Archive
SQL usage: schema evolution
My first serious involvement with SQL, about 15 years ago, was writing a parser for the grammar specified in the ISO SQL-92 Standard. One of the things that surprised me about SQL was how little source code was generally available (for testing) and the almost complete lack of any published papers on SQL usage (its always better to find out about where the pot-holes are from other peoples’ experience).
The source code availability surprie is largely answered by the very close coupling between source and data that occurs with SQL; most SQL source is closely tied to a database schema and unless you have a need to process exactly the same kind of data you are unlikely to have any interest having access to the corresponding SQL source. The growth in usage of MySQL means that these days it is much easier to get hold of large amounts of SQL (large is a relative term here, I suspect that there are probably many orders of magnitude fewer lines of SQL in existence than there is of other popular languages).
In my case I was fortunate in that NIST released their SQL validation suite for beta testing just as I started to test my parser (it had taken me a month to get the grammar into a manageable shape).
Published research on SQL usage continues to be thin on the ground and I was pleased to recently discover a paper combining empirical work on SQL usage with another rarely researched topic, declaration usage e.g., variables and types or in this case schema evolution (for instance, changes in the table columns over time).
The researchers only analyzed one database, the 171 releases of the schema used by Wikipedia between April 2003 and November 2007, but they also made their scripts available for download and hopefully the results of applying them to lots of other databases will be published.
Not being an experienced database person I don’t know how representative the Wikipedia figures are; the number of tables increased from 17 to 34 (100% increase) and the number of columns from 100 to 242 (142%). A factor of two increase sounds like a lot but I suspect that all but one these columns occupy a tiny fraction of the 14GB that is the current English Wikipedia.
Program optimization given 1,000 datasets
A recent paper reminded me of a consequence of widespread availability of multi-processor systems I had failed to mention in a previous post on compiler writing in the next decade. The wide spread availability of systems containing large numbers of processors opens up opportunities for both end users of compilers and compiler writers.
Some compiler optimizations involve making decisions about what parts of a program will be executed more frequently than other parts; usually speeding up the frequently executed at the expense of slowing down the less frequently executed. The flow of control through a program is often effected by the input it has been given.
Traditionally optimization tuning has been done by feeding a small number of input datasets into a small number of programs, with the lazy using only the SPEC benchmarks and the more conscientious (or perhaps driven by one very important customer) using a few more acquired over time. A few years ago the iterative compiler tuning community started to address this lack of input benchmark datasets by creating 20 datasets for each of their benchmark programs.
Twenty datasets was certainly a step up from a few. Now one group (Evaluating Iterative Optimization Across 1000 Data Sets; written by a team of six people) has used 1,000 different input data sets to evaluate the runtime performance of a program; in fact they test 32 different programs each having their own 1,000 data sets. Oh, one fact they forgot to mention in the abstract was that each of these 32 programs was compiled with 300 different combinations of compiler options before being fed the 1,000 datasets (another post talks about the problem of selecting which optimizations to perform and the order in which to perform them); so each program is executed 300,000 times.
Standing back from this one could ask why optimizers have to be ‘pre-tuned’ using fixed datasets and programs. For any program the best optimization results are obtained by profiling it processing large amounts of real life data and then feeding this profile data back to a recompilation of the original source. The problem with this form of optimization is that most users are not willing to invest the time and effort needed to collect the profile data.
Some people might ask if 1,000 datasets is too many, I would ask if it is enough. Optimization often involves trade-offs and benchmark datasets need to provide enough information to compiler writers that they can reliably tune their products. The authors of the paper are still analyzing their data and I imagine that reducing redundancy in their dataset is one area they are looking at. One topic not covered in their first paper, which I hope they plan to address, is how program power consumption varies across the different datasets.
Where next with the large multi-processor systems compiler writers now have available to them? Well, 32 programs is not really enough to claim reasonable coverage of all program characteristics that compilers are likely to encounter. A benchmark containing 1,000 different programs is the obvious next step. One major hurdle, apart from the people time involved, is finding 1,000 programs that have usable datasets associated with them.
Language usage in Google’s ngram viewer
I thought I would join the fun that people are having with Google’s new ngram viewer. The raw data (only a subset for bigrams and longer ngrams) was also enticing, but at 35+ gigabytes for the compressed 1/2/3-grams of English-all I decided to forgo the longer n-grams.
We all know that in the dim and distant past most programmers wrote in machine code, but it was not until 1980 that “source code” appeared more frequently in books that “machine code”.
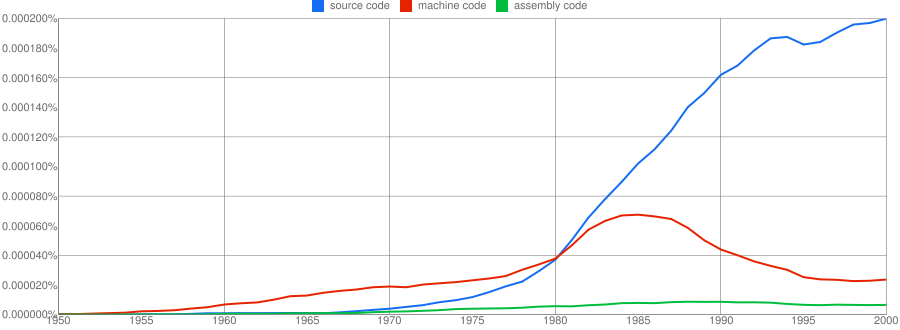
Computer language popularity is a perennial question. Fortran and Cobol address very different markets and I would have expected their usage to follow similar patterns, with “COBOL” having the obvious usage pattern for them both to follow. Instead, both “FORTRAN” and “Fortran” peaked within 10 years, with one staying there for another 20 years before declining and the other still going strong in 2000 (and still ahead of “PHP” and “Python” in 2000; neither shown to keep the clutter down). I am surprised to see “Prolog” usage being so much greater than “Lisp” and I would have expected “Lisp” to have a stronger presence in the 1970s.
I think the C++ crowd will be surprised to see that in 2000 usage was not much greater than what “FORTRAN” had enjoyed for 20 years.
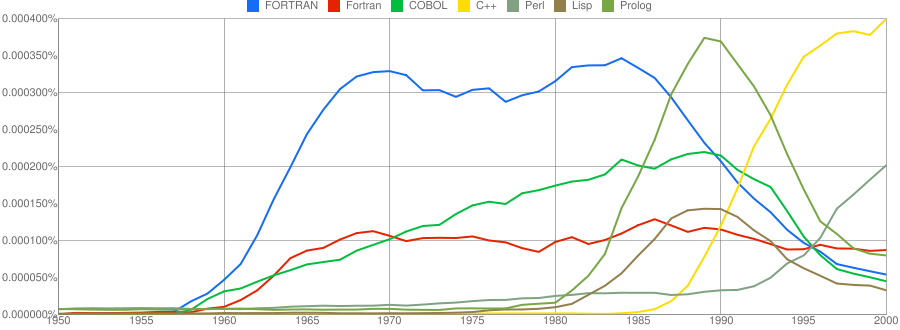
“C”, as in language, usage is obviously different to reliably measure. I have tried the obvious bigrams. Looking at some of the book matches for the phrase “in C” shows that the OCR process has sometimes inserted spaces that probably did not exist in the original, the effect being to split words and create incorrect bigrams. The phrase “in C” would also appear in books on music.
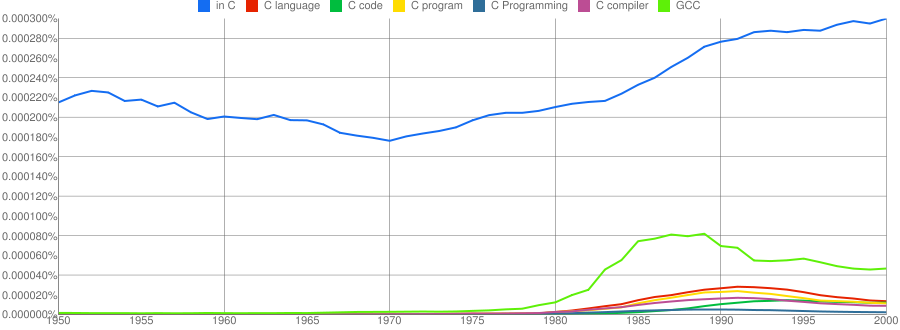
I have put the three words “Java”/”SQL”/”BASIC” in a separate plot because their usage swamps that of the other languages. Java obviously has multiple non-computer related uses and subtracting the estimated background usage suggests a language usage similar to that of “SQL”. There is too much noise for the usage of “Basic” to tell us much.
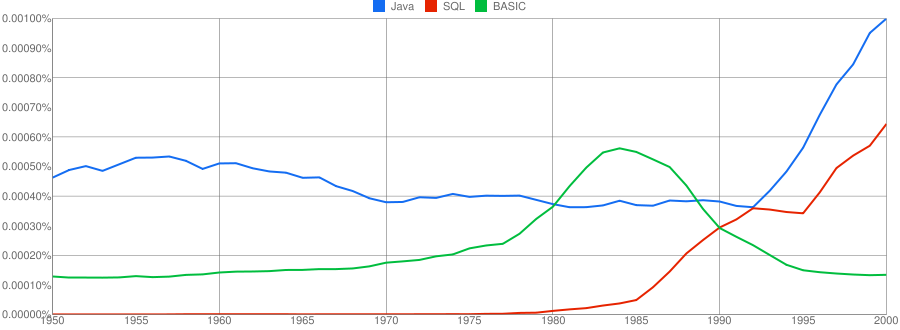
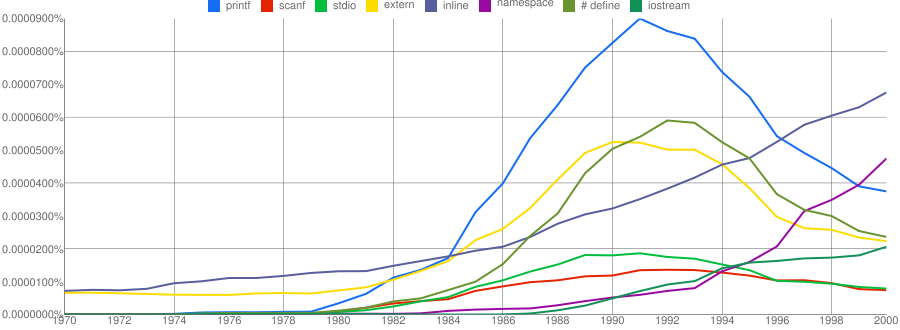
One way of comparing C/C++ language usage is to look source code usage where they are likely to differ. I/O, in the form of printf/scanf and stdio/iostream, is one obvious choice and while the expected C usage starts to declines in the 1990s the C++ usage just shows a stead growth (perhaps the <</>> usage, which does not appear in the Google viewer, has a dramatic growth during this time period).
Surprisingly #define also follows a similar pattern of decline. Even allowing for the rabid anti-macro rhetoric of the C++ in-crowd I would not have expected such a rapid decline. Perhaps this is some artifact of the book selection process used by Google; but then "namespace" shows a healthy growth around this time period.
The growth of "inline" over such a long period of time is a mystery. Perhaps some of this usage does not relate to a keyword appearing within source code examples but to text along the lines of "put this inline to make it faster".
What usage should we expect for the last decade? A greater usage of "PHP" and "Python" is an obvious call to make, along with the continuing growth of SQL, I think "UML" will also feature prominently. Will "C++" show a decline in favor or "Java" and what about "C#"? We will have to wait and see.
Has the seed that gets software development out of the stone-age been sown?
A big puzzle for archaeologists is why Stone Age culture lasted as long as it did (from approximately 2.5 millions years ago until the start of the copper age around 6.3 thousand years ago). Given the range of innovation rates seen in various cultures through-out human history, a much shorter Stone Age is to be expected. A recent paper proposes that low population density is what maintained the Stone Age status quo; there was not enough contact between different hunter gather groups for widespread take up of innovations. Life was tough, and the viable lifetime of individual groups of people may not have been long enough for them to be likely to pass on innovations (either their own ones encountered through contact with other groups).
Software development is often done by small groups that don’t communicate with other groups and regularly die out (well there is a high turn-over, with many of the more experienced people moving on to non-software roles). There are sufficient parallels between hunter gathers and software developers to suggest both were/are kept in a Stone Age for the same reason, lack of a method that enables people to obtain information about innovations and how worthwhile these might be within a given environment.
A huge barrier to the development of better software development practices is the almost complete lack of significant quantities of reliable empirical data that can be used to judge whether a claimed innovation is really worthwhile. Companies rarely make their detailed fault databases and product development history public; who wants to risk negative publicity and lawsuits just so academics have some data to work with.
At the start of this decade, public source code repositories like SourceForge and public software fault repositories like Bugzilla started to spring up. These repositories contain a huge amount of information about the characteristics of the software development process. Questions that can be asked of this data include: what are common patterns of development and which ones result in fewer faults, how does software evolve and how well do the techniques used to manage it work.
Empirical software engineering researchers are now setting up repositories, like Promise, containing the raw data from their analysis of Open Source (and some closed source) projects. By making this raw data available, they are reducing the effort needed by other researchers to investigate their own alternative ideas (I have just started a book on empirical software engineering using the R statistical language that uses examples based on this raw data).
One of the side effects of Open Source development could be the creation of software development practices that have been shown to be better (including showing that some existing practices make things worse). The source of these practices not being what the software developers themselves do or how they do it, but the footsteps they have left behind in the sand.
Christmas book for 2010
I’m rather late with my list of Christmas books for 2010. While I do have a huge stack of books waiting to be read I don’t seem to have read many books this year (I have been reading lots of rather technical blogs this year, i.e., time/thought consuming ones) and there is only one book I would strongly recommend.
Anybody with even the slightest of interest in code readability needs to read
Reading in the Brain by Stanislaw Dehaene (the guy who wrote The Number Sense, another highly recommended book). The style of the book is half way between being populist and being an undergraduate text.
Most of the discussion centers around the hardware/software processing that takes place in what Dehaene refers to as the letterbox area of the brain (in the left occipito-temporal cortex). The hardware being neurons in the human brain and software being the connections between them (part genetically hardwired and part selectively learned as the brain’s owner goes through childhood; Dehaene is not a software developer and does not use this hardware/software metaphor).
{kind=link}
As any engineer knows, knowledge of the functional characteristics of a system are essential when designing other systems to work with it. Reading this book will help people separate out the plausible from the functionally implausible in discussions about code readability.
Time and again the reading process has co-opted brain functionality that appears to have been designed to perform other activities. During the evolution of writing there also seems to have been some adaptation to existing processes in the brain; a lesson here for people designing code visualizations tools.
{kind=link}
{kind=link}
In my C book I tried to provide an overview of the reading process but skipped discussing what went on in the brain, partly through ignorance on my part and also a belief that we were a long way from having an accurate model. Dehaene’s book clearly shows that a good model of what goes on in the brain during reading is now available.
Build an ISO Standard and the world will beat a path to your door
An email I received today, announcing the release of version 1.0 of the GNU Modula-2 compiler, reminded me of some plans I had to write something about a proposal to add some new definitions to the next version of the ISO C Standard.
In the 80s I was heavily involved in the Pascal community and some of the leading members of this community thought that the successor language designed by Niklaus Wirth, Modula-2, ought to be the next big language. Unfortunately for them this view was not widely shared and after much soul searching it was decided that the lack of an ISO standard for the language was responsible for holding back widespread adoption. A Modula-2 ISO Standard was produced and, as they say, the rest is history.
The C proposal involves dividing the existing definition undefined behavior into two subcategories; bounded undefined behavior and critical undefined behavior. The intent is to provide guidance to people involved with software assurance. My long standing involvement with C means that I find the technical discussions interesting; I have to snap myself out of getting too involved in them with the observation that should the proposals be included in the revised C Standard they will probably have the same impact as the publication of the ISO Standard had on Modula-2 usage.
The only way for changes to an existing language standard to have any impact on developer usage is for them to require changes to existing compiler behavior or to specify additional runtime library functionality (e.g., Extensions to the C Library Part I: Bounds-checking interfaces).
C is top dog in Google AI Challenge
The Google AI Challenge has just finished and the scores for the 4,619 entries have been made available, along with the language used. Does the language choice of the entries tell us anything?
The following is a list of the 11 most common languages used, the mean and standard deviation of the final score for entries written in that language and the number of entries written in the language:
mean sd entries
C 2331 867 18
Haskell 2275 558 51
OCaml 2262 567 12
Ruby 2059 768 55
Java 2060 606 1634
C# 2039 612 485
C++ 2027 624 1232
Lisp 1987 686 32
Python 1959 637 948
Perl 1957 693 42
PHP 1944 769 80
C has the highest mean and Lisp one of the lowest; is this a killer blow for Lisp in AI? (My empirical morality prevented me omitting the inconveniently large standard deviations.) C does have the largest standard deviation; is this because of crashes caused by off-by-one/null pointer errors or lower ability on the authors part? Not nearly enough data to tell.
I am guessing that this challenge would be taken up by many people in their 20s, which would explain the large number of entries written in Java and C++ (the most common languages taught in universities over the last few years).
I don’t have an explanation for the relatively large number of entries written in Python.
How to explain the 0.4% of entries written in C and it top placing? Easy, us older folk may be a bit thin on the ground but we know what we are doing (I did not submit an entry).
Flawed analysis of “one child is a boy” problem?
A mathematical puzzle has reappeared over the last year as the topic of discussion in various blogs and I have not seen any discussion suggesting that the analysis appearing in blogs contains a fundamental flaw.
The problem is as follows: I have two children and at least one of them is a boy; what is the probability that I have two boys? (A variant of this problem specifies whether the boy was born first or last and has a noncontroversial answer).
Most peoples (me included) off-the-top-of-the-head answer is 1/2 (the other child can be a girl or a boy, assuming equal birth probabilities {which is very a good approximation to reality}).
The analysis that I believe to be incorrect goes something like the following: The possible birth orders are gb, bg, bb or gg and based on the information given we can rule out girl/girl, leaving the probability of bb as 1/3. Surprise!
A variant of this puzzle asks for the probability of boy/boy given that we know one of the children is a boy born on a Tuesday. Here the answer is claimed to be 13/27 (brief analysis or using more complicated maths). Even greater surprise!
I think the above analysis is incorrect, which seems to put me in a minority (ok, Wikipedia says the answer could sometimes be 1/2). Perhaps a reader of this blog can tell me where I am going wrong in the following analysis.
Lets call the known boy B, the possible boy b and the possible girls g. The sequence of birth events that can occur are:
Bg gB bB Bb gg
There are four sequences that contain at least one boy, two of which contain two boys. So the probability of two boys is 1/2. No surprise.
All of the blog based analysis I have seen treat the ordering of a known boy+girl birth sequence as being significant but do not to treat the ordering of a known boy+boy sequence as significant. This leads them to calculate the incorrect probability of 1/3.
The same analysis can be applied to the “boy born on a Tuesday” problem to get the probability 14/28 (i.e., 1/2).
Those of you who like to code up a problem might like to consider the use of a language like Prolog which I would have thought would be less susceptible to hidden assumptions than a Python solution.
Ordering of members in Oracle/Google Java copyright lawsuit
Oracle have specified some details in their ‘Java’ copyright claims against Google. One item that caught my eye was the source of a class copyrighted by Oracle and the corresponding class being used by Google. An experiment I ran at the 2005 and 2008 ACCU conferences studied how developers create/organize data structures from a given specification and sheds some light on developer behavior in this area (I am not a lawyer and have never been involved in a copyright case, so I will not say anything about legal issues).
{kind=link}
Two of the hypothesis investigated by the ACCU experiment were, 1) within aggregate types (e.g., structs or classes) members having the same type tend to be placed together (e.g., all the chars followed by all the ints followed by all the floats), and 2) the relative ordering of members follows the order of the corresponding items in the specification (e.g., if the specification documents the date and then the location and this information occurs within the same structure the corresponding date member will appear before the location member).
The first hypothesis was investigated by analyzing C source and found that members having the same type are very likely to be grouped together. Looking at the private definitions in the Oracle code we see that members having a HashSet or boolean type are not grouped together with other members of the same type; one possibility was that the class grew over time and new members were appended rather than intermixed with members already present. The corresponding Google code also has the HashSet or boolean intermixed with members having different types. At least one implementation exists where members having the same type are grouped together.
The second hypothesis was investigated by running an experiment which asked developers to create an API from a specification, with everybody seeing the same specification except the ordering of the information was individually randomized for each developer. The results showed that when creating a struct or class (each subject was allowed to create the API in a language of their choice, with C, C++ and Java actually being used) developers tended to list members in the same relative order as the information appeared in the specification.
If the Apache implementors of the code used by Google based their specification on the Oracle code, it is to be expected that the ordering of the members would be very similar, which is it.
There has been a lot of talk of clean room implementation being used for the Java-like code within Dalvik. Did somebody sit down and write a specification of the Oracle PolicyNode class that was then given to somebody else to implement?
The empirical evidence (i.e., members having the same type are not adjacent but intermixed with other types and relative member ordering is the same) suggests that the implementation of at least the private members of the PolicyNode class being used by Google was based directly on the Oracle code.
These members are defined to be private so Google cannot argue that they are part of an API (various people are claiming that being part of an API has some impact on copyright, I have no idea if this is true).
Can Google get around any copyright issue simply by reordering the member definitions? I have no idea.
It would appear that like the patent lawsuit this copyright lawsuit could prove to be very interesting to watch.
Language vulnerabilities TR published
ISO has just published the first Technical Report from the Programming Language Vulnerabilities working group (ISO/IEC TR 24772 Information technology — Programming languages — Guidance to avoiding vulnerabilities in programming languages through language selection and use). Having worked on programming language coding guidelines for many years, I was an eager participant during the first few years of this group. Unfortunately, this committee succumbed to an affliction that affects many groups working in this area, a willingness to uncritically include any reasonable sounding proposal that came its way.
Coding guidelines are primarily driven by human factors with implementation issues coming to the fore in some situations and guideline selection involves a cost/benefit trade-off. Early versions of the TR addressed these topics directly. As work progressed many members of WG23 (our official designation is actually ISO/IEC JTC 1/SC 22/WG 23) seemed to want a concrete approach, i.e., an unstructured list of guidelines, rather than a short list of potential problem areas derived by careful analysis.
A major input came from Larry Wagoner’s analysis of fault reports from various sources; he produced a list of the most common problems, and it was generally agreed that these be used as the base from which to derive the general guidelines.
Work began on writing the text to cover the faults listed by Larry, coalescing similar constructs where appropriate. Many of the faults occurred in programs written in C and some attempt was made to generalize the wording to be applicable to other languages (the core guidelines were intended to be language independent).
Over time suggestions were sent to the group’s convener and secretary for consideration (these came from group members and interested outsiders). Unfortunately, many of these proposals were accepted for inclusion without analysing the likelihood of them being a common source of faults in practice or the possibility that use of alternative constructs would be more fault-prone.
Some members of the group were loath to remove text from the draft document if it was decided that the issue discussed was not applicable. This text tended to migrate to a newly created Section 7 “Applications Issues”, a topic outside our scope of work).
The resulting document is a mishmash of guidelines likely to be relevant to real code and others that are little more than platitudes (e.g., ‘Demarcation of Control Flow’ and ‘Structured Programming’) or examples of very specific problems that occasional occur (i.e., not common enough to be worth mentioning such as ‘Enumeration issues’).
I eventually threw up my hands in despair at trying to stem the flow of ‘good’ ideas that kept being added, and stopped being actively involved.
Would I recommend TR 24772 to people? It does contain some very useful material. The material I think should have been culled is generally not bad, it just has a very low value and for most developers is probably not worth spending time on.
Footnote. ISO makes its money from selling standards and does not like to give them away for free. Those of us who work on standards want them to be used and would like them to be freely available. There is a precedent for TRs being made freely available, and hopefully this will eventually happen to TR 24772. In the meantime, there are documents on the WG23 web site that essentially contain all of the actual technical text.
Recent Comments