Multiple estimates for the same project
The first question I ask, whenever somebody tells me that a project was delivered on schedule (or within budget), is which schedule (or budget)?
New schedules are produced for projects that are behind schedule, and costs get re-estimated.
What patterns of behavior might be expected to appear in a project’s reschedulings?
It is to be expected that as a project progresses, subsequent schedules become successively more accurate (in the sense of having a completion date and cost that is closer to the final values). The term cone of uncertainty is sometimes applied as a visual metaphor in project management, with the schedule becoming less uncertain as the project progresses.
The only publicly available software project rescheduling data, from Landmark Graphics, is for completed projects, i.e., cancelled projects are not included (121 completed projects and 882 estimates).
The traditional project management slide has some accuracy metric improving as work on a project approaches completion. The plot below shows the percentage of a project completed when each estimate is made, against the ratio  ; the y-axis uses a log scale so that under/over estimates appear symmetrical (code+data):
; the y-axis uses a log scale so that under/over estimates appear symmetrical (code+data):
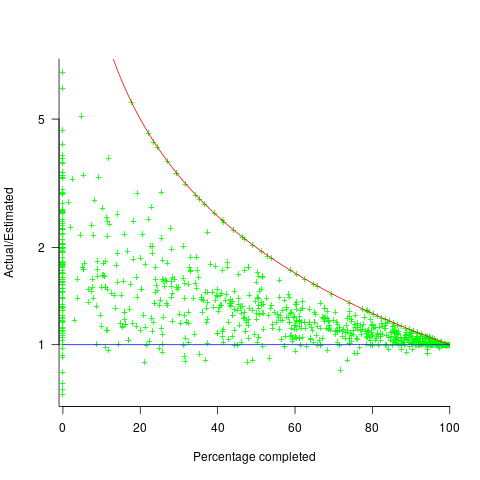
The closer a point to the blue line, the more accurate the estimate. The red line shows maximum underestimation, i.e., estimating that the project is complete when there is still more work to be done. A new estimate must be greater than (or equal) to the work already done, i.e.,  , and
, and  .
.
Rearranging, we get:  (plotted in red). The top of the ‘cone’ does not represent managements’ increasing certainty, with project progress, it represents the mathematical upper bound on the possible inaccuracy of an estimate.
(plotted in red). The top of the ‘cone’ does not represent managements’ increasing certainty, with project progress, it represents the mathematical upper bound on the possible inaccuracy of an estimate.
In theory there is no limit on overestimating (i.e., points appearing below the blue line), but in practice management are under pressure to deliver as early as possible and to minimise costs. If management believe they have overestimated, they have an incentive to hang onto the time/money allocated (the future is uncertain).
Why does management invest time creating a new schedule?
If information about schedule slippage leaks out, project management looks bad, which creates an incentive to delay rescheduling for as long as possible (i.e., let’s pretend everything will turn out as planned). The Landmark Graphics data comes from an environment where management made weekly reports and estimates were updated whenever the core teams reached consensus (project average was eight times).
The longer a project is being worked on, the greater the opportunity for more unknowns to be discovered and the schedule to slip, i.e., longer projects are expected to acquire more re-estimates. The plot below shows the number of estimates made, for each project, against the initial estimated duration (red/green) and the actual duration (blue/purple); lines are loess fits (code+data):
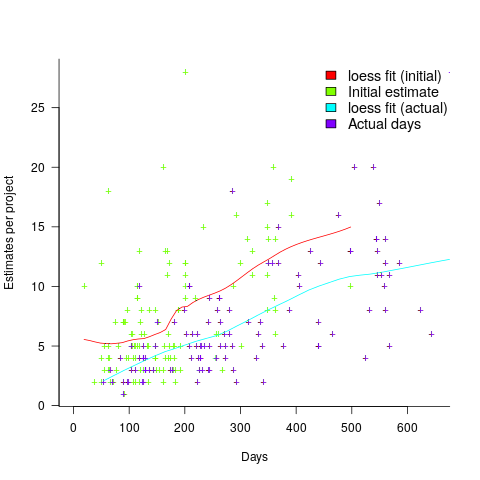
What might be learned from any patterns appearing in this data?
When presented with data on the sequence of project estimates, my questions revolve around the reasons for spending time creating a new estimate, and the amount of time spent on the estimate.
A lot of time may have been invested in the original estimate, but how much time is invested in subsequent estimates? Are later estimates simply calculated as a percentage increase, a politically acceptable value (to the stakeholder funding for the project), or do they take into account what has been learned so far?
The information needed to answer these answers is not present in the data provided.
However, this evidence of the consistent provision of multiple project estimates drives another nail in to the coffin of estimation research based on project totals (e.g., if data on project estimates is provided, one estimate per project, were all estimates made during the same phase of the project?)
My datum point is that of resets, taking into account everything learnt until then, and I sometimes took flak for that, especially when the new estimate was politically incorrect.