Archive
Projects chapter of ‘evidence-based software engineering’ reworked
The Projects chapter of my evidence-based software engineering book has been reworked; draft pdf available here.
A lot of developers spend their time working on projects, and there ought to be loads of data available. But, as we all know, few companies measure anything, and fewer hang on to the data.
Every now and again I actively contact companies asking data, but work on the book prevents me spending more time doing this. Data is out there, it’s a matter of asking the right people.
There is enough evidence in this chapter to slice-and-dice much of the nonsense that passes for software project wisdom. The problem is, there is no evidence to suggest what might be useful and effective theories of software development. My experience is that there is no point in debunking folktales unless there is something available to replace them. Nature abhors a vacuum; a debunked theory has to be replaced by something else, otherwise people continue with their existing beliefs.
There is still some polishing to be done, and a few promises of data need to be chased-up.
As always, if you know of any interesting software engineering data, please tell me.
Next, the Reliability chapter.
Three books discuss three small data sets
During the early years of a new field, experimental data relating to important topics can be very thin on the ground. Ever since the first computer was built, there has been a lot of data on the characteristics of the hardware. Data on the characteristics of software, and the people who write it, has been (and often continues to be) very thin on the ground.
Books are sometimes written by the researchers who produce the first data associated with an important topic, even if the data set is tiny; being first often generates enough interest for a book length treatment to be considered worthwhile.
As a field progresses lots more data becomes available, and the discussion in subsequent books can be based on findings from more experiments and lots more data
Software engineering is a field where a few ‘first’ data books have been published, followed by silence, or rather lots of arm waving and little new data. The fall of Rome has been followed by a 40-year dark-age, from which we are slowly emerging.
Three of these ‘first’ data books are:
- “Man-Computer Problem Solving” by Harold Sackman, published in 1970, relating to experimental data from 1966. The experiments investigated the impact of two different approaches to developing software, on programmer performance (i.e., batch processing vs. on-line development; code+data). The first paper on this work appeared in an obscure journal in 1967, and was followed in the same issue by a critique pointing out the wide margin of uncertainty in the measurements (the critique agreed that running such experiments was a laudable goal).
Failing to deal with experimental uncertainty is nothing compared to what happened next. A 1968 paper in a widely read journal, the Communications of the ACM, contained the following table (extracted from a higher quality scan of a 1966 report by the same authors, and available online).
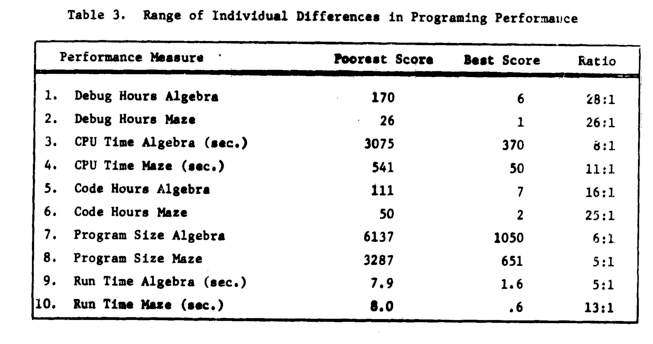
The tale of 1:28 ratio of programmer performance, found in an experiment by Grant/Sackman, took off (the technical detail that a lot of the difference was down to the techniques subjects’ used, and not the people themselves, got lost). The Grant/Sackman ‘finding’ used to be frequently quoted in some circles (or at least it did when I moved in them, I don’t know often it is cited today). In 1999, Lutz Prechelt wrote an expose on the sorry tale.
Sackman’s book is very readable, and contains lots of details and data not present in the papers, including survey data and a discussion of the intrinsic uncertainties associated with the experiment; it also contains the table above.
- “Software Engineering Economics” by Barry W. Boehm, published in 1981. I wrote about the poor analysis of the data contained in this book a few years ago.
The rest of this book contains plenty of interesting material, and even sounds modern (because books moving the topic forward have not been written).
- “Program Evolution: Process of Software Change” edited by M. M. Lehman and L. A. Belady, published in 1985, relating to experimental data from 1977 and before. Lehman and Belady managed to obtain data relating to 19 releases of an IBM software product (yes, 19, not nineteen-thousand); the data was primarily the date and number of modules contained in each release, plus less specific information about number of statements. This data was sliced and diced every which way, and the book contains many papers with the same data appearing in the same plot with different captions (had the book not been a collection of papers it would have been considerably shorter).
With a lot less data than Isaac Newton had available to formulate his three laws, Lehman and Belady came up with five, six, seven… “laws of software evolution” (which themselves evolved with the publication of successive papers).
The availability of Open source repositories means there is now a lot more software system evolution data available. Lehman’s laws have not stood the test of more data, although people still cite them every now and again.
Comparing expression usage in mathematics and C source
Why does a particular expression appear in source code?
One reason is that the expression is the coded form of a formula from the application domain, e.g.,  .
.
Another reason is that the expression calculates an algorithm/housekeeping related address, or offset, to where a value of interest is held.
Most people (including me, many years ago) think that the majority of source code expressions relate to the application domain, in one-way or another.
Work on a compiler related optimizer, and you will soon learn the truth; most expressions are simple and calculate addresses/offsets. Optimizing compilers would not have much to do, if they only relied on expressions from the application domain (my numbers tool throws something up every now and again).
What are the characteristics of application domain expression?
I like to think of them as being complicated, but that’s because it used to be in my interest for them to be complicated (I used to work on optimizers, which have the potential to make big savings if things are complicated).
Measurements of expressions in scientific papers is needed, but who is going to be interested in measuring the characteristics of mathematical expressions appearing in papers? I’m interested, but not enough to do the work. Then, a few weeks ago I discovered: An Analysis of Mathematical Expressions Used in Practice, by Clare So; an analysis of 20,000 mathematical papers submitted to arXiv between 2000 and 2004.
The following discussion uses the measurements made for my C book, as the representative source code (I keep suggesting that detailed measurements of other languages is needed, but nobody has jumped in and made them, yet).
The table below shows percentage occurrence of operators in expressions. Minus is much more common than plus in mathematical expressions, the opposite of C source; the ‘popularity’ of the relational operators is also reversed.
Operator Mathematics C source = 0.39 3.08 - 0.35 0.19 + 0.24 0.38 <= 0.06 0.04 > 0.041 0.11 < 0.037 0.22 |
The most common single binary operator expression in mathematics is n-1 (the data counts expressions using different variable names as different expressions; yes, n is the most popular variable name, and adding up other uses does not change relative frequency by much). In C source var+int_constant is around twice as common as var-int_constant
The plot below shows the percentage of expressions containing a given number of operators (I’ve made a big assumption about exactly what Clare So is counting; code+data). The operator count starts at two because that is where the count starts for the mathematics data. In C source, around 99% of expressions have less than two operators, so the simple case completely dominates.
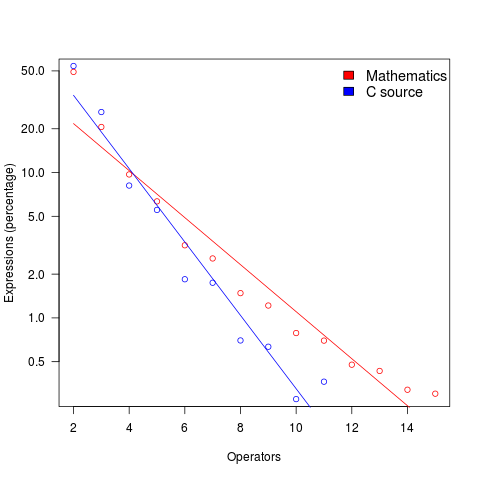
For expressions containing between two and five operators, frequency of occurrence is sort of about the same in mathematics and C, with C frequency decreasing more rapidly. The data disagrees with me again…
Cost ratio for bespoke hardware+software
What percentage of the budget for a bespoke hardware/software system is spent on software, compared to hardware?
The plot below has become synonymous with this question (without the red line, which highlights 1973), and is often used to claim that software costs are many times more than hardware costs.

The paper containing this plot was published in 1973 (the original source is a Rome period report), and is an extrapolation of data I assume was available in 1973, into what was then the future. The software and hardware costs are for bespoke command and control systems delivered to the U.S. Air Force, not commercial off-the-shelf solutions or even bespoke commercial systems.
Does bespoke software cost many times more than the hardware it runs on?
I don’t have any data that might be used to answer this questions, to any worthwhile degree of accuracy. I know of situations where I believe the bespoke software did cost a lot more than the hardware, and I know of some where the hardware cost more (I have never been privy to exact numbers on large projects).
Where did the pre-1973 data come from?
The USAF funded the creation of lots of source code, and the reports cite hardware and software figures from 1972.
To summarise: the above plot is for USAF spending on bespoke command and control hardware and software, and is extrapolated from 1973 into the future.
Recent Comments