Archive
Fortran 2008 Standard has been updated
An updated version of ISO/IEC 1539-1 Information technology — Programming languages — Fortran — Part 1: Base language has just been published. So what has JTC1/SC22/WG5 been up to?
This latest document is bug a release of the 2010 standard, known as Fortran 2008 (because the ANSI Standard from which the ISO Standard was derived, sed -e "s/ANSI/ISO/g" -e "s/National/International/g", was published in 2008) and incorporates all the published corrigenda. I must have been busy in 2008, because I did not look to see what had changed.
Actually the document I am looking at is the British Standard. BSI don’t bother with sed, they just glue a BSI Standards Publication page on the front and add BS to the name, i.e., BS ISO/IEC 1539-1:2010.
The interesting stuff is in Annex B, “Deleted and obsolescent features” (the new features are Fortranized versions of languages features you have probable seen elsewhere).
Programming language committees are known for issuing dire warnings that various language features are obsolescent and likely to be removed in a future revision of the standard, but actually removing anything is another matter.
Well, the Fortran committee have gone and deleted six features! Why wasn’t this on the news? Did the committee foresee the 2008 financial crisis and decide to sneak out the deletions while people were looking elsewhere?
What constructs cannot now appear in conforming Fortran programs?
- “Real and double precision DO variables. .. A similar result can be achieved by using a DO construct with no loop control and the appropriate exit test.”
What other languages call a for-loop, Fortran calls a DO loop. So loop control variables can no longer have a floating-point type.
- “Branching to an END IF statement from outside its block.”
An if-statement is terminated by the token sequence
END IF, which may have an optional label. It is no longer possible toGOTOthat label from outside the block of the if-statement. You are going to have to label the statement after it. - “PAUSE statement.”
This statement dates from the days when a computer (singular, not plural) had its own air-conditioned room and a team of operators to tend its every need. A
PAUSEstatement would cause a message to appear on the operators’ console and somebody would be dispatched to check the printer was switched on and had paper, or some such thing, and they would then resume execution of the paused program.I think WG5 has not seen the future here. Isn’t the
PAUSEstatement needed again for cloud computing? I’m sure that Amazon would be happy to quote a price for having an operator respond to aPAUSEstatement. - “ASSIGN and assigned GO TO statements and assigned format specifiers.”
No more assigning labels to variables and GOTOing them, as a means of leaping around 1,000 line functions. This modern programming practice stuff is a real killjoy.
- “H edit descriptor.”
First programmers stopped using punched cards and now the H edit descriptor have been removed from Fortran; Herman Hollerith no longer touches the life of working programmers.
In the good old days real programmers wrote
11HHello World. Using quote delimiters for string literals is for pansies. - “Vertical format control. … There was no standard way to detect whether output to a unit resulted in this vertical format control, and no way to specify that it should be applied; this has been deleted. The effect can be achieved by post-processing a formatted file.”
Don’t panic, C still supports the
\vescape sequence.
Student projects for 2016/2017
This is the time of year when students have to come up with an idea for their degree project. I thought I would suggest a few interesting ideas related to software engineering.
- The rise and fall of software engineering myths. For many years a lot of people (incorrectly) believed that there existed a 25-to-1 performance gap between the best/worst software developers (its actually around 5 to 1). In 1999 Lutz Prechelt wrote a report explaining out how this myth came about (somebody misinterpreted values in two tables and this misinterpretation caught on to become the dominant meme).
Is the 25-to-1 myth still going strong or is it dying out? Can anything be done to replace it with something closer to reality?
One of the constants used in the COCOMO effort estimation model is badly wrong. Has anybody else noticed this?
- Software engineering papers often contain trivial mathematical mistakes; these can be caused by cut and paste errors or mistakenly using the values from one study in calculations for another study. Simply consistency checks can be used to catch a surprising number of mistakes, e.g., the quote “8 subjects aged between 18-25, average age 21.3” may be correct because 21.3*8 == 170.4, ages must add to a whole number and the values 169, 170 and 171 would not produce this average.
The Psychologies are already on the case of Content Mining Psychology Articles for Statistical Test Results and there is a tool, statcheck, for automating some of the checks.
What checks would be useful for software engineering papers? There are tools available for taking pdf files apart, e.g., qpdf, pdfgrep and extracting table contents.
- What bit manipulation algorithms does a program use? One way of finding out is to look at the hexadecimal literals in the source code. For instance, source containing
0x33333333,0x55555555,0x0F0F0F0Fand0x0000003Fin close proximity is likely to be counting the number of bits that are set, in a 32 bit value.Jörg Arndt has a great collection of bit twiddling algorithms from which hex values can be extracted. The numbers tool used a database of floating-point values to try and figure out what numeric algorithms source contains; I’m sure there are better algorithms for figuring this stuff out, given the available data.
Feel free to add suggestions in the comments.
Does public disclosure of vulnerabilities improve vendor response?
Does public disclosure of vulnerabilities in vendor products result in them releasing a fix more quickly, compared to when the vulnerability is only disclosed to the vendor (i.e., no public disclosure)?
A study by Arora, Krishnan, Telang and Yang investigated this question and made their data available 🙂 So what does the data have to say (its from the US National Vulnerability Database over the period 2001-2003)?
The plot below is a survival curve for disclosed vulnerabilities, the longer it takes to release a patch to fix a vulnerability, the longer it survives.
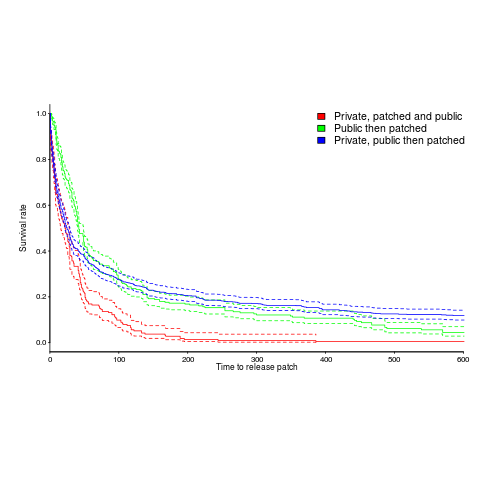
There is a popular belief that public disclosure puts pressure on vendors to release patchs more quickly, compared to when the public knows nothing about the problem. Yet, the survival curve above clearly shows publically disclosed vulnerabilities surviving longer than those only disclosed to the vendor. Is the popular belief wrong?
Digging around the data suggests a possible explanation for this pattern of behavior. Those vulnerabilities having the potential to cause severe nastiness tend not to be made public, but go down the path of private disclosure. Vendors prioritize those vulnerabilities most likely to cause the most trouble, leaving the less troublesome ones for another day.
This idea can be checked by building a regression model (assuming the necessary data is available and it is). In one way or another a lot of the data is censored (e.g., some reported vulnerabilities were not patched when the study finished); the Cox proportional hazards model can handle this (in fact, its the ‘standard’ technique to use for this kind of data).
This is a time dependent problem, some vulnerabilities start off being private and a public disclosure occurs before a patch is released, so there are some complications (see code+data for details). The first half of the output generated by R’s summary function, for the fitted model, is as follows:
Call:
coxph(formula = Surv(patch_days, !is_censored) ~ cluster(ID) +
priv_di * (log(cvss_score) + y2003 + log(cvss_score):y2002) +
opensource + y2003 + smallvendor + log(cvss_score):y2002,
data = ISR_split)
n= 2242, number of events= 2081
coef exp(coef) se(coef) robust se z Pr(>|z|)
priv_di 1.64451 5.17849 0.19398 0.17798 9.240 < 2e-16 ***
log(cvss_score) 0.26966 1.30952 0.06735 0.07286 3.701 0.000215 ***
y2003 1.03408 2.81253 0.07532 0.07889 13.108 < 2e-16 ***
opensource 0.21613 1.24127 0.05615 0.05866 3.685 0.000229 ***
smallvendor -0.21334 0.80788 0.05449 0.05371 -3.972 7.12e-05 ***
log(cvss_score):y2002 0.31875 1.37541 0.03561 0.03975 8.019 1.11e-15 ***
priv_di:log(cvss_score) -0.33790 0.71327 0.10545 0.09824 -3.439 0.000583 ***
priv_di:y2003 -1.38276 0.25089 0.12842 0.11833 -11.686 < 2e-16 ***
priv_di:log(cvss_score):y2002 -0.39845 0.67136 0.05927 0.05272 -7.558 4.09e-14 *** |
The explanatory variable we are interested in is priv_di, which takes the value 1 when the vulnerability is privately disclosed and 0 for public disclosure. The model coefficient for this variable appears at the top of the table and is impressively large (which is consistent with popular belief), but at the bottom of the table there are interactions with other variable and the coefficients are less than 1 (not consistent with popular belief). We are going to have to do some untangling.
cvss_score is a score, assigned by NIST, for the severity of vulnerabilities (larger is more severe).
The following is the component of the fitted equation of interest:
*(0.34+0.4*y2002)-1.4*y2003)}")
where:  is 0/1,
is 0/1, ") varies between 0.8 and 2.3 (mean value 1.8),
varies between 0.8 and 2.3 (mean value 1.8),  and
and  are 0/1 in their respective years.
are 0/1 in their respective years.
Applying hand waving to average away the variables:
)} right e^{{priv~di}(1.6-0.6-(0.7/3+1.4/3))} right e^{{priv~di}*0.3}")
gives a (hand waving mean) percentage increase of *100 right 35%") , when
, when priv_di changes from zero to one. This model is saying that, on average, patches for vulnerabilities that are privately disclosed take 35% longer to appear than when publically disclosed
The percentage change of patch delivery time for vulnerabilities with a low cvvs_score is around 90% and for a high cvvs_score is around 13% (i.e., patch time of vulnerabilities assigned a low priority improves a lot when they are publically disclosed, but patch time for those assigned a high priority is slightly improved).
I have not calculated 95% confidence bounds, they would be a bit over the top for the hand waving in the final part of the analysis. Also the general quality of the model is very poor; Rsquare= 0.148 is reported. A better model may change these percentages.
Has the situation changed in the 15 years since the data used for this analysis? If somebody wants to piece the necessary data together from the National Vulnerability Database, the code is ready to go (ok, some of the model variables may need updating).
Update: Just pushed a model with Rsquare= 0.231, showing a 63% longer patch time for private disclosure.
p-values in software engineering
Data relating to software engineering activities is starting to become common and the results of any statistical analysis of data will include something known as the p-value.
Most of the time having a p-value below some cut-off value is a good thing, but sometimes good things occur when the value is above the cut-off (see p-values for programmers for details about what the p-value is).
A commonly encountered cut-off value is 0.05 (sometimes written as 5%).
Where did this 0.05 come from? It was first proposed in 1920s by Ronald Fisher. Fisher’s Statistical Methods for Research Workers and later Statistical Tables for Biological, Agricultural, and Medical Research had a huge impact and a p-value cut-off of 0.05 became enshrined as the magic number.
To quote Fisher: “Either there is something in the treatment, or a coincidence has occurred such as does not occur more than once in twenty trials.”
Once in twenty was a reasonable level for an event occurring by chance (rather than as a result of some new fertilizer or drug) in an experiment in biological, agricultural or medical research in 1900s. Is it a reasonable level for chance events in software engineering?
A one in twenty chance of a new technique resulting in a building falling down would not be considered acceptable in civil engineering. In high energy physics a p-value of  is used to decide whether a new particle has been discovered (or not).
is used to decide whether a new particle has been discovered (or not).
In business p-values should be treated as part of cost/benefit analysis. How confident are we that this effect is for real, how much would it cost to be right or wrong about it? Using a cut-off value to make yes/no decisions (e.g., 0.049 yes, 0.051 no) is very simplistic decision making.
To get a paper published in a software engineering journal requires any data analysis to have p-values below 0.05. In this regard the editors are aping journals in the social sciences; in fact the high impact social science journals require p-values below 0.01 (the high impact journals receive more submissions and can afford to be choosier about what they publish).
What is a sensible choice for a p-value cur-off in software engineering journals? The simple answer is: As low as possible, given the need to accept  papers per month for publication. A more complicated answer would involve different cut-offs for different kinds of measurements, e.g., measuring people or measuring code.
papers per month for publication. A more complicated answer would involve different cut-offs for different kinds of measurements, e.g., measuring people or measuring code.
While the p-value attracts plenty of criticism, there is nothing wrong with p-values. Use of p-values has a dominant market position in statistics and they are frequently misused by the clueless and those wanting to mislead their audience. Any other technique is just as likely to be misused, if not more so.
The killer phrase associated with p-values is “statistically significant”, often abbreviated to just “significant”. How people love to describe the results of their measurements as being shown to be “significant”. Of course, I am free to choose whatever p-value cut-off I like for my experiments and then claim the results are significant. I have had researchers repeatedly tell me that their results were “significant”, every time I asked them about p-values; a serious red flag.
When dealing with statistical results, ask yourself what the reported p-values mean to you. Don’t accept the 0.05 is the cut-off that everybody uses nonsense. If the research won’t reveal actual p-values, walk away from the snake oil.
Software engineering data sets
The pretty pictures from my empirical software engineering book are now online, along with the 210 data sets and R code (330M).
Plotting the number of data sets in each year shows that empirical software engineering has really taken off in the last 10 years (code+data). Around dozen or so confidential data sets are not included; I am only writing about data that can be made public.
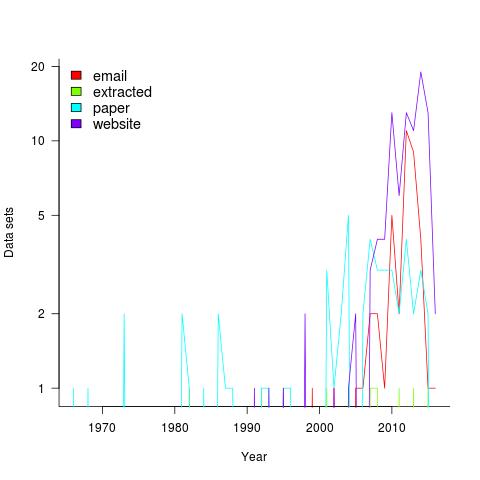
It used to be rare to find the data associated with a paper on the author’s website. Of course, before around 1995 there was no web, but since around 2012 the idea has started to take off.
Contact via email goes back to 1985 and before that people sent mag tapes through the post and many years ago somebody sent me punched tape (there is nothing like seeing the bits with the naked eye).
I have sent several hundred emails asking for data and received 55 data sets. I’m hoping this release will spur those who have promised me data to invest some time to send it.
My experience is that research data often lives on laptops and dies when the laptop is replaced (a study of biologists, who have been collecting data for hundreds of years, found a data ‘death rate’ of 17% a year). Had I started actively collecting data before 2010 the red line in the plot would be much higher for earlier years; I often received data from authors when writing my C book at the start of the century (Google went from nothing to being the best place to search, while I wrote).
In nine cases I extracted the data, either from the pdf or an image and then reverse engineered values.
I have around 50 data sets waiting to be processed. Given that lots more are bound to arrive before the book is finished, I expect to easily reach the 300 mark. A tiny number given my aim of writing about all software engineering issues for which public data exists.
If you know of interesting software engineering data, that is not to be found in these plots, please let me know.
Does using formal methods mean anything?
What counts as use of formal methods in software development?
Mathematics is involved, but then mathematics is involved in almost every aspect of software.
Formal methods are founded on the lie that doing things in mathematics means the results must be correct. There are plenty of mistakes in published mathematical proofs, as any practicing mathematician will tell you. The stuff that gets taught at school and university has been thoroughly checked and stood the test of time; the new stuff could be as bug written as software.
In the 1970s and 1980s formals methods was all about use of notation and formalisms. Writing algorithms, specifications, requirements, etc. in what looked like mathematical notation was called formal methods. The hope was that one day a tool would be available to check that what had been written did indeed have the characteristics being claimed, e.g., consistency, completeness, fault free (whatever that meant).
While everybody talked about automatic checking tools, what people spent their time doing was inventing new notations and formalisms. You were not a respected formal methods researcher unless you had several published papers, and preferably a book, describing your own formalism.
The market leader was VDM, mainly due to the work/promotion by Dansk Datamatik Center. I was a fan of Denotational semantics. There are even ISO standards for a couple of formal specification languages.
Fast forward to the last 10 years. What counts as done using formal methods today?
These days researchers who claim to be “doing formal methods” seem to be by writing code (which is an improvement over writing symbols on paper; it helps that today’s computers are orders of magnitude more powerful). The code written involves proof assistants such as Coq and Isabelle and programming languages such as OCaml and Haskell.
Can anybody writing code in OCaml or Haskell claim to be doing formal methods, or does a proof assistant of some kind have to be involved in the process?
If a program’s source code is translated into a form that can be handled by a proof assistant, can the issue of correctness of the translation be ignored? There is one research group who thinks it is ok to “trust” the translation process.
If one component of a program (say, parts of a compiler’s code generator) have been analyzed using a proof assistant, is it ok to claim that the entire program (perhaps the syntax and semantics processing that happens before code generation) has been formally verified? There is one research group who think such claims can be made about the entire program.
If I write a specification in Visual Basic, map this specification into C and involve formal methods at some point(s) in the process, then is it ok for me to claim that the correctness of the C implementation has been formally verified? There seem to be enough precedents for this claim to be viable.
In this day and age, is the use of formal methods anything more than a sign of intellectual dishonesty? Or is it just that today’s researchers are lazy, unwilling to put the effort into making sure that claims of correctness are proved start to finish?
‘to program’ is 70 this month
‘To program’ was first used to describe writing programs in August 1946.
The evidence for this is contained in First draft of a report on the EDVAC by John von Neumann and material from the Moore School lectures. Lecture 34, held on 7th August, uses “program” in its modern sense.
My copy of the Shorter Oxford English Dictionary, from 1976, does not list the computer usage at all! Perhaps, only being 30 years old in 1976, the computer usage was only considered important enough to include in the 20 volume version of the dictionary and had to wait a few more decades to be included in the shorter 2 volume set. Can a reader with access to the 20 volume set from 1976 confirm that it does include a computer usage for program?
Program, programme, 1633. [orig., in spelling program, – Gr.-L. programma … reintroduced from Fr. programme, and now more usu. so spelt.] … 1. A public notice … 2. A descriptive notice,… a course of study, etc.; a prospectus, syllabus; now esp. a list of the items or ‘numbers’ of a concert…
It would be another two years before a stored program computer was available ‘to program’ computers in a way that mimics how things are done today.
Grier ties it all together in a convincing argument in his paper: “The ENIAC, the verb “to program” and the emergence of digital computers” (cannot find a copy outside a paywall).
Steven Wolfram does a great job of untangling Ada Lovelace’s computer work. I think it is true to say that Lovelace is the first person to think like a programmer, while Charles Babbage was the first person to think like a computer hardware engineer.
If you encounter somebody claiming to have been programming for more than 70 years, they are probably embellishing their cv (in the late 90s I used to bump into people claiming to have been using Java for 10 years, i.e., somewhat longer than the language had existed).
Update: Oxford dictionaries used to come with an Addenda (thanks to Stephen Cox for reminding me in the comments; my volume II even says “Marl-Z and Addenda” on the spine).
Program, programme. 2. c. Computers. A fully explicit series of instructions which when fed into a computer will automatically direct its operation in carrying out a specific task 1946. Also as v. trans., to supply (a computer) with a p.; to cause (a computer) to do something by this means; also, to express as or in a p. Hence Programming vbl. sbl., the operation of programming a computer; also, the writing or preparation of programs. Programmer, a person who does this.
ALGEC: ALGorithmic language for EConomic problems
I have been reading about ALGEC, the computer language invented in the Soviet Union during the early 1960s, courtesy of a translation of the article Report on the Working Sessions of the Group on Algorithmic Languages for Processing Economic Information (GAIAPEI) by Rand.
The Soviet Union ran a command economy and the job of computers was obviously to process economic information.
The language is based on Algol 60, the default base language for the design of most establishment driven programming languages.
Since the Soviets were the only country to build a computer that used ternary logic, I was hoping that the language would include support for this ‘feature’. No such luck.
Two features caught by attention:
- Keywords can be written in a form that denotes their gender and number. For instance,
Booleancan be written:логическое(neuter),логический(masculine),логическая(feminine) andлогические(plural). - The keyword for the go to token is
to. There is obviously something about the use of Russian that makes it obvious that the word go should not be part of this keyword.
Do readers know of any other computer language which have been influence by features of the designers native human language (apart, obviously from all the English derived computer languages)?
Happy 10th birthday to CREST
Most university departments run regularly seminars and in July 2001 I attended a half day workshop run by Mark Harman at Brunel University. Over the years the workshop has changed names, locations and grown into a two day event with a worldwide reputation.
When Mark became professor of software engineering at University College London, the workshops became known as the CREST Open Workshops and next month the 47th workshop will celebrate 10 years of the CREST centre. Workshops vary from being mostly theory oriented to mostly practice oriented; the contents is always leading edge stuff. For many years the talks have been filmed and the back catalog contains plenty of interesting material.
If you are interested in the latest software engineering related issues, at a rather technical level, then keep an eye out for upcoming CREST workshops. The theory/practice orientation of a workshop is usually easy to guess from the style of papers written by the speakers. There are other software engineering groups dotted around the world; I have no experience of their seminars/workshops, but I’m sure they will make you feel welcome.
So, here’s to another 10 years of interesting workshops.
Some CREST related blog posts:
Human vs automatically generated source code: an arms race?
Machine learning in SE research is a bigger train wreck than I imagined
Hardware variability may be greater than algorithmic improvement
Workshop on App Store Analysis
Fortran & Cobol in the USAF over the years 1955-1986
I recently discovered a new dataset from Rome’s golden age, going back to 1955. Who knew that in 1955 the US Air Force took delivery of 133,075 lines of Cobol? The plot below shows lines of code against year, broken down by major languages used.
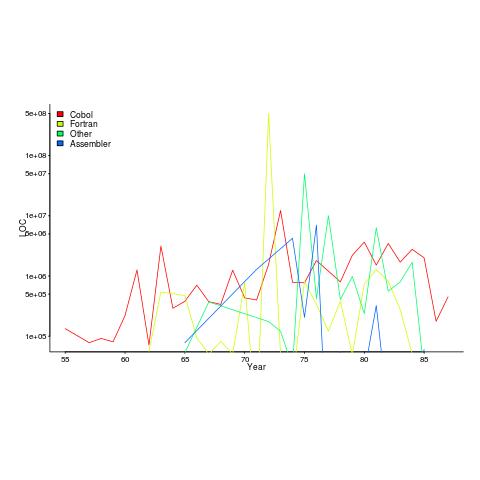
I got the data from the Master’s thesis of Captain NeSmith II (there is probably more software engineering data to be found in US Air Force officers’ Master’s thesis than all published academic papers before 2005). Captain NeSmith got his data from the Information Systems Designator (ISD) database maintained by the Standard Information Systems Center (SISC); the data does not include classified project and embedded systems. This database contained more data than appeared in the thesis, but I cannot find it anywhere.
Given the spiky nature of the data I’m guessing that LOC and development costs are counted in the year a project is delivered. Maintenance costs are through to financial year 1984.
The big question that jumps out of the data is “What project delivered 0.5 billion lines of Fortran in 1972?”
The LOC for Assemble suspiciously does not occur before 1965.
In the 1980s people were always talking about the billion+ lines of Cobol in use by the US Government. Over the 31 year span of this USAF data, 46 million lines of Cobol were delivered at a cost of $0.5 billion. Did another 50 arms of the government produce similar amounts of Cobol? Is the USAF under/over representative of Cobol?
The plot below shows yearly LOC against development cost, plus fitted regression lines.
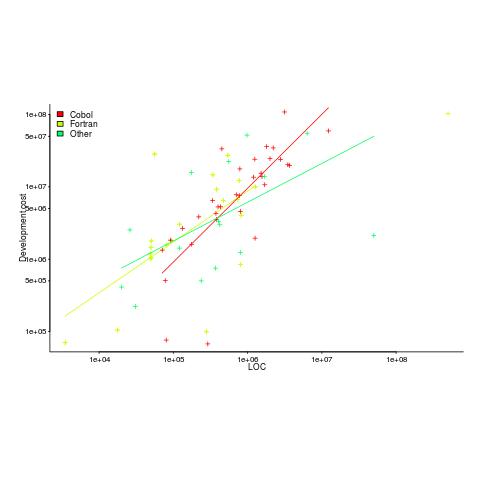
Using development cost as a proxy for effort, the coefficients of the fitted lines were close to those I fitted to Boehm’s embedded data (i.e., the exponents were lower than those listed by Boehm); Fortran 0.7, Cobol 1 and Other 0.5 (the huge Fortran outlier was excluded).
Adding Year to the regression model shows than Fortran development cost decreased by around 8% per year. Cobol may have been around 1% per year, depending on which model is chosen.
The maintenance costs can be plotted, but there is just too much uncertainty about them to say anything sensible (was inflation taken into account, how heavily used were the programs {more usage find more faults and demand for more features}, etc.).
NeSmith’s thesis contains a lot more data. The reproduction quality is not great, so the numbers have to be typed in. If you find any bugs in my data+code, please let me know and if you type in any of the other tables I would love a copy.
Recent Comments