Apollo guidance computer software development process
MIT’s Draper Lab implemented the primary Guidance, Navigation and Control System (GNCS) for the Apollo spacecraft, i.e., the hardware+software (the source code is now available on GitHub). Project Apollo ran from 1961 to 1972, and many MIT project reports are available (the five volume set: “MIT’s Role in Project Apollo” probably contains more than you want to know).
What development processes were used to implement the Apollo GNCS software?
For decades, I was told that large organizations, such as NASA, used the Waterfall method to develop software. Did the implementation of the Apollo GNCS software use a Waterfall process?
Readers will be familiar with the wide gulf that can exist between documented management plans and what developers actually did (which is rarely documented). One technique for gaining insight into development practices is to follow the money. Implementation work is a cost, and a detailed cost breakdown timeline of the various development activities provides some insight into the work flow. Gold dust: Daniel Rankin’s 1972 Master’s thesis lists the Apollo project software development costs for each 6-month period from the start of 1962 until the end of 1970; it also gives the number of 16-bit words (the size of an instruction) contained in each binary release, along with the number of new instructions.
The GNCS computer contained 36,864 16-bit words of read-only memory and 2,048 words of read/write memory. The Apollo spacecraft contained two GNCS computers. The plot below shows the cumulative number of new code (in words) contained in all binary releases and the instructions contained in each binary release, with Apollo numbers at the release date of the code for that mission; grey lines show read only word limit and read-only plus twice read/write word limit (code+data):
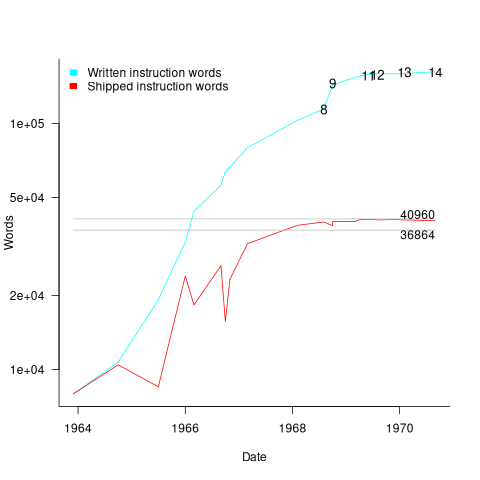
Four times as many instructions appeared over all releases, than made it into the final release. The continual turn-over of code in each release implies an iterative development process prior to the first manned launch, Apollo 8 (possibly an iterative waterfall process). After the first moon landing, Apollo 11, there were very few code changes for Apollo 12/13/14 (no data is available for the Apollo 15/16/17 missions).
The plot below shows thousands of dollars spent on the various software development activities within each 6-month period; the computing items are the cost of computer usage (code+data):
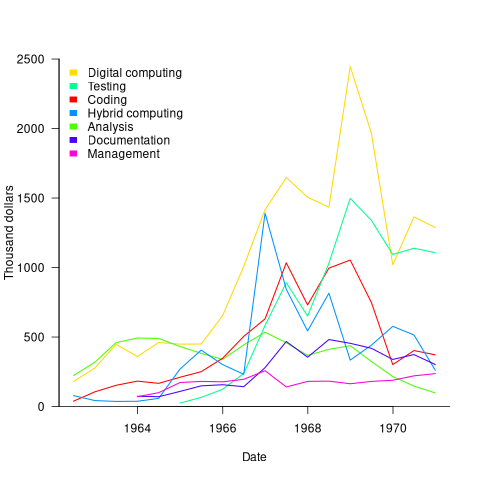
The plot suggests that most activities are ongoing over most of the decade. As expected, Coding costs significantly decrease before the release used during the first Moon landing, and testing costs continue at a high rate across the Apollo 11/12/13/14 missions. Why didn’t the Documentation costs go down when the Coding costs went down? Perhaps this was for some upcoming changes (not the Lunar rover which was built by Boeing). Activities in the legend are ordered by total amount spent; totals below:
Digital_Computer $18,373,000 Testing $ 9,786,000 Coding $ 8,233,000 Hybrid_Computer $ 7,190,000 Analysis $ 6,580,000 Documentation $ 4,177,000 Management $ 2,654,000 |
I think this data clearly shows that the Apollo GNCS software was developed using an iterative approach, and given that the cost of Coding was only twice as much as Documentation, within these iterations some form of Waterfall process was probably used.
Very interesting conclusion. I looked at Margaret Hamilton’s oral history at the CHM and was surprised not to find much on her development process.
@Nemo
Software development processes in the 1960s appear to have mirrored hardware development practices. Software specific processes grew out of experiences of projects like Apollo. This was all seat of the pants stuff.
Hamilton does mention things like matrix management, how updates were fed into the source tree (she does not use that term), and testing.
There is a lot of useful background in Don Eyles’ memoir “Sunburst and Luminary”: he was the programmer with primary responsibility for descent guidance on the Lunar Module. It’s a very interesting read; no data, but a lot of qualitative background on the development effort (as well as the escapades of a twenty-something in the ’60s…)
It has been a few years since I read it, but as I recall the Command Module people (who were most directly under Margaret Hamilton) and the Lunar Module people seem to have had a fair amount of separation as far as culture went, with the LEM folk being in general a bit looser and lighter on internal process (obviously, the whole effort was wrapped in mountains of general Apollo process). As told, of course, by one of the LEM folk, so caveats abound.
Certainly for a large fraction of the development it appears to have been iterative at a macro scale, because the whole *program* was iterative at a macro scale, with each flight proving out some milestone like “lunar orbit” or “independent LEM flight”.
There also seems to have been a fair amount of bottom-up, non-waterfall activity. I pulled out my copy and found this passage, relating to some semi-“unapproved” improvements to updates to velocity indicators:
> One advantage of developing something first in an offline version was that you could make your decisions without interference and when the time came to seek approval, your decisions, especially if they involved additional capability, would probably be accepted into the package. (And if you were also sending the offline programs to the simulators, there was the possibility of building up a constituency) … I wrote a Program Change Request to put the new code in LUMINARY for the Apollo 15 mission, and followed up with a memo … Meanwhile Tom Price called Russ Larson from Housten to say, “Crew won’t accept anything but zero error.” They had probably gotten wind that a new version was in the works.
In other words, Eyles made a change on his own initiative, sent a pre-released version to the simulators, and got “customer buy-in” *before* discussing the change with management.
There are also examples of programmers actively discussing UI and feature improvements directly with astronauts: they seem to have had good access to their “customers” in a way that modern Agile would approve of. For example, there is a passage with Eyles and John Young (Apollo 16 commander) sitting in a Lunar Module simulator, flying a “landing” while discussing a possible new feature to improve landing site accuracy.
My overall impression is that that the high-level process (e.g. coordination with the government) was very process-heavy, but the day-to-day work was very process-light — very chaotic, seat-of-the-pants stuff. Roughly equivalent to, in a modern day analogy, raising Jira tickets *after* doing the work (and calling the ticket “All of Don’s recent improvements”. That process contrast matches a lot of what I have heard about other elements of Apollo in general.
One thing I would suggest for your first graph is that the lines shouldn’t really join up like that, because you are actually sort-of plotting two distinct series. While the Command and Lunar module AGCs did share low-level code, the “application” software seems to have more different than it was similar. Basically, the LEM codebase was a fork of the CSM codebase, with (as I understand it) occasional copying back-and-forth to keep the common elements in sync.
So I think that what you really want to do for your graph is to use the chart earlier in Rankin’s paper that shows the “family tree” of software releases. Basically, I think you want a time-series for “the final COLOSSUS release (COLOSSUS 2E), and all its parents” and another for “the final LUMINARY release (LUMINARY 1D)”. They have a common ancestor at RETREAD, but I think the “glitches” in your graph come from swapping back and forth between COLOSSUS and LUMINARY as part of the same time series.
@David Morris
Thanks for such a thoughtful comment. Eyles’ memoir “Sunburst and Luminary” has been sitting in my Amazon basket some years now. I read “How Apollo Flew to the Moon” by W. David Woods, and that satiated my desire to read any more books on Apollo (when I was younger I read a lot of them). In her oral history, Margaret Hamilton also talks about how they sometimes worked around the bureaucracy.
I wondered about how much code was shared between the two computers. The basic maths and navigation code would be the same. Sorting through the code history/versions is probably a PhD thesis in waiting.
Are the glitches the result of records being out of sync with changes, paperwork going astray, or me merging treating two time series as one? I have added this to my list of pending questions, as well as moving Eyles’ book up my to-buy list.
Reading between the lines I think a lot of the software for early planetary probes was each effectively maintained during missions by a small group working by the seat of their pants.
I was curious, so I tried roughly splitting the time series out based on the lineage of releases. It’s hard to be exact, because of the octopus merge at SUNDISK, but it’s clear that RETREAD was a substantial refactoring, and that the divergence between the RETREAD and CORONA paths was pretty large. However, I think the data does at least *look* much nicer if you separate out the time series. In particular, if you assume that SUNDISK was mostly based on SUNSPOT and ignore its lineage through SUNDIAL, the size of each program grows in a way that feels very easy to wrap a plausible story around. (Of course, I have no substance to back up that plausibility).
At this point I think I am mere millimetres away from nerd-sniping myself into analysing the actual source dumps, so I will stop before the next several weeks disappear…
@David Morris
Margaret Hamilton is still with us, and she strikes me as the kind of person who after all these years would still know the answers to these kinds of question.
I got to skim around 50 random pages of Eyles’ memoir. His primary focus is on the application domain (to be expected in a book targeted at a more general audience), and programming discussion was all about low level coding issues.