Archive
2015: A new C semantics research group
A very new PhD student research group working on C semantics has just appeared on the horizon. You can tell they are very new to C semantics by the sloppy wording in their survey of C users (what is a ‘normal’ compiler and how does it differ from the ‘current mainstream’ compiler referred to in some questions? I’m surprised the outcome appeared clear to the authors, given the jumble of multiple choice options given to respondents).
Over the years a number of these groups have appeared, existed until their members received a PhD and then disappeared. In some cases one of the group members does something that shows a lot of potential (e.g., the C-semantics work), but the nature of academic research means that either the freshly minted PhD moves to industry or else moves on to another research area. Unfortunately most groups are overwhelmed by the task and pivot into meaningless subsets of concentrating on mathematical organisms. Very, very occasionally interesting work gets supported once the PhD is out of the way, Coccinelle being the stand-out example for C.
It takes implementing a full compiler (as part of a PhD or otherwise) to learn C semantics well enough to do meaningful research on it. The world seems to be stuck in a loop of using research to educate know-nothings until they know-something and then sending them off on another track. This is why C language researchers keep repeating themselves every 10 years or so.
Will anybody in this new group do any interesting work? Alan Mycroft set the bar very high for Cambridge by submitting a 100 page comment document on the draft C89 standard that listed almost as much ambiguous wording as everybody else put together found (but he was implementing a compiler in his spare time and not doing it for a PhD, so perhaps he does not count).
One suggestion I would make to this new group is that if they really are interested in actual usage they should measure actual usage, developer beliefs about compiler behavior is rarely very accurate and always heavily tainted by experiences from when they first started out.
High value IP auctions, finally a way to moneterise the blockchain
Team High-value-IP-auctions (Gary, Shlomie and yours truly) were at Hackcoin today. We targeted the opposite end of the market from Team Long Tail Licensing, i.e., high value at very low volume rather than low value at high volume.
One of the event sponsors was Nxt, a cryptocurrency I had not previously heard of. Nxt is unusual in that it is exclusively focused on the use of the blockchain as a tool for building applications, there is no mining to create new currency (it is based on proof-of-stake, which was all distributed at genesis). I was surprised at how well developed the software and documentation appeared to be (a five hour hack does not leave time for a detailed analysis).
So you have some very interesting information and want to provide a wealthy individual the opportunity to purchase exclusive access to it. There is a possibility that the individual concerned might not be very sporting about this opportunity and it would be prudent for the seller to remain anonymous throughout the negotiation and payment process.
A cryptocurrency blockchain is the perfect place to deposit information for which a global audience might be needed at some point in the future. The information can be stored in encrypted form (where it can hide in plain sight with all the other encrypted content), it will be rapidly distributed to a wide variety of independent systems and following a few simple rules allows the originating source to remain anonymous.
The wealthy individual gets sent details on how to read the information (i.e., a decryption key and a link to the appropriate block in the blockchain) and the Nxt account number where the requested purchase price should be deposited.
Once events have been set in motion the seller may not have reliable access to the Internet and would prefer a third party to handle the details.
The third party could be a monitor program running in the cloud (perhaps independent copies running on Amazon, Azure and Google to provide redundancy). This monitor program sleeps until the end of the offer period and then sends a request for the current balance on the account being used. If the account does not contain the purchase price, the encryption key and appropriate link is tweeted, otherwise the monitor program shuts itself down.
Those of you who don’t have any information that wealthy individuals might want to purchase could use this approach to run a kick-starter campaign, or any sale of digital goods that involved triggering product release after a minimum monetary amount is reached within a given amount of time.
Does the third party monitor program have to run outside of a blockchain environment? Perhaps it could be executed as a smart contract inside a crytpocurrency such as Ethereum. I did see mention of smart contracts inside Nxt, but unless I missed something they are not supported by the base API.
The designers of the Nxt blockchain have appreciated that they need a mechanism to stop it becoming weighed down by long dead information. The solution is pruned data, data that is removed from the blockchain after a period of time (the idea that a blockchain is an immutable database is great in theory, but dooms any implementation to eventual stasis).
Does our wealthy individual have any alternative options? Perhaps the information is copyright and the lawyers can be unleashed. I doubt that lawyers could prevent the information being revealed in this case, but copyright infringement via the blockchain is an issue that has yet to explode on the world.
The implementation was surprisingly straightforward and the only feature not yet working at the time of our presentation was tweeting of encryption key. We won first prize of 1-bitcoin!
Extracting absolute values from percentage data
Empirical data on requirements for commercial software systems is extremely hard to find. Massimo Felici’s PhD thesis on requirements evolution contains some very interesting data relating to an avionics system, but in many cases the graphs are plotted without numbers next to the axis tick marks. I imagine these numbers were removed because of concerns about what people who had been promoted beyond their level of competence might say (I would also have removed them if asked by the company who had provided the raw data, its a data providers market).
As soon as I saw the plot below I knew I could reverse engineer the original numbers for the plot in the top left.
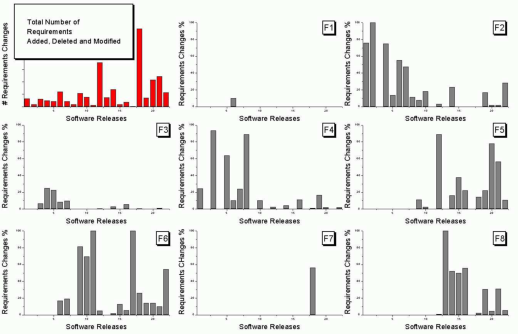
The top left plot is a total count of requirements added/deleted/modified in each of the 22 releases of the product. The eight other plots contain individual percentage information for each of the eight requirements features included in the total count product.
The key is that requirement counts have integer values and the percentages in the F1-8 plots are ratios that restrict the requirement counts to being exactly divisible by a calculated value.
I used WebPlotDigitizer, the goto tool for visually extracting data from plots, to obtain values for the height of each bar (for the time being assuming the unnumbered tick marks linearly increased in units of one).
Looking at the percentages for release one we see that 75% involved requirement feature F2 and 25% F4. This means that the total added/deleted/modified requirement count for release one must be divisible by 4. The percentages for release five are 64, 14 and 22; within a reasonable level of fuzziness this ratio is 9/2/3 and so the total count is probably divisible by 15. Repeating the process for release ten we get the ratio 7/4/1/28, probably divisible by 40; release six is probably divisible by 20, release nine by 10, release fourteen by 50 and fifteen by 10.
How do the release values extracted from the top left shape up when these divisibility requirements are enforced? A minimum value for the tick mark increment of 100 matches the divisibility requirements very well. Of course an increment of any multiple of 100 would match equally well, but until I spot a relationship that requires a larger value I will stick with 100.
I was not expecting to be so lucky in being able to extract useful ratios and briefly tried to be overly clever. Diophantine equations is the study of polynomial equations having integer solutions and there are lots of tools available for solving these equations. The data I have is fuzzy because it was extracted visually. A search for fuzzy diophantine equations locates some papers on how to solve such equations, but no obvious tools (there is code for solving fuzzy linear systems, but this technique does not restrict the solution space to integers).
The nearest possible solution path I could find involving statistics was: Statistical Analysis of Fuzzy Data.
If a reader has any suggestions for how to solve this problem automatically, given the percentage values, please let me know. Images+csvs for your delectation.
Power consumed by different instruction operand value pairs
We are all used to the idea that program performance (e.g., cpu, storage and power consumption) varies across different input data values. A very interesting new paper illustrates how the power consumption of individual instructions varies as instruction operand values change.
The graph below (thanks to Kerstin for sending me a color version, scale is in Joules) is a heatmap of the power consumed by the 8-bit multiply instruction of an XMOS XCore Atmel AVR cpu for all possible 8-bit values (with both operands in registers and producing a 16-bit result). Spare a thought for James Pallister who spent weeks of machine time properly gathering this data; by properly I mean he took account of the variability of modern processor power consumption and measured multiple devices (to relax James researches superoptimizing for minimal power consumption).
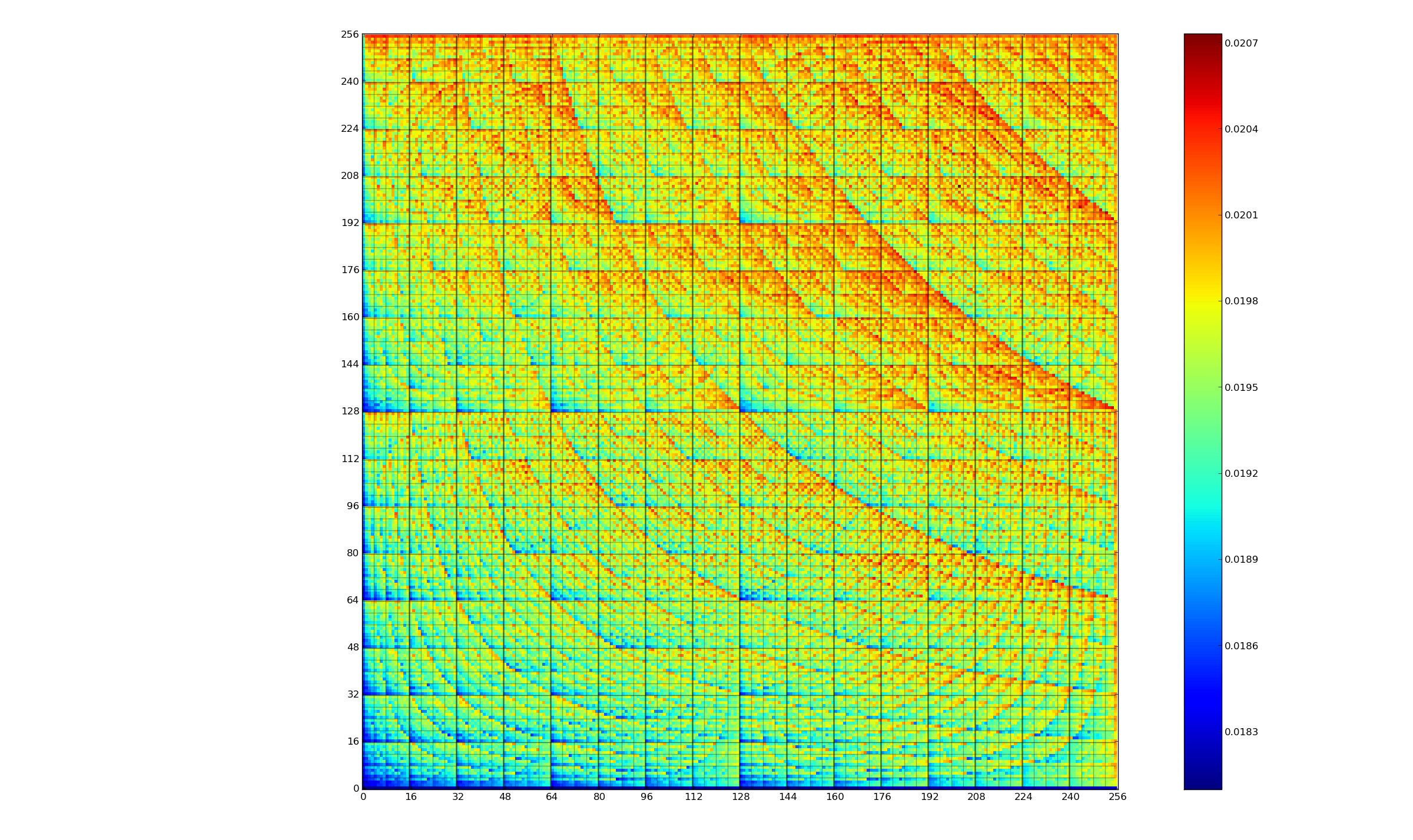
Why is power consumption not symmetric across the diagonal from bottom left to top right? I naively assumed power consumption would be independent of operand order. Have a think before seeing one possible answer further down.
The important thing you need to know about digital hardware power consumption is that change of state (i.e., 0-to-1 or 1-to-0) is what consumes most of the power in digital circuits (there is still a long way to go before the minimum limit set by the Margolus–Levitin theorem is reached).
The plot below is for the bit-wise AND instruction on a XMOS XCore cpu and its fractal-like appearance maps straight to the changing bit-patterns generated by the instruction (Jeremy Morse did this work).
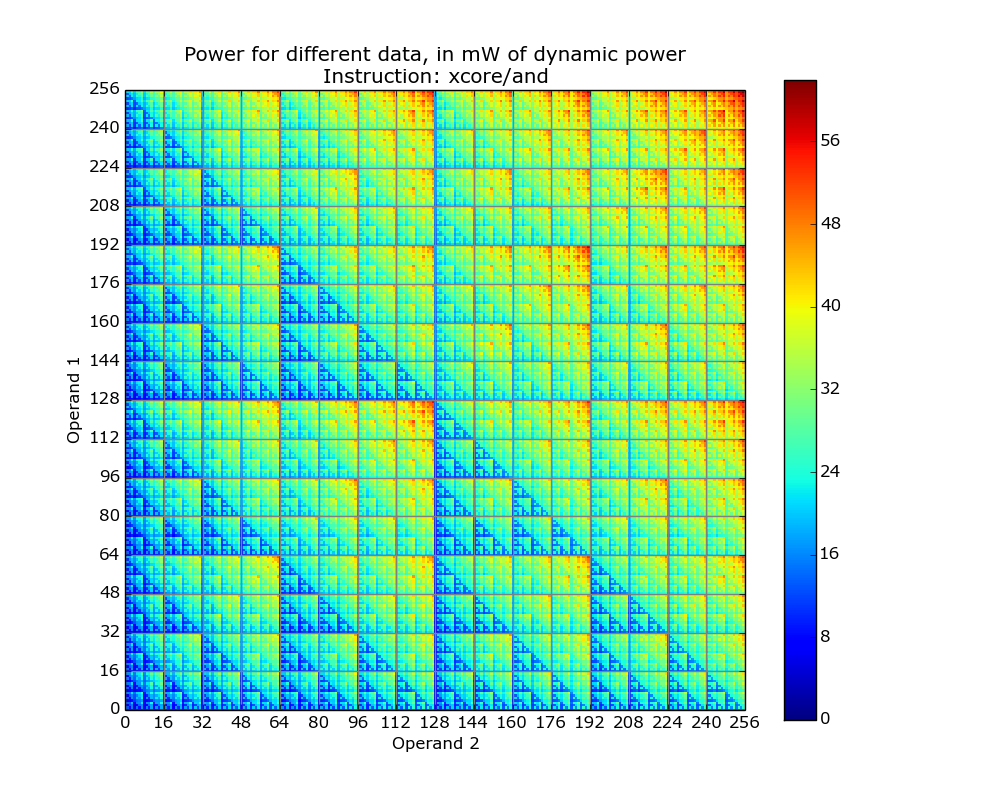
Anyone interested in doing their own power consumption measurements should get a MAGEEC Energy Measurement Kit and for those who are really hardcore the schematics are available for you to build one yourself.
Why is power consumption asymmetrical? Think of paper and pencil multiplication, the smaller number is written under the larger number to minimise the number of operations that need to be performed. The ‘popular’ explanation of the top plot is that the cpu does the multiply in whatever order the operand values happen to be in, i.e., not switching the values to minimise power consumption. Do you know of any processors that switch operand order to minimise power consumption? Would making this check cost more than the saving? Chip engineers, where are you?
A plug for the ENTRA project and some of the other people working with James, Kerstin and Jeremy: Steve Kerrison and Kyriakos Georgiou.
Is your interesting project on hold because of lack of sufficient cpu time?
Do you have an interesting project that is stalled because of lack of cloud compute resources? If so I know some guys who may be able to help.
One of the prizes at a recent hackathon was around $8k of cloud computing per month for a year. The guys who won it have not been using the monthly allowance and would like to put it to good use.
What counts as an “interesting project”? You are dealing with hackers who enjoy working at the edge of things and want to be involved in a project that impresses other hackers (here ‘involved’ means telling other people they are involved, not actually helping you with the project in any way). While it is obviously a project that uses computers it does not have to be about computing. Helping your me-to-startup is very unlikely to be interesting.
Hackers are fans of open data, so you will have to have a very good reason not to make any data you produce public.
Send me an email briefly describing your project, why it needs this cloud computing resource and show that you will not fritter it away because you don’t know what you are doing.
The clock is ticking.
Aggregate player preference for the first 20 building created in Illyriad
I was at the Microsoft Gaming data hackathon today. Gaming is very big business and companies rarely publish detailed game data. Through contacts one of the organizers was able to obtain two gaming datasets, both containing just under 300M of compressed of data.
Illyriad supplied a random snapshot of anonymised data on 50,000 users and Mediatonic supplied three months of player data.
Being a Microsoft event there were lots of C# developers, with data analysis people being thin on the ground. While there were plenty of gamers present I could not find any that knew the games for which we had data (domain experts are always in short supply at hackathons).
I happened to pick the Illyriad data to investigate first and stayed with it. The team sitting next to us worked on the Mediatonic data and while I got to hear about this data and kicked a few ideas around with them, I did not look at it.
The first thing to do with any dataset is to become familiar with what data it actually contains and the relationships between different items. I was working with two people new to data science who wanted to make the common beginner mistake of talking about interesting things we could do; it took a while for my message of “no point of talking about what we could do with the data until we know what data we have” to have any effect. Of course it is always worth listening to what a domain expert is interested in before looking at the data, as a source of ideas to keep in mind; it is not worth keeping in mind ideas from non-domain experts.
Quick Illyriad game overview: Players start with a settlement and construct/upgrade buildings until they have a legendary city. These buildings can generate resources such as food and iron; towns/cities can be conquered and colonized… you get the picture.
My initial investigation of the data did not uncover any of the obvious simple patterns, but did manage to find a way of connecting some pairs of players in a transaction relationship (the data for each player included a transaction list which gave one of 255 numeric locations and the transaction amount; I reasoned that the location/amount pair was likely to be unique).
The data is a snapshot in time, which appeared to rule out questions involving changes over time. Finally, I realized that time data was present in the form of the order in which each player created buildings in their village/town/city.
Buildings are the mechanism through which players create resources. What does the data have to say about gamers preferential building construction order? Do different players with different playing strategies use different building construction orders?
A search of the Illyriad website located various beginners’ guides containing various strategy suggestions, depending on player references for action.
Combining the order of the first 20 different buildings, created by all 50,000 players, into an aggregate preference building order we get:
Library Storehouse Lumberjack Clay Pit Farmyard Marketplace Quarry Iron Mine Barracks Consulate Mage Tower Paddock Common Ground Brewery Tavern Spearmaker Tannery Book Binder Flourmill Architects` Office |
A couple of technical points: its impractical to get an exact preference order for more than about 10 players and a Monti Carlo approach is used by RankAggreg and building multiple instance of the same kind of building were treated as a single instance (some form of weighting might be used to handle this behavior):
The order of the top three ranked buildings is very stable, but some of the buildings in lower ranks could switch places with adjacent buildings with little impact on ranking error.
Do better players use different building orders than poor players? The data does not include player ability data as such; it included game ranking (a high ranking might be achieved quickly by a strong player or slowly over a longer period by a weaker player) and various other rankings (some of which could be called sociability).
Does the preference for buildings change as a players’ village becomes a town becomes a city? At over 200 minutes of cpu time per run I have not yet had the time to find out. Here is the R code for you to try out some ideas:
library("plyr")
library("RankAggreg")
get_build_order=function(df)
{
# Remove duplicates for now
dup=duplicated(df$building_id)
# Ensure there are at least 20
build_order=c(df$building_id[!dup], -1:-20)
return(build_order[1:20])
}
# town_id,building_id,build_order_for_town
#1826159E-976D-4743-8AEB-0001281794C2,7,1
build=read.csv("~/illyriad/town_buildings.csv", as.is=TRUE)
build_order=daply(build, .(town_id), get_build_order)
build_rank=RankAggreg(build_order, 20) |
What did other teams discover in the data? My informal walk around on Saturday evening found everybody struggling to find anything interesting to talk about (I missed the presentation on Sunday afternoon, perhaps a nights sleep turned things around for people, we will have to check other blogs for news).
If I was to make one suggestion to the organizers of the next gaming data hackathon (I hope there is one), it would be to arrange to have some domain experts (i.e., people very familiar with playing the games) present.
ps. Thanks to Richard for organizing chicken for the attendee who only eats pizza when truly starving.
Update
Source code usage via n-gram analysis
In the last 18 months or so source code analysis using n-grams has started to take off as a research topic, with most of the current research centered around lexical tokens as the base unit. The usefulness of n-grams for getting an idea of the main kinds of patterns that occur in code is one of those techniques that has been long been spread via word of mouth in industry (I used to use it a lot to find common patterns in generated code, with the intent of optimizing that common pattern).
At the general token level n-grams can be used to suggest code completion sequences in IDEs and syntax error recovery tokens for compilers (I have never seen this idea implemented in a production compiler). Token n-grams are often very context specific, for instance the logical binary operators are common in control-expressions (e.g., in an if-statement) and rare outside of that context. Of course any context can be handled if the n in n-gram is very large, but every increase in n requires a lot more code to be counted, to separate out common features from the noise of many single instances ((n+1)-grams require roughly an order of T more tokens than n-gram, where T is the number of unique tokens, for the same signal/noise ratio).
At a higher conceptual level n-grams of language components (e.g, array/member accesses, expressions and function calls) provide other kinds of insights into patterns of code usage. Probably more than you want to know of this kind of stuff in table/graphical form and some Java data for those wanting to wave their own stick.
An n-gram analysis sometimes involves a subset of the possible tokens, for instance treating sequences of function/method api calls that does not match the any of the common sequences as possible faults (e.g., a call that should have been made, perhaps closing a file, was omitted).
It is easy to spot n-gram researchers who have no real ideas of their own and are jumping on the bandwagon; they spend most of their time talking about entropy.
Like all research topics, suggested uses for n-grams sometimes gets rather carried away with its own importance. For instance, the proposal that common code sequences are “natural” and have a style that must be followed by other code. Common code sequences are common for a reason and we ought to find out what that reason is before suggesting that developers blindly mimic this usage.
Recent Comments