 123.5 -3.779
funcsubstringBetween -145.8 125.8 -1.159
treatmentlocals first 342.5 124.8 2.745
treatmentparameters first 267.8 106.0 2.525
Correlation of Fixed Effects:
(Intr) fncnOA fncrpt fncrpC fncrvr fncsbB trtmntlf
fncndxOfAny -0.524
funcrepeat -0.490 0.613
fncrplcChrs -0.526 0.657 0.620
funcreverse -0.510 0.651 0.638 0.656
fncsbstrngB -0.523 0.655 0.607 0.655 0.648
trtmntlclsf -0.505 -0.167 -0.182 -0.160 -0.212 -0.128
trtmntprmtf -0.495 -0.184 -0.162 -0.184 -0.228 -0.213 0.673 |
An Almanac of the Internet
My search for software engineering data has turned me into a frequent buyer of second-hand computer books, many costing less than the postage of £2.80. When the following suggestion popped up along-side a search, I could not resist; there must be numbers in there!

The concept of an Almanac will probably be a weird idea to readers who grew up with search engines and Wikipedia. But yes, many years ago, people really did make a living by manually collecting information and selling it in printed form.
One advantage of the printed form is that updating it requires a new copy, the old copy lives on unchanged (unlike web pages); the disadvantage is taking up physical space (one day I will probably abandon this book in a British rail coffee shop).
Where did Internet users hang out in 1997?
The history of the Internet, as it appeared in 1997.

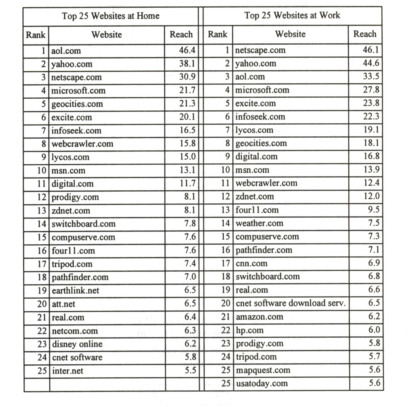
Of course, a list of web sites is an essential component of an Internet Almanac:

Investing in the gcc C++ front-end
I recently found out that RedHat are investing in improving the C++ front-end of gcc, i.e., management have assigned developers to work in this area. What’s in it for RedHat? I’m told there are large companies (financial institutions feature) who think that using some of the features added to recent C++ standards (these have been appearing on a regular basis) will improve the productivity of their developers. So, RedHat are hoping this work will boost their reputation and increase their sales to these large companies. As an ex-compiler guy (ex- in the sense of being promoted to higher levels that require I don’t do anything useful), I am always in favor or companies paying people to work on compilers; go RedHat.
Is there any evidence that features that have been added to any programming language improved developer productivity? The catch to this question is defining programmer productivity. There have been several studies showing that if productivity is defined as number of assembly language lines written per day, then high level languages are more productive than assembler (the lines of assembler generated by the compiler were counted, which is rather compiler dependent).
Of the 327 commits made this year to the gcc C++ front-end, by 29 different people, 295 were made by one of 17 people employed by RedHat (over half of these commits were made by two people and there is a long tail; nine people each made less than four commits). Measuring productivity by commit counts has plenty of flaws, but has the advantage of being easy to do (thanks Jonathan).
Recent Comments