Archive
Christmas books for 2019
The following are the really, and somewhat, interesting books I read this year. I am including the somewhat interesting books to bulk up the numbers; there are probably more books out there that I would find interesting. I just did not read many books this year, what with Amazon recommends being so user unfriendly, and having my nose to the grindstone finishing a book.
First the really interesting.
I have already written about Good Enough: The Tolerance for Mediocrity in Nature and Society by Daniel Milo.
I have also written about The European Guilds: An economic analysis by Sheilagh Ogilvie. Around half-way through I grew weary, and worried readers of my own book might feel the same. Ogilvie nails false beliefs to the floor and machine-guns them. An admirable trait in someone seeking to dispel the false beliefs in current circulation. Some variety in the nailing and machine-gunning would have improved readability.
Moving on to first half really interesting, second half only somewhat.
“In search of stupidity: Over 20 years of high-tech marketing disasters” by Merrill R. Chapman, second edition. This edition is from 2006, and a third edition is promised, like now. The first half is full of great stories about the successes and failures of computer companies in the 1980s and 1990s, by somebody who was intimately involved with them in a sales and marketing capacity. The author does not appear to be so intimately involved, starting around 2000, and the material flags. Worth buying for the first half.
Now the somewhat interesting.
“Can medicine be cured? The corruption of a profession” by Seamus O’Mahony. All those nonsense theories and practices you see going on in software engineering, it’s also happening in medicine. Medicine had a golden age, when progress was made on finding cures for the major diseases, and now it’s mostly smoke and mirrors as people try to maintain the illusion of progress.
“Who we are and how we got here” by David Reich (a genetics professor who is a big name in the field), is the story of the various migrations and interbreeding of ‘human-like’ and human peoples over the last 50,000 years (with some references going as far back as 300,000 years). The author tries to tell two stories, the story of human migrations and the story of the discoveries made by his and other people’s labs. The mixture of stories did not work for me; the story of human migrations/interbreeding was very interesting, but I was not at all interested in when and who discovered what. The last few chapters went off at a tangent, trying to have a politically correct discussion about identity and race issues. The politically correct class are going to hate this book’s findings.
“The Digital Party: Political organization and online democracy” by Paolo Gerbaudo. The internet has enabled some populist political parties to attract hundreds of thousands of members. Are these parties living up to their promises to be truly democratic and representative of members wishes? No, and Gerbaudo does a good job of explaining why (people can easily join up online, and then find more interesting things to do than read about political issues; only a few hard code members get out from behind the screen and become activists).
Suggestions for books that you think I might find interesting welcome.
A study, a replication, and a rebuttal; SE research is starting to become serious
tldr; A paper makes various claims based on suspect data. A replication finds serious problems with the data extraction and analysis. A rebuttal paper spins the replication issues as being nothing serious, and actually validating the original results, i.e., the rebuttal is all smoke and mirrors.
When I first saw the paper: A Large-Scale Study of Programming Languages and Code Quality in Github, the pdf almost got deleted as soon as I started scanning the paper; it uses number of reported defects as a proxy for code quality. The number of reported defects in a program depends on the number of people using the program, more users will generate more defect reports. Unfortunately data on the number of people using a program is extremely hard to come by (I only know of one study that tried to estimate number of users); studies of Java have also found that around 40% of reported faults are requests for enhancement. Most fault report data is useless for the model building purposes to which it is put.
Two things caught my eye, and I did not delete the pdf. The authors have done good work in the past, and they were using a zero-truncated negative binomial distribution; I thought I was the only person using zero-truncated negative binomial distributions to analyze software engineering data. My data analysis alter-ego was intrigued.
Spending a bit more time on the paper confirmed my original view, it’s conclusions were not believable. The authors had done a lot of work, this was no paper written over a long weekend, but lots of silly mistakes had been made.
Lots of nonsense software engineering papers get published, nothing to write home about. Everybody gets writes a nonsense paper at some point in their career, hopefully they get caught by reviewers and are not published (the statistical analysis in this paper was probably above the level familiar to most software engineering reviewers). So, move along.
At the start of this year, the paper: On the Impact of Programming Languages on Code Quality: A Reproduction Study appeared, published in TOPLAS (the first was in CACM, both journals of the ACM).
This replication paper gave a detailed analysis of the mistakes in data extraction, and the sloppy data analyse performed in the original work. Large chunks of the first study were cut to pieces (finding many more issues than I did, but not pointing out the missing usage data). Reading this paper now, in more detail, I found it a careful, well argued, solid piece of work.
This publication is an interesting event. Replications are rare in software engineering, and this is the first time I have seen a take-down (of an empirical paper) like this published in a major journal. Ok, there have been previous published disagreements, but this is machine learning nonsense.
The Papers We Love meetup group ran a mini-workshop over the summer, and Jan Vitek gave a talk on the replication work (unfortunately a problem with the AV system means the videos are not available on the Papers We Love YouTube channel). I asked Jan why they had gone to so much trouble writing up a replication, when they had plenty of other nonsense papers to choose from. His reasoning was that the conclusions from the original work were starting to be widely cited, i.e., new, incorrect, community-wide beliefs were being created. The finding from the original paper, that has been catching on, is that programs written in some languages are more/less likely to contain defects than programs written in other languages. What I think is actually being measured is number of users of the programs written in particular languages (a factor not present in the data).
Yesterday, the paper Rebuttal to Berger et al., TOPLAS 2019 appeared, along with a Medium post by two of the original authors.
The sequence: publication, replication, rebuttal is how science is supposed to work. Scientists disagree about published work and it all gets thrashed out in a series of published papers. I’m pleased to see this is starting to happen in software engineering, it shows that researchers care and are willing to spend time analyzing each others work (rather than publishing another paper on the latest trendy topic).
From time to time I had considered writing a post about the first two articles, but an independent analysis of the data meant some serious thinking, and I was not that keen (since I did not think the data went anywhere interesting).
In the academic world, reputation and citations are the currency. When one set of academics publishes a list of mistakes, errors, oversights, blunders, etc in the published work of another set of academics, both reputation and citations are on the line.
I have not read many academic rebuttals, but one recurring pattern has been a pointed literary style. The style of this Rebuttal paper is somewhat breezy and cheerful (the odd pointed phrase pops out every now and again), attempting to wave off what the authors call general agreement with some minor differences. I have had some trouble understanding how the rebuttal points discussed are related to the problems highlighted in the replication paper. The tone of the medium post is that there is nothing to see here, let’s all move on and be friends.
An academic’s work is judged by the number of citations it has received. Citations are used to help decide whether someone should be promoted, or awarded a grant. As I write this post, Google Scholar listed 234 citations to the original paper (which is a lot, most papers have one or none). The abstract of the Rebuttal paper ends with “…and our paper is eminently citable.”
The claimed “Point-by-Point Rebuttal” takes the form of nine alleged claims made by the replication authors. In four cases the Claim paragraph ends with: “Hence the results may be wrong!”, in two cases with: “Hence, FSE14 and CACM17 can’t be right.” (these are references to the original conference and journal papers, respectively), and once with: “Thus, other problems may exist!”
The rebuttal points have a tenuous connection to the major issues raised by the replication paper, and many of them are trivial issues (compared to the real issues raised).
Summary bullet points (six of them) at the start of the Rebuttal discuss issues not covered by the rebuttal points. My favourite is the objection bullet point claiming a preference, in the replication, for the use of the Bonferroni correction rather than FDR (False Discovery Rate). The original analysis failed to use either technique, when it should have used one or the other, a serious oversight; the replication is careful and does the analysis using both.
I would be very surprised if the Rebuttal paper, in its current form, gets published in any serious journal; it’s currently on a preprint server. It is not a serious piece of work.
Somebody who has only read the Rebuttal paper would take away a strong impression that the criticisms in the replication paper were trivial, and that the paper was not a serious piece of work.
What happens next? Will the ACM appoint a committee of the great and the good to decide whether the CACM article should be retracted? We are not talking about fraud or deception, but a bunch of silly mistakes that invalidate the claimed findings. Researchers are supposed to care about the integrity of published work, but will anybody be willing to invest the effort needed to get this paper retracted? The authors will not want to give up those 234, and counting, citations.
Update
The replication authors have been quick off the mark and posted a rebuttal of the Rebuttal.
The rebuttal of the Rebuttal has been written in the style that rebuttals are supposed to be written in, i.e., a point by point analysis of the issues raised.
Now what? I have no idea.
Design considerations for Mars colony computer systems
A very interesting article discussing SpaceX’s dramatically lower launch costs has convinced me that, in a decade or two, it will become economically viable to send people to Mars. Whether lots of people will be willing to go is another matter, but let’s assume that a non-trivial number of people decide to spend many years living in a colony on Mars; what computing hardware and software should they take with them?
Reliability and repairability are crucial. Same-day delivery of replacement parts is not an option; the opportunity for Earth/Mars travel occurs every 2-years (when both planets are on the same side of the Sun), and the journey takes 4-10 months.
Given the much higher radiation levels on Mars (200 mS/year; on Earth background radiation is around 3 mS/year), modern microelectronics will experience frequent bit-flips and have a low survival rate. Miniaturization is great for packing billions of transistors into a device, but increases the likelihood that a high energy particle traveling through the device will create a permanent short-circuit; Moore’s law has a much shorter useful life on Mars, compared to Earth. The lesser high energy particles can flip the current value of one or more bits.
Reliability and repairability of electronics, compared to other compute and control options, dictates minimizing the use of electronics (pneumatics is a viable replacement for many tasks; think World War II submarines), and simple calculation can be made using a slide rule or mechanical calculator (both are reliable, and possible to repair with simple tools). Some of the issues that need to be addressed when electronic devices are a proposed solution include:
- integrated circuits need to be fabricated with feature widths that are large enough such that devices are not unduly affected by background radiation,
- devices need to be built from exchangeable components, so if one breaks the others can be used as spares. Building a device from discrete components is great for exchangeability, but is not practical for building complicated cpus; one solution is to use simple cpus, and integrated circuits come in various sizes.
- use of devices that can be repaired or new ones manufactured on Mars. For instance, core memory might be locally repairable, and eventually locally produced.
There are lots of benefits from using the same cpu for everything, with ARM being the obvious choice. Some might suggest RISC-V, and perhaps this will be a better choice many years from now, when a Mars colony is being seriously planned.
Commercially available electronic storage devices have lifetimes measured in years, with a few passive media having lifetimes measured in decades (e.g., optical media); some early electronic storage devices had lifetimes likely to be measured in decades. Perhaps it is possible to produce hard discs with expected lifetimes measured in decades, research is needed (or computing on Mars will have to function without hard discs).
The media on which the source is held will degrade over time. Engraving important source code on the walls of colony housing is one long term storage technique; rather like the hieroglyphs on ancient Egyptian buildings.
What about displays? Have lots of small, same size, flat-screens, and fit them together for greater surface area. I don’t know much about displays, so won’t say more.
Computers built from discrete components consume lots of power (much lower power consumption is a benefit of fabricating smaller devices). No problem, they can double as heating systems. Switching power supplies can be very reliable.
Radio communications require electronics. The radios on the Voyager spacecraft have been operating for 42 years, which suggests to me that reliable communication equipment can be built (I know very little about radio electronics).
What about the software?
Repairability requires that software be open source, or some kind of Mars-use only source license.
The computer language of choice is obviously C, whose advantages include:
- lots of existing, heavily used, operating systems are written in C (i.e., no need to write, and extensively test, a new one),
- C compilers are much easier to implement than, say, C++ or Java compilers. If the C compiler gets lost, somebody could bootstrap another one (lots of individuals used to write and successfully sell C compilers),
- computer storage will be a premium on Mars based computers, and C supports getting close to the hardware to maximise efficient use of resources.
The operating system of choice may not be Linux. With memory at a premium, operating systems requiring many megabytes are bad news. Computers with 64k of storage (yes, kilobytes) used to be used to do lots of useful work; see the source code of various 1980’s operating systems.
Applications can be written before departure. Maintainability and readability are marketing terms, i.e., we don’t really know how to do this stuff. Extensive testing is a good technique for gaining confidence that software behaves as expected, and the test suite can be shipped with the software.
Adjectives in source code analysis
The use of adjectives to analysis source code is something of a specialist topic. This post can only increase the number of people using adjectives for this purpose (because I don’t know anybody else who does 😉
Until recently the only adjective related property I used to help analyse source was relative order. When using multiple adjective, people have a preferred order, e.g., in English size comes before color, as in “big red” (“red big” sounds wrong), and adjectives always appear before the noun they modify. Native speakers of different languages have various preferred orders. Source code may appear to only contain English words, but adjective order can provide a clue about the native language of the developer who wrote it, because native ordering leaks into English usage.
Searching for adjective patterns (or any other part-of-speech pattern) in identifiers used to be complicated (identifiers first had to be split into their subcomponents). Now, thanks to Vadim Markovtsev, 49 million token-split identifiers are available. Happy adjective pattern matching (Size Shape Age Color is a common order to start with; adjective pairs are found in around 0.1% of identifiers; some scripts).
Until recently, gradable adjectives were something that I had been vaguely aware of; these kinds of adjectives indicate a position on a scale, e.g., hot/warm/cold water. The study Grounding Gradable Adjectives through Crowdsourcing included some interesting data on the perceived change of an attribute produced by the presence by a gradable adjective. The following plot shows perceived change in quantity produced by some quantity adjectives (code+data):

How is information about gradable adjectives useful for analyzing source code?
One pattern that jumps out of the plot is that variability, between people, increases as the magnitude specified by the adjective increases (the x-axis shows standard deviations from the mean response). Perhaps the x-axis should use a log scale, there are lots of human related response characteristics that are linear on a log scale (I’m using the same scale as the authors of the study; the authors were a lot more aggressive in removing outliers than I have been), e.g., response to loudness of sound and Hick’s law.
At the moment, it looks as if my estimate of the value of a “small x” is going to be relatively closer to another developers “small x“, than our relative estimated value for a “huge x“.
Student projects for 2019/2020
It’s that time of year when students are looking for an interesting idea for a project (it might be a bit late for this year’s students, but I have been mulling over these ideas for a while, and might forget them by next year). A few years ago I listed some suggestions for student projects, as far as I know none got used, so let’s try again…
Checking the correctness of the Python compilers/interpreters. Lots of work has been done checking C compilers (e.g., Csmith), but I cannot find any serious work that has done the same for Python. There are multiple Python implementations, so it would be possible to do differential testing, another possibility is to fuzz test one or more compiler/interpreter and see how many crashes occur (the likely number of remaining fault producing crashes can be estimated from this data).
Talking to the Python people at the Open Source hackathon yesterday, testing of the compiler/interpreter was something they did not spend much time thinking about (yes, they run regression tests, but that seemed to be it).
Finding faults in published papers. There are tools that scan source code for use of suspect constructs, and there are various ways in which the contents of a published paper could be checked.
Possible checks include (apart from grammar checking):
- incorrect or inaccurate numeric literals.
Checking whether the suspect formula is used is another possibility, provided the formula involved contains known constants.
- inconsistent statistics reported (e.g., “8 subjects aged between 18-25, average age 21.3″ may be correct because 21.3*8 == 170.4, ages must add to a whole number and the values 169, 170 and 171 would not produce this average), and various tools are available (e.g., GRIMMER).
Citation errors are relatively common, but hard to check automatically without a good database (I have found that a failure of a Google search to return any results is a very good indicator that the reference does not exist).
There are lots of tools available for taking pdf files apart; I use pdfgrep a lot
Number extraction. Numbers are some of the most easily checked quantities, and anybody interested in fact checking needs a quick way of extracting numeric values from a document. Sometimes numeric values appear as numeric words, and dates can appear as a mixture of words and numbers. Extracting numeric values, and their possible types (e.g., date, time, miles, kilograms, lines of code). Something way more sophisticated than pattern matching on sequences of digit characters is needed.
spaCy is my tool of choice for this sort of text processing task.
Projects chapter of ‘evidence-based software engineering’ reworked
The Projects chapter of my evidence-based software engineering book has been reworked; draft pdf available here.
A lot of developers spend their time working on projects, and there ought to be loads of data available. But, as we all know, few companies measure anything, and fewer hang on to the data.
Every now and again I actively contact companies asking data, but work on the book prevents me spending more time doing this. Data is out there, it’s a matter of asking the right people.
There is enough evidence in this chapter to slice-and-dice much of the nonsense that passes for software project wisdom. The problem is, there is no evidence to suggest what might be useful and effective theories of software development. My experience is that there is no point in debunking folktales unless there is something available to replace them. Nature abhors a vacuum; a debunked theory has to be replaced by something else, otherwise people continue with their existing beliefs.
There is still some polishing to be done, and a few promises of data need to be chased-up.
As always, if you know of any interesting software engineering data, please tell me.
Next, the Reliability chapter.
Three books discuss three small data sets
During the early years of a new field, experimental data relating to important topics can be very thin on the ground. Ever since the first computer was built, there has been a lot of data on the characteristics of the hardware. Data on the characteristics of software, and the people who write it, has been (and often continues to be) very thin on the ground.
Books are sometimes written by the researchers who produce the first data associated with an important topic, even if the data set is tiny; being first often generates enough interest for a book length treatment to be considered worthwhile.
As a field progresses lots more data becomes available, and the discussion in subsequent books can be based on findings from more experiments and lots more data
Software engineering is a field where a few ‘first’ data books have been published, followed by silence, or rather lots of arm waving and little new data. The fall of Rome has been followed by a 40-year dark-age, from which we are slowly emerging.
Three of these ‘first’ data books are:
- “Man-Computer Problem Solving” by Harold Sackman, published in 1970, relating to experimental data from 1966. The experiments investigated the impact of two different approaches to developing software, on programmer performance (i.e., batch processing vs. on-line development; code+data). The first paper on this work appeared in an obscure journal in 1967, and was followed in the same issue by a critique pointing out the wide margin of uncertainty in the measurements (the critique agreed that running such experiments was a laudable goal).
Failing to deal with experimental uncertainty is nothing compared to what happened next. A 1968 paper in a widely read journal, the Communications of the ACM, contained the following table (extracted from a higher quality scan of a 1966 report by the same authors, and available online).
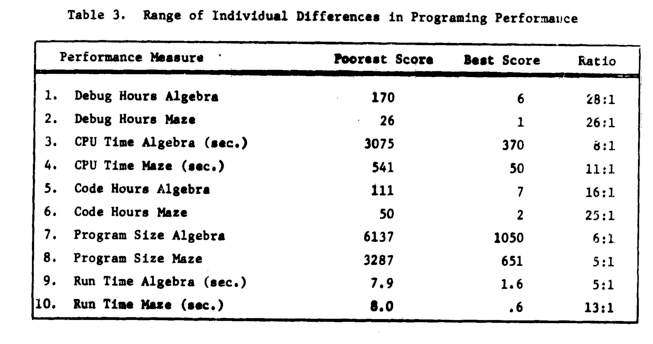
The tale of 1:28 ratio of programmer performance, found in an experiment by Grant/Sackman, took off (the technical detail that a lot of the difference was down to the techniques subjects’ used, and not the people themselves, got lost). The Grant/Sackman ‘finding’ used to be frequently quoted in some circles (or at least it did when I moved in them, I don’t know often it is cited today). In 1999, Lutz Prechelt wrote an expose on the sorry tale.
Sackman’s book is very readable, and contains lots of details and data not present in the papers, including survey data and a discussion of the intrinsic uncertainties associated with the experiment; it also contains the table above.
- “Software Engineering Economics” by Barry W. Boehm, published in 1981. I wrote about the poor analysis of the data contained in this book a few years ago.
The rest of this book contains plenty of interesting material, and even sounds modern (because books moving the topic forward have not been written).
- “Program Evolution: Process of Software Change” edited by M. M. Lehman and L. A. Belady, published in 1985, relating to experimental data from 1977 and before. Lehman and Belady managed to obtain data relating to 19 releases of an IBM software product (yes, 19, not nineteen-thousand); the data was primarily the date and number of modules contained in each release, plus less specific information about number of statements. This data was sliced and diced every which way, and the book contains many papers with the same data appearing in the same plot with different captions (had the book not been a collection of papers it would have been considerably shorter).
With a lot less data than Isaac Newton had available to formulate his three laws, Lehman and Belady came up with five, six, seven… “laws of software evolution” (which themselves evolved with the publication of successive papers).
The availability of Open source repositories means there is now a lot more software system evolution data available. Lehman’s laws have not stood the test of more data, although people still cite them every now and again.
Comparing expression usage in mathematics and C source
Why does a particular expression appear in source code?
One reason is that the expression is the coded form of a formula from the application domain, e.g.,  .
.
Another reason is that the expression calculates an algorithm/housekeeping related address, or offset, to where a value of interest is held.
Most people (including me, many years ago) think that the majority of source code expressions relate to the application domain, in one-way or another.
Work on a compiler related optimizer, and you will soon learn the truth; most expressions are simple and calculate addresses/offsets. Optimizing compilers would not have much to do, if they only relied on expressions from the application domain (my numbers tool throws something up every now and again).
What are the characteristics of application domain expression?
I like to think of them as being complicated, but that’s because it used to be in my interest for them to be complicated (I used to work on optimizers, which have the potential to make big savings if things are complicated).
Measurements of expressions in scientific papers is needed, but who is going to be interested in measuring the characteristics of mathematical expressions appearing in papers? I’m interested, but not enough to do the work. Then, a few weeks ago I discovered: An Analysis of Mathematical Expressions Used in Practice, by Clare So; an analysis of 20,000 mathematical papers submitted to arXiv between 2000 and 2004.
The following discussion uses the measurements made for my C book, as the representative source code (I keep suggesting that detailed measurements of other languages is needed, but nobody has jumped in and made them, yet).
The table below shows percentage occurrence of operators in expressions. Minus is much more common than plus in mathematical expressions, the opposite of C source; the ‘popularity’ of the relational operators is also reversed.
Operator Mathematics C source = 0.39 3.08 - 0.35 0.19 + 0.24 0.38 <= 0.06 0.04 > 0.041 0.11 < 0.037 0.22 |
The most common single binary operator expression in mathematics is n-1 (the data counts expressions using different variable names as different expressions; yes, n is the most popular variable name, and adding up other uses does not change relative frequency by much). In C source var+int_constant is around twice as common as var-int_constant
The plot below shows the percentage of expressions containing a given number of operators (I’ve made a big assumption about exactly what Clare So is counting; code+data). The operator count starts at two because that is where the count starts for the mathematics data. In C source, around 99% of expressions have less than two operators, so the simple case completely dominates.
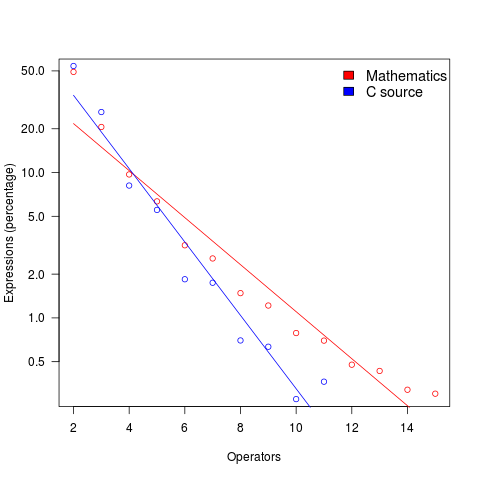
For expressions containing between two and five operators, frequency of occurrence is sort of about the same in mathematics and C, with C frequency decreasing more rapidly. The data disagrees with me again…
Cost ratio for bespoke hardware+software
What percentage of the budget for a bespoke hardware/software system is spent on software, compared to hardware?
The plot below has become synonymous with this question (without the red line, which highlights 1973), and is often used to claim that software costs are many times more than hardware costs.

The paper containing this plot was published in 1973 (the original source is a Rome period report), and is an extrapolation of data I assume was available in 1973, into what was then the future. The software and hardware costs are for bespoke command and control systems delivered to the U.S. Air Force, not commercial off-the-shelf solutions or even bespoke commercial systems.
Does bespoke software cost many times more than the hardware it runs on?
I don’t have any data that might be used to answer this questions, to any worthwhile degree of accuracy. I know of situations where I believe the bespoke software did cost a lot more than the hardware, and I know of some where the hardware cost more (I have never been privy to exact numbers on large projects).
Where did the pre-1973 data come from?
The USAF funded the creation of lots of source code, and the reports cite hardware and software figures from 1972.
To summarise: the above plot is for USAF spending on bespoke command and control hardware and software, and is extrapolated from 1973 into the future.
C compilers on PR1ME computers
At the start of this week I knew almost nothing about the C compilers running on PR1ME computers (every now and again I check bitsavers for newly scanned C compiler manuals).
On Tuesday I spotted the source of the Georgia Tech C Compiler for Prime Computers (which was believed lost until two 35-years old mag tapes were found); the implementation language is Ratfor.
I posted the information to the comp.compilers newsgroup, and in the ensuing posts I learned about Dennis Boone’s collection of scanned PR1ME manuals, including a C compiler user guide. This C user’s guide is for the Conboy/Pacer software compiler, not the one whose sources I linked to above.
The PR1ME C compiler has the usually assortment of vendor extensions, and missing features, of the kind that might be found in any C compiler from the 1980s; however, there is a larger than usual collection of infrequently seen characteristics. I spotted the following during a quick read through the manual:
- addresses point to 16-bit words (not 8-bit bytes). The implementers could have chosen to define a
charas 16-bit (i.e., defining the standard macroCHAR_BITas 16), but they went with 8-bit chars. Handling 8-bit chars on a word addressed processor means that pointers tocharhave to include a bit specifying which half of the 16-bits they are pointing to. Some Cray computers had the same issue, except their words contained 64 bits, so more offset bits had to be stored in pointers.The definition of an object having type
charoccupies 8 bits of a word, no other object is allocated in the other 8 bits; arrays ofcharare packed, two chars to a word. - ASCII characters have the top-bit set (the manual phrases this as “The basic character set … ASCII 7-bit set (called ASCII-7), with the eighth bit turned on.”). The C standard requires that the ten digit characters have continuous values, and that the basic character set be representable in a char.
- a pointer type may contain more bits than any supported integer type, i.e., 48-bit pointer and 32-bit integer. PR1ME cpus supported a dizzying array of different modes and instruction sets; some later instruction sets/modes support 48-bit pointers.
- “On some other machines, you may write code in which a function is called with more or fewer parameters than the function actually expects. Such code may work correctly on the 50 Series, but only if the missing or extra parameter is never referenced.”
- “On some other machines, programs run correctly if function return value data types are left undeclared. … If this function is not explicitly defined as returning a pointer, the default return value is type int. Such a program may run correctly on some machines, but not on a 50 Series machine.”
These characteristics combine to make the PR1ME a very unfriendly environment for C programs.
C programmers have a culture, the C way of doing things (these cultures exist for all languages), and the characteristics of this (and perhaps other) PR1ME C compilers run counter to this culture in many ways.
I’m not saying that C culture is good or bad, just that it exists and PR1ME is a very poor fit.
What elements of C culture clash with the PR1ME implementation?
There is an expectation that when two objects having char type are defined sequentially (e.g., char a, b;), it will be possible to access b by adding 1 to a pointer to a (as if the definition had been written as: char a[2];). Yes, this practice is now frowned upon, but it was once considered ok (at least in some circles). On PR1ME the two definitions are not equivalent, from the pointer arithmetic point of view.
Very many developers assume that C characters use ASCII. Most of the time they do, but they are not required to; EBCDIC being perhaps the most well known alternative. At least in the PR1ME encoding the alphabetic characters have contiguous values, which they don’t in EBCDIC. But setting the top bit, hmmm….
The assumption that sizeof(int) == sizeof(pointer_type) is endemic in 1980s code, and much code in later decades; many (not so young) C programmers will tell you the story of the first time they had to switch mind-sets to: sizeof(long) == sizeof(pointer_type). Not having a 48-bit integer type is a bit of a killer for C on PR1ME, as we will find out.
PR1MOS, the vendor operating system, uses a function call stack layout that assumes a function definition specifies exactly how the function will be called, e.g., the number and type of parameters, and the return type.
In the early decades of C, programmers were very lax about specifying exactly what arguments a function expected, and that no return type implicitly specified an int return type (and since everybody knew that sizeof(int) == sizeof(pointer_type), this meant that it was not necessary to specify pointer return types).
During development, having the program raise an exception, or whatever the behavior was, when a function call did not match the defined type of the function, is useful; it improves program reliability by catching those cases that might work as expected a lot of the time, but not all the time.
A lot of existing code was created on systems that were forgiving of function call/definition mismatches. Such C source is unlikely to just compile and run under PR1MOS, i.e., porting other peoples programs is likely to be a time-consuming process.
Recent Comments