Archive
Fitting discontinuous data from disparate sources
Sorting and searching are probably the most widely performed operations in computing; they are extensively covered in volume 3 of The Art of Computer Programming. Algorithm performance is influence by the characteristics of the processor on which it runs, and the size of the processor cache(s) has a significant impact on performance.
A study by Khuong and Morin investigated the performance of various search algorithms on 46 different processors. Khuong The two authors kindly sent me a copy of the raw data; the study webpage includes lots of plots.
The performance comparison involved 46 processors (mostly Intel x86 compatible cpus, plus a few ARM cpus) times 3 array datatypes times 81 array sizes times 28 search algorithms. First a 32/64/128-bit array of unsigned integers containing N elements was initialized with known values. The benchmark iterated 2-million times around randomly selecting one of the known values, and then searching for it using the algorithm under test. The time taken to iterate 2-million times was recorded. This was repeated for the 81 values of N, up to 63,095,734, on each of the 46 processors.
The plot below shows the results of running each algorithm benchmarked (colored lines) on an Intel Atom D2700 @ 2.13GHz, for 32-bit array elements; the kink in the lines occur roughly at the point where the size of the array exceeds the cache size (all code+data):
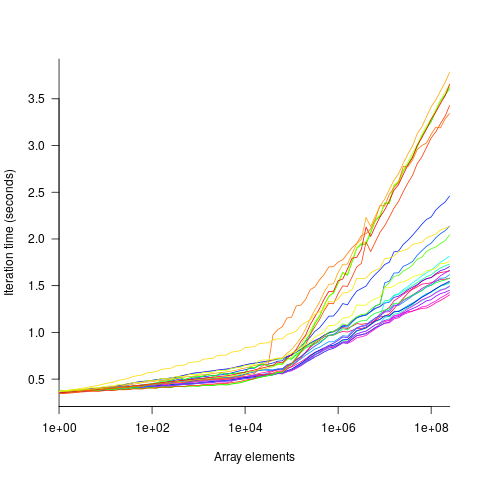
What is the most effective way of analyzing the measurements to produce consistent results?
One approach is to build two regression models, one for the measurements before the cache ‘kink’ and one for the measurements after this kink. By adding in a dummy variable at the kink-point, it is possible to merge these two models into one model. The problem with this approach is that the kink-point has to be chosen in advance. The plot shows that the performance kink occurs before the array size exceeds the cache size; other variables are using up some of the cache storage.
This approach requires fitting 46*3=138 models (I think the algorithm used can be integrated into the model).
If data from lots of processors is to be fitted, or the three datatypes handled, an automatic way of picking where the first regression model should end, and where the second regression model should start is needed.
Regression discontinuity design looks like it might be applicable; treating the point where the array size exceeds the cache size as the discontinuity. Traditionally discontinuity designs assume a sharp discontinuity, which is not the case for these benchmarks (R’s rdd package worked for one algorithm, one datatype running on one processor); the more recent continuity-based approach supports a transition interval before/after the discontinuity. The R package rdrobust supports a continued-based approach, but seems to expect the discontinuity to be a change of intercept, rather than a change of slope (or rather, I could not figure out how to get it to model a just change of slope; suggestions welcome).
Another approach is to use segmented regression, i.e., one of more distinct lines. The package segmented supports fitting this kind of model, and does estimate what they call the breakpoint (the user has to provide a first estimate).
I managed to fit a segmented model that included all the algorithms for 32-bit data, running on one processor (code+data). Looking at the fitted model I am not hopeful that adding data from more than one processor would produce something that contained useful information. I suspect that there are enough irregular behaviors in the benchmark runs to throw off fitting quality.
I’m always asking for more data, and now I have more data than I know how to analyze in a way that does not require me to build 100+ models 🙁
Suggestions welcome.
Research software code is likely to remain a tangled mess
Research software (i.e., software written to support research in engineering or the sciences) is usually a tangled mess of spaghetti code that only the author knows how to use. Very occasionally I encounter well organized research software that can be used without having an email conversation with the author (who has invariably spent years iterating through many versions).
Spaghetti code is not unique to academia, there is plenty to be found in industry.
Structural differences between academia and industry make it likely that research software will always be a tangled mess, only usable by the person who wrote it. These structural differences include:
- writing software is a low status academic activity; it is a low status activity in some companies, but those involved don’t commonly have other higher status tasks available to work on. Why would a researcher want to invest in becoming proficient in a low status activity? Why would the principal investigator spend lots of their grant money hiring a proficient developer to work on a low status activity?
I think the lack of status is rooted in researchers’ lack of appreciation of the effort and skill needed to become a proficient developer of software. Software differs from that other essential tool, mathematics, in that most researchers have spent many years studying mathematics and understand that effort/skill is needed to be able to use it.
Academic performance is often measured using citations, and there is a growing move towards citing software,
- many of those writing software know very little about how to do it, and don’t have daily contact with people who do. Recent graduates are the pool from which many new researchers are drawn. People in industry are intimately familiar with the software development skills of recent graduates, i.e., the majority are essentially beginners; most developers in industry were once recent graduates, and the stream of new employees reminds them of the skill level of such people. Academics see a constant stream of people new to software development, this group forms the norm they have to work within, and many don’t appreciate the skill gulf that exists between a recent graduate and an experienced software developer,
- paid a lot less. The handful of very competent software developers I know working in engineering/scientific research are doing it for their love of the engineering/scientific field in which they are active. Take this love away, and they will find that not only does industry pay better, but it also provides lots of interesting projects for them to work on (academics often have the idea that all work in industry is dull).
I have met people who have taken jobs writing research software to learn about software development, to make themselves more employable outside academia.
Does it matter that the source code of research software is a tangled mess?
The author of a published paper is supposed to provide enough information to enable their work to be reproduced. It is very unlikely that I would be able to reproduce the results in a chemistry or genetics paper, because I don’t know enough about the subject, i.e., I am not skilled in the art. Given a tangled mess of source code, I think I could reproduce the results in the associated paper (assuming the author was shipping the code associated with the paper; I have encountered cases where this was not true). If the code failed to build correctly, I could figure out (eventually) what needed to be fixed. I think people have an unrealistic expectation that research code should just build out of the box. It takes a lot of work by a skilled person to create to build portable software that just builds.
Is it really cost-effective to insist on even a medium-degree of buildability for research software?
I suspect that the lifetime of source code used in research is just as short and lonely as it is in other domains. One study of 214 packages associated with papers published between 2001-2015 found that 73% had not been updated since publication.
I would argue that a more useful investment would be in testing that the software behaves as expected. Many researchers I have spoken to have not appreciated the importance of testing. A common misconception is that because the mathematics is correct, the software must be correct (completely ignoring the possibility of silly coding mistakes, which everybody makes). Commercial software has the benefit of user feedback, for detecting some incorrect failures. Research software may only ever have one user.
Research software engineer is the fancy title now being applied to people who write the software used in research. Originally this struck me as an example of what companies do when they cannot pay people more, they give them a fancy title. Recently the Society of Research Software Engineering was setup. This society could certainly help with training, but I don’t see it making much difference with regard status and salary.
Update
This post generated a lot of discussion on the research software mailing list, and Peter Schmidt invited me to do a podcast with him. Here it is.
Widely used programming languages: past, present, and future
Programming languages are like pop groups in that they have followers, fans and supporters; new ones are constantly being created and some eventually become widely popular, while those that were once popular slowly fade away or mutate into something else.
Creating a language is a relatively popular activity. Science fiction and fantasy authors have been doing it since before computers existed, e.g., the Elf language Quenya devised by Tolkien, and in the computer age Star Trek’s Klingon. Some very good how-to books have been written on the subject.
As soon as computers became available, people started inventing programming languages.
What have been the major factors influencing the growth to widespread use of a new programming languages (I’m ignoring languages that become widespread within application niches)?
Cobol and Fortran became widely used because there was widespread implementation support for them across computer manufacturers, and they did not have to compete with any existing widely used languages. Various niches had one or more languages that were widely used in that niche, e.g., Algol 60 in academia.
To become widely used during the mainframe/minicomputer age, a new language first had to be ported to the major computers of the day, whose products sometimes supported multiple, incompatible operating systems. No new languages became widely used, in the sense of across computer vendors. Some new languages were widely used by developers, because they were available on IBM computers; for several decades a large percentage of developers used IBM computers. Based on job adverts, RPG was widely used, but PL/1 not so. The use of RPG declined with the decline of IBM.
The introduction of microcomputers (originally 8-bit, then 16, then 32, and finally 64-bit) opened up an opportunity for new languages to become widely used in that niche (which would eventually grow to be the primary computing platform of its day). This opportunity occurred because compiler vendors for the major languages of the day did not want to cannibalize their existing market (i.e., selling compilers for a lot more than the price of a microcomputer) by selling a much lower priced product on microcomputers.
BASIC became available on practically all microcomputers, or rather some dialect of BASIC that was incompatible with all the other dialects. The availability of BASIC on a vendor’s computer promoted sales of the hardware, and it was not worthwhile for the major vendors to create a version of BASIC that reduced portability costs; the profit was in games.
The dominance of the Microsoft/Intel partnership removed the high cost of porting to lots of platforms (by driving them out of business), but created a major new obstacle to the wide adoption of new languages: Developer choice. There had always been lots of new languages floating around, but people only got to see the subset that were available on the particular hardware they targeted. Once the cpu/OS (essentially) became a monoculture most new languages had to compete for developer attention in one ecosystem.
Pascal was in widespread use for a few years on micros (in the form of Turbo Pascal) and university computers (the source of Wirth’s ETH compiler was freely available for porting), but eventually C won developer mindshare and became the most widely used language. In the early 1990s C++ compiler sales took off, but many developers were writing C with a few C++ constructs scattered about the code (e.g., use of new, rather than malloc/free).
Next, the Internet took off, and opened up an opportunity for new languages to become dominant. This opportunity occurred because Internet related software was being made freely available, and established compiler vendors were not interested in making their products freely available.
There were people willing to invest in creating a good-enough implementation of the language they had invented, and giving it away for free. Luck, plus being in the right place at the right time resulted in PHP and Javascript becoming widely used. Network effects prevent any other language becoming widely used. Compatible dialects of PHP and Javascript may migrate widespread usage to quite different languages over time, e.g., Facebook’s Hack.
Java rode to popularity on the coat-tails of the Internet, and when it looked like security issues would reduce it to niche status, it became the vendor supported language for one of the major smart-phone OSs.
Next, smart-phones took off, but the availability of Open Source compilers closed the opportunity window for new languages to become dominant through lack of interest from existing compiler vendors. Smart-phone vendors wanted to quickly attract developers, which meant throwing their weight behind a language that many developers were already familiar with; Apple went with Objective-C (which evolved to Swift), Google with Java (which evolved to Kotlin, because of the Oracle lawsuit).
Where does Python fit in this grand scheme? I don’t yet have an answer, or is my world-view wrong to treat Python usage as being as widespread as C/C++/Java?
New programming languages continue to be implemented; I don’t see this ever stopping. Most don’t attract more users than their implementer, but a few become fashionable amongst the young, who are always looking to attach themselves to something new and shiny.
Will a new programming language ever again become widely used?
Like human languages, programming languages experience strong networking effects. Widely used languages continue to be widely used because many companies depend on code written in it, and many developers who can use it can obtain jobs; what company wants to risk using a new language only to find they cannot hire staff who know it, and there are not many people willing to invest in becoming fluent in a language with no immediate job prospects.
Today’s widely used programmings languages succeeded in a niche that eventually grew larger than all the other computing ecosystems. The Internet and smart-phones are used by everybody on the planet, there are no bigger ecosystems to provide new languages with a possible route to widespread use. To be widely used a language first has to become fashionable, but from now on, new programming languages that don’t evolve from (i.e., be compatible with) current widely used languages are very unlikely to migrate from fashionable to widely used.
It has always been possible for a proficient developer to dedicate a year+ of effort to create a new language implementation. Adding the polish need to make it production ready used to take much longer, but these days tool chains such as LLVM supply a lot of the heavy lifting. The problem for almost all language creators/implementers is community building; they are terrible at dealing with other developers.
It’s no surprise that nearly all the new languages that become fashionable originate with language creators who work for a company that happens to feel a need for a new language. Examples include:
- Go created by Google for internal use, and attracted an outside fan base. Company languages are not new, with IBM’s PL/1 being the poster child (or is there a more modern poster child). At the moment Go is a trendy language, and this feeds a supply of young developers willing to invest in learning it. Once the trendiness wears off, Google will start to have problems recruiting developers, the reason: Being labelled as a Go developer limits job prospects when few other companies use the language. Talk to a manager who has tried to recruit developers to work on applications written in Fortran, Pascal and other once-widely used languages (and even wannabe widely used languages, such as Ada),
- Rust a vanity project from Mozilla, which they have now
abandonedcast adrift. Did Rust become fashionable because it arrived at the right time to become the not-Google language? I await a PhD thesis on the topic of the rise and fall of Rust, - Microsoft’s C# ceased being trendy some years ago. These days I don’t have much contact with developers working in the Microsoft ecosystem, so I don’t know anything about the state of the C# job market.
Every now and again a language creator has the social skills needed to start an active community. Zig caught my attention when I read that its creator, Andrew Kelley, had quit his job to work full-time on Zig. Two and a-half years later Zig has its own track at FOSEM’21.
Will Zig become the next fashionable language, as Rust/Go popularity fades? I’m rooting for Zig because of its name, there are relatively few languages whose name starts with Z; the start of the alphabet is over-represented with language names. It would be foolish to root for a language because of a belief that it has magical properties (e.g., powerful, readable, maintainable), but the young are foolish.
Performance impact of comments on tasks taking a few minutes
How cost-effective is an investment in commenting code?
Answering this question requires knowing the time needed to write the comment and the time they save for later readers of the code.
A recent study investigated the impact of comments in small programming tasks on developer performance, and Sebastian Nielebock, the first author, kindly sent me a copy of the data.
How might the performance impact of comments be measured?
The obvious answer is to ask subjects to solve a coding problem, with half the subjects working with code containing comments and the other half the same code without the comments. This study used three kinds of commenting: No comments, Implementation comments and Documentation comments; the source was in Java.
Were the comments in the experiment useful, in the sense of providing information that was likely to save readers some time? A preliminary run was used to check that the comments provided some benefit.
The experiment was designed to be short enough that most subjects could complete it in less than an hour (average time to complete all tasks was 31 minutes). My own experience with running experiments is that it is possible to get professional developers to donate an hour of their time.
What is a realistic and experimentally useful amount of work to ask developers to in an hour?
The authors asked subjects to complete 9-tasks; three each of applying the code (i.e., use the code’s API), fix a bug in the code, and extend the code. Would a longer version of one of each, rather than a shorter three of each been better? I think the only way to find out is to try it both ways (I hope the authors plan to do another version).
What were the results (code+data)?
Regular readers will know, from other posts discussing experiments, that the biggest factor is likely to be subject (professional developers+students) differences, and this is true here.
Based on a fitted regression model, Documentation comments slowed performance on a task by 30 seconds, compared to No comments and Implementation comments (which both had the same performance impact). Given that average task completion time was 205 seconds, this is a 15% slowdown for Documentation comments.
This study set out to measure the performance impact of comments on small programming tasks. The answer, at least for tasks designed to take a few minutes, is that No comments, or if comments are required, then write Implementation comments.
This experiment measured the performance impact of comments on developers who did not write the code containing them. These developers have to first read and understand the comments (which takes time). However, the evidence suggests that code is mostly modified by the developer who wrote it (just reading the code does not leave a record that can be analysed). In this case, the reading a comment (that the developer previously wrote) can trigger existing memories, i.e., it has a greater information content for the original author.
Will comments have a bigger impact when read by the person who wrote them (and the code), or on tasks taking more than a few minutes? I await the results of more experiments…
Update: I have updated the script based on feedback about the data from Sebastian Nielebock.