Changes in the shape of code during the twenties?
At the end of 2009 I made two predictions for the next decade; Chinese and Indian developers having a major impact on the shape of code (ok, still waiting for this to happen), and scripting languages playing a significant role (got that one right, but then they were already playing a large role).
Since this blog has just entered its second decade, I will bring the next decade’s predictions forward a year.
I don’t see any new major customer ecosystems appearing. Ecosystems are the drivers of software development, and no new ecosystems has several consequences, including:
- No major new languages: Creating a language is a vanity endeavour. Vanity project can take off if they are in the right place at the right time. New ecosystems provide opportunities for new languages to become widely used by being in at the start and growing with the ecosystem. There is another opportunity locus; it is fashionable for companies that see themselves as thought-leaders to have their own language, e.g., Google, Apple, and Mozilla. Invent your language at the right time, while working for a thought-leader company and your language could become well-known enough to take-off.
I don’t see any major new ecosystems appearing, and all the likely companies already have their own language.
Any new language also faces the problem of not having a large collection packages.
- Software will be more thoroughly tested: When an ecosystem is new, the incentives drive early and frequent releases (to build a customer base); software just has to be good enough. Once a product is established, companies can invest in addressing issues that customers find annoying, like faulty behavior; the incentive change results in more testing.
There are other forces at work around testing. Companies are experiencing some very expensive faults (testing may be expensive, but not testing may be more expensive) and automatic test generation is becoming commercially usable (i.e., the cost of some kinds of testing is decreasing).
The evolution of widely used languages.
- I think Fortran and C will have new features added, with relatively little fuss, and will quietly continue to be widely used (to the dismay of the fashionista).
-
There is a strong expectation that C++ and Java should continue to evolve:
- I expect the ISO C++ work to implode, because there are too many people pulling in too many directions. It makes sense for the gcc and llvm teams to cooperate in taking C++ in a direction that satisfies developers’ needs, rather than the needs of bored consultants. What are Microsoft’s views? They only have their own compiler for strategic reasons (they make little if any profit selling compilers, compilers are an unnecessary drain on management time; who cares what happens to the language).
- It is going to be interesting watching the impact of Oracle’s move to charging for runtimes. I have no idea what might happen to Java.
In terms of code volume, the future surely has to be scripting languages, and in particular Python, Javascript and PHP. Ten years from now, will there be a widely used, single language? People have been predicting, for many years, that web languages will take over the world; perhaps there will be a sudden switch and I will see that the choice is obvious.
Moore’s law is now dead, which means researchers are going to have to look for completely new techniques for building logic gates. If photonic computers happen, then ternary notation may reappear again (it was used in at least one early Russian computer); I’m not holding my breath for this to occur.
Foundations for Evidence-Based Policymaking Act of 2017
The Foundations for Evidence-Based Policymaking Act of 2017 was enacted by the US Congress on 21st December.
A variety of US Federal agencies are responsible for ensuring the safety of US citizens, in some cases this safety is dependent on the behavior of software. The FDA is responsible for medical device safety and the FAA publishes various software safety handbooks relating to aviation (the Department of transportation has a wider remit).
Where do people go to learn about the evidence for software related issues?
The book: Evidence-based software engineering: based on the publicly available evidence sounds like a good place to start.
Quickly skimming this (currently draft) book shows that no public evidence is available on lots of issues. Oops.
Another issue is the evidence pointing to some suggested practices being at best useless and sometimes fraudulent, e.g., McCabe’s cyclomatic complexity metric.
The initial impact of evidence-based policymaking will be companies pushing back against pointless government requirements, in particular requirements that cost money to implement. In some cases this is a good, e.g., no more charades about software being more testable because its code has a low McCable complexity.
In the slightly longer term, people are going to have to get serious about collecting and analyzing software related evidence.
The Open, Public, Electronic, and Necessary Government Data Act or the OPEN Government Data Act (which is about to become law) will be a big help in obtaining evidence. I think there is a lot of software related data sitting on disks and tapes, waiting to be analysed (NASA appears to have loads to data that they have down almost nothing with, including not making it publicly available).
Interesting times ahead.
Distorting the input profile, to stress test a program
A fault is experienced in software when there is a mistake in the code, and a program is fed the input values needed for this mistake to generate faulty behavior.
There is suggestive evidence that the distribution of coding mistakes and inputs generating fault experiences both have an influence of fault discovery.
How might these coding mistakes be found?
Testing is one technique, it involves feeding inputs into a program and checking the resulting behavior. What are ‘good’ input values, i.e., values most likely to discover problems? There is no shortage of advice for manually writing tests, suggesting how to select input values, but automatic generation of inputs is often somewhat random (relying on quantity over quality).
Probabilistic grammar driven test generators are trivial to implement. The hard part is tuning the rules and the probability of them being applied.
In most situations an important design aim, when creating a grammar, is to have one rule for each construct, e.g., all arithmetic, logical and boolean expressions are handled by a single expression rule. When generating tests, it does not always make sense to follow this rule; for instance, logical and boolean expressions are much more common in conditional expressions (e.g., controlling an if-statement), than other contexts (e.g., assignment). If the intent is to mimic typical user input values, then the probability of generating a particular kind of binary operator needs to be context dependent; this might be done by having context dependent rules or by switching the selection probabilities by context.
Given a grammar for a program’s input (e.g., the language grammar used by a compiler), decisions have to be made about the probability of each rule triggering. One way of obtaining realistic values is to parse existing input, counting the number of times each rule triggers. Manually instrumenting a grammar to do this is a tedious process, but tool support is now available.
Once a grammar has been instrumented with probabilities, it can be used to generate tests.
Probabilities based on existing input will have the characteristics of that input. A recent paper on this topic (which prompted this post) suggests inverting rule probabilities, so that common becomes rare and vice versa; the idea is that this will maximise the likelihood of a fault being experienced (the assumption is that rarely occurring input will exercise rarely executed code, and such code is more likely to contain mistakes than frequently executed code).
I would go along with the assumption about rarely executed code having a greater probability of containing a mistake, but I don’t think this is the best test generation strategy.
Companies are only interested in fixing the coding mistakes that are likely to result of a fault being experienced by a customer. It is a waste of resources to fix a mistake that will never result in a fault experienced by a customer.
What input is likely to interact with coding mistakes to be the root cause of faults experienced by a customer? I have no good answer to this question. But, given there are customer input contains patterns (at least in the world of source code, and I’m told in other application domains), I would generate test cases that are very similar to existing input, but with one sub-characteristic changed.
In the academic world the incentive is to publish papers reporting loads-of-faults-found, the more the merrier. Papers reporting only a few faults are obviously using inferior techniques. I understand this incentive, but fixing problems costs money and companies want a customer oriented rationale before they will invest in fixing problems before they are reported.
The availability of tools that automate the profiling of a program’s existing input, followed by the generation of input having slightly, or very, different characteristics make it easier to answer some very tough questions about program behavior.
Growth of conditional complexity with file size
Conditional statements are a fundamental constituent of programs. Conditions are driven by the requirements of the problem being solved, e.g., if the water level is below the minimum, then add more water. As the problem being solved gets more complicated, dependencies between subproblems grow, requiring an increasing number of situations to be checked.
A condition contains one or more clauses, e.g., a single clause in: if (a==1), and two clauses in: if ((x==y) && (z==3)); a condition also appears as the termination test in a for-loop.
How many conditions containing one clause will a 10,000 line program contain? What will be the distribution of the number of clauses in conditions?
A while back I read a paper studying this problem (“What to expect of predicates: An empirical analysis of predicates in real world programs”; Google currently not finding a copy online, grrr, you will have to hassle the first author: durelli@icmc.usp.br, or perhaps it will get added to a list of favorite publications {be nice, they did publish some very interesting data}) it contained a table of numbers and yesterday my analysis of the data revealed a surprising pattern.
The data consists of SLOC, number of files and number of conditions containing a given number of clauses, for 63 Java programs. The following plot shows percentage of conditionals containing a given number of clauses (code+data):

The fitted equation, for the number of conditionals containing a given number of clauses, is:

where:  (the coefficient for the fitted regression model is 0.56, but square-root is easier to remember),
(the coefficient for the fitted regression model is 0.56, but square-root is easier to remember),  , and
, and  is the number of clauses.
is the number of clauses.
The fitted regression model is not as good when  or
or  is always used.
is always used.
This equation is an emergent property of the code; simply merging files to increase the average length will not change the distribution of clauses in conditionals.
When  , all conditionals contain the same number of clauses, off to infinity. For the 63 Java programs, the mean was 2,625, maximum 11,710, and minimum 172.
, all conditionals contain the same number of clauses, off to infinity. For the 63 Java programs, the mean was 2,625, maximum 11,710, and minimum 172.
I was expecting SLOC to have an impact, but was not expecting number of files to be involved.
What grows with SLOC? Number of global variables and number of dependencies. There are more things available to be checked in larger programs, and an increase in dependencies creates the need to perform more checks. Also, larger programs are likely to contain more special cases, which are likely to involve checking both general and specific values (i.e., more clauses in conditionals); ok, this second sentence is a bit more arm-wavy than the first. The prediction here is that the percentage of global variables appearing in conditions increases with SLOC.
Chopping stuff up into separate files has a moderating effect. Since I did not expect this, I don’t have much else to say.
This model explains 74% of the variance in the data (impressive, if I say so myself). What other factors might be involved? Depth of nesting would be my top candidate.
Removing non-if-statement related conditionals from the count would help clarify things (I don’t expect loop-controlling conditions to be related to amount of code).
Two interesting data-sets in one week, with 10-days still to go until Christmas 🙂
Update: Fitting the same equation to the data from a later paper by the same group, based on mobile applications written in Swift and Objective-C, also produces a well-fitted regression model (apart from the term specifying an interactions between and  ).
).
Update: Thanks to Frank Busse for reminding me of the FAA report An Investigation of Three Forms of the Modified Condition Decision Coverage (MCDC) Criterion, which contains detailed information on the 20,256 conditionals in five Ada programs. The number of conditionals containing a given number of clauses is fitted by a power law (exponent is approximately -3).
Impact of group size and practice on manual performance
How performance varies with group size is an interesting question that is still an unresearched area of software engineering. The impact of learning is also an interesting question and there has been some software engineering research in this area.
I recently read a very interesting study involving both group size and learning, and Jaakko Peltokorpi kindly sent me a copy of the data.
That is the good news; the not so good news is that the experiment was not about software engineering, but the manual assembly of a contraption of the experimenters devising. Still, this experiment is an example of the impact of group size and learning (through repeating the task) on time to complete a task.
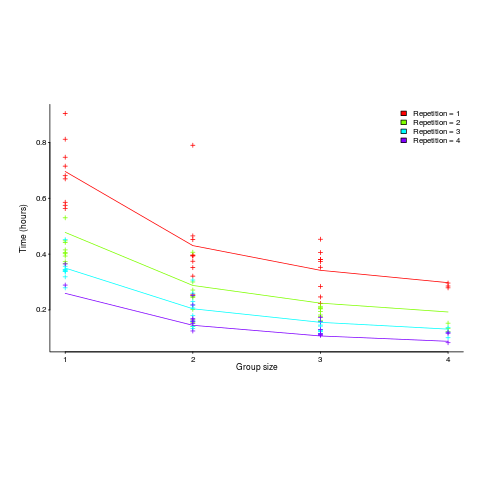
Subjects worked in groups of one to four people and repeated the task four times. Time taken to assemble a bespoke, floor standing rack with some odd-looking connections between components was measured (the image in the paper shows something that might function as a floor standing book-case, if shelves were added, apart from some component connections getting in the way).
The following equation is a very good fit to the data (code+data). There is theory explaining why ") applies, but the division by group-size was found by suck-it-and-see (in another post I found that time spent planning increased with teams size).
applies, but the division by group-size was found by suck-it-and-see (in another post I found that time spent planning increased with teams size).
There is a strong repetition/group-size interaction. As the group size increases, repetition has less of an impact on improving performance.
![time = 0.16+ 0.53/{group size} - log(repetitions)*[0.1 + {0.22}/{group size}]](https://shape-of-code.com/wp-content/plugins/wpmathpub/phpmathpublisher/img/math_981.5_b0d171bba046801a68ce5dc8ae1d6115.png "time = 0.16+ 0.53/{group size} - log(repetitions)*[0.1 + {0.22}/{group size}]")
The following plot shows one way of looking at the data (larger groups take less time, but the difference declines with practice), lines are from the fitted regression model:
and here is another (a group of two is not twice as fast as a group of one; with practice smaller groups are converging on the performance of larger groups):
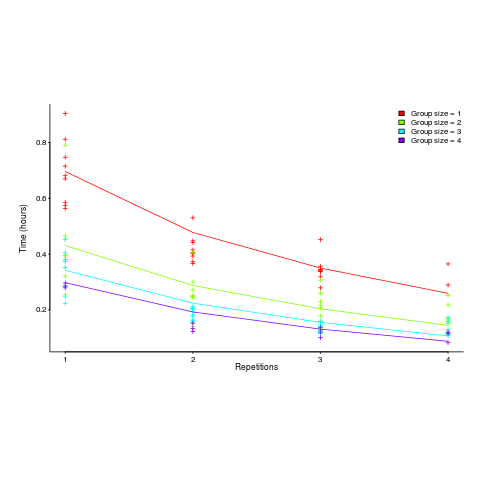
Would the same kind of equation fit the results from solving a software engineering task? Hopefully somebody will run an experiment to find out 🙂
Coding guidelines should specify what constructs can be used
There is a widespread belief that an important component of creating reliable software includes specifying coding constructs that should not be used, i.e., coding guidelines. Given that the number of possible coding constructs is greater than the number of atoms in the universe, this approach is hopelessly impractical.
A more practical approach is to specify the small set of constructs that developers that can only be used. Want a for-loop, then pick one from the top-10 most frequently occurring looping constructs (found by measuring existing usage); the top-10 covers 70% of existing C usage, the top-5 55%.
Specifying the set of coding constructs that can be used, removes the need for developers to learn lots of stuff that hardly ever gets used, allowing them to focus on learning a basic set of techniques. A small set of constructs significantly simplifies the task of automatically checking code for problems; many of the problems currently encountered will not occur; many edge cases disappear.
Developer coding mistakes have two root causes:
- what was written is not what was intended. A common example is the conditional in the if-statement:
if (x = y), where the developer intended to writeif (x == y). This kind of coding typo is the kind of construct flagged by static analysis tools as suspicious.People make mistakes, and developers will continue to make this kind of typographical mistake in whatever language is used,
- what was written does not have the behavior that the developer believes it has, i.e., there is a fault in the developers understanding of the language semantics.
Incorrect beliefs, about a language, can be reduced by reducing the amount of language knowledge developers need to remember.
Developer mistakes are also caused by misunderstandings of the requirements, but this is not language specific.
Why do people invest so much effort on guidelines specifying what constructs not to use (these discussions essentially have the form of literary criticism)? Reasons include:
- providing a way for developers to be part of the conversation, through telling others about their personal experiences,
- tool vendors want a regular revenue stream, and product updates flagging uses of even more constructs (that developers could misunderstand or might find confusing; something that could be claimed for any language construct) is a way of extracting more money from existing customers,
- it avoids discussing the elephant in the room. Many developers see themselves as creative artists, and as such are entitled to write whatever they think necessary. Developers don’t seem to be affronted by the suggestion that their artistic pretensions and entitlements be curtailed, probably because they don’t take the idea seriously.
The 520’th post
This is the 520’th post on this blog, which will be 10-years old tomorrow. Regular readers may have noticed an increase in the rate of posting over the last few months; at the start of this month I needed to write 10 posts to hit my one-post a week target (which has depleted the list of things I keep meaning to write about).
What has happened in the last 10-years?
- I no longer visit libraries, which are becoming coffee shops+wifi hot-spots where people who have librarian in their job title, hot desk; books, they are around here somewhere. I used to regularly visit libraries, particularly while working on my C book. No libraries have so far needed to be visited, for the writing of my evidence-based software engineering book,
- many old manuals, reports, books and magazines became freely available for download, via sites like the Internet Archive, Bitsavers and the Defense Technical Information Center; for second hand books there is AbeBooks. Site like Research Gate, Semantic Scholar and Google Scholar are fantastic sources for more recent work; for new books there is Amazon,
- Github became the place to make source code+stuff available,
- researchers in software engineering started to become interested in evidence-based research. In the UK the CREST Open Workshops were a fantastic series of events; I went to about a third of them, and there were often a couple of gold nuggets per event (a change of funding means running future events will require a lot more work),
- smart phones became the last, next, major software consumer ecosystem (capturing a large percentage of the world’s population means there is no room left for something bigger), and the cloud started on its path to being 99% of the commercial software ecosystem,
- Python joined the short-list to become the world’s primary programming language (assuming that people still run programs outside of the browser). The decline of PERL became very obvious, and work on adding new features to Cobol stopped (work on adding features to Fortran is still going strong),
- known faults are now being automatically fixed by modifying the source code (using genetic programming). This has yet to move out of research, but we all know where it’s going,
- whole program optimization of systems containing millions of lines of code became a viable option for commercial developers (a topic of late night discussion for compiler writers in the 1980s, and perhaps earlier decades, when having more than 64K of memory was treated as nirvana),
- after 20-years of being the only major open source compiler tool-chain, gcc got some serious competition. I originally predicted that llvm would disappear, failing to recognize that Apple were supporting it for licensing reasons,
- the death throes of Moore’s law went from subtle to, isn’t it dead yet?
I probably missed several major events hiding in plain sight, either because I am too close to them or blinkered.
What did not happen in the last 10 years?
- No major new languages. These require major new hardware ecosystems; in the smartphone market Android used Java and iOS made use of existing languages. There were the usual selection of fashion/vanity driven wannabes, e.g., Julia, Rust, and Go. The R language started to get noticed, but it has been around since 1995, and Python looks set to eventually kill it off,
- no accident killing 100+ people has been attributed to faults in software. Until this happens, software engineering has a dead bodies problem,
- the creation of new software did not slow down from its break-neck speed,
- in the first few years of this blog I used to make yearly predictions, which did not happen (most of the time).
Now I can relax for 9.5 years, before scurrying to complete 1,040 posts, i.e., the rate of posting will now resume its previous, more sedate, pace.
Half-life of software as a service, services
How is software used to provide a service (e.g., the software behind gmail) different from software used to create a product (e.g., sold as something that can be installed)?
This post focuses on one aspect of the question, software lifetime.
The Killed by Google website lists Google services and products that are no more. Cody Ogden, the creator of the site, has open sourced the code of the website; there are product start/end dates!
After removing 20 hardware products from the list, we are left with 134 software services. Some of the software behind these services came from companies acquired by Google, so the software may have been used to provide a service pre-acquisition, i.e., some calculated lifetimes are underestimates.
The plot below shows the number of Google software services (blue) having a given lifetime (calculated as days between Google starting/withdrawing service), mainframe software from the 1990s (red; only available at yearly resolution), along with fitted exponential regression lines (code+data):
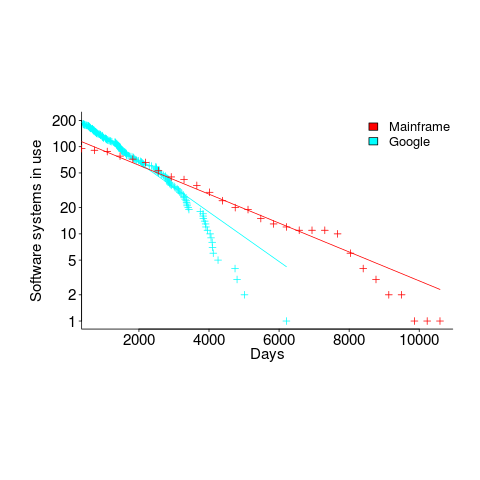
Overall, an exponential is a good fit (squinting to ignore the dozen red points), although product culling is not exponentially ruthless at short lifetimes (newly launched products are given a chance to prove themselves).
The Google service software half-life is 1,500 days, about 4.1 years (assuming the error/uncertainty is additive, if it is multiplicative {i.e., a percentage} the half-life is 1,300 days); the half-life of mainframe software is 2,600 days (with the same assumption about the kind of error/uncertainty).
One explanation of the difference is market maturity. Mainframe software has been evolving since the 1950s and probably turned over at the kind of rate we saw a few years ago with Internet services. By the 1990s things had settled down a bit in the mainframe world. Will software-based services on the Internet settle down faster than mainframe software? Who knows.
Based on this Google data, the cost/benefit ratio when deciding whether to invest in reducing future software maintenance costs, is going to have to be significantly better than the ratio calculated for mainframe software.
Software system lifetime data is extremely hard to find (this is only the second set I have found). Any pointers to other lifetime data very welcome, e.g., a collection of Microsoft product start/end dates 🙂
Ecosystems as major drivers of software development
During the age of the Algorithm, developers wrote most of the code in their programs. In the age of the Ecosystem, developers make extensive use of code supplied by third-parties.
Software ecosystems are one of the primary drivers of software development.
The early computers were essentially sold as bare metal, with the customer having to write all the software. Having to write all the software was expensive, time-consuming, and created a barrier to more companies using computers (i.e., it was limiting sales). The amount of software that came bundled with a new computer grew over time; the following plot (code+data) shows the amount of code (thousands of instructions) bundled with various IBM computers up to 1968 (an antitrust case eventually prevented IBM bundling software with its computers):
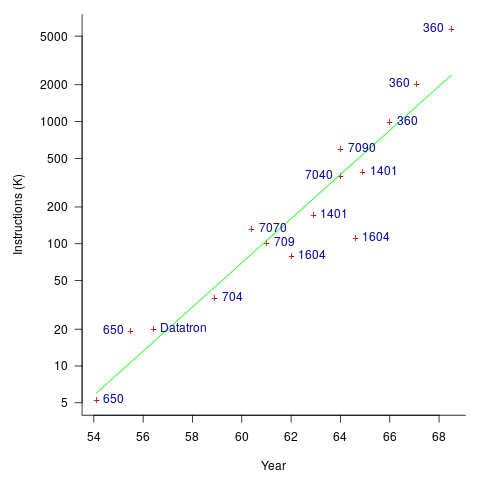
Some tasks performed using computers are common to many computer users, and users soon started to meet together, to share experiences and software. SHARE, founded in 1955, was the first computer user group.
SHARE was one of several nascent ecosystems that formed at the start of the software age, another is the Association for Computing Machinery; a great source of information about the ecosystems existing at the time is COMPUTERS and AUTOMATION.
Until the introduction of the IBM System/360, manufacturers introduced new ranges of computers that were incompatible with their previous range, i.e., existing software did not work.
Compatibility with existing code became a major issue. What had gone before started to have a strong influence on what was commercially viable to do next. Software cultures had come into being and distinct ecosystems were springing up.
A platform is an ecosystem which is primarily controlled by one vendor; Microsoft Windows is the poster child for software ecosystems. Over the years, Microsoft has added more and more functionality to Windows, and I don’t know enough to suggest the date when substantial Windows programs substantially depended on third-party code; certainly small apps may be mostly Windows code. The Windows GUI certainly ties developers very closely to a Windows way of doing things (I have had many people tell me that porting to a non-Windows GUI was a lot of work, but then this statement seems to be generally true of porting between different GUIs).
Does Facebook’s support for the writing of simple apps make it a platform? Bill Gates thought not: “A platform is when the economic value of everybody that uses it, exceeds the value of the company that creates it.”, which some have called the Gates line.
The rise of open source has made it viable for substantial language ecosystems to flower, or rather substantial package ecosystems, with each based around a particular language. For practical purposes, language choice is now about the quality and quantity of their ecosystem. The dedicated followers of fashion like to tell everybody about the wonders of Go or Rust (in fashion when I wrote this post), but without a substantial package ecosystem, no language stands a chance of being widely used over the long term.
Major new software ecosystems have been created on a regular basis (regular, as in several per decade), e.g., mainframes in the 1960s, minicomputers and workstation in the 1970s, microcomputers in the 1980s, the Internet in the 1990s, smartphones in the 2000s, the cloud in the 2010s.
Will a major new software ecosystem come into being in the future? Major software ecosystems tend to be hardware driven; is hardware development now basically done, or should we expect something major to come along? A major hardware change requires a major new market to conquer. The smartphone has conquered a large percentage of the world’s population; there is no larger market left to conquer. Now, it’s about filling in the gaps, i.e., lots of niche markets that are still waiting to be exploited.
Software ecosystems are created through lots of people working together, over many years, e.g., the huge number of quality Python packages. Perhaps somebody will emerge who has the skills and charisma needed to get many developers to build a new ecosystem.
Software ecosystems can disappear; I think this may be happening with Perl.
Can a date be put on the start of the age of the Ecosystem? Ideas for defining the start of the age of the Ecosystem include:
- requiring a huge effort to port programs from one ecosystem to another. It used to be very difficult to port between ecosystems because they were so different (it has always been in vendors’ interests to support unique functionality). Using this method gives an early start date,
- by the amount of code/functionality in a program derived from third-party packages. In 2018, it’s certainly possible to write a relatively short Python program containing a huge amount of functionality, all thanks to third-party packages. Was this true for any ecosystems in the 1980s, 1990s?
Polished statistical analysis chapters in evidence-based software engineering
I have completed the polishing/correcting/fiddling of the eight statistical analysis related chapters of my evidence-based software engineering book, and an updated draft pdf is now available (download here).
The material was in much better shape than I recalled, after abandoning it to the world 2-years ago, to work on the software engineering chapters.
Changes include moving more figures into the margin (which is responsible for a lot of the reduction in page count), fixing grammatical typos, removing place-holders for statistical techniques that are unlikely to be of general interest to software engineers, and mostly minor shuffling around (the only big change was moving a lot of material from the Experiments chapter to the Statistics chapter).
There is still some work to be done, in places (most notably the section on surveys).
What next? My collection of data waiting to be analysed has been piling up, so I will spend the next month reducing the backlog.
The six chapters covering the major areas of software engineering need to be polished and fleshed out, from their current bare-bones state. All being well, this time next year a beta release will be ready.
While working on the statistical material, I have been making monthly updates to the pdf+data available. If it makes sense to do this for the rest of the material, then it will happen. I’m not going to write a blog post every month; perhaps a post after what look like important milestones.
As always, if you know of any interesting software engineering data, please tell me.
Recent Comments