Archive
Learning useful stuff from the Ecosystems chapter of my book
What useful, practical things might professional software developers learn from the Ecosystems chapter in my evidence-based software engineering book?
This week I checked the ecosystems chapter; what useful things did I learn (combined with everything I learned during all the other weeks spent working on this chapter)?
A casual reader would conclude that software engineering ecosystems involved lots of topics, with little or no theory connecting them. I had great plans for the connecting theories, but lack of detailed data, time and inspiration means the plans remain in my head (e.g., modelling the interaction between the growth of source code written in a particular language and the number of developers actively using that language).
For managers, the usefulness of this chapter is the strategic perspective it provides. How does what they and others are doing relate to everything else, and what patterns of evolution are to be expected?
Software people like to think that everything about software is unique. Software is unique, but the activities around it follow patterns that have been followed by other unique technologies, e.g., the automobile and jet engines. There is useful stuff to be learned from non-software ecosystems, and the chapter discusses some similarities I have learned about.
There is lots more evidence of the finite lifetime of software related items: lifetime of products, Linux distributions, packages, APIs and software careers.
Some readers might be surprised by the amount of discussion about what is now historical hardware. Software needs hardware to execute it, and the characteristics of the hardware of the day can have a significant impact on the characteristics of the software that gets written. I suspect that most of this discussion will not be that useful to most readers, but it provides some context around why things are the way they are today.
Readers with a wide knowledge of software ecosystems will notice that several major ecosystems barely get a mention. Embedded systems is a huge market, as is Microsoft Windows, and very many professional developers use C++. However, to date the focus of most research has been around Linux and Android (because its use of Java, a language often taught in academia), and languages that have a major package repository. So the ecosystems chapter presents a rather blinkered view of software engineering ecosystems.
What did I learn from this chapter?
Software ecosystems are bigger and more complicated that I had originally thought.
Readers might have a completely different learning experience from reading the ecosystems chapter. What useful things did you learn from the ecosystems chapter?
Learning useful stuff from the Projects chapter of my book
What useful, practical things might professional software developers learn from the Projects chapter in my evidence-based software engineering book?
This week I checked the projects chapter; what useful things did I learn (combined with everything I learned during all the other weeks spent working on this chapter)?
There turned out to be around three to four times more data publicly available than I had first thought. This is good, but there is a trap for the unweary. For many topics there is one data set, and that one data set may not be representative. What is needed is a selection of data from various sources, all relating to a given topic.
Some data is better than no data, provided small data sets are treated with caution.
Estimation is a popular research topic: how long will a project take and how much will it cost.
After reading all the papers I learned that existing estimation models are even more unreliable than I had thought, and what is more, there are plenty of published benchmarks showing how unreliable the models really are (these papers never seem to get cited).
Models that include lines of code in the estimation process (i.e., the majority of models) need a good estimate of the likely number of lines in the final software system. One issue that nobody had considered was the impact of developer variability on the number of lines written to implement the same functionality, which turns out to be large. Oops.
Machine learning has infested effort estimation research. What the machine learning models actually do is estimate adjustment, i.e., they do not create their own estimate but adjust one passed in as input to the model. Most estimation data sets are tiny, and only contain a few different variables; unless the estimate is included in the training phase, the generated model produces laughable results. Oops.
The good news is that there appear to be lots of recurring patterns in the project data. This is good news because recurring patterns are something to be explained by a theory of software project development (apparent randomness is bad news, from the perspective of coming up with a model of what is going on). I think we are still a long way from having workable theories, but seeing patterns is a good sign that one or more theories will be possible.
I think that the main takeaway from this chapter is that software often has a short lifetime. People in industry probably have a vague feeling that this is true, from experience with short-lived projects. It is not cost effective to approach commercial software development from the perspective that the code will live a long time; some code does live a long time, but most dies young. I see the implications of this reality being a major source of contention with those in academia who have spent too long babbling away in front of teenagers (teaching the creation of idealized software that lives on forever), and little or no time building software systems.
A lot of software is written by teams of people, however, there is not a lot of data available on teams (software or otherwise). Given the difficulty of hiring developers, companies have to make do with what they have, so a theory of software teams might not be that useful in practice.
Readers might have a completely different learning experience from reading the projects chapter. What useful things did you learn from the projects chapter?
Learning useful stuff from the Reliability chapter of my book
What useful, practical things might professional software developers learn from my evidence-based software engineering book?
Once the book is officially released I need to have good answers to this question (saying: “Well, I decided to collect all the publicly available software engineering data and say something about it”, is not going to motivate people to read the book).
This week I checked the reliability chapter; what useful things did I learn (combined with everything I learned during all the other weeks spent working on this chapter)?
A casual reader skimming the chapter would conclude that little was known about software reliability, and they would be right (I already knew this, but I learned that we know even less than I thought was known), and many researchers continue to dig in unproductive holes.
A reader with some familiarity with reliability research would be surprised to see that some ‘major’ topics are not discussed.
The train wreck that is machine learning has been avoided (not forgetting that the data used is mostly worthless), mutation testing gets mentioned because of some interesting data (the underlying problem is that mutation testing assumes that coding mistakes are local to one line, but in practice coding mistakes often involve multiple lines), and the theory discussions don’t mention non-homogeneous Poisson process as the basis for software fault models (because this process is not capable of solving the questions asked).
What did I learn? My highlights include:
- Anne Choa‘s work on population estimation. The takeaway from this work is that if people want to estimate the number of remaining fault experiences, based on previous experienced faults, then every occurrence (i.e., not just the first) of a fault needs to be counted,
- Phyllis Nagel and Janet Dunham’s top read work on software testing,
- the variability in the numeric percentage that people assign to probability terms (e.g., almost all, likely, unlikely) is much wider than I would have thought,
- the impact of the distribution of input values on fault experiences may be detectable,
- really a lowlight, but there is a lot less publicly available data than I had expected (for the other chapters there was more data than I had expected).
The last decade has seen fuzzing grow to dominate the headlines around software reliability and testing, and provide data for people who write evidence-based books. I don’t have much of a feel for how widely used it is in industry, but it is a very useful tool for reliability researchers.
Readers might have a completely different learning experience from reading the reliability chapter. What useful things did you learn from the reliability chapter?
Impact of function size on number of reported faults
Are longer functions more likely to contain more coding mistakes than shorter functions?
Well, yes. Longer functions contain more code, and the more code developers write the more mistakes they are likely to make.
But wait, the evidence shows that most reported faults occur in short functions.
This is true, at least in Java. It is also true that most of a Java program’s code appears in short methods (in C 50% of the code is contained in functions containing 114 or fewer lines, while in Java 50% of code is contained in methods containing 4 or fewer lines). It is to be expected that most reported faults appear in short functions. The plot below shows, left: the percentage of code contained in functions/methods containing a given number of lines, and right: the cumulative percentage of lines contained in functions/methods containing less than a given number of lines (code+data):
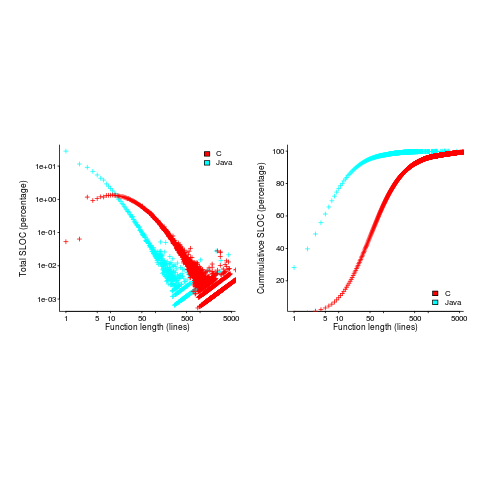
Does percentage of program source really explain all those reported faults in short methods/functions? Or are shorter functions more likely to contain more coding mistakes per line of code, than longer functions?
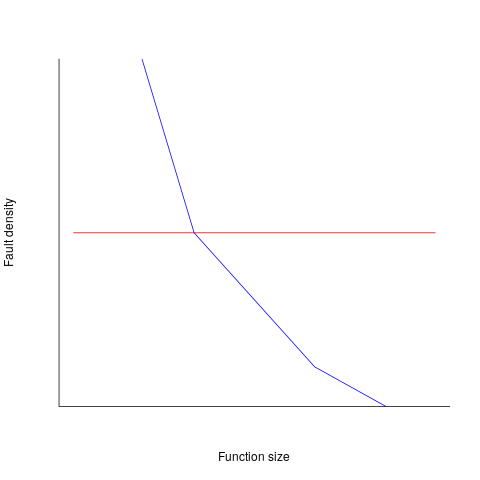
Reported faults per line of code is often referred to as: defect density.
If defect density was independent of function length, the plot of reported faults against function length (in lines of code) would be horizontal; red line below. If every function contained the same number of reported faults, the plotted line would have the form of the blue line below.
Two things need to occur for a fault to be experienced. A mistake has to appear in the code, and the code has to be executed with the ‘right’ input values.
Code that is never executed will never result in any fault reports.
In a function containing 100 lines of executable source code, say, 30 lines are rarely executed, they will not contribute as much to the final total number of reported faults as the other 70 lines.
How does the average percentage of executed LOC, in a function, vary with its length? I have been rummaging around looking for data to help answer this question, but so far without any luck (the llvm code coverage report is over all tests, rather than per test case). Pointers to such data very welcome.
Statement execution is controlled by if-statements, and around 17% of C source statements are if-statements. For functions containing between 1 and 10 executable statements, the percentage that don’t contain an if-statement is expected to be, respectively: 83, 69, 57, 47, 39, 33, 27, 23, 19, 16. Statements contained in shorter functions are more likely to be executed, providing more opportunities for any mistakes they contain to be triggered, generating a fault experience.
Longer functions contain more dependencies between the statements within the body, than shorter functions (I don’t have any data showing how much more). Dependencies create opportunities for making mistakes (there is data showing dependencies between files and classes is a source of mistakes).
The previous analysis makes a large assumption, that the mistake generating a fault experience is contained in one function. This is true for 70% of reported faults (in AspectJ).
What is the distribution of reported faults against function/method size? I don’t have this data (pointers to such data very welcome).
The plot below shows number of reported faults in C++ classes (not methods) containing a given number of lines (from a paper by Koru, Eman and Mathew; code+data):
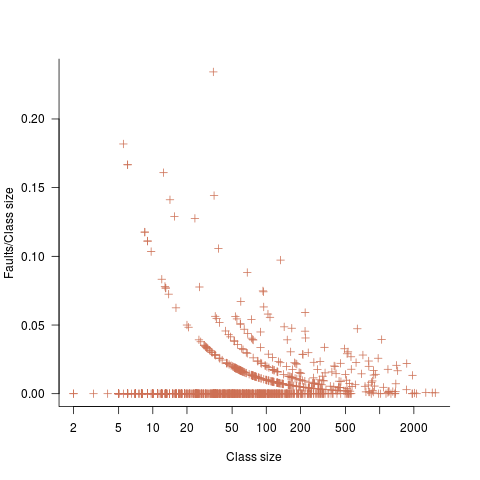
It’s tempting to think that those three curved lines are each classes containing the same number of methods.
What is the conclusion? There is one good reason why shorter functions should have more reported faults, and another good’ish reason why longer functions should have more reported faults. Perhaps length is not important. We need more data before an answer is possible.
Recent Comments