Benchmarking fuzzers
Fuzzing has become a popular area of research in the reliability & testing community, with a stream of papers claiming to have created a better tool/algorithm. The claims of ‘betterness’, made by the authors, often derive from the number of previously unreported faults discovered in some collection of widely used programs.
Developers in industry will be interested in using fuzzing if it provides a cost-effective means of discovering coding mistakes that are likely to result in customers experiencing a serious fault. This requirement roughly translates to: minimal cost for finding maximal distinct mistakes (finding the same mistake more than once is wasted effort); whether a particular coding mistake is likely to produce a serious customer fault is a decision decided by people.
How do different fuzzing tools compare, when benchmarking the number of distinct mistakes they each find, for a given amount of cpu time?
TL;DR: I don’t know, and this approach is probably not a useful way of comparing fuzzers.
Fuzzing researchers are currently competing on the number of previously unreported faults discovered, i.e., not listed in the fuzzed program’s database of fault reports. Most research papers only report the number of distinct faults discovered in each program fuzzed, the amount of wall clock hours/days used (sometimes weeks), and the characteristics of the computer/cluster on which the campaign was run. This may be enough information to estimate an upper bound on faults per unit of cpu time; more detailed data is rarely available (I have emailed the authors of around a dozen papers asking for more detailed data).
A benchmark based on comparing faults discovered per unit of cpu time only makes sense when the new fault discovery rate is roughly constant. Experience shows that discovery time can vary by orders of magnitude.
Code coverage is a fuzzer performance metric that is starting to be widely used by researchers. Measures of coverage include: statements/basic blocks, conditions, or some object code metric. Coverage has the advantage of providing defined fuzzer objectives (e.g., generate input that causes uncovered code to be executed), and is independent of the number of coding mistakes present in the code.
How is a fuzzer likely to be used in industry?
The fuzzing process may be incremental, discovering a few coding mistakes, fixing them, rinse and repeat; or, perhaps fuzzing is run in a batch over, say, a weekend when the test machine is available.
The current research approach is batch based, not fixing any of the faults discovered (earlier researchers fixed faults).
Not fixing discovered faults means that underlying coding mistakes may be repeatedly encountered, which wastes cpu time because many fuzzers terminate the run when the program they are testing crashes (a program crash is a commonly encountered fuzzing fault experience). The plot below shows the number of occurrences of the same underlying coding mistake, when running eight fuzzers on the program JasPer; 77 distinct coding mistakes were discovered, with three fuzzers run over 3,000 times, four run over 1,500 times, and one run 62 times (see Green Fuzzing: A Saturation-based Stopping Criterion using Vulnerability Prediction by Lipp, Elsner, Kacianka, Pretschner, Böhme, and Banescu; code+data):
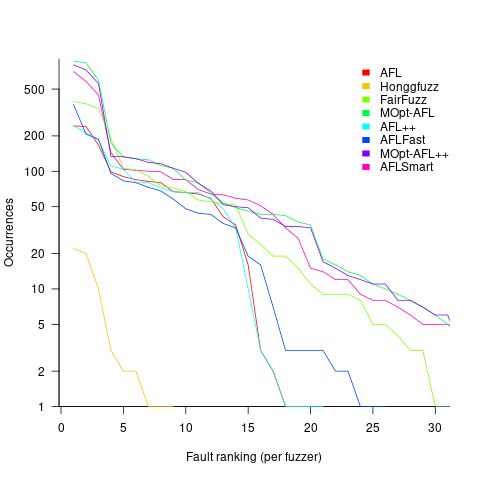
I have not seen any paper where the researchers attempt to reduce the number of times the same root cause coding mistake is discovered. Researchers are focused on discovering unreported faults; and with around 98% of fault discoveries being duplicates, appear to have resources to squander.
If developers primarily use a find/fix iterative process, then duplicate discoveries will be an annoying drag on cpu time. However, duplicate discoveries are going to make it difficult to effectively benchmark fuzzers.
Recent Comments