Archive
The aims of software engineering research
Physics researchers aim to explain the workings of the universe (technically they build models whose behavior mimics that of the universe we can measure), biologists the workings of biological systems, and psychologists the working of the human mind.
What are researchers in software engineering aiming to do?
Talking to academics, the answer is that they aim to do research that can be published in a high impact journal.
What do those involved in commercial software development think software engineering researchers should be aiming to achieve?
Most of the commercial developers I have asked have never thought about the subject; hardly surprising, they have plenty of other issues to think about.
Those who pay for software, rather than create it, want it to be cheaper and delivered faster.
Vendors are under some pressure to reduce costs and deliver sooner. But since its inception, software has been a sellers market, which means the customer pressure does not have the impact it has in other industries.
The very large organizations who pay lots of money for software for their own use (e.g., the U.S. Department of Defence) recognise that research into software production may well save them lots of money, and at one time interesting things were being discovered, but then funding got rerouted to people with an aversion to actual software engineering, i.e., academics.
Cheaper and faster will always be of interest, and will start to become a hot topic in software engineering research once software starts to becoming a buyers market.
Maintaining existing systems continues its growth to dominating what nearly every software developer does. Dependencies on the rest of the software world (e.g., libraries and compilers) is starting to consume a large percentage of maintenance costs. Managers want to know which packages are likely to have a long and stable lifetime, and which are likely to be short-lived. An understanding of the evolution of software ecosystems is a pressing need. This is really cheaper and faster over the long term.
Cheaper and faster (short term for development, long term for maintenance) covers everything.
It’s tempting to list personnel selection, i.e., who is likely to make the best software developer. But why should the process of selecting software developers be any different from the processes used to select people to become doctors, lawyers and other professions? I’m sure that those involved in the various professions would like a magic wand that points to the appropriate people (for some definition of appropriate), this magic wand is no more likely to exist for software developers than any other profession.
What do you think the aims of software engineering research should be?
Time-to-fix when mistake discovered in a later project phase
Traditionally the management of software development projects divides them into phases, e.g., requirements, design, coding and testing. A mistake introduced in one phase may not be detected until a later phase. There is long-standing folklore that earlier mistakes detected in later phases are much much more costly to fix persists, despite the original source of this folklore being resoundingly debunked. Fixing a mistake later is likely to a bit more costly, but how much more costly? A lack of data prevents reliable analysis; this question also suffers from different projects having different cost-to-fix profiles.
This post addresses the time-to-fix question (cost involves all the resources needed to perform the fix). Does it take longer to correct mistakes when they are detected in phases that come after the one in which they were made?
The data comes from the paper: Composing Effective Software Security Assurance Workflows. The 35,367 (yes, thirty-five thousand) logged fixes, from 39 projects drawn from three organizations, contains information on: phases in which the mistake was made and fixed, time taken, person ID, project ID, date/time, plus other stuff 🙂
Every project has its own characteristics that affect time-to-fix. Project 615, avionics software developed by organization A, has the most fixes (7,503) and is analysed here.
Avionics software is safety critical, and each major phase included its own review and inspection. The major phases include: requirements gathering, requirements analysis, high level design, design, coding, and testing. When counting the number of phases between introduction/fix, should review and inspection each count as a phase?
The primary reason for doing a review and inspection is to check the correctness (i.e., lack of mistakes) in the corresponding phase. If there is a time-to-fix penalty for mistakes found in these symbiotic-phases, I suspect it will be different from the time-to-fix penalty between major phases (which for simplicity, I’m assuming is major-phase independent).
The time-to-fix has a resolution of 1-minute, and some fix times are listed as taking a minute; 72% of fixes are recorded as taking less than 10-minutes. What kind of mistakes require less than 10-minutes to fix? Typos and other minutiae.
The plot below shows time-to-fix for mistakes having a given ‘distance’ between introduction/fix phase, for fixes taking at least 1, 5 and 10-minutes (code+data):
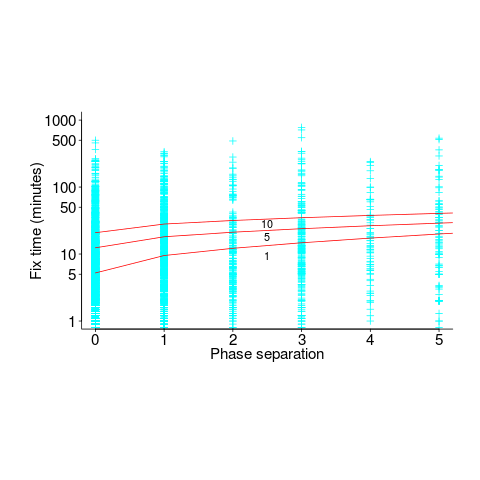
There is a huge variation in time-to-fix, and the regression lines (which have the form:  ) explains just 6% of the variance in the data, i.e., there is a small increase with phase separation, but it is almost down in the noise.
) explains just 6% of the variance in the data, i.e., there is a small increase with phase separation, but it is almost down in the noise.
All but one of the 38 people who worked on the project made multiple fixes (30 made more than 20 fixes), and may have got faster with practice. Adding the number of previous fixes by people making more than 20 fixes to the model gives:  , and improves the model by less than 1-percent.
, and improves the model by less than 1-percent.
Fixing mistakes is a human activity, and individual performance often has a big impact on fitted models. Adding person ID to the model as a multiplication factor: i.e.,  , improves the variance explained to 14% (better than a poke in the eye, just). The fitted value of
, improves the variance explained to 14% (better than a poke in the eye, just). The fitted value of  varies between 0.66 and 1.4 (factor of two, human variation).
varies between 0.66 and 1.4 (factor of two, human variation).
The answer to the time-to-fix question posed earlier (for project 615), is that it does take slightly longer to fix a mistake detected in phases occurring after the one in which the mistake was introduced. The phase difference is tiny, with differences in human performance having a bigger impact.
Quality control in a zero cost of replication business
When a new manufacturing material becomes available, its use is often integrated with existing techniques, e.g., using scientific management techniques for software production.
Customers want reliable products, and companies that sell unreliable products don’t make money (and may even lose lots of money).
Quality assurance of manufactured products is a huge subject, and lots of techniques have been developed.
Needless to say, quality assurance techniques applied to the production of hardware are often touted (and sometimes applied) as the solution for improving the quality of software products (whatever quality is currently being defined as).
There is a fundamental difference between the production of hardware and software:
- Hardware is designed, a prototype made and this prototype refined until it is ready to go into production. Hardware production involves duplicating an existing product. The purpose of quality control for hardware production is ensuring that the created copies are close enough to identical to the original that they can be profitably sold. Industrial design has to take into account the practicalities of mass production, e.g., can this device be made at a low enough cost.
- Software involves the same design, prototype, refinement steps, in some form or another. However, the final product can be perfectly replicated at almost zero cost, e.g., downloadable file(s), burn a DVD, etc.
Software production is a once-off process, and applying techniques designed to ensure the consistency of a repetitive process don’t sound like a good idea. Software production is not at all like mass production (the build process comes closest to this form of production).
Sometimes people claim that software development does involve repetition, in that a tiny percentage of the possible source code constructs are used most of the time. The same is also true of human communications, in that a few words are used most of the time. Does the frequent use of a small number of words make speaking/writing a repetitive process in the way that manufacturing identical widgets is repetitive?
The virtually zero cost of replication (and distribution, via the internet, for many companies) does more than remove a major phase of the traditional manufacturing process. Zero cost of replication has a huge impact on the economics of quality control (assuming high quality is considered to be equivalent to high reliability, as measured by number of faults experienced by customers). In many markets it is commercially viable to ship software products that are believed to contain many mistakes, because the cost of fixing them is so very low; unlike the cost of hardware, which is non-trivial and involves shipping costs (if only for a replacement).
Zero defects is not an economically viable mantra for many software companies. When companies employ people to build the same set of items, day in day out, there is economic sense in having them meet together (e.g., quality circles) to discuss saving the company money, by reducing production defects.
Many software products have a short lifespan, source code has a brief and lonely existence, and many development projects are never shipped to paying customers.
In software development companies it makes economic sense for quality circles to discuss the minimum number of known problems they need to fix, before shipping a product.
Extreme value theory in software engineering
As its name suggests, extreme value theory deals with extreme deviations from the average, e.g., how often will rainfall be heavy enough to cause a river to overflow its banks.
The initial list of statistical topics I thought ought to be covered in my evidence-based software engineering book included extreme value theory. At the time, and even today, there were/are no books covering “Statistics for software engineering”, so I had no prior work to guide my selection of topics. I was keen to cover all the important topics, had heard of it in several (non-software) contexts and jumped to the conclusion that it must be applicable to software engineering.
Years pass: the draft accumulate a wide variety of analysis techniques applied to software engineering data, but, no use of extreme value theory.
Something else does not happen: I don’t find any ‘Using extreme value theory to analyse data’ books. Yes, there are some really heavy-duty maths books available, but nothing of a practical persuasion.
The book’s Extreme value section becomes a subsection, then a subsubsection, and ended up inside a comment (I cannot bring myself to delete it).
It appears that extreme value theory is more talked about than used. I can understand why. Extreme events are newsworthy; rivers that don’t overflow their banks are not news.
Just over a month ago a discussion cropped up on the UK’s C++ standards’ panel mailing list: was email traffic down because of COVID-19? The panel’s convenor, Roger Orr, posted some data on monthly volumes. Oh, data 🙂
Monthly data is a bit too granular for detailed analysis over relatively short periods. After some poking around Roger was able to send me the date&time of every post to the WG21‘s Core and Lib reflectors, since February 2016 (there have been various changes of hosts and configurations over the years, and date of posts since 2016 was straightforward to obtain).
During our email exchanges, Roger had mentioned that every now and again a huge discussion thread comes out of nowhere. Woah, sounds like WG21 could do with some extreme value theory. How often are huge discussion threads likely to occur, and how huge is a once in 10-years thread that they might have to deal with?
There are two techniques for analysing the distribution of extreme values present in a sample (both based around the generalized extreme value distribution):
- Generalized Extreme Value (GEV) uses block maxima, e.g., maximum number of daily emails sent in each month,
- Generalized Pareto (GP) uses peak over threshold: pick a threshold and extract day values for when more than this threshold number of emails was sent.
The plots below show the maximum number of monthly emails that are expected to occur (y-axis) within a given number of months (x-axis), for WG21’s Core and Lib email lists. The circles are actual occurrences, and dashed lines 95% confidence intervals; GEV was used for these fits (code+data):
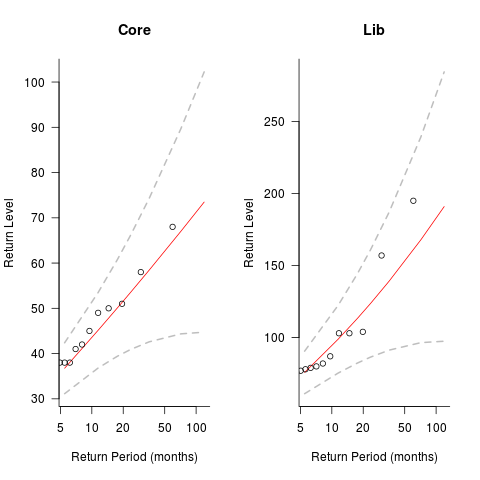
The 10-year return value for Core is around a daily maximum of 70 +-30, and closer to 200 +-100 for Lib.
The model used is very simplistic, and fails to take into account the growth in members joining these lists and traffic lost when a new mailing list is created for a new committee subgroup.
If any readers have suggests for uses of extreme value theory in software engineering, please let me know.
Postlude. This discussion has reordered events. My original interest in the mailing list data was the desire to find some evidence for the hypothesis that the volume of email increased as the date of the next WG21 meeting approached. For both Core and Lib, the volume actually decreases slightly as the date of the next meeting approaches; see code for details. Also, the volume of email at the weekend is around 60% lower than during weekdays.
Scientific management of software production
When Frederick Taylor investigated the performance of workers in various industries, at the start of the 1900’s, he found that workers organise their work to suit themselves; workers were capable of producing significantly more than they routinely produced. This was hardly news. What made Taylor’s work different was that having discovered the huge difference between actual worker output and what he calculated could be achieved in practice, he was able to change work practices to achieve close to what he had calculated to be possible. Changing work practices took several years, and the workers did everything they could to resist it (Taylor’s The principles of scientific management is an honest and revealing account of his struggles).
Significantly increasing worker output pushed company profits through the roof, and managers everywhere wanted a piece of the action; scientific management took off. Note: scientific management is not a science of work, it is a science of the management of other people’s work.
The scientific management approach has been successfully applied to production where most of the work can be reduced to purely manual activities (i.e., requiring little thinking by those who performed them). The essence of the approach is to break down tasks into the smallest number of component parts, to simplify these components so they can be performed by less skilled workers, and to rearrange tasks in a way that gives management control over the production process. Deskilling tasks increases the size of the pool of potential workers, decreasing labor costs and increasing the interchangeability of workers.
Given the almost universal use of this management technique, it is to be expected that managers will attempt to apply it to the production of software. The software factory was tried, but did not take-off. The use of chief programmer teams had its origins in the scarcity of skilled staff; the idea is that somebody who knows what they were doing divides up the work into chunks that can be implemented by less skilled staff. This approach is essentially the early stages of scientific management, but it did not gain traction (see “Programmers and Managers: The Routinization of Computer Programming in the United States” by Kraft).
The production of software is different in that once the first copy has been created, the cost of reproduction is virtually zero. The human effort invested in creating software systems is primarily cognitive. The division between management and workers is along the lines of what they think about, not between thinking and physical effort.
Software systems can be broken down into simpler components (assuming all the requirements are known), but can the implementation of these components be simplified such that they can be implemented by less skilled developers? The process of simplification is practical when designing a system for repetitive reproduction (e.g., making the same widget again and again), but the first implementation of anything is unlikely to be simple (and only one implementation is needed for software).
If it is not possible to break down the implementation such that most of the work is easy to do, can we at least hire the most productive developers?
How productive are different developers? Programmer productivity has been a hot topic since people started writing software, but almost no effective research has been done.
I have no idea how to measure programmer productivity, but I do have some ideas about how to measure their performance (a high performance programmer can have zero productivity by writing programs, faster than anybody else, that don’t do anything useful, from the client’s perspective).
When the same task is repeatedly performed by different people it is possible to obtain some measure of average/minimum/maximum individual performance.
Task performance improves with practice, and an individual’s initial task performance will depend on their prior experience. Measuring performance based on a single implementation of a task provides some indication of minimum performance. To obtain information on an individual’s maximum performance they need to be measured over multiple performances of the same task (and of course working in a team affects performance).
Should high performance programmers be paid more than low performance programmers (ignoring the issue of productivity)? I am in favour of doing this.
What about productivity payments, e.g., piece work?
This question is a minefield of issues. Manual workers have been repeatedly found to set informal quotas amongst themselves, i.e., setting a maximum on the amount they will produce during a shift (see “Money and Motivation: An Analysis of Incentives in Industry” by William Whyte). Thankfully, I don’t think I will be in a position to have to address this issue anytime soon (i.e., I don’t see a reliable measure of programmer productivity being discovered in the foreseeable future).
Recent Comments