Archive
The 520’th post
This is the 520’th post on this blog, which will be 10-years old tomorrow. Regular readers may have noticed an increase in the rate of posting over the last few months; at the start of this month I needed to write 10 posts to hit my one-post a week target (which has depleted the list of things I keep meaning to write about).
What has happened in the last 10-years?
- I no longer visit libraries, which are becoming coffee shops+wifi hot-spots where people who have librarian in their job title, hot desk; books, they are around here somewhere. I used to regularly visit libraries, particularly while working on my C book. No libraries have so far needed to be visited, for the writing of my evidence-based software engineering book,
- many old manuals, reports, books and magazines became freely available for download, via sites like the Internet Archive, Bitsavers and the Defense Technical Information Center; for second hand books there is AbeBooks. Site like Research Gate, Semantic Scholar and Google Scholar are fantastic sources for more recent work; for new books there is Amazon,
- Github became the place to make source code+stuff available,
- researchers in software engineering started to become interested in evidence-based research. In the UK the CREST Open Workshops were a fantastic series of events; I went to about a third of them, and there were often a couple of gold nuggets per event (a change of funding means running future events will require a lot more work),
- smart phones became the last, next, major software consumer ecosystem (capturing a large percentage of the world’s population means there is no room left for something bigger), and the cloud started on its path to being 99% of the commercial software ecosystem,
- Python joined the short-list to become the world’s primary programming language (assuming that people still run programs outside of the browser). The decline of PERL became very obvious, and work on adding new features to Cobol stopped (work on adding features to Fortran is still going strong),
- known faults are now being automatically fixed by modifying the source code (using genetic programming). This has yet to move out of research, but we all know where it’s going,
- whole program optimization of systems containing millions of lines of code became a viable option for commercial developers (a topic of late night discussion for compiler writers in the 1980s, and perhaps earlier decades, when having more than 64K of memory was treated as nirvana),
- after 20-years of being the only major open source compiler tool-chain, gcc got some serious competition. I originally predicted that llvm would disappear, failing to recognize that Apple were supporting it for licensing reasons,
- the death throes of Moore’s law went from subtle to, isn’t it dead yet?
I probably missed several major events hiding in plain sight, either because I am too close to them or blinkered.
What did not happen in the last 10 years?
- No major new languages. These require major new hardware ecosystems; in the smartphone market Android used Java and iOS made use of existing languages. There were the usual selection of fashion/vanity driven wannabes, e.g., Julia, Rust, and Go. The R language started to get noticed, but it has been around since 1995, and Python looks set to eventually kill it off,
- no accident killing 100+ people has been attributed to faults in software. Until this happens, software engineering has a dead bodies problem,
- the creation of new software did not slow down from its break-neck speed,
- in the first few years of this blog I used to make yearly predictions, which did not happen (most of the time).
Now I can relax for 9.5 years, before scurrying to complete 1,040 posts, i.e., the rate of posting will now resume its previous, more sedate, pace.
Half-life of software as a service, services
How is software used to provide a service (e.g., the software behind gmail) different from software used to create a product (e.g., sold as something that can be installed)?
This post focuses on one aspect of the question, software lifetime.
The Killed by Google website lists Google services and products that are no more. Cody Ogden, the creator of the site, has open sourced the code of the website; there are product start/end dates!
After removing 20 hardware products from the list, we are left with 134 software services. Some of the software behind these services came from companies acquired by Google, so the software may have been used to provide a service pre-acquisition, i.e., some calculated lifetimes are underestimates.
The plot below shows the number of Google software services (blue) having a given lifetime (calculated as days between Google starting/withdrawing service), mainframe software from the 1990s (red; only available at yearly resolution), along with fitted exponential regression lines (code+data):
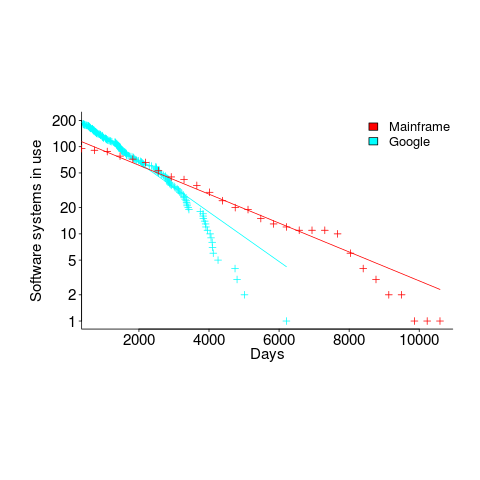
Overall, an exponential is a good fit (squinting to ignore the dozen red points), although product culling is not exponentially ruthless at short lifetimes (newly launched products are given a chance to prove themselves).
The Google service software half-life is 1,500 days, about 4.1 years (assuming the error/uncertainty is additive, if it is multiplicative {i.e., a percentage} the half-life is 1,300 days); the half-life of mainframe software is 2,600 days (with the same assumption about the kind of error/uncertainty).
One explanation of the difference is market maturity. Mainframe software has been evolving since the 1950s and probably turned over at the kind of rate we saw a few years ago with Internet services. By the 1990s things had settled down a bit in the mainframe world. Will software-based services on the Internet settle down faster than mainframe software? Who knows.
Based on this Google data, the cost/benefit ratio when deciding whether to invest in reducing future software maintenance costs, is going to have to be significantly better than the ratio calculated for mainframe software.
Software system lifetime data is extremely hard to find (this is only the second set I have found). Any pointers to other lifetime data very welcome, e.g., a collection of Microsoft product start/end dates 🙂
Ecosystems as major drivers of software development
During the age of the Algorithm, developers wrote most of the code in their programs. In the age of the Ecosystem, developers make extensive use of code supplied by third-parties.
Software ecosystems are one of the primary drivers of software development.
The early computers were essentially sold as bare metal, with the customer having to write all the software. Having to write all the software was expensive, time-consuming, and created a barrier to more companies using computers (i.e., it was limiting sales). The amount of software that came bundled with a new computer grew over time; the following plot (code+data) shows the amount of code (thousands of instructions) bundled with various IBM computers up to 1968 (an antitrust case eventually prevented IBM bundling software with its computers):
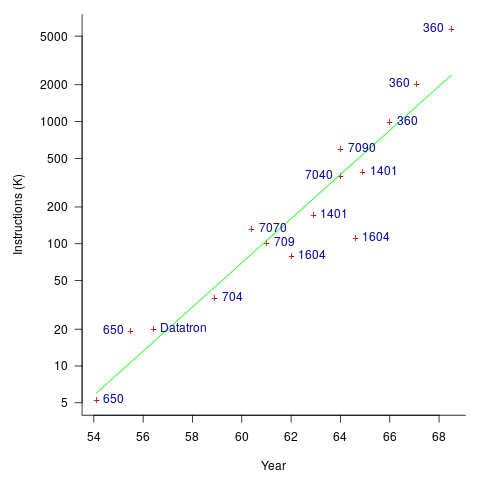
Some tasks performed using computers are common to many computer users, and users soon started to meet together, to share experiences and software. SHARE, founded in 1955, was the first computer user group.
SHARE was one of several nascent ecosystems that formed at the start of the software age, another is the Association for Computing Machinery; a great source of information about the ecosystems existing at the time is COMPUTERS and AUTOMATION.
Until the introduction of the IBM System/360, manufacturers introduced new ranges of computers that were incompatible with their previous range, i.e., existing software did not work.
Compatibility with existing code became a major issue. What had gone before started to have a strong influence on what was commercially viable to do next. Software cultures had come into being and distinct ecosystems were springing up.
A platform is an ecosystem which is primarily controlled by one vendor; Microsoft Windows is the poster child for software ecosystems. Over the years, Microsoft has added more and more functionality to Windows, and I don’t know enough to suggest the date when substantial Windows programs substantially depended on third-party code; certainly small apps may be mostly Windows code. The Windows GUI certainly ties developers very closely to a Windows way of doing things (I have had many people tell me that porting to a non-Windows GUI was a lot of work, but then this statement seems to be generally true of porting between different GUIs).
Does Facebook’s support for the writing of simple apps make it a platform? Bill Gates thought not: “A platform is when the economic value of everybody that uses it, exceeds the value of the company that creates it.”, which some have called the Gates line.
The rise of open source has made it viable for substantial language ecosystems to flower, or rather substantial package ecosystems, with each based around a particular language. For practical purposes, language choice is now about the quality and quantity of their ecosystem. The dedicated followers of fashion like to tell everybody about the wonders of Go or Rust (in fashion when I wrote this post), but without a substantial package ecosystem, no language stands a chance of being widely used over the long term.
Major new software ecosystems have been created on a regular basis (regular, as in several per decade), e.g., mainframes in the 1960s, minicomputers and workstation in the 1970s, microcomputers in the 1980s, the Internet in the 1990s, smartphones in the 2000s, the cloud in the 2010s.
Will a major new software ecosystem come into being in the future? Major software ecosystems tend to be hardware driven; is hardware development now basically done, or should we expect something major to come along? A major hardware change requires a major new market to conquer. The smartphone has conquered a large percentage of the world’s population; there is no larger market left to conquer. Now, it’s about filling in the gaps, i.e., lots of niche markets that are still waiting to be exploited.
Software ecosystems are created through lots of people working together, over many years, e.g., the huge number of quality Python packages. Perhaps somebody will emerge who has the skills and charisma needed to get many developers to build a new ecosystem.
Software ecosystems can disappear; I think this may be happening with Perl.
Can a date be put on the start of the age of the Ecosystem? Ideas for defining the start of the age of the Ecosystem include:
- requiring a huge effort to port programs from one ecosystem to another. It used to be very difficult to port between ecosystems because they were so different (it has always been in vendors’ interests to support unique functionality). Using this method gives an early start date,
- by the amount of code/functionality in a program derived from third-party packages. In 2018, it’s certainly possible to write a relatively short Python program containing a huge amount of functionality, all thanks to third-party packages. Was this true for any ecosystems in the 1980s, 1990s?
Polished statistical analysis chapters in evidence-based software engineering
I have completed the polishing/correcting/fiddling of the eight statistical analysis related chapters of my evidence-based software engineering book, and an updated draft pdf is now available (download here).
The material was in much better shape than I recalled, after abandoning it to the world 2-years ago, to work on the software engineering chapters.
Changes include moving more figures into the margin (which is responsible for a lot of the reduction in page count), fixing grammatical typos, removing place-holders for statistical techniques that are unlikely to be of general interest to software engineers, and mostly minor shuffling around (the only big change was moving a lot of material from the Experiments chapter to the Statistics chapter).
There is still some work to be done, in places (most notably the section on surveys).
What next? My collection of data waiting to be analysed has been piling up, so I will spend the next month reducing the backlog.
The six chapters covering the major areas of software engineering need to be polished and fleshed out, from their current bare-bones state. All being well, this time next year a beta release will be ready.
While working on the statistical material, I have been making monthly updates to the pdf+data available. If it makes sense to do this for the rest of the material, then it will happen. I’m not going to write a blog post every month; perhaps a post after what look like important milestones.
As always, if you know of any interesting software engineering data, please tell me.
Waiting for the funerals: culture in software engineering research
A while ago I changed my opinion about why software engineering academics very rarely got/get involved in empirical/experimental based research.
I used to think it was because commercial data was so hard to get hold of.
In practice commercial data does not seem to be that hard to get hold of. At least for academics in business schools, and I have not experienced problems gaining access to commercial data (but it is very hard finding a company willing to allow me to make an anonymised version of its data public). There are many evidence-based papers published using confidential data (i.e., data that cannot be made public).
I now think the reasons for non-evidence-based research are culture and preference for non-people based research.
In the academic world the software side of computing often has a strong association is mathematics departments (I know that in some universities it is in engineering). I have had several researchers tell me that it would raise eyebrows, if they started doing more people oriented research, because this kind of research is viewed as being the purview of other departments.
Software had its algorithm era, which is now long gone; but unfortunately, many academics still live in a world where the mindset of TEOCP holds sway.
Baffled looks are common, when I talk to software engineering academics. They are baffled by the idea that it is possible to run experiments in software engineering, and they are baffled by the idea of evidence-based theories. I am still struggling to understand the mindset that produces the arguments they make against the possibility of experiments and evidence being useful.
In the past I know that some researchers have had problems getting experiment-based papers published. Hopefully this problem is now in the past, given that empirical/experimental papers are becoming more common.
Max Planck, one of the founders of quantum mechanics, found that physicists trained in what we now call classical physics, were not willing to teach or adopt a quantum mechanics world view; Planck observed: “Science advances one funeral at a time”.
Some pair programming benefits may be mathematical artefacts
Many claims are made about the advantages of pair programming. The claim that the performance of pairs is better than the performance of individuals may actually be the result of the mathematical consequences of two people working together, rather than working independently (at least for some tasks).
Let’s say that individuals have to find a fault in code, and then fix it. Some people will find the fault and then its fix much more quickly than others. The data for the following analysis comes from the report Experimental results on software debugging (late Rome period), via Lutz Prechelt and shows the density of the time taken by each developer to find and fix a fault in a short Fortran program.
Fixing faults is different from many other development tasks in that if often requires a specific insight to spot the mistake; once found, the fixing task tends to be trivial.
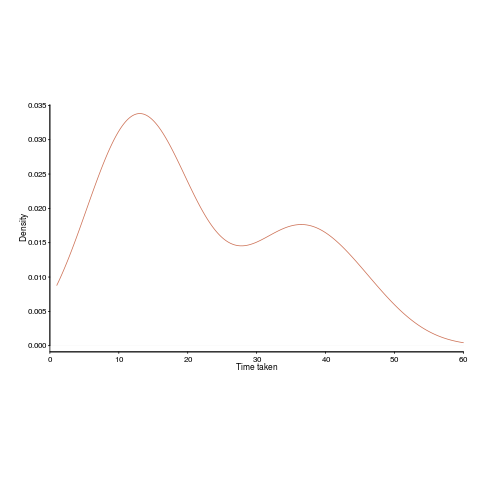
The mean time taken, for task t1, is 22.2 minutes (standard deviation 13).
How long might pairs of developers have taken to solve the same problem. We can take the existing data, create pairs, and estimate (based on individual developer time) how long the pair might take (code+data).
Averaging over every pair of 17 individuals would take too much compute time, so I used bootstrapping. Assuming the time taken by a pair was the shortest time taken by the two of them, when working individually, sampling without replacement produces a mean of 14.9 minutes (sd 1.4) (sampling with replacement is complicated…).
By switching to pairs we appear to have reduced the average time taken by 30%. However, the apparent saving is nothing more than the mathematical consequence of removing larger values from the sample.
The larger the variability of individuals, the larger the apparent saving from working in pairs.
When working as a pair, there will be some communication overhead (unless one is much faster and ignores the other developer), so the saving will be slightly less.
If the performance of a pair was the mean of their individual times, then pairing would not change the mean performance, compared to working alone. The performance of a pair has to be less than the mean of the performance of the two individuals, for pairs to show an improved performance.
There is an analytic solution for the distribution of the minimum of two values drawn from the same distribution. If ") is a probability density function and
is a probability density function and ") the corresponding cumulative distribution function, then the corresponding functions for the minimum of a pair of values drawn from this distribution is given by:
the corresponding cumulative distribution function, then the corresponding functions for the minimum of a pair of values drawn from this distribution is given by: =1-(1-F(x))^2") and
and =2f(x)(1-F(x))") .
.
The presence of two peaks in the above plot means the data is not going to be described by a single distribution. So, the above formula look interesting but are not useful (in this case).
When pairs of values are drawn from a Normal distribution, a rough calculation suggests that the mean is shifted down by approximately half the standard deviation.
Christmas books for 2018
The following are the really interesting books I read this year (only one of which was actually published in 2018, everything has to work its way through several piles). The list is short because I did not read many books and/or there is lots of nonsense out there.
The English and their history by Robert Tombs. A hefty paperback, at nearly 1,000 pages, it has been the book I read on train journeys, for most of this year. Full of insights, along with dull sections, a narrative that explains lots of goings-on in a straight-forward manner. I still have a few hundred pages left to go.
The mind is flat by Nick Chater. We experience the world through a few low bandwidth serial links and the brain stitches things together to make it appear that our cognitive hardware/software is a lot more sophisticated. Chater’s background is in cognitive psychology (these days he’s an academic more connected with the business world) and describes the experimental evidence to back up his “mind is flat” model. I found that some of the analogues dragged on too long.
In the readable social learning and evolution category there is: Darwin’s unfinished symphony by Leland and The secret of our success by Henrich. Flipping through them now, I cannot decide which is best. Read the reviews and pick one.
Group problem solving by Laughin. Eye opening. A slim volume, packed with data and analysis.
I have already written about Experimental Psychology by Woodworth.
The Digital Flood: The Diffusion of Information Technology Across the U.S., Europe, and Asia by Cortada. Something of a specialist topic, but if you are into the diffusion of technology, this is surely the definitive book on the diffusion of software systems (covers mostly hardware).
Is it worth attending an academic conference or workshop?
If you work in industry, is it worth attending an academic conference or workshop?
The following observations are based on my attending around 50 software engineering and compiler related conferences/workshops, plus discussion with a few other people from industry who have attended such events.
Short answer: No.
Slightly longer answer: Perhaps, if you are looking to hire somebody knowledgeable in a particular domain.
Much longer answer: Academics go to conferences to network. They are looking for future collaborators, funding, jobs, and general gossip. What is the point of talking to somebody from industry? Academics will make small talk and be generally friendly, but they don’t know how to interact, at the professional level, with people from industry.
Why are academics generally hopeless at interacting, at the professional level, with people from industry?
Part of the problem is lack of practice, many academic researchers live in a world that rarely intersects with people from industry.
Impostor syndrome is another. I have noticed that academics often think that people in industry have a much better understanding of the realities of their field. Those who have had more contact with people from industry might have noticed that impostor syndrome is not limited to academia.
Talking of impostor syndrome, and feeling of being a fraud, academics don’t seem to know how to handle direct criticism. Again I think it is a matter of practice. Industry does not operate according to: I won’t laugh at your idea, if you don’t laugh at mine, which means people within industry are practiced at ‘robust’ discussion (this does not mean they like it, and being good at handling such discussions smooths the path into management).
At the other end of the impostor spectrum, some academics really do regard people working in industry as simpletons. I regularly have academics express surprise that somebody in industry, i.e., me, knows about this-that-or-the-other. My standard reply is to say that its because I paid more for my degree and did not have the usual labotomy before graduating. Not a reply guaranteed to improve industry/academic relations, but I enjoy the look on their faces (and I don’t expect they express that opinion again to anyone else from industry).
The other reason why I don’t recommend attending academic conferences/workshops, is that lots of background knowledge is needed to understand what is being said. There is no point attending ‘cold’, you will not understand what is being presented (academic presentations tend to be much better organized than those given by people in industry, so don’t blame the speaker). Lots of reading is required. The point of attending is to talk to people, which means knowing something about the current state of research in their area of interest. Attending simply to learn something about a new topic is a very poor use of time (unless the purpose is to burnish your c.v.).
Why do I continue to attend conferences/workshops?
If a conference/workshop looks like it will be attended by people who I will find interesting, and it’s not too much hassle to attend, then I’m willing to go in search of gold nuggets. One gold nugget per day is a good return on investment.
Practical ecosystem books for software engineers
So you have read my (draft) book on evidence-based software engineering and want to learn more about ecosystems. What books do I suggest?
Biologists have been studying ecosystems for a long time, and more recently social scientists have been investigating cultural ecosystems. Many of the books written in these fields are oriented towards solving differential equations and are rather subject specific.
The study of software ecosystems has been something of a niche topic for a long time. Problems for researchers have included gaining access to ecosystems and the seeming proliferation of distinct ecosystems. The state of ecosystem research in software engineering is rudimentary; historians are starting to piece together what has happened.
Most software ecosystems are not even close to being in what might be considered a steady state. Eventually most software will be really old, and this will be considered normal (“Shock Of The Old: Technology and Global History since 1900” by Edgerton; newness is a marketing ploy to get people to buy stuff). In the meantime, I have concentrated on the study of ecosystems in a state of change.
Understanding ecosystems is about understanding how the interaction of participant’s motivation, evolves the environment in which they operate.
“Modern Principles of Economics” by Cowen and Tabarrok, is a very readable introduction to economics. Economics might be thought of as a study of the consequences of optimizing the motivation of maximizing return on investment. “Principles of Corporate Finance” by Brealey and Myers, focuses on the topic in its title.
“The Control Revolution: Technological and Economic Origins of the Information Society” by Beniger: the ecosystems in which software ecosystems coexist and their motivations.
“Evolutionary dynamics: exploring the equations of life” by Nowak, is a readable mathematical introduction to the subject given in the title.
“Mathematical Models of Social Evolution: A Guide for the Perplexed” by McElreath and Boyd, is another readable mathematical introduction, but focusing on social evolution.
“Social Learning: An Introduction to Mechanisms, Methods, and Models” by Hoppitt and Laland: developers learn from each other and from their own experience. What are the trade-offs for the viability of an ecosystem that preferentially contains people with specific ways of learning?
“Robustness and evolvability in living systems” by Wagner, survival analysis of systems built from components (DNA in this case). Rather specialised.
Books with a connection to technology ecosystems.
“Increasing returns and path dependence in the economy” by Arthur, is now a classic, containing all the basic ideas.
“The red queen among organizations” by Barnett, includes a chapter on computer manufacturers (has promised me data, but busy right now).
“Information Foraging Theory: Adaptive Interaction with Information” by Pirolli, is an application of ecosystem know-how, i.e., how best to find information within a given environment. Rather specialised.
“How Buildings Learn: What Happens After They’re Built” by Brand, yes building are changed just like software and the changes are just as messy and expensive.
Several good books have probably been omitted, because I failed to spot them sitting on the shelf. Suggestions for books covering topics I have missed welcome, or your own preferences.
Practical psychology books for software engineers
So you have read my (draft) book on evidence-based software engineering and want to learn more about human psychology. What books do I suggest?
I wrote a book about C that attempted to use results from cognitive psychology to understand developer characteristics. This work dates from around 2000, and some of my book choices may have been different, had I studied the subject 10 years later. Another consequence is that this list is very weak on social psychology.
I own all the following books, but it may have been a few years since I last took them off the shelf.
There are two very good books providing a broad introduction: “Cognitive psychology and its implications” by Anderson, and “Cognitive psychology: A student’s handbook” by Eysenck and Keane. They have both been through many editions, and buying a copy that is a few editions earlier than current, saves money for little loss of content.
“Engineering psychology and human performance” by Wickens and Hollands, is a general introduction oriented towards stuff that engineering requires people to do.
Brain functioning: “Reading in the brain” by Dehaene (a bit harder going than “The number sense”). For those who want to get down among the neurons “Biological psychology” by Kalat.
Consciouness: This issue always comes up, so let’s kill it here and now: “The illusion of conscious will” by Wegner, and “The mind is flat” by Chater.
Decision making: What is the difference between decision making and reasoning? In psychology those with a practical orientation study decision making, while those into mathematical logic study reasoning. “Rational choice in an uncertain world” by Hastie and Dawes, is a general introduction; “The adaptive decision maker” by Payne, Bettman and Johnson, is a readable discussion of decision making models. “Judgment under Uncertainty: Heuristics and Biases” by Kahneman, Slovic and Tversky, is a famous collection of papers that kick started the field at the start of the 1980s.
Evolutionary psychology: “Human evolutionary psychology” by Barrett, Dunbar and Lycett. How did we get to be the way we are? Watch out for the hand waving (bones can be dug up for study, but not the software of our mind), but it weaves a coherent’ish story. If you want to go deeper, “The Adapted Mind: Evolutionary Psychology and the Generation of Culture” by Barkow, Tooby and Cosmides, is a collection of papers that took the world by storm at the start of the 1990s.
Language: “The psychology of language” by Harley, is the book to read on psycholinguistics; it is engrossing (although I have not read the latest edition).
Memory: I have almost a dozen books discussing memory. What these say is that there are a collection of memory systems having various characteristics; which is what the chapters in the general coverage books say.
Modeling: So you want to model the human brain. ACT-R is the market leader in general cognitive modeling. “Bayesian cognitive modeling” by Lee and Wagenmakers, is a good introduction for those who prefer a more abstract approach (“Computational modeling of cognition” by Farrell and Lewandowsky, is a big disappointment {they have written some great papers} and best avoided).
Reasoning: The study of reasoning is something of a backwater in psychology. Early experiments showed that people did not reason according to the rules of mathematical logic, and this was treated as a serious fault (whose fault it was, shifted around). Eventually most researchers realised that the purpose of reasoning was to aid survival and reproduction, not following the recently (100 years or so) invented rules of mathematical logic (a few die-hards continue to cling to the belief that human reasoning has a strong connection to mathematical logic, e.g., Evans and Johnson-Laird; I have nearly all their books, but have not inflicted them on the local charity shop yet). Gigerenzer has written several good books: “Adaptive thinking: Rationality in the real world” is a readable introduction, also “Simple heuristics that make us smart”.
Social psychology: “Social learning” by Hoppitt and Laland, analyzes the advantages and disadvantages of social learning; “The Secret of Our Success: How Culture Is Driving Human Evolution, Domesticating Our Species, and Making Us Smarter” by Henrich, is a more populist book (by a leader in the field).
Vision: “Visual intelligence” by Hoffman is a readable introduction to how we go about interpreting the photons entering our eyes, while “Graph design for the eye and mind” by Kosslyn is a rule based guide to visual presentation. “Vision science: Photons to phenomenology” by Palmer, for those who are really keen.
Several good books have probably been omitted, because I failed to spot them sitting on the shelf. Suggestions for books covering topics I have missed welcome, or your own preferences.
Recent Comments