Archive
Deep dive looking for good enough reliability models
A previous post summarised the main highlights of my trawl through the software reliability research papers/reports/data, which failed to find any good enough models for estimating the reliability of a software system. This post summarises a deep dive into the technical aspects of the research papers.
I am now a lot more confident that better than worst case models for calculating software reliability don’t yet exist (perhaps the problem does not have a solution). By reliability, I mean the likelihood that a fault will be experienced during 1-hour of operation (1-hour is the time interval often used in safety critical standards).
All the papers assume that time to next new fault experience can be effectively modelled using timing information on the previously discovered distinct faults. Timing information might be cpu time, or elapsed time during testing or customer use, or even number of tests. Issues of code coverage and the correspondence between tests and customer usage are rarely mentioned.
Building a model requires making assumptions about the world. Given the data used, all the models assume that there is a relationship connecting the time between successive distinct faults, e,g, the Jelinski-Moranda model assumes that the time between fault experiences has an exponential distribution and that the exponent is the same for all faults. While the Jelinski-Moranda model does not match the behavior seen in the available datasets, it is widely discussed (its simplicity makes it a great example, with the analysis being straightforward and the result easy to explain).
Much of the fault timing data comes from the test process, with the rest coming from customer usage (either cpu or elapsed; like today’s cloud usage, mainframe time usage was often charged). What connection does a model fitted to data on the faults discovered during testing have with faults experienced by customers using the software? Managers want to minimise the cost of testing (one claimed use case for these models is estimating the likelihood of discovering a new fault during testing), and maximising the number of faults found probably has a higher priority than mimicking customer usage.
The early software reliability papers (i.e., the 1970s) invariably proposed a new model and then checked how well it fitted a small dataset.
While the top, must-read paper on software fault analysis was published in 1982, it has mostly remained unknown/ignored (it appeared as a NASA report written by non-academics who did not then promote their work). Perhaps if Nagel and Skrivan’s work had become widely known, today we might have a practical software reliability model.
Reliability research in the 1980s was dominated by theoretical analysis of the previously proposed models and their variants, finding connections between them and building more general models. Ramos’s 2009 PhD thesis contains a great overview of popular (academic) reliability models, their interconnections, and using them to calculate a number.
I did discover some good news. Researchers outside of software engineering have been studying a non-software problem whose characteristics have a direct mapping to software reliability. This non-software problem involves sampling from a population containing subpopulations of varying sizes (warning: heavy-duty maths), e.g., oil companies searching for new oil fields of unknown sizes. It looks, perhaps (the maths is very hard going), as-if the statisticians studying this problem have found some viable solutions. If I’m lucky, I will find a package implementing the technical details, or find a gentle introduction. Perhaps this thread will have a happy ending…
An aside: When quickly deciding whether a research paper is worth reading, if the title or abstract contains a word on my ignore list, the paper is ignored. One consequence of this recent detailed analysis is that the term NHPP has been added to my ignore list for software reliability issues (it has applicability for hardware).
Zig is the next fashionable language
New programming languages are constantly being created, with most remaining unknown outside a small circle of friends. Every 5-10 years or so, a few of these languages break out to become fashionable to use. In the early 1980s, I was a fan of Pascal and had conversations with developers trying to figure out why they were fans of C. Yes, C was once the fashionable language to talk about. One of these languages went on to be used almost everywhere, while the other had the common fate of fading into obscurity.
Fashion serves a purpose. People, not just developers, enjoy experimenting, feel a need for self-expression, with a “fresh start” making them feel new and energized. Following fashion provides a means of fulfilling these desires. Developers who don’t need to earn a living using established languages are able to invest their time being part of the growing community of the current fashionable language.
Over the last 5-10 years Rust and Go were fashionable languages, with Julia being part of the trend vibe for a few years in the mid 2010s.
This last year, I have noticed a significant decline in articles extolling Go and meeting developers using it. In the last 6 months, I have seen a marked growth in criticism of Rust (very slow compilation speed in particular).
Fashion requires change and reinvention, because widespread use ruins its specialness. When Rust is no longer perceived to be fashionable (I think Go is already at this point), a new language will be ‘chosen’ to fill the void. Which languages are the likely candidates?
For some time, I have been telling people that my candidate language is Zig. My original whimsical reason was that very few programming languages have names starting with letters near the end of the alphabet (the preponderance of language names start with a letter near the beginning).
Experience has taught me that technical merits have little to do with language choice, clearly illustrated by the wide use of PHP and JavaScript.
A necessary condition for a language to become fashionable is that it be usable on the widely available software development platforms of the day (which is how PHP and JavaScript catapulted their user growth), another is that there be at least one core developer generally available to respond to user questions. The first condition provides something to use, and the second the basis for a welcoming community.
New languages are created on a regular basis by PhD students, but these implementations are a means to an end, i.e., publishing papers about some technique. There might be something to use, but rarely a welcoming community.
Andrew Kelley, the creator of Zig and president of the Zig foundation, quit his job in 2018 to work full-time on Zig. Andrew has put a lot of effort into building a community and raising funds to hire people.
Doing all the necessary things is not enough, there is luck and timing is important. The start date for Zig is four years after the start date for Rust. Not long enough for Rust to become unfashionable and need a replacement. However, seven years after leaving his job, Andrew is still working on Zig. Persistence is also an important success factor.
While I don’t actively follow Zig, I do visit sites where fringe languages are regularly discussed. Over the last six months, there has been a noticeable increase in Zig related discussions, and somebody has written a Zig book. Given that Zig related discussions are uncommon, this uptick may just be noise.
To me, Zig looks ready to go, and also has an appealing backstory (i.e., created by a lone developer working hard over many years) that contrasts with the Rust/Go perceived backstory (i.e., created in the bowls of an, not at the time, ‘evil’ corporation). I have not seen any other contenders for the next fashionable language.
Will LLMs cause fashionable languages to stop being a thing? Perhaps in the long term, or perhaps a new criterion for being fashionable will be not-known to LLMs. At the moment, developers are very aware of the failing of LLM code generation. In the short term, I think that fashionable languages will remain a thing.
Apollo guidance computer software development process
MIT’s Draper Lab implemented the primary Guidance, Navigation and Control System (GNCS) for the Apollo spacecraft, i.e., the hardware+software (the source code is now available on GitHub). Project Apollo ran from 1961 to 1972, and many MIT project reports are available (the five volume set: “MIT’s Role in Project Apollo” probably contains more than you want to know).
What development processes were used to implement the Apollo GNCS software?
For decades, I was told that large organizations, such as NASA, used the Waterfall method to develop software. Did the implementation of the Apollo GNCS software use a Waterfall process?
Readers will be familiar with the wide gulf that can exist between documented management plans and what developers actually did (which is rarely documented). One technique for gaining insight into development practices is to follow the money. Implementation work is a cost, and a detailed cost breakdown timeline of the various development activities provides some insight into the work flow. Gold dust: Daniel Rankin’s 1972 Master’s thesis lists the Apollo project software development costs for each 6-month period from the start of 1962 until the end of 1970; it also gives the number of 16-bit words (the size of an instruction) contained in each binary release, along with the number of new instructions.
The GNCS computer contained 36,864 16-bit words of read-only memory and 2,048 words of read/write memory. The Apollo spacecraft contained two GNCS computers. The plot below shows the cumulative number of new code (in words) contained in all binary releases and the instructions contained in each binary release, with Apollo numbers at the release date of the code for that mission; grey lines show read only word limit and read-only plus twice read/write word limit (code+data):
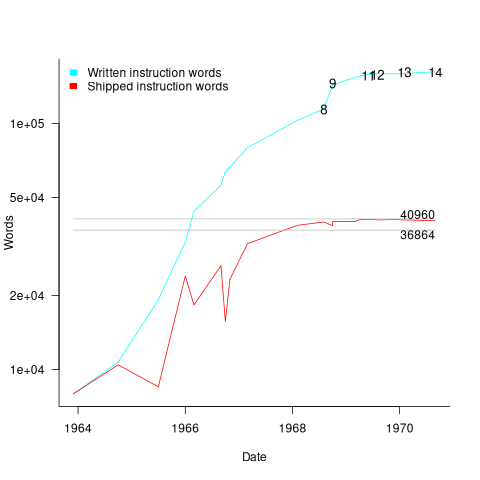
Four times as many instructions appeared over all releases, than made it into the final release. The continual turn-over of code in each release implies an iterative development process prior to the first manned launch, Apollo 8 (possibly an iterative waterfall process). After the first moon landing, Apollo 11, there were very few code changes for Apollo 12/13/14 (no data is available for the Apollo 15/16/17 missions).
The plot below shows thousands of dollars spent on the various software development activities within each 6-month period; the computing items are the cost of computer usage (code+data):
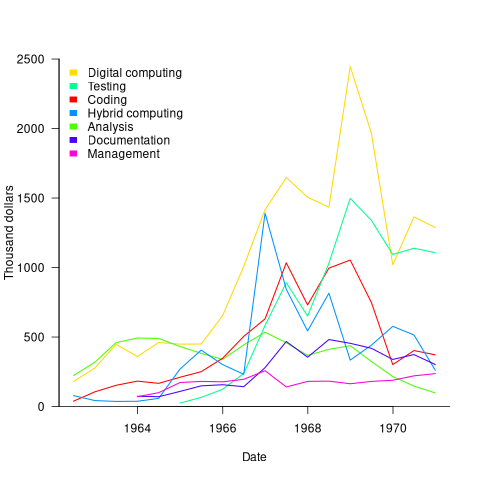
The plot suggests that most activities are ongoing over most of the decade. As expected, Coding costs significantly decrease before the release used during the first Moon landing, and testing costs continue at a high rate across the Apollo 11/12/13/14 missions. Why didn’t the Documentation costs go down when the Coding costs went down? Perhaps this was for some upcoming changes (not the Lunar rover which was built by Boeing). Activities in the legend are ordered by total amount spent; totals below:
Digital_Computer $18,373,000 Testing $ 9,786,000 Coding $ 8,233,000 Hybrid_Computer $ 7,190,000 Analysis $ 6,580,000 Documentation $ 4,177,000 Management $ 2,654,000 |
I think this data clearly shows that the Apollo GNCS software was developed using an iterative approach, and given that the cost of Coding was only twice as much as Documentation, within these iterations some form of Waterfall process was probably used.
Creating a global Standard requires being politically neutral
Governments actively promote Standards because following them saves their citizens time and money. The UK and US have contrasting rationales, with the UK focusing on savings achieved through repeated use of standardized items and the US focusing on the repeated use of skills people acquired through using a standardized item (i.e., reduced training costs).
Manufacturers wanting to export products want to be able to ship identical products all over the world, i.e., not have to make costly changes for different national markets. To be able to do this, they need the rest of the world to have a Standard way of doing things. The once dominant military and industrial status of Great Britain, and now the US, motivated them to create and encourage other countries to follow the Standards they created.
These days, most programming language Standards work is done by people employed by US companies attending an international committee, SC22, with (currently) 28 countries paying to be P (participating) members and 21 countries as O (observing) members (most countries don’t appear to have any active involvement in language standards). The reason for the dominance of US companies is that few non-US companies are willing to fund staff to do Standard’s work. For a few languages SC22 essentially rubber stamps documents produced elsewhere, e.g., most of the Cobol work used to be done by a US committee and ECMAScript (aka JavaScript) work is done in a European committee mostly attended by US companies.
Other countries sometimes get to dominate the creation of a language Standard, e.g., the UK led the Pascal Standard work. At the last SC22 meeting, a person from the US lamented that Europe was set to become the dominant driver of the Ada Standard. I resisted the urge to cheer: Make Europe Great Again.
Getting an international Standard adopted throughout the world requires that ISO be politically neutral and accept any sovereign country as a member (provided they pay the membership fees). For instance, North Korea is a member of ISO.
The only politics I have previously seen in programming language standard meetings has involved company rivalry, not geopolitical rivalry. A recent request for comment from SC2 (the ISO committee responsible for coded character sets; readers are more likely to be familiar with Unicode, essentially the same information published by a non-profit consortium based in California) looks like geopolitics, in the sense of geopolitical virtue signalling.
The document is: Request for SC2 member comments on proposal to encode “Ruble sign with double vertical stem”. What does the character “Ruble sign with double vertical stem” look like? To quote the document: “The proposed character is a text element that cannot be represented by any existing character or character sequence.” Readers will have to imagine Russia’s Ruble currency symbol, ₽, with two vertical stems (I assume these stems are short antennae like lines).
What is the geopolitical connection? Readers will be aware of Russia’s invasion of Ukraine, but may not be aware of Russia’s involvement in Transnistria (quoting Wikipedia, “… a landlocked breakaway state internationally recognized as part of Moldova.”). Since 1994, the proposed character has been used as the Transnistria currency symbol.
The request for comment includes a “Non-technical considerations” section summarises various controversy points, and finishes with: “We are not aware of any non-technical criteria having been used by SC2 or WG2 in the past that could be applied to disqualify this character. We are also concerned that adopting a criterion that allows for opposing a character because of association with politically or socially defined user communities could be problematic.”
The proposed character is not included in ISO 4217 (which defines numeric codes for the representation of currencies). However, SC22 does not require that a character used to represent a currency be included in ISO 4217. Previously, SC22 has accepted currency characters that are not in ISO 4217.
Is this a one-off objection, or does it mark the start of a stream of requests to remove one or more politically incorrect characters from ISO 10646/Unicode?
A lot of people put a lot of effort into creating a unified Standard for all the characters created by the World’s people. I hope the destructive nature of virtue signalling does not take hold in programming language Standard ecosystem.
Recent Comments