Growth in number of packages for widely used languages
These days a language’s ecosystem of add-ons, such as packages, is often more important than the features provided by the language (which usually only vary in their syntactic sugar, and built-in support for some subset of commonly occurring features).
Use of a particular language grows and shrinks, sometimes over very many decades. Estimating the number of users of a language is difficult, but a possible proxy is ecosystem activity in the form of package growth/decline. However, it will take many several decades for the data needed to test how effective this proxy might be.
Where are we today?
The Module Counts website is the home for a project that counts the number of libraries/packages/modules contained in 26 language specific repositories. Daily data, in some cases going back to 2010, is available as a csv 🙂 The following are the most interesting items I discovered during a fishing expedition.
The csv file contains totals, and some values are missing (which means specifying an ‘ignore missing values’ argument to some functions). Some repos have been experiencing large average daily growth (e.g., 65 for PyPI, and 112 for Maven Central-Java), while others are more subdued (e.g., 0.7 for PERL and 3.9 for R’s CRAN). Apart from a few days, the daily change is positive.
Is the difference in the order of magnitude growth due to number of active users, number of packages that currently exist, a wide/narrow application domain (Python is wide, while R’s is narrow), the ease of getting a package accepted, or something else?
The plots below show how PyPI has been experiencing exponential growth of a kind (the regression model fitted to the daily total has the form  , where
, where  is the number of days since 2010-01-01; the red line is the daily diff of this equation), while Ruby has been experiencing a linear decline since late 2014 (all code+data):
is the number of days since 2010-01-01; the red line is the daily diff of this equation), while Ruby has been experiencing a linear decline since late 2014 (all code+data):
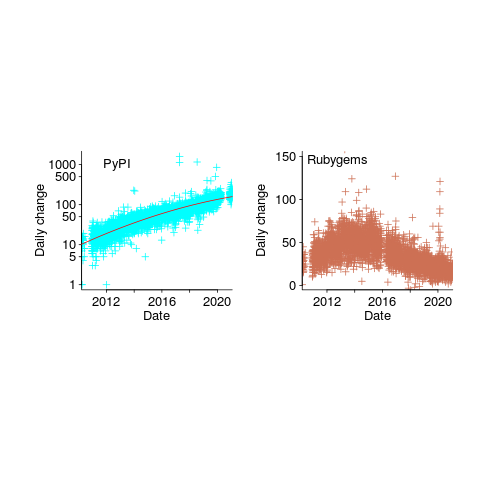
Will the five-year decline in new submissions to Rubygems continue, and does this point to an eventual demise of Ruby (a few decades from now)? Rubygems has years to go before it reaches PERL’s low growth rate (I think PERL is in terminal decline).
Are there any short term patterns, say at the weekly level? Autocorrelation is a technique for estimating the extent to which today’s value is affected by values from the immediate past (usually one or two measurement periods back, i.e., yesterday or the day before that). The two plots below show the autocorrelation for daily changes, with lag in days:
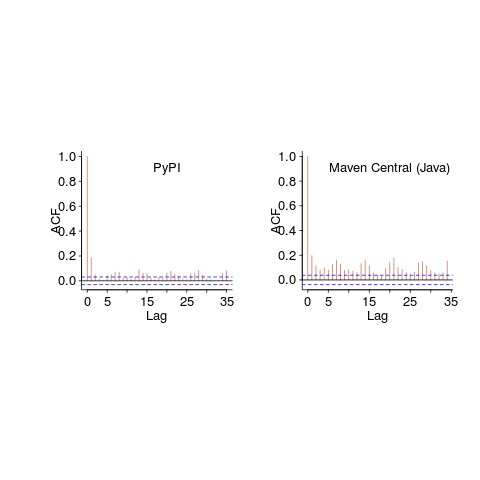
The recurring 7-day ‘peaks’ show the impact of weekends (I assume). Is the larger ”weekend-effect’ for Java, compared to PyPI, due to Java usage including a greater percentage of commercial developers (who tend not to work at the weekend)?
I did not manage to find any seasonal effect, e.g., more submissions during the winter than the summer. But I only checked a few of the languages, and only for a single peak (see code for details).
Another way of tracking package evolution is version numbering. For instance, how often do version numbers change, and which component, e.g., major/minor. There have been a couple of studies looking at particular repos over a few years, but nobody is yet recording broad coverage daily, over the long term 😉
Payback time-frame for research in software engineering
What are the major questions in software engineering that researchers should be trying to answer?
A high level question whose answer is likely to involve life, the universe, and everything is: What is the most cost-effective way to build software systems?
Viewing software engineering research as an attempt to find the answer to a big question mirrors physicists quest for a Grand Unified Theory of how the Universe works.
Physicists have the luxury of studying the Universe at their own convenience, the Universe does not need their input to do a better job.
Software engineering is not like physics. Once a software system has been built, the resources have been invested, and there is no reason to recreate it using a more cost-effective approach (the zero cost of software duplication means that manufacturing cost is the cost of the first version).
Designing and researching new ways of building software systems may be great fun, but the time and money needed to run the realistic experiments needed to evaluate their effectiveness is such that they are unlikely to be run. Searching for more cost-effective software development techniques by paying to run the realistic experiments needed to evaluate them, and waiting for the results to become available, is going to be expensive and time-consuming. A theory is proposed, experiments are run, results are analysed; rinse and repeat until a good-enough cost-effective technique is found. One iteration will take many years, and this iterative process is likely to take many decades.
Very many software systems are being built and maintained, and each of these is an experiment. Data from these ‘experiments’ provides a cost-effective approach to improving existing software engineering practices by studying the existing practices to figure out how they work (or don’t work).
Given the volume of ongoing software development, most of the payback from any research investment is likely to occur in the near future, not decades from now; the evidence shows that source code has a short and lonely existence. Investing for a payback that might occur 30-years from now makes no sense; researchers I talk to often use this time-frame when I ask them about the benefits of their research, i.e., just before they are about to retire. Investing in software engineering research only makes economic sense when it is focused on questions that are expected to start providing payback in, say, 3-5 years.
Who is going to base their research on existing industry practices?
Researching existing practices often involves dealing with people issues, and many researchers in computing departments are not that interested in the people side of software engineering, or rather they are more interested in the computer side.
Algorithm oriented is how I would describe researchers who claim to be studying software engineering. I am frequently told about the potential for huge benefits from the discovery of more efficient algorithms. For many applications, algorithms are now commodities, i.e., they are good enough. Those with a career commitment to studying algorithms have a blinkered view of the likely benefits of their work (most of those I have seen are doing studying incremental improvements, and are very unlikely to make a major break through).
The number of researchers studying what professional developers do, with an aim to improving it, is very small (I am excluding the growing number of fake researchers doing surveys). While I hope there will be a significant growth in numbers, I’m not holding my breadth (at least in the short term; as for the long term, Planck’s experience with quantum mechanics was: “Science advances one funeral at a time”).
Software effort estimation is mostly fake research
Effort estimation is an important component of any project, software or otherwise. While effort estimation is something that everybody in industry is involved with on a regular basis, it is a niche topic in software engineering research. The problem is researcher attitude (e.g., they are unwilling to venture into the wilds of industry), which has stopped them acquiring the estimation data needed to build realistic models. A few intrepid people have risked an assault on their ego and talked to people in industry, the outcome has been, until very recently, a small collection of tiny estimation datasets.
In a research context, the term effort estimation is actually a hang over from the 1970s; effort correction more accurately describes the behavior of most models since the 1990s. In the 1970s, models took various quantities (e.g., estimated lines of code) and calculated an effort estimate. Later models have included an estimate as input to the model, producing a corrected estimate as output. For the sake of appearances, I will use existing terminology.
Which effort estimation datasets do researchers tend to use?
A 2012 review of datasets used for effort estimation using machine learning between 1991-2010, found that the top three were: Desharnias with 24 papers (29%), COCOMO with 19 papers (23%) and ISBSG with 17. A 2019 review of datasets used for effort estimation using machine learning between 1991 and 2017, found the top three to be NASA with 17 papers (23%), the COCOMO data and ISBSG were joint second with 16 papers (21%), and Desharnais was third with 14. The 2012 review included more sources in its search than the 2019 review, and subjectively your author has noticed a greater use of the NASA dataset over the last five years or so.
How large are these datasets that have attracted so many research papers?
The NASA dataset contains 93 rows (that is not a typo, there is no power-of-ten missing), COCOMO 63 rows, Desharnais 81 rows, and ISBSG is licensed by the International Software Benchmarking Standards Group (academics can apply for a limited time use for research purposes, i.e., not pay the $3,000 annual subscription). The China dataset contains 499 rows, and is sometimes used (there is no mention of a supercomputer being required for this amount of data ;-).
Why are researchers involved in software effort estimation feeding tiny datasets from the 1980s-1990s into machine learning algorithms?
Grant money. Research projects are more likely to be funded if they use a trendy technique, and for the last decade machine learning has been the trendiest technique in software engineering research. What data is available to learn from? Those estimation datasets that were flogged to death in the 1990s using non-machine learning techniques, e.g., regression.
Use of machine learning also has the advantage of not needing to know anything about the details of estimating software effort. Everything can be reduced to a discussion of the machine learning algorithms, with performance judged by a chosen error metric. Nobody actually looks at the predicted estimates to discover that the models are essentially producing the same answer, e.g., one learner predicts 43 months, 2 weeks, 4 days, 6 hours, 47 minutes and 11 seconds, while a ‘better’ fitting one predicts 43 months, 2 weeks, 2 days, 6 hours, 27 minutes and 51 seconds.
How many ways are there to do machine learning on datasets containing less than 100 rows?
A paper from 2012 evaluated the possibilities using 9-learners times 10 data-preprocessing options (e.g., log transform or discretization) times 7-error estimation metrics giving 630 possible final models; they picked the top 10 performers.
This 2012 study has not stopped researchers continuing to twiddle away on the option’s nobs available to them; anything to keep the paper mills running.
To quote the authors of one review paper: “Unfortunately, we found that very few papers (including most of our own) paid any attention at all to properties of the data set.”
Agile techniques are widely used these days, and datasets from the 1990s are not applicable. What datasets do researchers use to build Agile effort estimation models?
A 2020 review of Agile development effort estimation found 73 papers. The most popular data set, containing 21 rows, was used by nine papers. Three papers used simulated data! At least some authors were going out and finding data, even if it contains fewer rows than the NASA dataset.
As researchers in business schools have shown, large datasets can be obtained from industry; ISBSG actively solicits data from industry and now has data on 9,500+ projects (as far as I can tell a small amount for each project, but that is still a lot of projects).
Are there any estimates on GitHub? Some Open source projects use JIRA, which includes support for making estimates. Some story point estimates can be found on GitHub, but the actuals are missing.
A handful of researchers have obtained and released estimation datasets containing thousands of rows, e.g., the SiP dataset contains 10,100 rows and the CESAW dataset contains over 40,000 rows. These datasets are generally ignored, perhaps because when presented with lots of real data, researchers have no idea what to do with it.
My new kitchen clock
After several decades of keeping up with the time, since November my kitchen clock has only been showing the correct time every 12-hours. Before I got to buy a new one, I was asked what I wanted to Christmas, and there was money to spend 🙂
Guess what Santa left for me:

The Hermle Ravensburg is a mechanical clock, driven by the pull of gravity on a cylindrical 1kg of Iron (I assume).
Setup requires installing the energy source (i.e., hang the cylinder on one end of a chain), attach clock to a wall where there is enough distance for the cylinder to slowly ‘fall’, set the time, add energy (i.e., pull the chain so the cylinder is at maximum height), and set the pendulum swinging.
The chain is long enough for eight days of running. However, for the clock to be visible from outside my kitchen I had to place it over a shelf, and running time is limited to 2.5 days before energy has to be added.
The swinging pendulum provides the reference beat for the running of the clock. The cycle time of a pendulum swing is proportional to the square root of the distance of the center of mass from the pivot point. There is an adjustment ring for fine-tuning the swing time (just visible below the circular gold disc of the pendulum).
I used my knowledge of physics to wind the center of mass closer to the pivot to reduce the swing time slightly, overlooking the fact that the thread on the adjustment ring moved a smaller bar running through its center (which moved in the opposite direction when I screwed the ring towards the pivot). Physics+mechanical knowledge got it right on the next iteration.
I have had the clock running 1-second per hour too slow, and 1-second per hour too fast. Current thinking is that the pendulum is being slowed slightly when the cylinder passes on its slow fall (by increased air resistance). Yes dear reader, I have not been resetting the initial conditions before making a calibration run 😐
What else remains to learn, before summer heat has to be adjusted for?
While the clock face and hands may be great for attracting buyers, it has serious usability issues when it comes to telling the time. It is difficult to tell the time without paying more attention than normal; without being a few feet from the clock it is not possible to tell the time by just glancing at it. The see though nature of the face, the black-on-black of the end of the hour/minute hands, and the extension of the minute hand in the opposite direction all combine to really confuse the viewer.
A wire cutter solved the minute hand extension issue, and yellow fluorescent paint solved the black-on-black issue. Ravensburg clock with improved user interface, framed by faded paint of its predecessor below:

There is a discrete ting at the end of every hour. This could be slightly louder, and I plan to add some weight to the bell hammer. Had the bell been attached slightly off center, fine volume adjustment would have been possible.
Likelihood of a fault experience when using the Horizon IT system
It looks like the UK Post Office’s Horizon IT system is going to have a significant impact on the prosecution of cases that revolve around the reliability of software systems, at least in the UK. I have discussed the evidence illustrating the fallacy of the belief that “most computer error is either immediately detectable or results from error in the data entered into the machine.” This post discusses what can be learned about the reliability of a program after a fault experience has occurred, or alleged to have occurred in the Horizon legal proceedings.
Sub-postmasters used the Horizon IT system to handle their accounts with the Post Office. In some cases money that sub-postmasters claimed to have transferred did not appear in the Post Office account. The sub-postmasters claimed this was caused by incorrect behavior of the Horizon system, the Post Office claimed it was due to false accounting and prosecuted or fired people and sometimes sued for the ‘missing’ money (which could be in the tens of thousands of pounds); some sub-postmasters received jail time. In 2019 a class action brought by 550 sub-postmasters was settled by the Post Office, and the presiding judge has passed a file to the Director of Public Prosecutions; the Post Office may be charged with instituting and pursuing malicious prosecutions. The courts are working their way through reviewing the cases of the sub-postmasters charged.
How did the Post Office lawyers calculate the likelihood that the missing money was the result of a ‘software bug’?
Horizon trial transcript, day 1, Mr De Garr Robinson acting for the Post Office: “Over the period 2000 to 2018 the Post Office has had on average 13,650 branches. That means that over that period it has had more than 3 million sets of monthly branch accounts. It is nearly 3.1 million but let’s call it 3 million and let’s ignore the fact for the first few years branch accounts were weekly. That doesn’t matter for the purposes of this analysis. Against that background let’s take a substantial bug like the Suspense Account bug which affected 16 branches and had a mean financial impact per branch of £1,000. The chances of that bug affecting any branch is tiny. It is 16 in 3 million, or 1 in 190,000-odd.”
That 3.1 million comes from the calculation: 19-year period times 12 months per year times 13,650 branches.
If we are told that 16 events occurred, and that there are 13,650 branches and 3.1 million transactions, then the likelihood of a particular transaction being involved in one of these events is 1 in 194,512.5. If all branches have the same number of transactions, the likelihood of a particular branch being involved in one of these 16 events is 1 in 853 (13650/16 -> 853); the branch likelihood will be proportional to the number of transactions it performs (ignoring correlation between transactions).
This analysis does not tell us anything about the likelihood that 16 events will occur, and it does not tell us anything about whether these events are the result of a coding mistake or fraud.
We don’t know how many of the known 16 events are due to mistakes in the code and how many are due to fraud. Let’s ask: What is the likelihood of one fault experience occurring in a software system that processes a total of 3.1 million transactions (the number of branches is not really relevant)?
The reply to this question is that it is not possible to calculate an answer, because all the required information is not specified.
A software system is likely to contain some number of coding mistakes, and given the appropriate input, any of these mistakes may produce a fault experience. The information needed to calculate the likelihood of one fault experience occurring is:
- the number of coding mistakes present in the software system,
- for each coding mistake, the probability that an input drawn from the distribution of input values produced by users of the software will produce a fault experience.
Outside of research projects, I don’t know of any anyone who has obtained the information needed to perform this calculation.
The Technical Appendix to Judgment (No.6) “Horizon Issues” states that there were 112 potential occurrences of the Dalmellington issue (paragraph 169), but does not list the number of transactions processed between these ‘issues’ (which would enable a likelihood to be estimated for that one coding mistake).
The analysis of the Post Office expert, Dr Worden, is incorrect in a complicated way (paragraphs 631 through 635). To ‘prove’ that the missing money was very unlikely to be the result of a ‘software bug’, Dr Worden makes a calculation that he claims is the likelihood of a particular branch experiencing a ‘bug’ (he makes the mistake of using the number of known events, not the number of unknown possible events). He overlooks the fact that while the likelihood of a particular branch experiencing an event may be small, the likelihood of any one of the branches experiencing an event is 13,630 times higher. Dr Worden’s creates complication by calculating the number of ‘bugs’ that would have to exist for there to be a 1 in 10 chance of a particular branch experiencing an event (his answer is 50,000), and then points out that 50,000 is such a large number it could not be true.
As an analogy, let’s consider the UK National Lottery, where the chance of winning the Thunderball jackpot is roughly 1 in 8-million per ticket purchased. Let’s say that I bought a ticket and won this week’s jackpot. Using Dr Worden’s argument, the lottery could claim that my chance of winning was so low (1 in 8-million) that I must have created a counterfeit ticket; they could even say that because I did not buy 0.8 million tickets, I did not have a reasonable chance of winning, i.e., a 1 in 10 chance. My chance of winning from one ticket is the same as everybody else who buys one ticket, i.e., 1 in 8-million. If millions of tickets are bought, it is very likely that one of them will win each week. If only, say, 13,650 tickets are bought each week, the likelihood of anybody winning in any week is very low, but eventually somebody will win (perhaps after many years).
The difference between the likelihood of winning the Thunderball jackpot and the likelihood of a Horizon fault experience is that we have enough information to calculate one, but not the other.
The analysis by the defence team produced different numbers, i.e., did not conclude that there was not enough information to perform the calculation.
Is there any way that the information needed to calculate the likelihood of a fault experience occurring?
In theory fuzz testing could be used. In practice this is probably completely impractical. Horizon is a data driven system, and so a copy of the database would need to be used, along with a copy of all the Horizon software. Where is the computer needed to run this software+database? Yes, use of the Post Office computer system would be needed, along with all the necessary passwords.
Perhaps, if we wait long enough, a judge will require that one party make all the software+database+computer+passwords available to the other party.
What impact might my evidence-based book have in 2021?
What impact might the release of my evidence-based software engineering book have on software engineering in 2021?
Lots of people have seen the book. The release triggered a quarter of a million downloads, or rather it getting linked to on Twitter and Hacker News resulted in this quantity of downloads. Looking at the some of the comments on Hacker News, I suspect that many ‘readers’ did not progress much further than looking at the cover. Some have scanned through it expecting to find answers to a question that interests them, but all they found was disconnected results from a scattering of studies, i.e., the current state of the field.
The evidence that source code has a short and lonely existence is a gift to those seeking to save time/money by employing a quick and dirty approach to software development. Yes, there are some applications where a quick and dirty iterative approach is not a good idea (iterative as in, if we make enough money there will be a version 2), the software controlling aircraft landing wheels being an obvious example (if the wheels don’t deploy, telling the pilot to fly to another airport to see if they work there is not really an option).
There will be a few researchers who pick up an idea from something in the book, and run with it; I have had a couple of emails along this line, mostly from just starting out PhD students. It would be naive to think that lots of researchers will make any significant changes to their existing views on software engineering. Planck was correct to say that science advances one funeral at a time.
I’m hoping that the book will produce a significant improvement in the primitive statistical techniques currently used by many software researchers. At the moment some form of Wilcoxon test, invented in 1945, is the level of statistical sophistication wielded in most software engineering papers (that do any data analysis).
Software engineering research has the feeling of being a disjoint collection of results, and I’m hoping that a few people will be interested in starting to join the dots, i.e., making connections between findings from different studies. There are likely to be a limited number of major dot joinings, and so only a few dedicated people are needed to make it happen. Why hasn’t this happened yet? I think that many academics in computing departments are lifestyle researchers, moving from one project to the next, enjoying the lifestyle, with little interest in any research results once the grant money runs out (apart from trying to get others to cite it). Why do I think this? I have emailed many researchers information about the patterns I have found in the data they sent me, and a common response is almost completely disinterest (some were interested) in any connections to other work.
What impact do you think ‘all’ the evidence presented will have?
Source code discovery, skipping over the legal complications
The 2020 US elections introduced the issue of source code discovery, in legal cases, to a wider audience. People wanted to (and still do) check that the software used to register and count votes works as intended, but the companies who wrote the software wouldn’t make it available and the courts did not compel them to do so.
I was surprised to see that there is even a section on “Transfer of or access to source code” in the EU-UK trade and cooperation agreement, agreed on Christmas Eve.
I have many years of experience in discovering problems in the source code of programs I did not write. This experience derives from my time as a compiler implementer (e.g., a big customer is being held up by a serious issue in their application, and the compiler is being blamed), and as a static analysis tool vendor (e.g., managers want to know about what serious mistakes may exist in the code of their products). In all cases those involved wanted me there, I could talk to some of those involved in developing the code, and there were known problems with the code. In court cases, the defence does not want the prosecution looking at the code, and I assume that all conversations with the people who wrote the code goes via the lawyers. I have intentionally stayed away from this kind of work, so my practical experience of working on legal discovery is zero.
The most common reason companies give for not wanting to make their source code available is that it contains trade-secrets (they can hardly say that it’s because they don’t want any mistakes in the code to be discovered).
What kind of trade-secrets might source code contain? Most code is very dull, and for some programs the only trade-secret is that if you put in the implementation effort, the obvious way of doing things works, i.e., the secret sauce promoted by the marketing department is all smoke and mirrors (I have had senior management, who have probably never seen the code, tell me about the wondrous properties of their code, which I had seen and knew that nothing special was present).
Comments may detail embarrassing facts, aka trade-secrets. Sometimes the code interfaces to a proprietary interface format that the company wants to keep secret, or uses some formula that required a lot of R&D (management gets very upset when told that ‘secret’ formula can be reverse engineered from the executable code).
Why does a legal team want access to source code?
If the purpose is to check specific functionality, then reading the source code is probably the fastest technique. For instance, checking whether a particular set of input values can cause a specific behavior to occur, or tracing through the logic to understand the circumstances under which a particular behavior occurs, or in software patent litigation checking what algorithms or formula are being used (this is where trade-secret claims appear to be valid).
If the purpose is a fishing expedition looking for possible incorrect behaviors, having the source code is probably not that useful. The quantity of source contained in modern applications can be huge, e.g., tens to hundreds of thousands of lines.
In ancient times (i.e., the 1970s and 1980s) programs were short (because most computers had tiny amounts of memory, compared to post-2000), and it was practical to read the source to understand a program. Customer demand for more features, and the fact that greater storage capacity removed the need to spend time reducing code size, means that source code ballooned. The following plot shows the lines of code contained in the collected algorithms of the Transactions on Mathematical Software, the red line is a fitted regression model of the form:  (code+data):
(code+data):
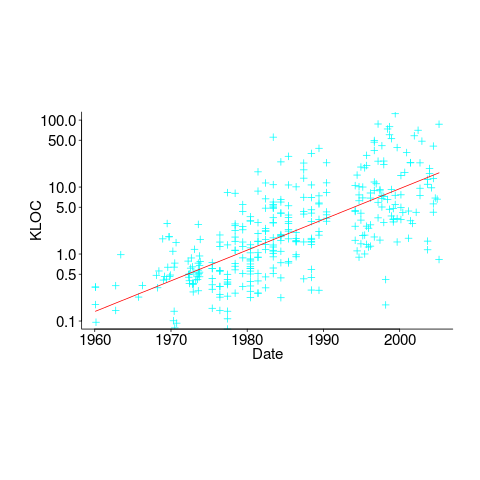
How, by reading the source code, does anybody find mistakes in a 10+ thousand line program? If the program only occasionally misbehaves, finding a coding mistake by reading the source is likely to be very very time-consuming, i.e, months. Work it out yourself: 10K lines of code is around 200 pages. How long would it take you to remember all the details and their interdependencies of a detailed 200-page technical discussion well enough to spot an inconsistency likely to cause a fault experience? And, yes, the source may very well be provided as a printout, or as a pdf on a protected memory stick.
From my limited reading of accounts of software discovery, the time available to study the code may be just days or maybe a week or two.
Reading large quantities of code, to discover possible coding mistakes, are an inefficient use of human time resources. Some form of analysis tool might help. Static analysis tools are one option; these cost money and might not be available for the language or dialect in which the source is written (there are some good tools for C because it has been around so long and is widely used).
Character assassination, or guilt by innuendo is another approach; the code just cannot be trusted to behave in a reasonable manner (this approach is regularly used in the software business). Software metrics are deployed to give the impression that it is likely that mistakes exist, without specifying specific mistakes in the code, e.g., this metric is much higher than is considered reasonable. Where did these reasonable values come from? Someone, somewhere said something, the Moon aligned with Mars and these values became accepted ‘wisdom’ (no, reality is not allowed to intrude; the case is made by arguing from authority). McCabe’s complexity metric is a favorite, and I have written how use of this metric is essentially accounting fraud (I have had emails from several people who are very unhappy about me saying this). Halstead’s metrics are another favorite, and at least Halstead and others at the time did some empirical analysis (the results showed how ineffective the metrics were; the metrics don’t calculate the quantities claimed).
The software development process used to create software is another popular means of character assassination. People seem to take comfort in the idea that software was created using a defined process, and use of ad-hoc methods provides an easy target for ridicule. Some processes work because they include lots of testing, and doing lots of testing will of course improve reliability. I have seen development groups use a process and fail to produce reliable software, and I have seen ad-hoc methods produce reliable software.
From what I can tell, some expert witnesses are chosen for their ability to project an air of authority and having impressive sounding credentials, not for their hands-on ability to dissect code. In other words, just the kind of person needed for a legal strategy based on character assassination, or guilt by innuendo.
What is the most cost-effective way of finding reliability problems in software built from 10k+ lines of code? My money is on fuzz testing, a term that should send shivers down the spine of a defense team. Source code is not required, and the output is a list of real fault experiences. There are a few catches: 1) the software probably to be run in the cloud (perhaps the only cost/time effective way of running the many thousands of tests), and the defense is going to object over licensing issues (they don’t want the code fuzzed), 2) having lots of test harnesses interacting with a central database is likely to be problematic, 3) support for emulating embedded cpus, even commonly used ones like the Z80, is currently poor (this is a rapidly evolving area, so check current status).
Fuzzing can also be used to estimate the numbers of so-far undetected coding mistakes.
Many coding mistakes are not immediately detectable
Earlier this week I was reading a paper discussing one aspect of the legal fallout around the UK Post-Office’s Horizon IT system, and was surprised to read the view that the Law Commission’s Evidence in Criminal Proceedings Hearsay and Related Topics were citing on the subject of computer evidence (page 204): “most computer error is either immediately detectable or results from error in the data entered into the machine”.
What? Do I need to waste any time explaining why this is nonsense? It’s obvious nonsense to anybody working in software development, but this view is being expressed in law related documents; what do lawyers know about software development.
Sometimes fallacies become accepted as fact, and a lot of effort is required to expunge them from cultural folklore. Regular readers of this blog will have seen some of my posts on long-standing fallacies in software engineering. It’s worth collecting together some primary evidence that most software mistakes are not immediately detectable.
A paper by Professor Tapper of Oxford University is cited as the source (yes, Oxford, home of mathematical orgasms in software engineering). Tapper’s job title is Reader in Law, and on page 248 he does say: “This seems quite extraordinarily lax, given that most computer error is either immediately detectable or results from error in the data entered into the machine.” So this is not a case of his words being misinterpreted or taken out of context.
Detecting many computer errors is resource intensive, both in elapsed time, manpower and compute time. The following general summary provides some of the evidence for this assertion.
Two events need to occur for a fault experience to occur when running software:
- a mistake has been made when writing the source code. Mistakes include: a misunderstanding of what the behavior should be, using an algorithm that does not have the desired behavior, or a typo,
- the program processes input values that interact with a coding mistake in a way that produces a fault experience.
That people can make different mistakes is general knowledge. It is my experience that people underestimate the variability of the range of values that are presented as inputs to a program.
A study by Nagel and Skrivan shows how variability of input values results in fault being experienced at different time, and that different people make different coding mistakes. The study had three experienced developers independently implement the same specification. Each of these three implementations was then tested, multiple times. The iteration sequence was: 1) run program until fault experienced, 2) fix fault, 3) if less than five faults experienced, goto step (1). This process was repeated 50 times, always starting with the original (uncorrected) implementation; the replications varied this, along with the number of inputs used.
How many input values needed to be processed, on average, before a particular fault is experienced? The plot below (code+data) shows the numbers of inputs processed, by one of the implementations, before individual faults were experienced, over 50 runs (sorted by number of inputs needed before the fault was experienced):
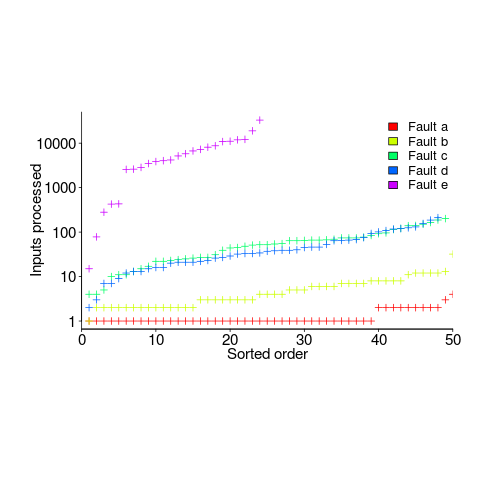
The plot illustrates that some coding mistakes are more likely to produce a fault experience than others (because they are more likely to interact with input values in a way that generates a fault experience), and it also shows how the number of inputs values processed before a particular fault is experienced varies between coding mistakes.
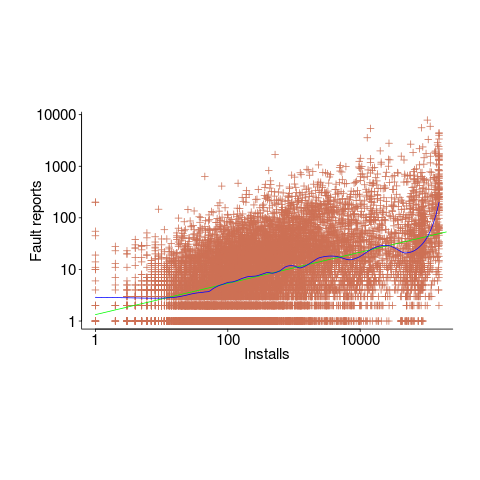
Real-world evidence of the impact of user input on reported faults is provided by the Ultimate Debian Database, which provides information on the number of reported faults and the number of installs for 14,565 packages. The plot below shows how the number of reported faults increases with the number of times a package has been installed; one interpretation is that with more installs there is a wider variety of input values (increasing the likelihood of a fault experience), another is that with more installs there is a larger pool of people available to report a fault experience. Green line is a fitted power law,  , blue line is a fitted loess model.
, blue line is a fitted loess model.
The source containing a mistake may be executed without a fault being experienced; reasons for this include:
- the input values don’t result in the incorrect code behaving differently from the correct code. For instance, given the made-up incorrect code
if (x < 8)(i.e.,8was typed rather than7), the comparison only produces behavior that differs from the correct code whenxhas the value7, - the input values result in the incorrect code behaving differently than the correct code, but the subsequent path through the code produces the intended external behavior.
Some of the studies that have investigated the program behavior after a mistake has deliberately been introduced include:
- checking the later behavior of a program after modifying the value of a variable in various parts of the source; the results found that some parts of a program were more susceptible to behavioral modification (i.e., runtime behavior changed) than others (i.e., runtime behavior not change),
- checking whether a program compiles and if its runtime behavior is unchanged after random changes to its source code (in this study, short programs written in 10 different languages were used),
- 80% of radiation induced bit-flips have been found to have no externally detectable effect on program behavior.
What are the economic costs and benefits of finding and fixing coding mistakes before shipping vs. waiting to fix just those faults reported by customers?
Checking that a software system exhibits the intended behavior takes time and money, and the organization involved may not be receiving any benefit from its investment until the system starts being used.
In some applications the cost of a fault experience is very high (e.g., lowering the landing gear on a commercial aircraft), and it is cost-effective to make a large investment in gaining a high degree of confidence that the software behaves as expected.
In a changing commercial world software systems can become out of date, or superseded by new products. Given the lifetime of a typical system, it is often cost-effective to ship a system expected to contain many coding mistakes, provided the mistakes are unlikely to be executed by typical customer input in a way that produces a fault experience.
Beta testing provides selected customers with an early version of a new release. The benefit to the software vendor is targeted information about remaining coding mistakes that need to be fixed to reduce customer fault experiences, and the benefit to the customer is checking compatibility of their existing work practices with the new release (also, some people enjoy being able to brag about being a beta tester).
- One study found that source containing a coding mistake was less likely to be changed due to fixing the mistake than changed for other reasons (that had the effect of causing the mistake to disappear),
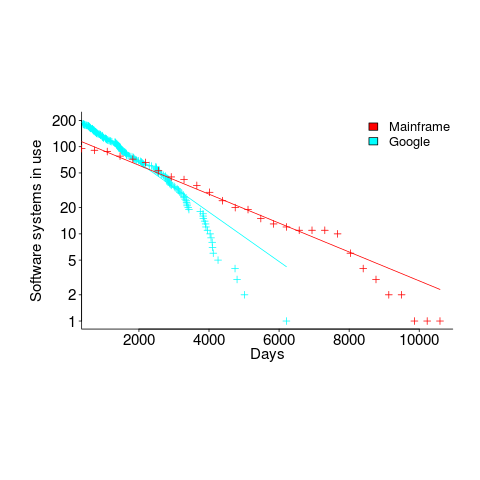
- Software systems don't live forever; systems are replaced or cease being used. The plot below shows the lifetime of 202 Google applications (half-life 2.9 years) and 95 Japanese mainframe applications from the 1990s (half-life 5 years; code+data).
Not only are most coding mistakes not immediately detectable, there may be sound economic reasons for not investing in detecting many of them.
Survival rate of WG21 meeting attendance
WG21, the C++ Standards committee, has a very active membership, with lots of people attending the regular meetings; there are three or four meetings a year, with an average meeting attendance of 67 (between 2004 and 2016).
The minutes of WG21 meetings list those who attend, and a while ago I downloaded these for meetings between 2004 and 2016. Last night I scraped the data and cleaned it up (or at least the attendee names).
WG21 had its first meeting in 1992, and continues to have meetings (eleven physical meetings at the time or writing). This means the data is both left and right censored; known as interval censored. Some people will have attended many meetings before the scraped data starts, and some people listed in the data may not have attended another meeting since.
What can we say about the survival rate of a person being a WG21 attendee in the future, e.g., what is the probability they will attend another meeting?
Most regular attendees are likely to miss a meeting every now and again (six people attended all 30 meetings in the dataset, with 22 attending more than 25), and I assumed that anybody who attended a meeting after 1 January 2015 was still attending. Various techniques are available to estimate the likelihood that known attendees were attending meetings prior to those in the dataset (I’m going with what ever R’s survival package does). The default behavior of R’s Surv function is to handle right censoring, the common case. Extra arguments are needed to handle interval censored data, and I think I got these right (I had to cast a logical argument to numeric for some reason; see code+data).
The survival curves in days since 1 Jan 2004, and meetings based on the first meeting in 2004, with 95% confidence bounds, look like this:
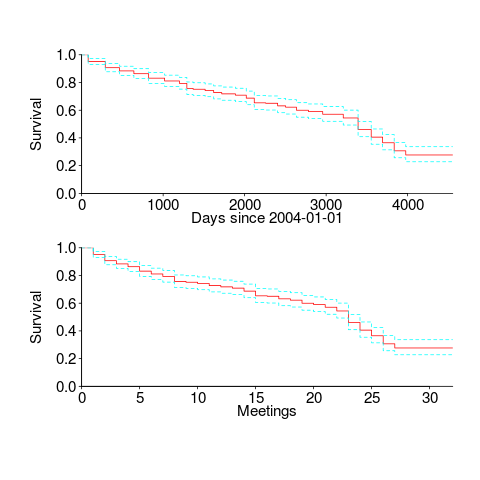
I was expecting a sharper initial reduction, and perhaps wider confidence bounds. Of the 374 people listed as attending a meeting, 177 (47%) only appear once and 36 (10%) appear twice; there is a long tail, with 1.6% appearing at every meeting. But what do I know, my experience of interval censored data is rather limited.
The half-life of attendance is 9 to 10 years, suspiciously close to the interval of the data. Perhaps a reader will scrape the minutes from earlier meetings 🙂
Within the time interval of the data, new revisions of the C++ standard occurred in 20072011 and 2014; there had also been a new release in 2003, and one was being worked on for 2017. I know some people stop attending meetings after a major milestone, such as a new standard being published. A fancier analysis would investigate the impact of standards being published on meeting attendance.
People also change jobs. Do WG21 attendees change jobs to ones that also require/allow them to attend WG21 meetings? The attendee’s company is often listed in the minutes (and is in the data). Something for intrepid readers to investigate.
Christmas books for 2020
A very late post on the interesting books I read this year (only one of which was actually published in 2020). As always the list is short because I did not read many books and/or there is lots of nonsense out there, but this year I have the new excuses of not being able to spend much time on trains and having my own book to finally complete.
I have already reviewed The Weirdest People in the World: How the West Became Psychologically Peculiar and Particularly Prosperous, and it is the must-read of 2020 (after my book, of course :-).
The True Believer by Eric Hoffer. This small, short book provides lots of interesting insights into the motivational factors involved in joining/following/leaving mass movements. Possible connections to software engineering might appear somewhat tenuous, but bits and pieces keep bouncing around my head. There are clearer connections to movements going mainstream this year.
The following two books came from asking what-if questions about the future of software engineering. The books I read suggesting utopian futures did not ring true.
“Money and Motivation: Analysis of Incentives in Industry” by William Whyte provides lots of first-hand experience of worker motivation on the shop floor, along with worker response to management incentives (from the pre-automation 1940s and 1950s). Developer productivity is a common theme in discussions I have around evidence-based software engineering, and this book illustrates the tangled mess that occurs when management and worker aims are not aligned. It is easy to imagine the factory-floor events described playing out in web design companies, with some web-page metric used by management as a proxy for developer productivity.
Labor and Monopoly Capital: The Degradation of Work in the Twentieth Century by Harry Braverman, to quote from Wikipedia, is an “… examination the nature of ‘skill’ and the finding that there was a decline in the use of skilled labor as a result of managerial strategies of workplace control.” It may also have discussed management assault of blue-collar labor under capitalism, but I skipped the obviously political stuff. Management do want to deskill software development, if only because it makes it easier to find staff, with the added benefit that the larger pool of less skilled staff increases management control, e.g., low skilled developers knowing they can be easily replaced.
Recent Comments