Modelling estimate/actual including uncertainty in the estimate
What is an effective technique for modelling the relationship between the time estimated to implement a task and the actual time taken to implement that task?
A regression model is the obvious approach. However, an important assumption made by the commonly used regression techniques is not met by estimate/actual project data
The commonly used regression techniques involve two kinds of variables: the explanatory variable and the response variable (also known as the independent and dependent variables). For instance, in the equation  ,
,  is the explanatory variable and
is the explanatory variable and  is the response variable.
is the response variable.
When fitting a regression model to measurement data, the fitted equation is assumed to have the form such as:  , where
, where  is uncertainty in the value of , with the valued assumed to have no uncertainty;
is uncertainty in the value of , with the valued assumed to have no uncertainty;  and
and  are constants fitted by the modelling process. The values returned by the model fitting process include an estimate for , as well as estimates for and .
are constants fitted by the modelling process. The values returned by the model fitting process include an estimate for , as well as estimates for and .
When running an experiment, the values of the explanatory variables(e.g., ) are chosen by the experimenter, with the subject providing the value of the response variable, e.g., .
What does this technical detail have to do with estimation data?
The task estimate/actual values are both provide by the subject (i.e., the developer), there is no experimenter providing one of the values; in fact there is no experiment, these are measurements of things that happened. Both the estimate and actual are response variables, and both contain some amount of uncertainty, and the fitting process needs to take this into account. The appropriate regression technique to use for this case is an errors-in-variables model, which fits the equation +epsilon") , with
, with  being the uncertainty in .
being the uncertainty in .
A previous post discussed the surprising behavior that can occur when failing to use errors-in-variables regression for where the data does not contain any explanatory variables, i.e., all the variables contain uncertainty.
The process of fitting an errors-in-variables regression model requires additional input, a value for has to be specified. Taking the example of task estimation, possible uncertainties in the estimate include: misunderstanding of the requirement(s), faded memory of the actual time previously taken by very similar tasks, an inaccurate model of developer skills, and a preference for using round numbers.
What data is available on the uncertainty of individual task estimates? I know of one study where, unknown to them, the individuals estimated the same task twice (in fact, seven people each estimated the same six distinct tasks twice, over a period of three-months). The plot below shows the first/second estimate made by each person for each of the six tasks, with the grey line showing where first==second estimate (code+data):
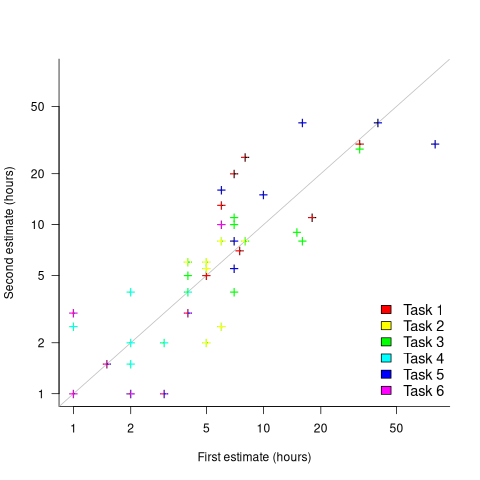
Assuming the estimation uncertainty in this experiment’s data is roughly equal to the estimation uncertainty in other estimation datasets, of tasks taking up to 20 hours, how might it be used to calculate a value for the uncertainty in estimated values?
Two possibilities include:
- Assuming that the uncertainty in both the first and second estimates is equal, a model can be fitted using Deming regression (which treats both variables as having the same uncertainty), and the residual standard error of this model used as the value of . This value for a fitted multiplicative model is 0.6 (code+data),
- using the mean of the relative errors,
}/Est_1") ; its value is 0.55.
; its value is 0.55.
How different are the models built using linear regression and errors-in-variables regression, for small task estimates?
A basic linear regression model fitted to the SiP estimation dataset is:  .
.
Updating this model, using SIMEX, to take into uncertainty in the value of  gives, for an uncertainty error of 0.55:
gives, for an uncertainty error of 0.55:  , and for an uncertainty error of 0.60:
, and for an uncertainty error of 0.60:  . The coefficients for the two models are essentially the same (code+data).
. The coefficients for the two models are essentially the same (code+data).
The exponent value is the noticeable difference between the linear regression and errors-in-variables regression models. Adding the assumed amount of uncertainty (based on data from one experiment) to the estimated value leads to a model where estimate/actual are very close to having a linear relationship.
Is this errors-in-variables model any closer to reality than the linear regression model? The model shows that the estimate/actual relationship is closer to linear than was previously thought. Until more data becomes available, we won’t know how close this relationship actually is.
The people who made the estimates in the SiP data also performed the work that took the recorded actual time. Assigning a task to a different person could produce both a different estimate and a different actual, but these possible values are unknown. On a larger scale, different companies bidding on the same contract specify different amounts and have different implementations times; data showing these differences.
Recent Comments