Archive
Source code chapter of ‘evidence-based software engineering’ reworked
The Source code chapter of my evidence-based software engineering book has been reworked (draft pdf).
When writing the first version of this chapter, I was not certain whether source code was a topic warranting a chapter to itself, in an evidence-based software engineering book. Now I am certain. Source code is the primary product delivery, for a software system, and it is takes up much of the available cognitive effort.
What are the desirable characteristics that source code should have, to minimise production costs per unit of functionality? This is what an evidence-based chapter on source code is all about.
The release of this chapter completes my second pass over the material. Readers will notice the text still contains ... and ?‘s. The third pass will either delete these, or say something interesting (I suspect mostly the former, because of lack of data).
Talking of data, February has been a bumper month for data (apologies if you responded to my email asking for data, and it has not appeared in this release; a higher than average number of people have replied with data).
The plan is to spend a few months getting a beta release ready. Have the beta release run over the summer, with the book in the shops for Christmas.
I’m looking at getting a few hundred printed, for those wanting paper.
The only publisher that did not mind me making the pdf freely available was MIT Press. Unfortunately one of the reviewers was foaming at the mouth about the things I had to say about software engineering researcher (it did not help that I had written a blog post containing a less than glowing commentary on academic researchers, the week of the review {mid-2017}); the second reviewer was mildly against, and the third recommended it.
If any readers knows the editors at MIT Press, do suggest they have another look at the book. I would rather a real publisher make paper available.
Next, getting the ‘statistics for software engineers’ second half of the book ready for a beta release.
The wisdom of the ancients
The software engineering ancients are people like Halstead and McCabe, along with less well known ancients (because they don’t name anything after them) such as Boehm for cost estimation, Lehman for software evolution, and Brooks because of a book; these ancients date from before 1980.
Why is the wisdom of these ancients still venerated (i.e., people treat them as being true), despite the evidence that they are very inaccurate (apart from Brooks)?
People hate a belief vacuum, they want to believe things.
The correlation between Halstead’s and McCabe’s metrics, and various software characteristics is no better than counting lines of code, but using a fancy formula feels more sophisticated and everybody else uses them, and we don’t have anything more accurate.
That last point is the killer, in many (most?) cases we don’t have any metrics that perform better than counting lines of code (other than taking the log of the number of lines of code).
Something similar happened in astronomy. Placing the Earth at the center of the solar system results in inaccurate predictions of where the planets are going to be in the sky; adding epicycles to the model helps to reduce the error. Until Newton came along with a model that produced very accurate results, people stuck with what they knew.
The continued visibility of COCOMO is a good example of how academic advertising (i.e., publishing papers) can keep an idea alive. Despite being more sophisticated, the Putnam model is not nearly as well known; Putnam formed a consulting company to promote this model, and so advertised to a different market.
Both COCOMO and Putnam have lines of code as an integral component of their models, and there is huge variability in the number of lines written by different people to implement the same functionality.
People tend not to talk about Lehman’s quantitative work on software evolution (tiny data set, and the fitted equation is very different from what is seen today). However, Lehman stated enough laws, and changed them often enough, that it’s possible to find something in there that relates to today’s view of software evolution.
Brooks’ book “The Mythical Man-Month” deals with project progress and manpower; what he says is timeless. The problem is that while lots of people seem happy to cite him, very few people seem to have read the book (which is a shame).
There is a book coming out this year that provides lots of evidence that the ancient wisdom is wrong or at best harmless, but it does not contain more accurate models to replace what currently exists 🙁
Patterns of regular expression usage: duplicate regexs
Regular expressions are widely used, but until recently they were rarely studied empirically (i.e., just theory research).
This week I discovered two groups studying regular expression usage in source code. The VTSBULeeLab has various papers analysing 500K distinct regular expressions, from programs written in eight languages and StackOverflow; Carl Chapman and Peipei Wang have been looking at testing of regular expressions, and also ran an interesting experiment (I will write about this when I have decoded the data).
Regular expressions are interesting, in that their use is likely to be purely driven by an application requirement; the use of an integer literals may be driven by internal housekeeping requirements. The number of times the same regular expression appears in source code provides an insight (I claim) into the number of times different programs are having to solve the same application problem.
The data made available by the VTSBULeeLab group provides lots of information about each distinct regular expression, but not a count of occurrences in source. My email request for count data received a reply from James Davis within the hour 🙂
The plot below (code+data; crates.io has not been included because the number of regexs extracted is much smaller than the other repos) shows the number of unique patterns (y-axis) against the number of identical occurrences of each unique pattern (x-axis), e.g., far left shows number of distinct patterns that occurred once, then the number of distinct patterns that each occur twice, etc; colors show the repositories (language) from which the source was obtained (to extract the regexs), and lines are fitted regression models of the form:  , where:
, where:  is driven by the total amount of source processed and the frequency of occurrence of regexs in source, and
is driven by the total amount of source processed and the frequency of occurrence of regexs in source, and  is the rate at which duplicates occur.
is the rate at which duplicates occur.
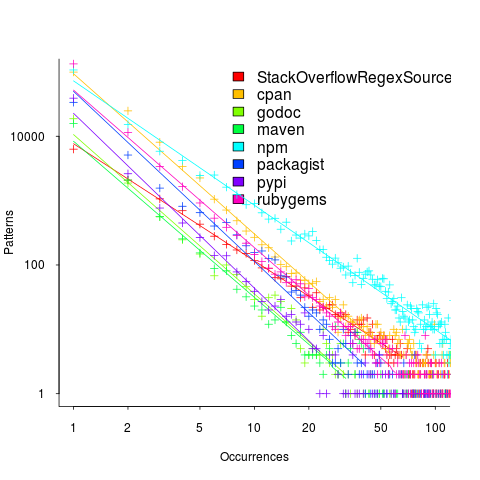
So most patterns occur once, and a few patterns occur lots of times (there is a long tail off to the unplotted right).
The following table shows values of for the various repositories (languages):
StackOverflow cpan godoc maven npm packagist pypi rubygems
-1.8 -2.5 -2.5 -2.4 -1.9 -2.6 -2.7 -2.4 |
The lower (i.e., closer to zero) the value of , the more often the same regex will appear.
The values are in the region of -2.5, with two exceptions; why might StackOverflow and npm be different? I can imagine lots of duplicates on StackOverflow, but npm (I’m not really familiar with this package ecosystem).
I am pleased to see such good regression fits, and close power law exponents (I would have been happy with an exponential fit, or any other equation; I am interested in a consistent pattern across languages, not the pattern itself).
Some of the code is likely to be cloned, i.e., cut-and-pasted from a function in another package/program. Copy rates as high as 70% have been found. In this case, I don’t think cloned code matters. If a particular regex is needed, what difference does it make whether the code was cloned or written from scratch?
If the same regex appears in source because of the same application requirement, the number of reuses should be correlated across languages (unless different languages are being used to solve different kinds of problems). The plot below shows the correlation between number of occurrences of distinct regexs, for each pair of languages (or rather repos for particular languages; top left is StackOverflow).

Why is there a mix of strong and weakly correlated pairs? Is it because similar application problems tend to be solved using different languages? Or perhaps there are different habits for cut-and-pasted source for developers using different repositories (which will cause some patterns to occur more often, but not others, and have an impact on correlation but not the regression fit).
There are a lot of other interesting things that can be done with this data, when connected to the results of the analysis of distinct regexs, but these look like hard work, and I have a book to finish.
Source code has a brief and lonely existence
The majority of source code has a short lifespan (i.e., a few years), and is only ever modified by one person (i.e., 60%).
Literate programming is all well and good for code written to appear in a book that the author hopes will be read for many years, but this is a tiny sliver of the source code ecosystem. The majority of code is never modified, once written, and does not hang around for very long; an investment is source code futures will make a loss unless the returns are spectacular.
What evidence do I have for these claims?
There is lots of evidence for the code having a short lifespan, and not so much for the number of people modifying it (and none for the number of people reading it).
The lifespan evidence is derived from data in my evidence-based software engineering book, and blog posts on software system lifespans, and survival times of Linux distributions. Lifespan in short because Packages are updated, and third-parties change/delete APIs (things may settle down in the future).
People who think source code has a long lifespan are suffering from survivorship bias, i.e., there are a small percentage of programs that are actively used for many years.
Around 60% of functions are only ever modified by one author; based on a study of the change history of functions in Evolution (114,485 changes to functions over 10 years), and Apache (14,072 changes over 12 years); a study investigating the number of people modifying files in Eclipse. Pointers to other studies that have welcome.
One consequence of the short life expectancy of source code is that, any investment made with the expectation of saving on future maintenance costs needs to return many multiples of the original investment. When many programs don’t live long enough to be maintained, those with a long lifespan have to pay the original investments made in all the source that quickly disappeared.
One benefit of short life expectancy is that most coding mistakes don’t live long enough to trigger a fault experience; the code containing the mistake is deleted or replaced before anybody notices the mistake.
Update: a few days later
I was remiss in not posting some plots for people to look at (code+data).
The plot below shows number of function, in Evolution, modified a given number of times (left), and functions modified by a given number of authors (right). The lines are a bi-exponential fit.

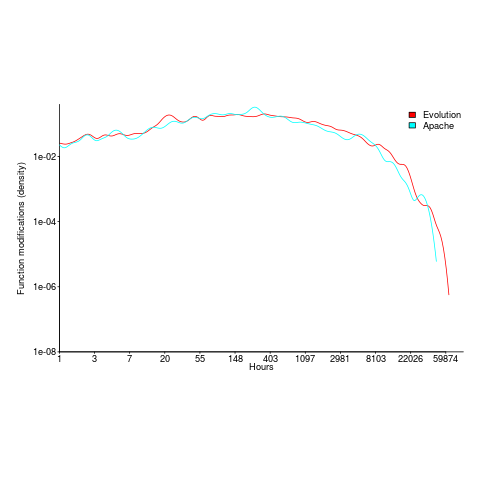
What is the interval (in hours) between between modifications of a function? The plot below has a logarithmic x-axis, and is sort-of flat over most of the range (you need to squint a bit). This is roughly saying that the probability of modification in hours 1-3 is the same as in hours 3-7, and hours, 7-15, etc (i.e., keep doubling the hour interval). At round 10,000 hours function modification probability drops like a stone.
Recent Comments