Archive
A new career in software development: advice for non-youngsters
Lately I have been encountering non-young people looking to switch careers, into software development. My suggestions have centered around the ageism culture and how they can take advantage of fashions in software ecosystems to improve their job prospects.
I start by telling them the good news: the demand for software developers outstrips supply, followed by the bad news that software development culture is ageist.
One consequence of the preponderance of the young is that people are heavily influenced by fads and fashions, which come and go over less than a decade.
The perception of technology progresses through the stages of fashionable, established and legacy (management-speak for unfashionable).
Non-youngsters can leverage the influence of fashion’s impact on job applicants by focusing on what is unfashionable, the more unfashionable the less likely that youngsters will apply, e.g., maintaining Cobol and Fortran code (both seriously unfashionable).
The benefits of applying to work with unfashionable technology include more than a smaller job applicant pool:
- new technology (fashion is about the new) often experiences a period of rapid change, and keeping up with change requires time and effort. Does somebody with a family, or outside interests, really want to spend time keeping up with constant change at work? I suspect not,
- systems depending on unfashionable technology have been around long enough to prove their worth, the sunk cost has been paid, and they will continue to be used until something a lot more cost-effective turns up, i.e., there is more job security compared to systems based on fashionable technology that has yet to prove their worth.
There is lots of unfashionable software technology out there. Software can be considered unfashionable simply because of the language in which it is written; some of the more well known of such languages include: Fortran, Cobol, Pascal, and Basic (in a multitude of forms), with less well known languages including, MUMPS, and almost any mainframe related language.
Unless you want to be competing for a job with hordes of keen/cheaper youngsters, don’t touch Rust, Go, or anything being touted as the latest language.
Databases also have a fashion status. The unfashionable include: dBase, Clarion, and a whole host of 4GL systems.
Be careful with any database that is NoSQL related, it may be fashionable or an established product being marketed using the latest buzzwords.
Testing and QA have always been very unsexy areas to work in. These areas provide the opportunity for the mature applicants to shine by highlighting their stability and reliability; what company would want to entrust some young kid with deciding whether the software is ready to be released to paying customers?
More suggestions for non-young people looking to get into software development welcome.
Evaluating estimation performance
What is the best way to evaluate the accuracy of an estimation technique, given that the actual values are known?
Estimates are often given as point values, and accuracy scoring functions (for a sequence of estimates) have the form }") , where
, where  is the number of estimated values,
is the number of estimated values,  the estimates, and
the estimates, and  the actual values; smaller
the actual values; smaller  is better.
is better.
Commonly used scoring functions include:
=(E-A)^2") , known as squared error (SE)
, known as squared error (SE)=delim{|}{E-A}{|}") , known as absolute error (AE)
, known as absolute error (AE)=delim{|}{E-A}{|}/A") , known as absolute percentage error (APE)
, known as absolute percentage error (APE)=delim{|}{E-A}{|}/E") , known as relative error (RE)
, known as relative error (RE)
APE and RE are special cases of: =delim{|}{1-(A/E)^{beta}}{|}") , with
, with  and
and  respectively.
respectively.
Let’s compare three techniques for estimating the time needed to implement some tasks, using these four functions.
Assume that the mean time taken to implement previous project tasks is known,  . When asked to implement a new task, an optimist might estimate 20% lower than the mean,
. When asked to implement a new task, an optimist might estimate 20% lower than the mean,  , while a pessimist might estimate 20% higher than the mean,
, while a pessimist might estimate 20% higher than the mean,  . Data shows that the distribution of the number of tasks taking a given amount of time to implement is skewed, looking something like one of the lines in the plot below (code):
. Data shows that the distribution of the number of tasks taking a given amount of time to implement is skewed, looking something like one of the lines in the plot below (code):
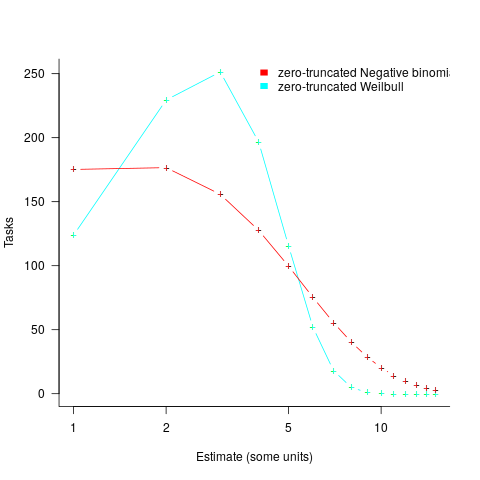
We can simulate task implementation time by randomly drawing values from a distribution having this shape, e.g., zero-truncated Negative binomial or zero-truncated Weibull. The values of  and
and  are calculated from the mean, , of the distribution used (see code for details). Below is each estimator’s score for each of the scoring functions (the best performing estimator for each scoring function in bold; 10,000 values were used to reduce small sample effects):
are calculated from the mean, , of the distribution used (see code for details). Below is each estimator’s score for each of the scoring functions (the best performing estimator for each scoring function in bold; 10,000 values were used to reduce small sample effects):
SE AE APE RE
2.73 1.29 0.51 0.56
2.31 1.23 0.39 0.68
2.70 1.37 0.36 0.86
Surprisingly, the identity of the best performing estimator (i.e., optimist, mean, or pessimist) depends on the scoring function used. What is going on?
The analysis of scoring functions is very new. A 2010 paper by Gneiting showed that it does not make sense to select the scoring function after the estimates have been made (he uses the term forecasts). The scoring function needs to be known in advance, to allow an estimator to tune their responses to minimise the value that will be calculated to evaluate performance.
The mathematics involves Bregman functions (new to me), which provide a measure of distance between two points, where the points are interpreted as probability distributions.
Which, if any, of these scoring functions should be used to evaluate the accuracy of software estimates?
In software estimation, perhaps the two most commonly used scoring functions are APE and RE. If management selects one or the other as the scoring function to rate developer estimation performance, what estimation technique should employees use to deliver the best performance?
Assuming that information is available on the actual time taken to implement previous project tasks, then we can work out the distribution of actual times. Assuming this distribution does not change, we can calculate APE and RE for various estimation techniques; picking the technique that produces the lowest score.
Let’s assume that the distribution of actual times is zero-truncated Negative binomial in one project and zero-truncated Weibull in another (purely for convenience of analysis, reality is likely to be more complicated). Management has chosen either APE or RE as the scoring function, and it is now up to team members to decide the estimation technique they are going to use, with the aim of optimising their estimation performance evaluation.
A developer seeking to minimise the effort invested in estimating could specify the same value for every estimate. Knowing the scoring function (top row) and the distribution of actual implementation times (first column), the minimum effort developer would always give the estimate that is a multiple of the known mean actual times using the multiplier value listed:
APE RE
Negative binomial 1.4 0.5
Weibull 1.2 0.6
For instance, management specifies APE, and previous task/actuals has a Weibull distribution, then always estimate the value  .
.
What mean multiplier should Esta Pert, an expert estimator aim for? Esta’s estimates can be modelled by the equation ") , i.e., the actual implementation time multiplied by a random value uniformly distributed between 0.5 and 2.0, i.e., Esta is an unbiased estimator. Esta’s table of multipliers is:
, i.e., the actual implementation time multiplied by a random value uniformly distributed between 0.5 and 2.0, i.e., Esta is an unbiased estimator. Esta’s table of multipliers is:
APE RE
Negative binomial 1.0 0.7
Weibull 1.0 0.7
A company wanting to win contracts by underbidding the competition could evaluate Esta’s performance using the RE scoring function (to motivate her to estimate low), or they could use APE and multiply her answers by some fraction.
In many cases, developers are biased estimators, i.e., individuals consistently either under or over estimate. How does an implicit bias (i.e., something a person does unconsciously) change the multiplier they should consciously aim for (having analysed their own performance to learn their personal percentage bias)?
The following table shows the impact of particular under and over estimate factors on multipliers:
0.8 underestimate bias 1.2 overestimate bias
Score function APE RE APE RE
Negative binomial 1.3 0.9 0.8 0.6
Weibull 1.3 0.9 0.8 0.6
Let’s say that one-third of those on a team underestimate, one-third overestimate, and the rest show no bias. What scoring function should a company use to motivate the best overall team performance?
The following table shows that neither of the scoring functions motivate team members to aim for the actual value when the distribution is Negative binomial:
APE RE
Negative binomial 1.1 0.7
Weibull 1.0 0.7
One solution is to create a bespoke scoring function for this case. Both APE and RE are special cases of a more general scoring function (see top). Setting  in this general form creates a scoring function that produces a multiplication factor of 1 for the Negative binomial case.
in this general form creates a scoring function that produces a multiplication factor of 1 for the Negative binomial case.
Twitter and evidence-based software engineering
This year’s quest for software engineering data has led me to sign up to Twitter (all the software people I know, or know-of, have been contacted, and discovery through articles found on the Internet is a very slow process).
@evidenceSE is my Twitter handle. If you get into a discussion and want some evidence-based input, feel free to get me involved. Be warned that the most likely response, to many kinds of questions, is that there is no data.
My main reason for joining is to try and obtain software engineering data. Other reasons include trying to introduce an evidence-based approach to software engineering discussions and finding new (to me) problems that people want answers to (that are capable of being answered by analysing data).
The approach I’m taking is to find software engineering tweets discussing a topic for which some data is available, and to jump in with a response relating to this data. Appropriate tweets are found using the search pattern: (agile OR software OR "story points" OR "story point" OR "function points") (estimate OR estimates OR estimating OR estimation OR estimated OR #noestimates OR "evidence based" OR empirical OR evolution OR ecosystems OR cognitive). Suggestions for other keywords or patterns welcome.
My experience is that the only effective way to interact with developers is via meaningful discussion, i.e., cold-calling with a tweet is likely to be unproductive. Also, people with data often don’t think that anybody else would be interested in it, they have to convinced that it can provide valuable insight.
You never know who has data to share. At a minimum, I aim to have a brief tweet discussion with everybody on Twitter involved in software engineering. At a minute per tweet (when I get a lot more proficient than I am now, and have workable templates in place), I could spend two hours per day to reach 100 people, which is 35,000 per year; say 20K by the end of this year. Over the last three days I have managed around 10 per day, and obviously need to improve a lot.
How many developers are on Twitter? Waving arms wildly, say 50 million developers and 1 in 1,000 have a Twitter account, giving 50K developers (of which an unknown percentage are active). A lower bound estimate is the number of followers of popular software related Twitter accounts: CompSciFact has 238K, Unix tool tips has 87K; perhaps 1 in 200 developers have a Twitter account, or some developers have multiple accounts, or there are lots of bots out there.
I need some tools to improve the search process and help track progress and responses. Twitter has an API and a developer program. No need to worry about them blocking me or taking over my business; my usage is small fry and I’ not building a business to take over. I was at Twitter’s London developer meetup in the week (the first in-person event since Covid) and the youngsters present looked a lot younger than usual. I suspect this is because the slightly older youngsters remember how Twitter cut developers off at the knee a few years ago by shutting down some useful API services.
The Twitter version-2 API looks interesting, and the Twitter developer evangelists are keen to attract developers (having ‘wiped out’ many existing API users), and I’m happy to jump in. A Twitter API sandbox for trying things out, and there are lots of example projects on Github. Pointers to interesting tools welcome.
Evidence-based Software Engineering: now in paperback form
I made my Evidence-based Software Engineering book available as a pdf file. While making a printed version available looked possible, I was uncertain that the result would be of acceptable quality; the extensive use of color and an A4 page size restricted the number of available printers who could handle it. Email exchanges with several publishers suggested that the number of likely print edition copies sold would be small (based on experience with other books, under 100). The pdf was made available under a creative commons license.
Around half-million copies of the pdf have been downloaded (some partially).
A few weeks ago, I spotted a print version of this book on Amazon (USA). I have no idea who made this available. Is the quality any good? I was told that it was, so I bought a copy.
The printed version looks great, with vibrant colors, and is reasonably priced. It sits well in the hand, while reading. The links obviously don’t work for the paper version, but I’m well practised at using multiple fingers to record different book locations.
I have one report that the Kindle version doesn’t load on a Kindle or the web app.
If you love printed books, I heartily recommend the paperback version of Evidence-based Software Engineering; it even has a 5-star review on Amazon 😉
Programming language similarity based on their traits
A programming language is sometimes described as being similar to another, more wide known, language.
How might language similarity be measured?
Biologists ask a very similar question, and research goes back several hundred years; phenetics (also known as taximetrics) attempts to classify organisms based on overall similarity of observable traits.
One answer to this question is based on distance matrices.
The process starts by flagging the presence/absence of each observed trait. Taking language keywords (or reserved words) as an example, we have (for a subset of C, Fortran, and OCaml):
if then function for do dimension object C 1 1 0 1 1 0 0 Fortran 1 0 1 0 1 1 0 OCaml 1 1 1 1 1 0 1 |
The distance between these languages is calculated by treating this keyword presence/absence information as an n-dimensional space, with each language occupying a point in this space. The following shows the Euclidean distance between pairs of languages (using the full dataset; code+data):
C Fortran OCaml C 0 7.615773 8.717798 Fortran 7.615773 0 8.831761 OCaml 8.717798 8.831761 0 |
Algorithms are available to map these distance pairs into tree form; for biological organisms this is known as a phylogenetic tree. The plot below shows such a tree derived from the keywords supported by 21 languages (numbers explained below, code+data):
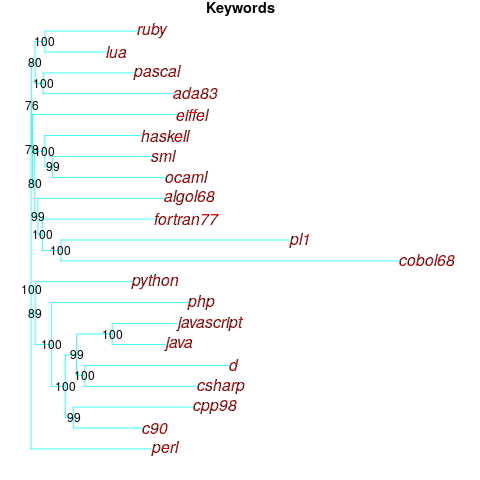
How confident should we be that this distance-based technique produced a robust result? For instance, would a small change to the set of keywords used by a particular language cause it to appear in a different branch of the tree?
The impact of small changes on the generated tree can be estimated using a bootstrap technique. The particular small-change algorithm used to estimate confidence levels for phylogenetic trees is not applicable for language keywords; genetic sequences contain multiple instances of four DNA bases, and can be sampled with replacement, while language keywords are a set of distinct items (i.e., cannot be sampled with replacement).
The bootstrap technique I used was: for each of the 21 languages in the data, was: add keywords to one language (the number added was 5% of the number of its existing keywords, randomly chosen from the set of all language keywords), calculate the distance matrix and build the corresponding tree, repeat 100 times. The 2,100 generated trees were then compared against the original tree, counting how many times each branch remained the same.
The numbers in the above plot show the percentage of generated trees where the same branching decision was made using the perturbed keyword data. The branching decisions all look very solid.
Can this keyword approach to language comparison be applied to all languages?
I think that most languages have some form of keywords. A few languages don’t use keywords (or reserved words), and there are some edge cases. Lisp doesn’t have any reserved words (they are functions), nor technically does Pl/1 in that the names of ‘word tokens’ can be defined as variables, and CHILL implementors have to choose between using Cobol or PL/1 syntax (giving CHILL two possible distinct sets of keywords).
To what extent are a language’s keywords representative of the language, compared to other languages?
One way to try and answer this question is to apply the distance/tree approach using other language traits; do the resulting trees have the same form as the keyword tree? The plot below shows the tree derived from the characters used to represent binary operators (code+data):

A few of the branching decisions look as-if they are likely to change, if there are changes to the keywords used by some languages, e.g., OCaml and Haskell.
Binary operators don’t just have a character representation, they can also have a precedence and associativity (neither are needed in languages whose expressions are written using prefix or postfix notation).
The plot below shows the tree derived from combining binary operator and the corresponding precedence information (the distance pairs for the two characteristics, for each language, were added together, with precedence given a weight of 20%; see code for details).

No bootstrap percentages appear because I could not come up with a simple technique for handling a combination of traits.
Are binary operators more representative of a language than its keywords? Would a combined keyword/binary operator tree would be more representative, or would more traits need to be included?
Does reducing language comparison to a single number produce something useful?
Languages contain a complex collection of interrelated components, and it might be more useful to compare their similarity by discrete components, e.g., expressions, literals, types (and implicit conversions).
What is the purpose of comparing languages?
If it is for promotional purposes, then a measurement based approach is probably out of place.
If the comparison has a source code orientation, weighting items by source code occurrence might produce a more applicable tree.
Sometimes one language is used as a reference, against which others are compared, e.g., C-like. How ‘C-like’ are other languages? Taking keywords as our reference-point, comparing languages based on just the keywords they have in common with C, the plot below is the resulting tree:

I had expected less branching, i.e., more languages having the same distance from C.
New languages can be supported by adding a language file containing the appropriate trait information. There is a Github repo, prog-lang-traits, send me a pull request to add your language file.
It’s also possible to add support for more language traits.
Ecology as a model for the software world
Changing two words in the Wikipedia description of Ecology gives “… the study of the relationships between software systems, including humans, and their physical environment”; where physical environment might be taken to include the hardware on which software runs and the hardware whose behavior it controls.
What do ecologists study? Wikipedia lists the following main areas; everything after the first sentence, in each bullet point, is my wording:
- Life processes, antifragility, interactions, and adaptations.
Software system life processes include its initial creation, devops, end-user training, and the sales and marketing process.
While antifragility is much talked about, it is something of a niche research topic. Those involved in the implementations of safety-critical systems seem to be the only people willing to invest the money needed to attempt to build antifragile software. Is N-version programming the poster child for antifragile system software?
Interaction with a widely used software system will have an influence on the path taken by cultures within associated microdomains. Users adapt their behavior to the affordance offered by a software system.
A successful software system (and even unsuccessful ones) will exist in multiple forms, i.e., there will be a product line. Software variability and product lines is an active research area.
- The movement of materials and energy through living communities.
Is money the primary unit of energy in software ecosystems? Developer time is needed to create software, which may be paid for or donated for free. Supporting a software system, or rather supporting the needs of the users of the software is often motivated by a salary, although a few do provide limited free support.
What is the energy that users of software provide? Money sits at the root; user attention sells product.
- The successional development of ecosystems (“… succession is the process of change in the species structure of an ecological community over time.”)
Before the Internet, monthly computing magazines used to run features on the changing landscape of the computer world. These days, we have blogs/podcasts telling us about the latest product release/update. The Ecosystems chapter of my software engineering book has sections on evolution and lifespan, but the material is sparse.
Over the longer term, this issue is the subject studied by historians of computing.
Moore’s law is probably the most famous computing example of succession.
- Cooperation, competition, and predation within and between species.
These issues are primarily discussed by those interested in the business side of software. Developers like to brag about how their language/editor/operating system/etc is better than the rest, but there is no substance to the discussion.
Governments have an interest in encouraging effective competition, and have enacted various antitrust laws.
- The abundance, biomass, and distribution of organisms in the context of the environment.
These are the issues where marketing departments invest in trying to shift the distribution in their company’s favour, and venture capitalists spend their time trying to spot an opportunity (and there is the clickbait of language popularity articles).
The abundance of tools/products, in an ecosystem, does not appear to deter people creating new variants (suggesting that perhaps ambition or dreams are the unit of energy for software ecosystems).
- Patterns of biodiversity and its effect on ecosystem processes.
Various kinds of diversity are important for biological systems, e.g., the mutual dependencies between different species in a food chain, and genetic diversity as a resource that provides a mechanism for species to adapt to changes in their environment.
It’s currently fashionable to be in favour of diversity. Diversity is so popular in ecology that a 2003 review listed 24 metrics for calculating it. I’m sure there are more now.
Diversity is not necessarily desired in software systems, e.g., the runtime behavior of source code should not depend on the compiler used (there are invariably edge cases where it does), and users want different editor command to be consistently similar.
Open source has helped to reduce diversity for some applications (by reducing the sales volume of a myriad of commercial offerings). However, the availability of source code significantly reduces the cost/time needed to create close variants. The 5,000+ different cryptocurrencies suggest that the associated software is diverse, but the rapid evolution of this ecosystem has driven developers to base their code on the source used to implement earlier currencies.
Governments encourage competitive commercial ecosystems because competition discourages companies charging high prices for their products, just because they can. Being competitive requires having products that differ from other vendors in a desirable way, which generates diversity.
NoEstimates panders to mismanagement and developer insecurity
Why do so few software development teams regularly attempt to estimate the duration of the feature/task/functionality they are going to implement?
Developers hate giving estimates; estimating is very hard and estimates are often inaccurate (at a minimum making the estimator feel uncomfortable and worse when management treats an estimate as a quotation). The future is uncertain and estimating provides guidance.
Managers tell me that the fear of losing good developers dissuades them from requiring teams to make estimates. Developers have told them that they would leave a company that required them to regularly make estimates.
For most of the last 70 years, demand for software developers has outstripped supply. Consequently, management has to pay a lot more attention to the views of software developers than the views of those employed in most other roles (at least if they want to keep the good developers, i.e., those who will have no problem finding another job).
It is not difficult for developers to get a general idea of how their salary, working conditions and practices compares with other developers in their field/geographic region. They know that estimating is not a common practice, and unless the economy is in recession, finding a new job that does not require estimation could be straight forward.
Management’s demands for estimates has led to the creation of various methods for calculating proxy estimate values, none of which using time as the unit of measure, e.g., Function points and Story points. These methods break the requirements down into smaller units, and subcomponents from these units are used to calculate a value, e.g., the Function point calculation includes items such as number of user inputs and outputs, and number of files.
How accurate are these proxy values, compared to time estimates?
As always, software engineering data is sparse. One analysis of 149 projects found that  , with the variance being similar to that found when time was estimated. An analysis of Function point calculation data found a high degree of consistency in the calculations made by different people (various Function point organizations have certification schemes that require some degree of proficiency to pass).
, with the variance being similar to that found when time was estimated. An analysis of Function point calculation data found a high degree of consistency in the calculations made by different people (various Function point organizations have certification schemes that require some degree of proficiency to pass).
Managers don’t seem to be interested in comparing estimated Story points against estimated time, preferring instead to track the rate at which Story points are implemented, e.g., velocity, or burndown. There are tiny amounts of data comparing Story points with time and Function points.
The available evidence suggests a relationship connecting Function points to actual time, and that Function points have similar error bounds to time estimates; the lack of data means that Story points are currently just a source of technobabble and number porn for management power-points (send me Story point data to help change this situation).
4,000 vs 400 vs 40 hours of software development practice
What is the skill difference between professional developers and newly minted computer science graduates?
Practice, e.g., 4,000 vs. 400 hours
People get better with practice, and after two years (around 4,000 hours) a professional developer will have had at least an order of magnitude more practice than most students; not just more practice, but advice and feedback from experienced developers. Most of these 4,000 hours are probably not the deliberate practice of 10,000 hours fame.
It’s understandable that graduates with a computing degree consider themselves to be proficient software developers; this opinion is based on personal experience (i.e., working with other students like themselves), and not having spent time working with professional developers. It’s not a joke that a surprising number of academics don’t appreciate the student/professional difference, the problem is that some academics only ever get to see a limit range of software development expertise (it’s a question of incentives).
Surveys of student study time have found that for Computer science, around 50% of students spend 11 hours or more, per week, in taught study and another 11 hours or more doing independent learning; let’s take 11 hours per week as the mean, and 30 academic weeks in a year. How much of the 330 hours per year of independent learning time is spent creating software (that’s 1,000 hours over a three-year degree, assuming that any programming is required)? I have no idea, and picked 40% because it matched up with 4,000.
Based on my experience with recent graduates, 400 hours sounds high (I have no idea whether an average student spends 4-hours per week doing programming assignments). While a rare few are excellent, most are hopeless. Perhaps the few hours per week nature of their coding means that they are constantly relearning, or perhaps they are just cutting and pasting code from the Internet.
Most graduates start their careers working in industry (around 50% of comp sci/maths graduates work in an ICT profession; UK higher-education data), which means that those working in industry are ideally placed to compare the skills of recent graduates and professional developers. Professional developers have first-hand experience of their novice-level ability. This is not a criticism of computing degrees; there are only so many hours in a day and lots of non-programming material to teach.
Many software developers working in industry don’t have a computing related degree (I don’t). Lots of non-computing STEM degrees give students the option of learning to program (I had to learn FORTRAN, no option). I don’t have any data on the percentage of software developers with a computing related degree, and neither do I have any data on the average number of hours non-computing STEM students spend on programming; I’ve cosen 40 hours to flow with the sequence of 4’s (some non-computing STEM students spend a lot more than 400 hours programming; I certainly did). The fact that industry hires a non-trivial number of non-computing STEM graduates as software developers suggests that, for practical purposes, there is not a lot of difference between 400 and 40 hours of practice; some companies will take somebody who shows potential, but no existing coding knowledge, and teach them to program.
Many of those who apply for a job that involves software development never get past the initial screening; something like 80% of people applying for a job that specifies the ability to code, cannot code. This figure is based on various conversations I have had with people about their company’s developer recruitment experiences; it is not backed up with recorded data.
Some of the factors leading to this surprisingly high value include: people attracted by the salary deciding to apply regardless, graduates with a computing degree that did not require any programming (there is customer demand for computing degrees, and many people find programming is just too hard for them to handle, so universities offer computing degrees where programming is optional), concentration of the pool of applicants, because those that can code exit the applicant pool, leaving behind those that cannot program (who keep on applying).
Apologies to regular readers for yet another post on professional developers vs. students, but I keep getting asked about this issue.
Anthropological studies of software engineering
Anthropology is the study of humans, and as such it is the top level research domain for many of the human activities involved in software engineering. What has been discovered by the handful of anthropologists who have spent time researching the tiny percentage of humans involved in writing software?
A common ‘discovery’ is that developers don’t appear to be doing what academics in computing departments claim they do; hardly news to those working in industry.
The main subfields relevant to software are probably: cultural anthropology and social anthropology (in the US these are combined under the name sociocultural anthropology), plus linguistic anthropology (how language influences social life and shapes communication). There is also historical anthropology, which is technically what historians of computing do.
For convenience, I’m labelling anybody working in an area covered by anthropology as an anthropologist.
I don’t recommend reading any anthropology papers unless you plan to invest a lot of time in some subfield. While I have read lots of software engineering papers, anthropologist’s papers on this topic are often incomprehensible to me. These papers might best be described as anthropology speak interspersed with software related terms.
Anthropologists write books, and some of them are very readable to a more general audience.
The Art of Being Human: A Textbook for Cultural Anthropology by Wesch is a beginner’s introduction to its subject.
Ethnography, which explores cultural phenomena from the point of view of the subject of the study, is probably the most approachable anthropological research. Ethnographers spend many months living with a remote tribe, community, or nowadays a software development company, and then write-up their findings in a thesis/report/book. Examples of approachable books include: “Engineering Culture: Control and Commitment in a High-Tech Corporation” by Kunda, who studied a large high-tech company in the mid-1980s; “No-Collar: The Humane Workplace and its Hidden Costs” by Ross, who studied an internet startup that had just IPO’ed, and “Coding Freedom: The Ethics and Aesthetics of Hacking” by Coleman, who studied hacker culture.
Linguistic anthropology is the field whose researchers are mostly likely to match developers’ preconceived ideas about what humanities academics talk about. If I had been educated in an environment where Greek and nineteenth century philosophers were the reference points for any discussion, then I too would use this existing skill set in my discussions of source code (philosophers of source code did not appear until the twentieth century). Who wouldn’t want to apply hermeneutics to the interpretation of source code (the field is known as Critical code studies)?
It does not help that the software knowledge of many of the academics appears to have been acquired by reading computer books from the 1940s and 1950s.
The most approachable linguistic anthropology book I have found, for developers, is: The Philosophy of Software Code and Mediation in the Digital Age by Berry (not that I have skimmed many).
Study of developers for the cost of a phase I clinical drug trial
For many years now, I have been telling people that software researchers need to be more ambitious and apply for multi-million pound/dollar grants to run experiments in software engineering. After all, NASA spends a billion or so sending a probe to take some snaps of a planet and astronomers lobby for $100million funding for a new telescope.
What kind of experimental study might be run for a few million pounds (e.g., the cost of a Phase I clinical drug trial)?
Let’s say that each experiment involves a team of professional developers implementing a software system; call this a Project. We want the Project to be long enough to be realistic, say a week.
Different people exhibit different performance characteristics, and the experimental technique used to handle this is to have multiple teams independently implement the same software system. How many teams are needed? Fifteen ought to be enough, but more is better.
Different software systems contain different components that make implementation easier/harder for those involved. To remove single system bias, a variety of software systems need to be used as Projects. Fifteen distinct Projects would be great, but perhaps we can get away with five.
How many developers are on a team? Agile task estimation data shows that most teams are small, i.e., mostly single person, with two and three people teams making up almost all the rest.
If we have five teams of one person, five of two people, and five of three people, then there are 15 teams and 30 people.
How many people will be needed over all Projects?
15 teams (30 people) each implementing one Project 5 Projects, which will require 5*30=150 people (5*15=75 teams) |
How many person days are likely to be needed?
If a 3-person team takes a week (5 days), a 2-person team will take perhaps 7-8 days. A 1-person team might take 9-10 days.
The 15 teams will consume 5*3*5+5*2*7+5*1*9=190 person days The 5 Projects will consume 5*190=950 person days |
How much is this likely to cost?
The current average daily rate for a contractor in the UK is around £500, giving an expected cost of 190*500=£475,000 to hire the experimental subjects. Venue hire is around £40K (we want members of each team to be co-located).
The above analysis involves subjects implementing one Project. If, say, each subject implements two, three or four Projects, one after the other, the cost is around £2million, i.e., the cost of a Phase I clinical drug trial.
What might we learn from having subjects implement multiple Projects?
Team performance depends on the knowledge and skill of its members, and their ability to work together. Data from these experiments would be the first of their kind, and would provide realistic guidance on performance factors such as: impact of team size; impact of practice; impact of prior experience working together; impact of existing Project experience. The multiple implementations of the same Project created provide a foundation for measuring expected reliability and theories of N-version programming.
A team of 1 developer will take longer to implement a Project than a team of 2, who will take longer than a team of 3.
If 20 working days is taken as the ballpark period over which a group of subjects are hired (i.e., a month), there are six team size sequences that one subject could work (A to F below); where individual elapsed time is close to 20 days (team size 1 is 10 days elapsed, team size 2 is 7.5 days, team size 3 is 5 days).
Team size A B C D E F
1 twice once once
2 once thrice once
3 twice twice four |
The cost of hiring subjects+venue+equipment+support for such a study is likely to be at least £1,900,000.
If the cost of beta testing, venue hire and research assistants (needed during experimental runs) is included, the cost is close to £2.75 million.
Might it be cheaper and simpler to hire, say, 20-30 staff from a medium size development company? I chose a medium-sized company because we would be able to exert some influence over developer selection and keeping the same developers involved. The profit from 20-30 people for a month is not enough to create much influence within a large company, and a small company would not want to dedicate a large percentage of its staff for a solid month.
Beta testing is needed to validate both the specifications for each Project and that it is possible to schedule individuals to work in a sequence of teams over a month (individual variations in performance create a scheduling nightmare).
Recent Comments