Archive
Single-quote as a digit separator soon to be in C++
At the C++ Standard’s meeting in Chicago last week agreement was finally reached on what somebody in the language standards world referred to as one of the longest bike-shed controversies; the C++14 draft that goes out for voting real-soon-now will include support for single-quotation-mark as a digit separator. Assuming the draft makes it through ISO voting you could soon be writing (Compiler support assumed) 32'767 and 0.000'001 and even 1'2'3'4'5'6'7'8'9 if you so fancied, in your conforming C++ programs.
Why use single-quote? Wouldn’t underscore have been better? This issue has been on the go since 2007 and if you feel really strongly about it the next bike-shed C++ Standard’s meeting is in Issaquah, WA at the start of next year.
Changing the lexical grammar of a language is fraught with danger; will there be a change in the behavior of existing code? If the answer is Yes, then the next question is how many people will be affected and how badly? Let’s investigate; here are the lexical details of the proposed change:
pp-number: digit . digit pp-number digit pp-number ' digit pp-number ' nondigit pp-number identifier-nondigit pp-number e sign pp-number E sign pp-number . |
Ideally the change of behavior should cause the compiler to generate a diagnostic, when code containing it is encountered, so the developer gets to see the problem and do something about it. The following conforming C++ code will upset a C++14 compiler (when I write C++ I mean the C++ Standard as it exists in 2013, i.e., what was called C++11 before it was ratified):
#define M(x) #x // stringize the macro argument char *p=M(1'2,3'4); |
At the moment the call to the macro M contains one argument, the sequence of three tokens {1}, {'2,3'} and {4} (the usual convention is to bracket the characters making up one token with matching curly braces).
In C++14 the call to M will contain the two arguments {1'2} and {3,4}. conforming compiler is required to complain when the number of arguments to a macro invocation don’t match the definition…. Unless the macro is defined to accept a variable number of arguments:
#define M(x, ...) __VA_ARGS__ int x[2] = { M(1'2,3'4) }; // C++11: int x[2] = {}; // C++14: int x[2] = { 3'4 }; |
This is the worst kind of change in behavior, known as a silent change, the existing code compiles without complaint but has different behavior.
How much existing code contains either of these constructs? I suspect very very little human written code, maybe even none. This is the sort of stuff that is more likely to be produced by automatic code generators. But how much more likely? I have no idea.
How much benefit does the new feature provide? It certainly looks useful, but coming up with a number for the benefit is hard. I guess it has the potential to shave a fraction of a second off of the attention a developer has to pay when reading code, after they have invested in learning about the construct (which is lots of seconds). Multiplied over many developers and not that many instances (the majority of numeric literals contain a single digit), we could be talking a man year or two per year of worldwide development effort?
All of the examples I have seen require the ‘assistance’ of macros, here is another (courtesy of Jeff Snyer):
#define M(x) A ## x #define A0xb int operator "" _de(char); int x = M(0xb'c'_de); |
Are there any examples of a silent change that don’t involve the preprocessor?
How many ways of programming the same specification?
How many different ways are there of writing a program to implement a given specification? Non-trivial specifications probably have an enormous number of possible programming solutions. What about really simple specifications, say something based on the 3n+1 problem (write a programs that takes a list of integers and outputs their ‘3n+1’ length; ‘3n+1’ length algorithm: for integer  , if is even divide it by
, if is even divide it by  and assign the result to , otherwise is odd, multiply it by
and assign the result to , otherwise is odd, multiply it by  and add
and add  to give the new value of ; repeat the process, counting the number of iterations until reaches )?.
to give the new value of ; repeat the process, counting the number of iterations until reaches )?.
I can think of a dozen or so (slightly) different ways that I might write a program to solve this problem. If I really had to I could probably come up with a few hundred different solutions, but I think the source code of these programs would not look like something I would normally write. If I was to run a competition how many different answers might I get? If you twisted my arm I might have said 500. What do you think?
Meine van der Meulen studied the N-version programing for his PhD thesis (N groups independently write a program to the same specification, compare the output of the N programs and select the ‘best’ answer; cannot find a copy of the thesis online). This was empirical work and van der Meulen posted the above 3n+1 problem to a programming competition website and used the 95,497 submitted solutions for his analysis; he also kindly sent me a copy of the solutions (11,674 solutions were written in Pascal, the rest were in C).
Not all the solutions correctly solve the problem. I ignored this ‘detail’. There are also many duplicates (as in identical source code).
I am interested in differently coded solutions. I defined different as the sequence of operators/punctuators making up the program being different (or at least having a different MD5 checksum), so identifiers and comments are ignored. Should permutations in the order of independent adjacent statements really be counted as different? For the sack of keeping my life simple they current are. This definition of differently coded reduces the original 63,823 C programs down to 6,301. Wow, how are 6k+ different programs possible?
The original specification did not mention performance, but lots of developers did all sorts of weird and wonderful stuff to improve runtime performance. The most common optimization technique used (apart from some inventive ways of checking for odd/even) was to cache previous answers along with the solution for all the intermediate steps that were passed through on the way to 1 (the path from the starting value to 1 is very erratic and sometimes goes through values greater than the starting value) and check this cache to see whether it contains the current value of.
A common measure of program size is lines of code. What is the size distribution, in LOC, for these 6,301 programs? One program has been labeled an outlier and excluded from the analysis (most of its 8,345 lines were taken up with initializing a data structure with precomputed solutions).
The following plots lines of code against the number of programs containing that many lines (download code and data).
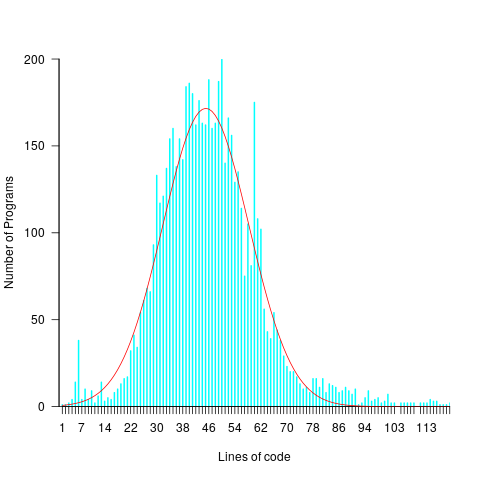
The mean program length is 46.3 lines, standard deviations 15.4. The red curve is a Normal distribution whose mean/sd has been tweaked to give a better visual fit (a Shapiro-Wilk test dispels any hope tht the distribution might be Normal). There is no reason to think that the data will be fitted by any known distribution and I’m not going to overfit on one data-point. If pushed I will wave my arms and describe the distribution as Normalish with added spikes and a fat right tail.
That spike around 60 lines is interesting. Is this group of solutions all doing the same thing but with different statement orderings? I have previously written about how gcc/llvm do a good job of turning the core of the algorithm into the same machine code. Perhaps a future version of these compilers will be able to tell us whether the programs clumping around 60 LOC are doing the same thing.
Software engineering: A great discipline for an academic fraudster
I am a sporadic reader of In the Pipeline, a blog covering drug discovery and the pharma industry, subjects about which I have no real interest but the author is a no nonsense guy whose writing I enjoy reading. A topic that regularly crops up is retraction of a published paper (i.e., effectively saying “ignore that paper we published way back when”). Reasons for retraction include a serious mistake, plagiarism of somebody else’s work or outright fabrication of data.
Retraction of papers published in software engineering journals is rare, why is that? I don’t think software engineering researchers are more/less honest than researchers in other fields. I could not find any entries on Retraction Watch.
Plagiarism certainly occurs and every now and again a paper is retracted for this reason.
Corrections to previously published papers certainly occur on a regular basis, but I don’t recall seeing a retraction because of a serious error (but then I rarely get to gossip around the coffee table in university departments and am not that well up on such goings on).
Researchers are certainly not above using the subset of a benchmark that shines the most favorable light on their work, or simply performing misleading comparisons. Researchers who do such things are seem more as an embarrassment than a threat to academic integrity, they are certainly not in the same league as those who fabricate data
Fabrication of data in software engineering? I’m sure it goes on, but unless the people responsible own up I think it is unlikely to be detected (unless the claims are truely over the top). There is no culture of replication in software engineering or of building on other peoples’ work (everybody is into doing their own thing); two very serious problems, but not the topic of this discussion.
In fact software engineering is the ideal discipline for an academic fraudster: replication is very rare, everyone doing their own thing, a culture of poor/nonexistent record keeping and experimental data is rarely kept past the replacement of the machine on which it sits (I am regularly told this when I email authors asking for a copy of their raw data for my book). Even in disciplines whose characteristics are at the other end of the culture scale, it can take a long time for fraud to be uncovered.
From time to time authors I contact tell me that the numbers appearing in the published paper are incorrect; often there is an offer of the correct numbers and sometimes a vague recollection of what they might be. Sometimes authors don’t reply to my email, is the data fake or is talking to me not worth their time (I have received replies to this effect)?
Am I worried about fraud in software engineering research? No, incorrect data in published work is more likely to occur because of clerical mistakes, laziness or incompetence.
Recent Comments