Example of an initial analysis of some new NASA data
For the last 20 years, the bug report databases of Open source projects have been almost the exclusive supplier of fault reports to the research community. Which, if any, of the research results are applicable to commercial projects (given the volunteer nature of most Open source projects and that anybody can submit a report)?
The only way to find out if Open source patterns are present in closed source projects is to analyse fault reports from closed source projects.
The recent paper Software Defect Discovery and Resolution Modeling incorporating Severity by Nafreen, Shi and Fiondella caught my attention for several reasons. It does non-trivial statistical analysis (most software engineering research uses simplistic techniques), it is a recent dataset (i.e., might still be available), and the data is from a NASA project (I have long assumed that NASA is more likely than most to reliable track reported issues). Lance Fiondella kindly sent me a copy of the data (paper giving more details about the data)!
Over the years, researchers have emailed me several hundred datasets. This NASA data arrived at the start of the week, and this post is an example of the kind of initial analysis I do before emailing any questions to the authors (Lance offered to answer questions, and even included two former students in his email).
It’s only worth emailing for data when there looks to be a reasonable amount (tiny samples are rarely interesting) of a kind of data that I don’t already have lots of.
This data is fault reports on software produced by NASA, a very rare sample. The 1,934 reports were created during the development and testing of software for a space mission (which launched some time before 2016).
For Open source projects, it’s long been known that many (40%) reported faults are actually requests for enhancements. Is this a consequence of allowing anybody to submit a fault report? It appears not. In this NASA dataset, 63% of the fault reports are change requests.
This data does not include any information on the amount of runtime usage of the software, so it is not possible to estimate the reliability of the software.
Software development practices vary a lot between organizations, and organizational information is often embedded in the data. Ideally, somebody familiar with the work processes that produced the data is available to answer questions, e.g., the SiP estimation dataset.
Dates form the bulk of this data, i.e., the date on which the report entered a given phase (expressed in days since a nominal start date). Experienced developers could probably guess from the column names the work performed in each phase; see list below:
Date Created
Date Assigned
Date Build Integration
Date Canceled
Date Closed
Date Closed With Defect
Date In Test
Date In Work
Date on Hold
Date Ready For Closure
Date Ready For Test
Date Test Completed
Date Work Completed |
There are probably lots of details that somebody familiar with the process would know.
What might this date information tell us? The paper cited had fitted a Cox proportional hazard model to predict fault fix time. I might try to fit a multi-state survival model.
In a priority queue, task waiting times follow a power law, while randomly selecting an item from a non-prioritized queue produces exponential waiting times. The plot below shows the number of reports taking a given amount of time (days elapsed rounded to weeks) from being assigned to build-integration, for reports at three severity levels, with fitted exponential regression lines (code+data):
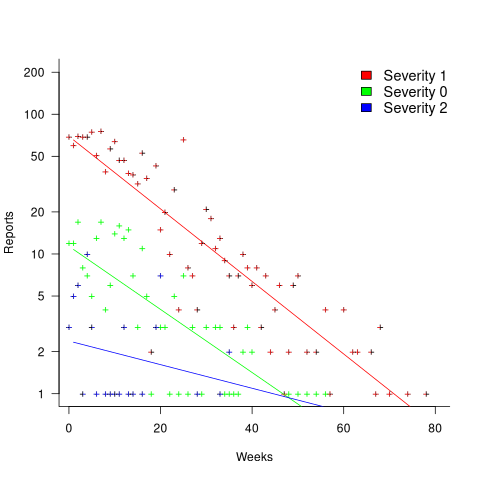
Fitting an exponential, rather than a power law, suggests that the report to handle next is effectively selected at random, i.e., reports are not in a priority queue. The number of severity 2 reports is not large enough for there to be a significant regression fit.
I now have some familiarity with the data and have spotted a pattern that may be of interest (or those involved are already aware of the random selection process).
As always, reader suggestions welcome.
I wonder if you separated out the NASA data into projects with very low number of users/usage v. more widely used products you would get different results?
There are some NASA projects – think Mars lander – which (I expect, I’m guessing) has very few users (1, 2 or 3) and therefore one might expect very few bug reports based on your previous analysis.
Conversely the data probably contains widely used software, so it would be interesting to see the difference.
I’d also note you observation that 63% of NASA, and 40% more generally, of “fault reports” are actually “change requests.” I long ago stopped differentiating between the two.
Sure, a menu option which blue-screens the machine is a clear fault and a “can you make the blue screen green” request is a feature request but many are not so clear cut.
More importantly, many companies make it difficult to request changes, thus incentivising people to asking for a bug fix.
Equally, calling something a “bug” gives the caller moral authority and, in many companies of my experience, more leverage to push for a change. “Feature requests” are seen as discretional. Hence there is office politics at play.
Ultimately there is no difference. This becomes clear when when a project has very high quality and few “bugs”, the use of the terms “bug”, “fault” and “defect” is largely subjective.
Years ago I ran a team delivering software to ITV. One day we released a new version with a “bug”. ITV were very upset and demanded a rapid fix. We did the fix and scheduled it for our next monthly release.
When the day came ITV were on the phone again complaining we had removed the cache feature which their team now depended on. Bug or feature?
@Allan Kelly
I imagine that most NASA spacecraft software has one user, in that it runs on one spacecraft. I agree that with such tiny usage, the number of reported faults should be small. However, a lot of effort goes into testing spacecraft software, because of the high cost of failure. How does one separate out the two factors of usage vs testing?
Given information on usage/testing/faults experienced from many missions, it ought to be possible to statistically separate out the effects (some arm waving). While NASA appears to have lots of data, getting it has proven to be extremely difficult. This is the first public fault data from NASA in many years.
For few/some/many people in the Agile world, the line between change request and traditional bug is regarded as being very fuzzy. For an evolving product, this make sense. I don’t have any idea how much spacecraft software evolves once it’s on its way.
When producing bespoke software, the fault/feature difference is probably important because of who gets to pay for the work.