Archive
Comparing developer/LLM coding performance
Lots of claims are being made about how LLMs will soon outperform developers on coding tasks. Given the lack of any effective measure of developer performance, these claims are meaningless. At some point, lower costs will entice management to accept good enough LLM performance as a replacement for human developers, i.e., LLM don’t need to be technically better than developers.
The outperform claims are, currently, marketing puff, and I was not expecting anybody to make a serious attempt to compare developer/LLM performance. However, concerns about AI exceeding human capacity to control it (and maybe wiping out humans) has resulted in some well funded AI safety research groups. There is at least one group actively recruiting developers to “… establish human performance baselines on tasks related to software engineering, machine learning, and cybersecurity …”.
The most talked about AI threat scenarios all seem to start with recursive self-improvement, i.e., LLMs training themselves, exponentially improving with each iteration (the implied exponential always seems to be continuously up, rather than getting exponentially closer to a maximum).
Can current LLMs improve themselves faster than a developer can?
Implementing a new LLM is beyond the ability of today’s LLM, but they can implement some of the components used to build an LLM. How does LLM performance compare against developers, on the implementation of these components?
The paper RE-Bench: Evaluating frontier AI R&D capabilities of language model agents against human experts from METR (Model Evaluation & Threat Research) comes with code and “… anonymized human expert data coming soon.” for seven tasks. The baseline was derived from the performance of 61 human experts.
I’m always pleased to see researchers doing experiments with developers. I wish there were more groups doing this kind of thing.
However, I think that these researchers have made the common mistake of using very complicated subject tasks in their experiment. Most software development tasks are mundane, with the occasional complicated task (which can often be solved by using an appropriate package/library). The tasks may be representative of the harder tasks that need to be done, but they are not representative of the complete LLM implementation scenario.
A consequence of using complicated tasks is that most subjects only had enough time to complete one task (they were given 8 hours). With so few tasks (seven) the confidence intervals are going to be very wide on any general statement about human/LLM performance. With around ten subjects per task, the individual task confidence intervals are also going to be wide.
Task 7 made me laugh: “… that generates solutions to CodeContests problems in Rust, …”
Why Rust? Did they happen to have access to lots of Rust experts, or does the research group contain enthusiastic fans of Rust? I suspect the latter. There is a certain kind of highly intelligent developer who strongly believes that writing programs in a particular language imbues the code with magical properties (their rationale won’t be worded that way). For the last few years, Rust has been one of these pixie dust languages. Many decades ago, C had this charisma.
Perhaps each generation of ever more ‘intelligent’ LLMs will choose to design a new language to use to implement their ‘successor’.
There are a myriad of tasks related to software engineering. Solving GitHub issues is a thankless task, and having LLMs reliably close open issues would be of enormous benefit. A study published two months ago obtained a 1.96% solution rate (no explicit testing of developers).
Example of an initial analysis of some new NASA data
For the last 20 years, the bug report databases of Open source projects have been almost the exclusive supplier of fault reports to the research community. Which, if any, of the research results are applicable to commercial projects (given the volunteer nature of most Open source projects and that anybody can submit a report)?
The only way to find out if Open source patterns are present in closed source projects is to analyse fault reports from closed source projects.
The recent paper Software Defect Discovery and Resolution Modeling incorporating Severity by Nafreen, Shi and Fiondella caught my attention for several reasons. It does non-trivial statistical analysis (most software engineering research uses simplistic techniques), it is a recent dataset (i.e., might still be available), and the data is from a NASA project (I have long assumed that NASA is more likely than most to reliable track reported issues). Lance Fiondella kindly sent me a copy of the data (paper giving more details about the data)!
Over the years, researchers have emailed me several hundred datasets. This NASA data arrived at the start of the week, and this post is an example of the kind of initial analysis I do before emailing any questions to the authors (Lance offered to answer questions, and even included two former students in his email).
It’s only worth emailing for data when there looks to be a reasonable amount (tiny samples are rarely interesting) of a kind of data that I don’t already have lots of.
This data is fault reports on software produced by NASA, a very rare sample. The 1,934 reports were created during the development and testing of software for a space mission (which launched some time before 2016).
For Open source projects, it’s long been known that many (40%) reported faults are actually requests for enhancements. Is this a consequence of allowing anybody to submit a fault report? It appears not. In this NASA dataset, 63% of the fault reports are change requests.
This data does not include any information on the amount of runtime usage of the software, so it is not possible to estimate the reliability of the software.
Software development practices vary a lot between organizations, and organizational information is often embedded in the data. Ideally, somebody familiar with the work processes that produced the data is available to answer questions, e.g., the SiP estimation dataset.
Dates form the bulk of this data, i.e., the date on which the report entered a given phase (expressed in days since a nominal start date). Experienced developers could probably guess from the column names the work performed in each phase; see list below:
Date Created
Date Assigned
Date Build Integration
Date Canceled
Date Closed
Date Closed With Defect
Date In Test
Date In Work
Date on Hold
Date Ready For Closure
Date Ready For Test
Date Test Completed
Date Work Completed |
There are probably lots of details that somebody familiar with the process would know.
What might this date information tell us? The paper cited had fitted a Cox proportional hazard model to predict fault fix time. I might try to fit a multi-state survival model.
In a priority queue, task waiting times follow a power law, while randomly selecting an item from a non-prioritized queue produces exponential waiting times. The plot below shows the number of reports taking a given amount of time (days elapsed rounded to weeks) from being assigned to build-integration, for reports at three severity levels, with fitted exponential regression lines (code+data):
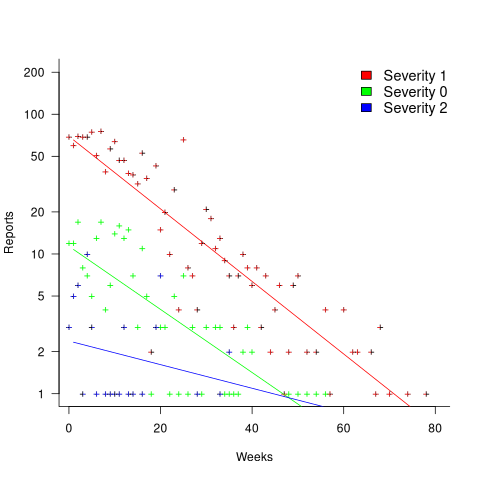
Fitting an exponential, rather than a power law, suggests that the report to handle next is effectively selected at random, i.e., reports are not in a priority queue. The number of severity 2 reports is not large enough for there to be a significant regression fit.
I now have some familiarity with the data and have spotted a pattern that may be of interest (or those involved are already aware of the random selection process).
As always, reader suggestions welcome.
Extracting information from duplicate fault reports
Duplicate fault reports (that is, reports whose cause is the same underlying coding mistake) are an underused source of information. I sometimes email the authors of a paper analysing fault data asking for information about duplicates. Duplicate information is rarely available, because the authors don’t bother to record it.
If a program’s coding mistakes are a closed population, i.e., no new ones are added or existing ones fixed, duplicate counts might be used to estimate the number of remaining mistakes.
However, coding mistakes in production software systems are invariably open populations, i.e., reported faults are fixed, and new functionality (containing new coding mistakes) is added.
A dataset made available by Sadat, Bener, and Miranskyy contains 18 years worth of information on duplicate fault reports in Apache, Eclipse and KDE. The following analysis uses the KDE data.
Fault reports are created by users, and changes in the rate of reports whose root cause is the same coding mistake provides information on changes in the number of active users, or changes in the functionality executed by the active users. The plot below shows, for 10 unique faults (different colors), the number of days between the first report and all subsequent reports of the same fault (plus character); note the log scale y-axis (code+data):

Changes in the rate at which duplicates are reported are visible as changes in the slope of each line formed by plus signs of the respective color. Possible reasons for the change include: the coding mistake appears in a new release which users do not widely install for some time, 2) a fault become sufficiently well known, or workaround provided, that the rate of reporting for that fault declines. Of course, only some fault experiences are ever reported.
Almost all books/papers on software reliability that model the occurrence of fault experiences treat them as-if they were a Non-Homogeneous Poisson Process (NHPP); in most cases, authors are simply repeating what they have read elsewhere.
Some important assumptions made by NHPP models do not apply to software faults. For instance, NHPP models assume that the probability of encountering a fault experience is the same for different coding mistakes, i.e., they are all equally likely. What does the evidence show about this assumption? If all coding mistakes had the same probability of producing a fault experience, the mean time between duplicate fault reports would be the same for all fault reports. The plot below shows the interval, in days, between consecutive duplicate fault reports, for the 392 faults whose number of duplicates was between 20 and 100, sorted by interval (out of a total of 30,377; code+data):
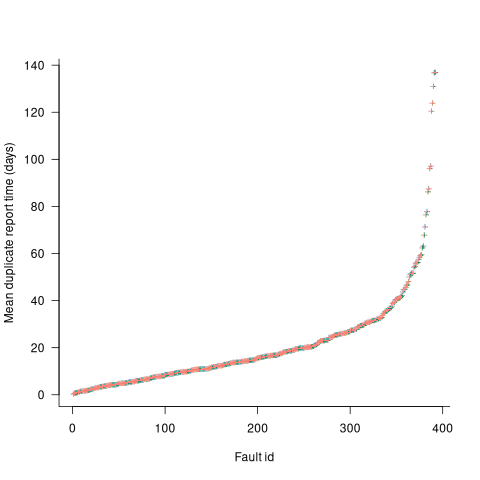
The variation in mean time between duplicate fault reports, for different faults, is evidence that different coding mistakes have different probabilities of producing a fault experience. This behavior is consistent with the observation that mistakes in deeply nested if-statements are less likely to be executed than mistakes contained in less-deeply nested code. However, this observation invalidating assumptions made by NHPP models has not prevented them dominating the research literature.
Changing development culture and practices: LLM edition
The popular perception of creating software systems is that it mainly involves writing code. In the 1950s, management treated writing code as a clerical task that just mapped the detailed requirements specified by someone with knowledge of the problem to something a computer could execute. Job titles reflected this division of labour, e.g., coder/programmer, systems analyst (the Wikipedia entry lists implementation as part of the job, this eventually became true in theory and for many was probably true in practice since the early days).
Using Large Language Models to write code based on the requirements contained in a prompt appears to take software development back to the process mandated by the managers of early software projects.
A major economic incentive for the creation of software systems is enabling more efficient work processes, with the collateral damage of decimated employment in some work functions. This happened to clerical workers and non-software engineering workers. Now it’s happening to software developers.
Hardware designers did not cease to exist once Computer-aided design became available. Technical drawing skills (larger schools once had a room full of drawing boards for teaching young teenagers) has ceased to be a job requirement (image from Wikipedia).

Software developer will remain as a job category, perhaps with reduced numbers or with reduced average pay. But the use of LLMs will change the culture and practices of software development.
The shift from using assembly language to high level languages suggests a few ideas about the kinds of changes. Using assembly language requires being reasonably familiar with the cpu architecture, e.g., register names/widths/instruction-restrictions and instruction timings. General developer chat about cpu architectures was still a thing in the 1980s, less so in the 1990s, and very rarely today (people do blog about it). Several decades from now, what will no longer be a general topic of developer conversation? Data types, perhaps; like registers, bit pattern representation is a low level detail. Since most developers don’t know much about the languages they use, it may be difficult to measure the impact of LLM usage on language knowledge.
High-level languages increase developer productivity by reducing the number of details that need to be thought about, at the cost of less efficient code. But for many applications, machine time is cheaper than human time.
LLMs increase developer productivity by reducing the need to lookup details (e.g., spelling of method names and their parameters). As confidence grows in the accuracy of LLM suggested code, developers will start accepting, whatever. What counts is whether the code works, not whether the average developer would have written something faster/smaller/idiomatic.
The early languages have a straightforward mapping from statements/declarations to machine code. Over time, languages were created that allowed developers to think less and less about implementation details, at the cost of supporting constructs that could introduce lots of hidden overhead. I expect that customer demand will incentivize LLM functionality that reduces what developers need to think about.
A real danger of LLM usage is that it will, eventually, result in programs a lot more bloated than humans have managed to achieve. There are physical constraints restricting what hardware designers can do, and these constraints show up in patterns of behavior, e.g., Rent’s rule relating the number of external connections in a logic block to the number of logic gates in the block. There are common usage patterns in existing code, but no theory suggesting they are desirable, or not, in any sense. I await having enough LLM generated production code to make statistically significant measurements.
I suspect that these days most developers are writing glue code, or short programs, and in the near term I expect that most LLM code will fill this need. Unfortunately, there is very little research/measurement on glue code/short program, so there are no known developer usage patterns to compare LLMs against.
Recent Comments