Estimation accuracy in the (building|road) construction industry
Lots of people complain about software development taking longer than estimated. Are estimates in other industries more accurate, and do they contain patterns similar to those seen in software task estimates?
Readers will probably not be surprised to learn that obtaining estimate/actual data is as hard for other industries as it is for software.
Software engineering sometimes gets compared with building construction, in the sense that building construction is perceived as being straightforward and predictable. My tiny experience with building construction is that it is not as straightforward and predictable as outsiders think, a view echoed by the few people in the building industry I have spoken to.
I have found two building datasets, the supplementary material from: Forecasting the Project Duration Average and Standard Deviation from Deterministic Schedule Information (the 101 rows also include some service projects), and Ballesteros-Pérez kindly sent me the data for Duration and Cost Variability of Construction Activities: An Empirical Study which included 746 rows of road construction estimate/actual data from an unknown source. This data is for large projects, where those involved had to bid to get the work.
The following plot reminds us of how effort vs actual often looks like for short software tasks; it includes a fitted regression model and prediction intervals at one standard deviation (68.3%) and two standard deviations (95%); the faint grey line shows Estimate == Actual (post discussing the analysis and linking to code+data):
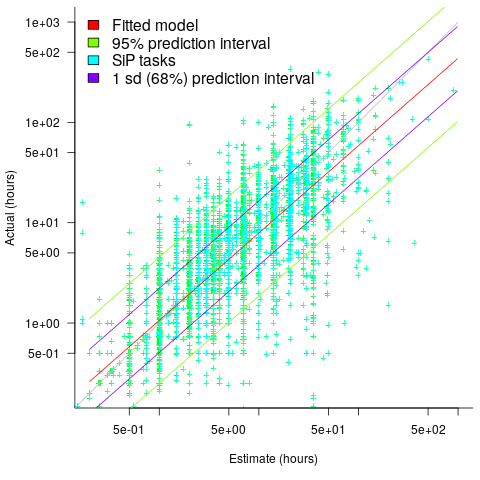
The data in the above plot is for small tasks, which did not involve bidding for the work.
The following plot shows estimated vs actual duration for 101 construction projects. The red line has the form:  , i.e., average estimate is 9% lower than actual duration (blue line shows
, i.e., average estimate is 9% lower than actual duration (blue line shows  ; code+data).
; code+data).
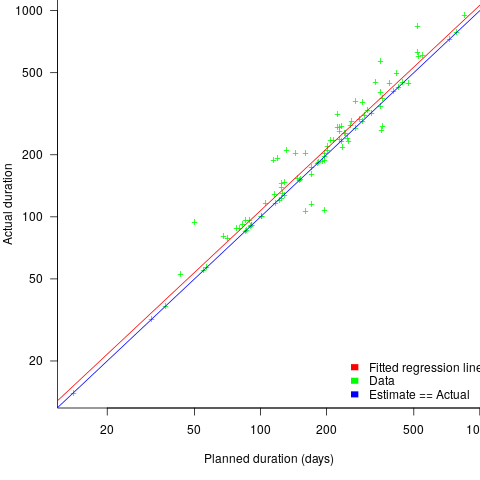
The obvious differences are that the fitted line shows consistent underestimation (hardly surprising when bidding for work; 16% of estimates are greater than the actual), that the variance of project estimate/actual about the line is much smaller for building construction, and that the red/blue lines are essentially parallel (the exponent for software tasks is consistently around 0.85, rather than 1)
The following plot shows estimated vs actual for 746 road construction projects. The red line has the form:  , i.e., average estimate is 24% lower than actual duration (blue line shows ; code+data):
, i.e., average estimate is 24% lower than actual duration (blue line shows ; code+data):
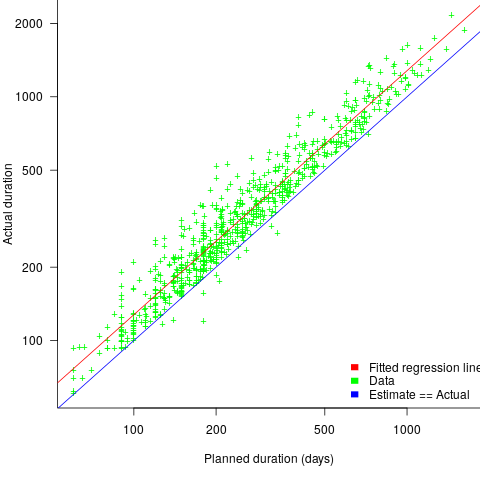
Again there is a consistent average underestimate (project bidding was via an auction process), the red/blue lines are essentially parallel, and while the estimate/actual variance is larger than for building construction only 1.5% estimates are greater than the actual.
Consistent underestimating is not surprising for external projects awarded via a bidding process.
The unpredicted differences are the much smaller estimate/actual variance (compared to software), and the fitted line running parallel to .
Evolution of the DORA metrics
There is a growing buzz around the DORA metrics. Where did the DORA metrics come from, what are they, and are they useful?
The company DevOps Research and Assessment LLC (DORA) was founded by Nicole Forsgren, Jez Humble, and Gene Kim in 2016, and acquired by Google in 2018. DevOps is a role that combines software development (Dev) and IT operations (Ops).
The original ideas behind the DORA metrics are described in the 2015 paper DevOps: Profiles in ITSM Performance and Contributing Factors, by Forsgren and Humble. The more well known Accelerate book, published in 2018, is an evangelistic reworking of the material, plus some business platitudes extolling the benefits of using a lean process.
The 2015 paper approaches the metric selection process from the perspective of reducing business costs, and uses a data driven approach. This is how metric selection should be done, and for the first seven or eight pages I was cheering the authors on. The validity of a data driven approaches depends on the reliability of the data and its applicability to the questions being addressed. I don’t think that the reliability of the data used is sufficient to support the conclusions being drawn from it. The data used is the survey results behind the Puppet Labs 2015 State of DevOps Report; the 2018 book included data from the 2016 and 2017 State of DevOps reports.
Between 2015-2018, DORA is more a way of doing DevOps than a collection of metrics to calculate. The theory is based on ideas from the Economic Order Quantity model; this model is used in inventory management to calculate the number of items that should be held in stock, to meet production demand, such that stock holding costs plus item reordering costs are minimised (when the number of items in stock falls below some value, there is an optimum number of items to reorder to replenish stocks).
The DORA mapping of the Economic Order Quantity model to DevOps employs a rather liberal interpretation of the concepts involved. There are three fundamental variables:
- Batch size: the quantity of additions, modifications and deletions of anything that could have an effect on IT services, e.g., changes to code or configuration files,
- Holding cost: the lost opportunity cost of not deploying work that has been done, e.g., lost business because a feature is not available or waste because an efficiency improvement is not used. Cognitive capitalism also has the lost opportunity cost of not learning about the impact of an update on the ecosystem,
- Transaction cost: the cost of building, testing and deploying to production a completed batch.
The aim is to minimise  .
.
So far, so good and reasonable.
Now the details; how do we measure batch size, holding cost and transaction cost?
DORA does not measure these quantities (the paper points out that deployment frequency could be treated as a proxy for batch size, in that as deployment frequency goes to infinity batch size goes to zero). The terms holding cost and transaction cost do not appear in the 2018 book.
Having mapped Economic Order Quantity variables to software, the 2015 paper pivots and maps these variables to a Lean manufacturing process (the 2018 book focuses on Lean). Batch size is now deployment frequency, and higher is better.
Ok, let’s follow the pivoted analysis of Lean ideas applied to software. The 2015 paper uses cluster analysis to find patterns in the 2015 State of DevOps survey data. I have not seen any of the data, or even the questions asked; the description of the analysis is rather sketchy (I imagine it is similar to that used by Forsgren in her PhD thesis on a different dataset). The report published by Puppet Labs analyses the data using linear regression and partial least squares.
Three IT performance profiles are characterized (High, Medium and Low). Why three and not, say, four or five? The papers simply says that three ’emerged’.
The analysis of the Puppet Labs 2015 survey data (6k+ responses) essentially takes the form of listing differences in values of various characteristics between High/Medium/Low teams; responses came from “technical professionals of all specialities involved in DevOps”. The analysis in the 2018 book discussed some of the between year differences.
My experience of asking hundreds of people for data is that most don’t have any. I suspect this is true of those who answered the Puppet Labs surveys, and that answers are guestimates.
The fact that the accuracy of analysis of the survey data is poor does not really matter, because DORA pivots again.
This pivot switches to organizational metrics (from team metrics), becomes purely production focused (very appropriate for DevOps), introduces an Elite profile, and focuses on four key metrics; the following is adapted from Google:
- Deployment Frequency: How often an organization successfully releases to production,
- Lead Time for Changes: The amount of time it takes a commit to get into production,
- Change Failure Rate: The percentage of deployments causing a failure in production,
- Mean time to repair (MTTR): How long it takes an organization to recover from a failure in production.
Are these four metrics useful?
To somebody with zero DevOps experience (i.e., me) they look useful. The few DevOps people I have spoken to are talking about them but not using them (not least because they don’t have the data required).
The characteristics of the Elite/High/Medium/Low profiles reflects Google’s DevOps business interests. Companies offering an online service at a national scale want to quickly respond to customer demand, continuously deploy, and quickly recover from service outages.
There are companies where it makes business sense for DevOps deployments to occur much less frequently than at Google. I also know companies who would love to have deployment rates within an order of magnitude of Google’s, but cannot even get close without a significant restructuring of their build and deployment infrastructure.
Extracting numbers from a stacked density plot
A month or so ago, I found a graph showing a percentage of PCs having a given range of memory installed, between March 2000 and April 2020, on a TechTalk page of PC Matic; it had the form of a stacked density plot. This kind of installed memory data is rare, how could I get the underlying values (a previous post covers extracting data from a heatmap)?
The plot below is the image on PC Matic’s site:
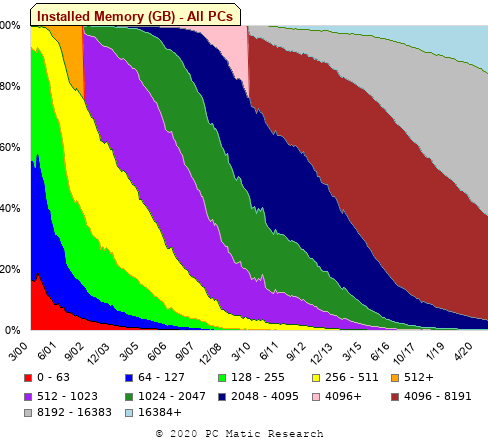
The change of colors creates a distinct boundary between different memory capacity ranges, and it ought to be possible to find the y-axis location of each color change, for a given x-axis location (with location measured in pixels).
The image was a png file, I loaded R’s png package, and a call to readPNG created the required 2-D array of pixel information.
library("png")
img=readPNG("../rc_mem_memrange_all.png") |
Next, the horizontal and vertical pixel boundaries of the colored data needed to be found. The rectangle of data is surrounded by white pixels. The number of white pixels (actually all ones corresponding to the RGB values) along each horizontal and vertical line dramatically drops at the data image boundary. The following code counts the number of col points in each horizontal line (used to find the y-axis bounds):
horizontal_line=function(a_img, col)
{
lines_col=sapply(1:n_lines, function(X) sum((a_img[X, , 1]==col[1]) &
(a_img[X, , 2]==col[2]) &
(a_img[X, , 3]==col[3]))
)
return(lines_col)
}
white=c(1, 1, 1)
n_cols=dim(img)[2]
# Find where fraction of white points on a line changes dramatically
white_horiz=horizontal_line(img, white)
# handle when upper boundary is missing
ylim=c(0, which(abs(diff(white_horiz/n_cols)) > 0.5))
ylim=ylim[2:3] |
Next, for each vertical column of pixels, at each x-axis pixel location, the sought after y value occurs at the change of color boundary in the corresponding vertical column. This boundary includes a 1-pixel wide separation color, which creates a run of 2 or 3 consecutive pixel color changes.
The color change is easily found using the duplicated function.
# Return y position of vertical color changes at x_pos
y_col_change=function(x_pos)
{
# Good enough technique to generate a unique value per RGB color
col_change=which(!duplicated(img[y_range, x_pos, 1]+
10*img[y_range, x_pos, 2]+
100*img[y_range, x_pos, 3]))
# Handle a 1-pixel separation line between colors.
# Diff is used to find these consecutive sequences.
y_change=c(1, col_change[which(diff(col_change) > 1)+1])
# Always return a vector containing max_vals elements.
return(c(y_change, rep(NA, max_vals-length(y_change))))
} |
Next, we need to group together the sequence of points that delimit a particular boundary. The points along the same boundary are all associated with the same two colors, i.e., the ones below/above the boundary (plus a possible boundary color).
The plot below shows all the detected boundary points, in black, overwritten by colors denoting the points associated with the same below/above colors (code):
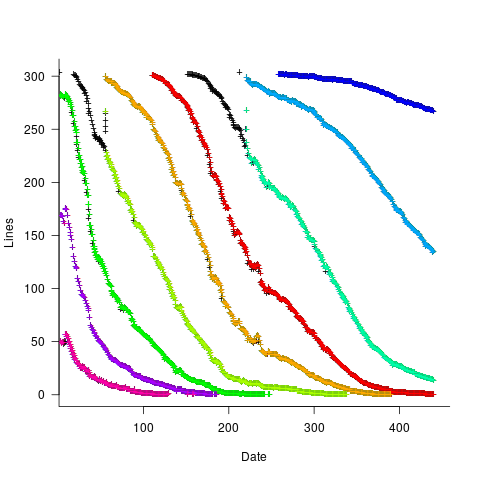
The visible black pluses show that the algorithm is not perfect. The few points here and there can be ignored, but the two blocks at the top of the original image have thrown a spanner in the works for some range of points (this could be fixed manually, or perhaps it is possible to tweak the color extraction formula to work around them).
How well does this approach work with other stacked density plots? No idea, but I am on the lookout for other interesting examples.
Multi-state survival modeling of a Jira issues snapshot
Work items in a formal development process progress through a series of stages, e.g., starting at Open, perhaps moving to Withdrawn or Merged with another item, eventually reaching Development, and finishing at Done (with a few being Reopened, i.e., moving back to the start of the process).
This process can be modelled as a Markov chain, provided data on each stage of the process is available, for each work item; allowing values such as average time spent in each state and transition probabilities to be calculated.
The Jira issue/task/bug/etc tracking system has an option to generate a snapshot of the current status of work items in the system. The snapshot information on each item includes: start-date, current-state, time-in-state, date-of-snapshot.
If we assume that all work items pass through the same sequence of states, from Open to Done, then the snapshot contains enough information to build a multi-state survival model.
The key information is time-in-state, which can be used to calculate the date/time when an item transitioned from its previous state to its current state, providing a required link between all states.
How is a multi-state survival model better than creating a distinct survival model for each state?
The calculation of each state in a multi-state model takes into account information from the succeeding state, i.e., the time-in-state value in the succeeding state provides timing (from the Start state) on when a work item transitioned from its previous state. While this information could be added to each of the distinct models, it’s simpler to bundle everything together in one model.
A data analysis article by Robert Krasinski linked to the data used 🙂 The data does not include a description of the columns, but most of the names appear self-explanatory (I have no idea what key might be). Each of the 3,761 rows includes a story-point estimate, team-id, and a tag name for the work item.
Building a multi-state model provides a means for estimating the impact of team-id and story-points on time-in-state. I would expect items with higher story-point estimates to spend longer in Development, but I’m not sure how much difference there will be on other states.
I pruned the 22 states present in the data down to the following sequence of 13. Items might be Withdrawn or Merged with others items at any time, but I’m keeping things simple. These two states should also be absorbing in that there is no exit from them, I faked this by adding a transition to Done.
Open
Withdrawn
Merged
Backlog
In Analysis
In Refinement
Ready for Development
In Development
Code Review
Ready for Test
In Testing
Ready for Signoff
Done |
I’m familiar with building survival models, but have only ever built a couple of multi-state survival models. R supports several packages, which is the best one to use for this minimalist multi-state dataset?
The msm package is very much into state transition probabilities, or at least that is the impression I got from reading its manual. flexsurv and mstate are other packages I looked at. I decided to stay with the survival package, the default for simpler problems; the manuals contained lots of examples and some of them appeared similar to my problem.
Each row of work item information in the Jira snapshot looks something like the following:
X daysInStatus start status obsdate 1 0.53 2020-05-12 In Development 2020-05-18 |
This work item transitioned from state Ready for Development at time  to state In Development at time
to state In Development at time  , and was still in state In Development at time
, and was still in state In Development at time  (when the snapshot was taken); the
(when the snapshot was taken); the  is a small interval used to separate the states.
is a small interval used to separate the states.
As is often the case with R packages, most of the work went into figuring out how to call the library functions with the data formatted just so, plus of course my own misunderstandings. Once the data was cleaned and process, the analysis was one line of code plus one to print the results; for instance, to estimate the mean time in each state by story-point value (code+data):
sp_fit=survfit(Surv(tstop-tstart, state) ~ sp, data=merged_status) print(sp_fit) |
Given the uncertainties in this model building process, I’m not going to discuss the results. This post is a proof of concept, which others can apply when the sequence of states is known with some degree of confidence, and good reasons for noise in the data are available.
Estimating quantities from several hundred to several thousand
How much influence do anchoring and financial incentives have on estimation accuracy?
Anchoring is a cognitive bias which occurs when a decision is influenced by irrelevant information. For instance, a study by John Horton asked 196 subjects to estimate the number of dots in a displayed image, but before providing their estimate subjects had to specify whether they thought the number of dots was higher/lower than a number also displayed on-screen (this was randomly generated for each subject).
How many dots do you estimate appear in the plot below?

Estimates are often round numbers, and 46% of dot estimates had the form of a round number. The plot below shows the anchor value seen by each subject and their corresponding estimate of the number of dots (the image always contained five hundred dots, like the one above), with round number estimates in same color rows (e.g., 250, 300, 500, 600; code+data):
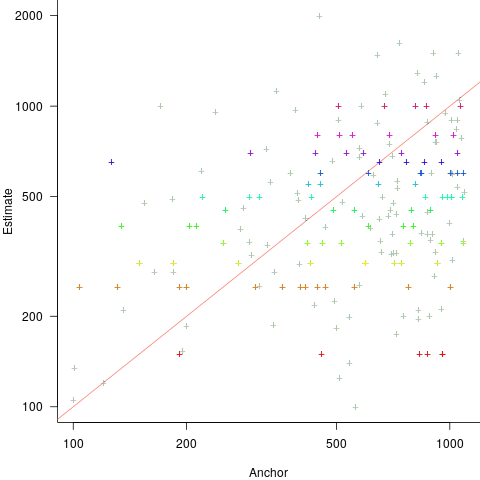
How much influence does the anchor value have on the estimated number of dots?
One way of measuring the anchor’s influence is to model the estimate based on the anchor value. The fitted regression equation  explains 11% of the variance in the data. If the higher/lower choice is included the model, 44% of the variance is explained; higher equation is:
explains 11% of the variance in the data. If the higher/lower choice is included the model, 44% of the variance is explained; higher equation is:  and lower equation is:
and lower equation is:  (a multiplicative model has a similar goodness of fit), i.e., the anchor has three-times the impact when it is thought to be an underestimate.
(a multiplicative model has a similar goodness of fit), i.e., the anchor has three-times the impact when it is thought to be an underestimate.
How much would estimation accuracy improve if subjects’ were given the option of being rewarded for more accurate answers, and no anchor is present?
A second experiment offered subjects the choice of either an unconditional payment of $2.50 or a payment of $5.00 if their answer was in the top 50% of estimates made (labelled as the risk condition).
The 196 subjects saw up to seven images (65 only saw one), with the number of dots varying from 310 to 8,200. The plot below shows actual number of dots against estimated dots, for all subjects; blue/green line shows  , and red line shows the fitted regression model
, and red line shows the fitted regression model  (code+data):
(code+data):
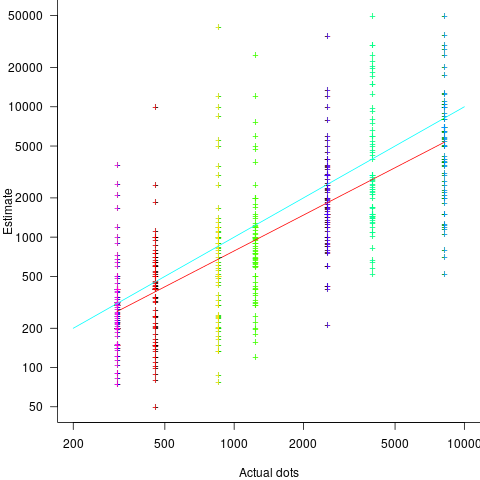
The variance in the estimated number of dots is very high and increases with increasing actual dot count, however, this behavior is consistent with the increasing variance seen for images containing under 100 dots.
Estimates were not more accurate in those cases where subjects chose the risk payment option. This is not surprising, performance improvements require feedback, and subjects were not given any feedback on the accuracy of their estimates.
Of the 86 subjects estimating dots in three or more images, 44% always estimated low and 16% always high. Subjects always estimating low/high also occurs in software task estimates.
Estimation patterns previously discussed on this blog have involved estimated values below 100. This post has investigated patterns in estimates ranging from several hundred to several thousand. Patterns seen include extensive use of round numbers and increasing estimate variance with increasing actual value; all seen in previous posts.
Most percentages are more than half
Most developers think …
Most editors …
Most programs …
Linguistically most is a quantifier (it’s a proportional quantifier); a word-phrase used to convey information about the number of something, e.g., all, any, lots of, more than half, most, some.
Studies of most have often compared and contrasted it with the phrase more than half; findings include: most has an upper bound (i.e., not all), and more than half has a lower bound (but no upper bound).
A corpus analysis of most (432,830 occurrences) and more than half (4,857 occurrences) found noticeable usage differences. Perhaps the study’s most interesting finding, from a software engineering perspective, was that most tended to be applied to vague and uncountable domains (i.e., there was no expectation that the population of items could be counted), while uses of more than half almost always had a ‘survey results’ interpretation (e.g., supporting data cited as collaboration for 80% of occurrences; uses of most cited data for 19% of occurrences).
Readers will be familiar with software related claims containing the most qualifier, which are actually opinions that are not grounded in substantive numeric data.
When most is used in a numeric based context, what percentage (of a population) is considered to be most (of the population)?
When deciding how to describe a proportion, a writer has the choice of using more than half, most, or another qualifier. Corpus based studies find that the distribution of most has a higher average percentage value than more than half (both are left skewed, with most peaking around 80-85%).
When asked to decide whether a phrase using a qualifier is true/false, with respect to background information (e.g., Given that 55% of the birlers are enciad, is it true that: Most of the birlers are enciad?), do people treat most and more than half as being equivalent?
A study by Denić and Szymanik addressed this question. Subjects (200 took part, with results from 30 were excluded for various reasons) saw a statement involving a made-up object and verb, such as: “55% of the birlers are enciad.” They then saw a sentence containing either most or more than half, that was either upward-entailing (e.g., “More than half of the birlers are enciad.”), or downward-entailing (e.g., “It is not the case that more than half of the birlers are enciad.”); most/more than half and upward/downward entailing creates four possible kinds of sentence. Subjects were asked to respond true/false.
The percentage appearing in the first sentence of the two seen by subjects varied, e.g., “44% of the tiklets are hullaw.”, “12% of the puggles are entand.”, “68% of the plipers are sesare.” The percentage boundary where each subjects’ true/false answer switched was calculated (i.e., the mean of the percentages present in the questions’ each side of true/false boundary; often these values were 46% and 52%, whose average is 49; this is an artefact of the question wording).
The plot below shows the number of subjects whose true/false boundary occurred at a given percentage (code+data):
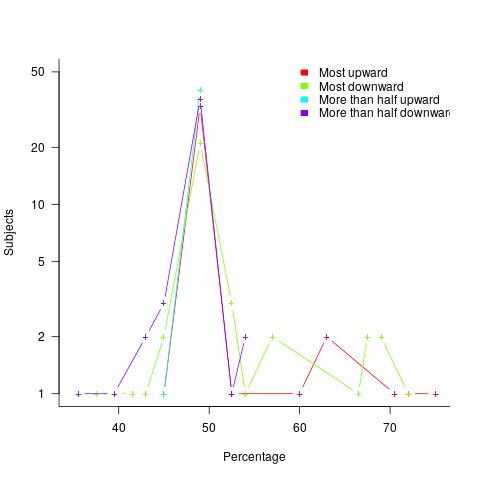
When asked, the majority of subjects had a 50% boundary for most/more than half+upward/downward. A downward entailment causes some subjects to lower their 50% boundary.
So now we know (subject to replication). Most people are likely to agree that 50% is the boundary for most/more than half, but some people think that the boundary percentage is higher for most.
When asked to write a sentence, percentages above 50% attract more mosts than more than halfs.
Most is preferred when discussing vague and uncountable domains; more than half is used when data is involved.
Over/under estimation factor for ‘most estimates’
When asked to estimate the time taken to perform a software development related task, people regularly over or under estimate. What range of over/under estimation falls within the bounds of the term ‘most estimates’, i.e., the upper/lower bounds of the ratio  (an overestimate occurs when
(an overestimate occurs when  , an underestimate when
, an underestimate when  )?
)?
On Twitter, I have been citing a factor of two for over/under time estimates. This factor of two involves some assumptions and a personal interpretation.
The following analysis is based on the two major software task effort estimation datasets: SiP and CESAW. The tasks in both datasets are for internal projects (i.e., no tendering against competitors), and require at most a few hours work.
The following analysis is based on the SiP data.
Of the 8,252 unique tasks in the SiP data, 30% are underestimates, 37% exact, and 33% overestimates.
How do we go about calculating bounds for the over/under factor of most estimates (a previous post discussed calculating an accuracy metric over all estimates)?
A simplistic approach is to average over each of the overestimated and underestimated tasks. The plot below shows hours estimated against the ratio actual/estimated, for each task (code+data):
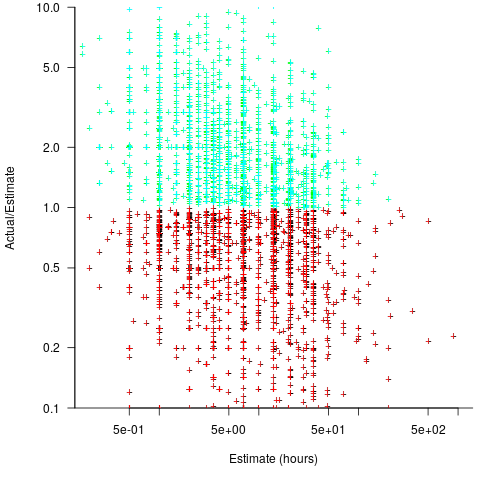
Averaging the over/under estimated tasks separately (using the geometric mean) gives 0.47 and 1.9 respectively, i.e., tasks are over/under estimated by a factor of two.
This approach fails to take into account the number of estimates that are over/under/equal, i.e., it ignores likelihood information.
A regression model takes into account the distribution of values, and we could adopt the fitted model’s prediction interval as the over/under confidence intervals. The prediction interval is the interval within which other observations are expected to fall, with some probability (R’s predict function uses one standard deviation).
The plot below shows a fitted regression model and prediction intervals at one standard deviation (68.3%) and two standard deviations (95%); the faint grey line shows Estimate == Actual (code+data):
The fitted model tilts down from the upward direction of the Estimate == Actual line, consequently the over/under estimation factor depends on the size of the estimate. The table below lists the over/under estimation factor for low/high estimates at one & two standard deviations (68.3 and 95% probability).
People like simple answers (i.e., single values) and the mean value is a commonly used technique of summarising many values. The task estimate values are unevenly distributed and weighting the mean by the distribution of estimated values is more representative than, say, an evenly distributed set of estimates. The 5th and 6th columns in the table below list the weighted means at one/two standard deviations (the CESAW columns are the values for all projects in the CESAW data).
1 sd 2 sd Weighted mean CESAW
Low High Low High 1 sd 2 sd 1 sd 2 sd
Over 0.56 0.24 0.27 0.11 0.46 0.25 0.29 0.1
Under 2.4 1.0 4.9 2.0 2.00 4.1 2.4 6.5 |
The weighted means for over/under estimates are close to a factor of two of the actual (divide/multiply) within one standard deviation (68.3%), and a factor of four within two standard deviations (95%).
Why choose to give the one standard deviation factor, rather than the two? People talk of “most estimates”, but what percentage range does ‘most’ map to? I have tended to think of ‘most’ as more than two-thirds, e.g., at least one standard deviation (a recent study suggests that ‘most’ usage peaks at 80-85%), and I think of two standard deviations as ‘nearly all’ (i.e., 95%; there are probably people who call this ‘most’).
Perhaps a between two and four is a more appropriate answer (particularly since the bounds are wider for the CESAW data). Suggestions welcome.
A Wikihouse hackathon
I was at the Wikihouse hackathon on Wednesday. Wikihouse is an open-source project involving prefabricated house designs and building processes.
Why is a software guy attending what looks like a very non-software event? The event organizers listed software developer as one of the attendee skill sets. Also, I have been following the blog Construction Physics, where Brian Potter has been trying to work out why the efficiency of building construction has not significantly improved over many decades; the approach is wide-ranging, data driven and has parallels with my analysis of software engineering. I counted four software people at the event, out of 30’ish attendees; Sidd I knew from previous hacks.
Building construction shares some characteristics with software development. In particular, projects are bespoke, but constructed using subcomponents that are variations on those used in most other projects of the same kind of building, e.g., walls±window frames, floors/ceilings.
The Wikihouse design and build process is based around a collection of standardised, prefabricated subcomponents, called blocks; these are made from plywood, slotted together, and held in place using butterfly/bow-tie joints (wood has a negative carbon footprint). A library of blocks is available, with the page for each block including a DXF cutting file, assembly manual, 3-D model, and costing; there is a design kit for building a house, including a spreadsheet for costing, and a variety of How-Tos. All this is available under an open source license. The Open Systems Lab is implementing building design software and turning planning codes into code.
Not knowing anything about building construction, I have no way of judging the claims made during the hackathon introductory presentations, e.g., cost savings, speed of build, strength of building, expected lifetime, etc.
Constructing lots of buildings using Wikihouse blocks could produce an interesting dataset (provided those doing the construction take the time to record things). Questions such as: how does construction time vary by team composition (self-build is possible) and experience, and by number of rooms and their size spring to mind (no construction time/team data was recorded during the construction of the ‘beta test’ buildings).
The morning was taken up with what was essentially a product pitch, then we got shown around the ‘beta test’ buildings (they feel bigger on the inside), lunch and finally a few hours hacking. The help they wanted from software people was in connecting together some of the data/tools they had created, but with only a few hours available there was little that could be done (my input was some suggestions on construction learning curves and a few people/groups I knew doing construction data analysis)
Will an open source approach enable the Wikihouse project to succeed with its prefabricated approach to building construction, where closed source companies have failed when using this approach, e.g., Katerra?
Part of the reason that open source software succeeded was that it provided good enough functionality to startup projects/companies who could not afford to pay for software (in some cases the open source tools provided superior functionality). Some of these companies grew to be significant players, convincing others that open source was viable for production work. Source code availability allows developers to use it without needing to involve management, and plenty of managers have been surprised to find out how embedded open source software is within their group/organization.
Buildings are not like software, lots of people with some kind of power notice when a new building appears. Buildings need to be connected to services such as water, gas and electricity, and they have a rateable value which the local council is keen to collect. Land is needed to build on, and there are a whole host of permissions and certificates that need to be obtained before starting to build and eventually moving in. Doing it, and telling people later is not an option, at least in the UK.
Cognitive effort, whatever it might be
Software developers spend a lot of time acquiring knowledge and understanding of the software system they are working on. This mental activity fits within the field of Cognition, which covers all aspects of intellectual functions and processes. Human cognition as it related to software development is covered in chapter 2 of my book Evidence-based software engineering; a reading list.
Cognitive effort (e.g., thinking) is hard work, or at least mental effort feels like hard work. It has become fashionable for those extolling the virtues of some development technique/process to claim that one of its benefits is a reduction in cognitive effort; sometimes the term cognitive load is used, but I suspect this is not a reference to cognitive load theory (which is working memory based).
A study by Arai, with herself as the subject, measured the time taken to mentally multiply two four-digit values (e.g., 2,645 times 5,784). Over 2-weeks, Arai practiced on four days, on each day multiplying over 20 four-digit value pairs. A week later Arai multiplied 40 four-digit value pairs (starting at 1:45pm, finishing at 6:31pm), had dinner between 6:31-7:41 pm, and then, multiplied 20 four-digit value pairs (starting at 7:41, finishing at 10:07). The plot below shows the time taken for each mental multiplication sequence, with fitted regression lines (code+data):
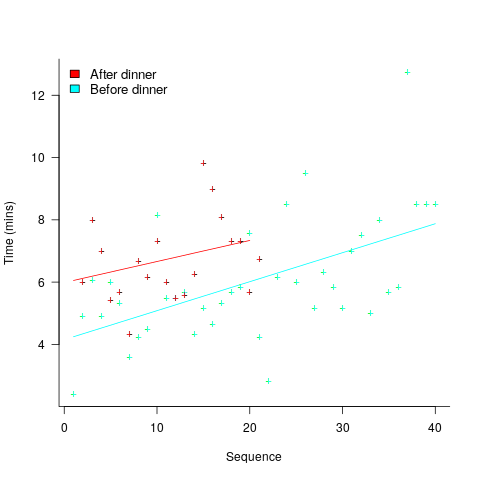
Over the course of the first, 5-hour session, average time taken slowed from four to eight minutes. The slope of the regression fit for the second session is poor, although the fit for the start value (6 minutes) is good.
The average increase in time taken is assumed to be driven by a reduction in mental effort, caused by the mental fatigue experienced during an extended period of continuous mental work.
What do we know about cognitive effort?
TL;DR Many theories and little evidence.
Cognitive psychologists are still at the stage of figuring out what exactly cognitive effort is. For instance, what is going on when we try harder (or decide to give up), and what is being conserved when we conserve our mental resources? The major theories include:
- Cognitive control: Mental processes form a continuum, from those that can be performed automatically with little or no effort, to those requiring concentrated conscious effort. Here, cognitive control is viewed as the force through which cognitive effort is exerted. The idea is that mental effort regulates the engagement of cognitive control in the same way as physical effort regulates the engagement of muscles.
- Metabolic constraints: Mental processes consume energy (glucose is the brain’s primary energy source), and the feeling of mental effort is caused by reduced levels of glucose. The extent to which mental effort is constrained by glucose levels is an ongoing debate.
- Capacity constraints: Working memory has a limited capacity (i.e., the oft quoted 7±2 limit), and tasks that fill this capacity do feel effortful. Cognitive load theory is based around this idea. A capacity limited working memory, as a basis of cognitive effort, suffers from the problem that people become mentally tired in the sense that later tasks feel like they require more effort. A capacity constrained model does not predict this behavior. Neither does a constraints model predict that increasing rewards can result in people exerting more cognitive effort.
How might cognitive effort be measured?
TL;DR It’s all relative or not at all.
To date, experiments have compared relative expenditure of effort between different tasks (some comparing cognitive with physical effort, other purely cognitive). For instance, showing that subjects are willing to perform a task requiring more cognitive effort when the expected reward is higher.
As always with human experiments, people can have very different behavioral characteristics. In particular, people differ in what is known as need for cognition, i.e., their willingness to invest cognitive effort.
While a lot of research has investigated the characteristics of working memory, the only real metric studied has been capacity, e.g., the longest sequence of digits that can be remembered/recalled, or span tasks involving having to remember words while performing simple arithmetic operations.
Experimental research on cognitive effort seems to be picking up, but don’t hold your breadth for reliable answers. Research of human characteristics can start out looking straight forward, but tends to quickly disappear down multiple, inconclusive rabbit holes.
Rounding and heaping in non-software estimates
Round numbers are often preferred in software task estimation times, e.g., 1, 5, 7 (hours in one working day), and 14. This human preference for round numbers is not specific to software, or to estimating. Round numbers can act as goals, as clustering points, may be used more often as uncertainty increases, or be the result of satisficing, etc.
Rounding can occur in response to any question involving a numeric value, e.g., a government census or survey asking citizens about their financial situation or health. Rounding introduces error in the analysis of data. The Whipple index, described in 1919, was the first attempt to quantify the amount of error; calculated as: “per cent which the number reported as multiples of 5 forms of one-fifth of the total number between ages 23 to 62 years inclusive.” for errors of reported age. Other metrics for this error have been proposed, and packages to calculate them are available.
At some point (the evidence suggests a 1940 paper) a published paper introduced the term heaping effect. These days, heaping is more often used to name the process, compared to rounding, e.g., heaping of values; ‘heaping’ papers do use the term rounding, but I have not seen ’rounding’ papers use heaping.
The choice of rounding values depends on the unit of measurement. For instance, reported travel arrival/departure times are rounded to intervals of 5, 14, 30 and 60 minutes; based on reported/actual travel times it is possible to estimate the probability that particular rounding intervals have been used.
The Whipple index fails when all the values are large (e.g., multiple thousands), or take a small range of values (e.g., between one and twenty).
One technique for handling rounding of large values is to define roundedness in terms of the fraction of value digits that are trailing zeroes. The plot below shows the number of households having a given estimated balance on their first mortgage in the 2013 Survey of Consumer Finances (in red), and the distribution of actual balances reported by the New York Federal Reserve (in blue/green; data extracted from plot in a paper and scaled to equalize total mortgage values; code+data):
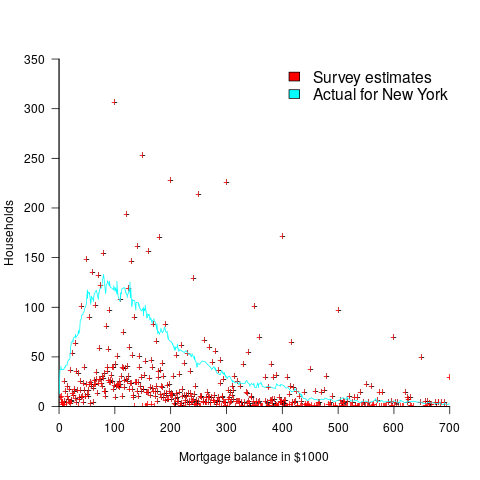
The relatively high number of distinct round numbers swamps any underlying distribution of actual values. While some values having some degree of roundness occur more often than non-round values, they still appear less often than expected by the known distribution. It is possible that homeowners have mortgages at round values because they of banking limits, or reasons other than rounding when answering the survey.
The plot below shows the number of people reporting having a given number of friends, plus number of cigarettes smoked per day, from the 2015 survey of Objective and Subjective Quality of Life in Poland (code+data):
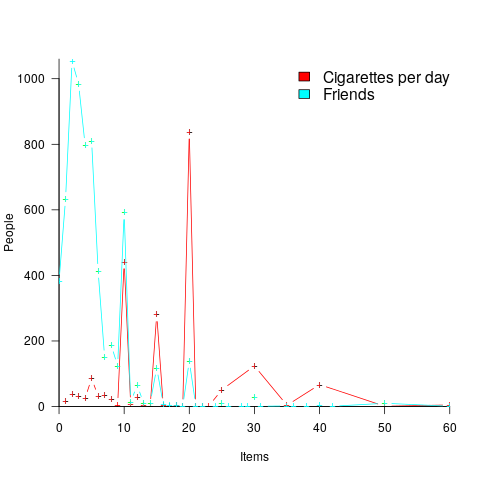
The narrow range of a person’s number of friends prevents the Whipple index from effectively detecting rounding/heaping.
The dominance of round numbers in the cigarettes smoked per day may be caused by the number of cigarettes contained in a packet, i.e., people may be accurately reporting that they smoke the contents of a packet, rather than estimating a rounded number.
Simple techniques are available for correcting the mean/variance when values are always rounded to specified boundaries. When the probability of rounding is not 100%, the calculation is more complicated.
Rounded/Heaped data contains multiple distributions, i.e., the non-rounded values and the rounded values; various mixture models have been proposed to fit such data. Alternatively, the data can be ‘deheaped’, and various deheaping techniques have been proposed.
Given the prevalence of significant amounts of rounding/heaping, it’s surprising how few people know about it.
Recent Comments