Number of digits in floating-point literals
Some of the interesting floating-point literals detected by the numbers program not only look uninteresting but plain wrong. For instance, almost every program I analyze appears to contain a literal denoting the ratio of the diameter of the Earth to at least one minor planet. One problem is that most of the numbers contained in the interesting number database are only likely to occur in very specific circumstances and as the size of this database grows the percentage of inappropriate matches grows.
I could (and at some point probably will have to) assign an interestingness level to numbers, but this goes against one of the original aims of identifying the operations performed by unknown source.
An alternative idea is to create a connection between the fuzziness of the matching process and the probability of the literal being encountered in code. For instance, a more exact match might be required for 0.5 because it contains few mantissa digits and sits within a range of values that are commonly encountered, while a much fuzzier match might be used for 1.879623e+3 because it contains more digits and occupies a less commonly encountered range of values.
Floating-point literals often contain leading or trailing zeros, e.g., 0.001, 100.0, 1e+2
or 0.50. Does the presence of these zeros change the probability of a particular mantissa being encountered? For instance the literals 100.0 and 1e+2 have the same numeric value but different numbers of mantissa digits.
Another issue is developer intent. Why did a developer write 0.50, did they simply want two digits to appear after the decimal point because the surrounding literals in the source contain two digits and it makes the visual appearance look better or does this usage denote a quantity whose accuracy is known to two decimal digits?
The following figure is derived from 1 million non-zero floating-point literals contained in ten large, computationally intensive programs.
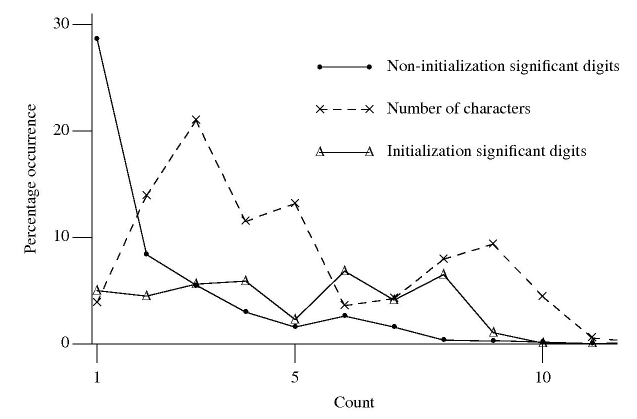
The dashed line denotes the percentage of mantissas containing a given number of characters, including leading/trailing zeros and any decimal point.
The two solid lines denote the digit count of the mantissas with any leading/trailing zeros removed, along with any decimal point, e.g., both 100.0 and 1e+2 would be considered to contain one digit.
It seemed to me that floating-point literals appearing within an initializer attached to a variable definition often contain more digits than literals that appear elsewhere. The solid, triangle tagged, solid line that spends most of its time around 5% are floating-point literals appearing within an initializer (to be exact they are literals separated from another literal by a comma {with some simplistic handling of Fortran line continuation}). The bullet tagged line are all other literals.
I was partially right about the characteristics of floating-point literals in initializers. It turns out the probability of encountering a mantissa containing a given number of digits is approximately constant within an initializer (a more sophisticated analysis might show an upward trend with increasing numbers of digits).
The mantissa digit count outside of initializers has the kind of probability distribution I was looking for. Hopefully this distribution will contribute to a useful measure of interestingness.
-
May 31st, 2010 at 02:30 | #1The Shape of Code » Frequency of floating literals in a given range
Recent Comments