A signature for the “embeddedness” of source code and developers?
Patterns in the use of source code can tell us a lot about the people who wrote the code, the characteristics of the hardware it runs on and what the application is all about.
Often the pattern of usage needs a lot of work to understand and many remain completely baffling, but every now and again the forces driving a pattern leap off the page. One such pattern is visible in the plot below; data courtesy of Jacob Engblom and the cbook data is from my C book (assuming you know something about the nitty gritty of embedded software development). It shows the percentage of functions defined to have a given number of parameters:
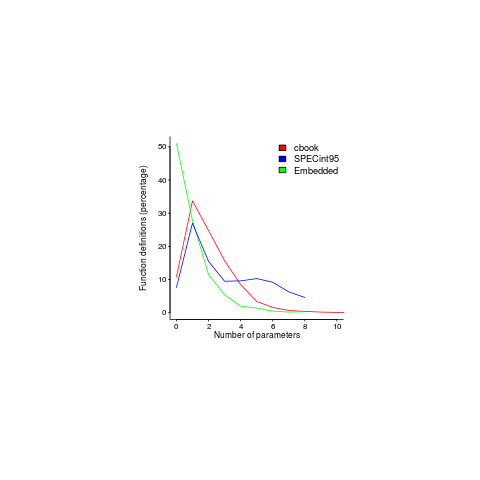
Embedded software has to run in very constrained environments. The hardware is often mass produced and saving a penny per device can add up to big savings, so the cheapest processor is chosen and populated with the smallest possible memory; developers have to work with what they are given. Power consumption may be down below one watt, so clock speeds are closer to 1 MHz than 1 GHz.
Parameter passing is a relatively expensive operation and there are major savings, relatively speaking, to be had by using global variables. Experienced embedded developers know this and this plot is telling us that they are acting on this knowledge.
The following are two ways of interpreting the embedded data (I cannot think of any others that make sense):
- the time/resource critical functions use globals rather than parameters and all the other functions are written more or less the same as in a non-embedded environment. In statistical terms this behavior is described by a zero-inflated model,
- there is pressure on the developer to reduce the number of parameters in all function definitions.
This data contains counts, so a Poisson distribution is the obvious candidate for our model.
My attempts to fit a zero-inflated model failed miserably (code+data). A basic Poisson distribution fitted everything reasonably well (let’s ignore that tiresome bump in the blue line); plus signs are the predictions made from each fitted model.
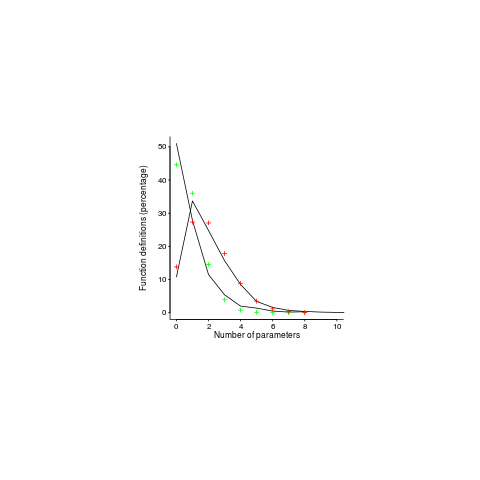
For desktop developers, the distribution of function definitions having a given number of parameters follows a Poisson distribution with a λ of 2, while for embedded developers λ is 0.8.
What about values of λ between 0.8 and 2; perhaps the λ of a project’s, or developer’s, code parameter count can be used as an indicator of ’embeddedness’?
What is needed to parameter count data from a range of 4-bit, 8-bit and 16-bit systems and measurements of developers who have been working in the field for, say, 4, 8, 16 years. Please let me know.
The data is from a Masters thesis written in 1999, is it still relevant today? Have modern companies become kinder to developers and stopped making their life so hard by saving pennies when building mass produced products; are modern low-power devices being used so values can be passed via parameters rather than via globals, or are they being used for applications where even less power is available?
One difference from 20 years ago is that embedded devices are more mainstream, easier to get hold of and sales opportunities abound. This availability creates an environment where developers with a desktop development mentality (which developers new to embedded always seem to have had) don’t get to learn about the overheads of parameter passing.
Have compilers gotten better at reducing the function parameter overhead? The most obvious optimization is inlining a function at the point of call. If the function is only called once, this works fine, with multiple calls the generated code can get larger (one of the things we are trying to avoid). I don’t have any reliable data on modern compiler performance int his area, but then I have not looked hard. Pointers to benchmarks welcome.
Does embedded software have any other signatures that differentiate it from desktop software (other than the obvious one of specifying address in definitions of global variables)? Suggestions welcome.
Dead giveaway: Is the code MISRAble? 😛
Embedded systems never seems to have enough CPU, memory, or other important resources. That leads to numerous custom optimizations, depending on the situation at hand.
Depending on the hardware architecture and function calling convention, parameter passing may have a large overhead, or it may be relatively “free”. How big is the register file? How many bytes to encode and CPU cycles to decode a passed parameter? In my limited experience, low parameter counts are due as much to whole-program optimization (global knowledge) as they are to function call overhead.
Expect to see a lot more bit twiddling, small look-up tables, gotos, etc. Also look for memory-mapped I/O, snippets of embedded assembly, etc. Many embedded applications contain what little there is of an OS…
Most embedded system guides strongly discourage memory management after startup. It is common that the entire memory map is set at compile/link time. Dynamic linking is rare. Look for big tables that serve as scratch space and object pools. Look for addresses that are re-used for different purposes during execution. Look for registers with fixed meaning. Depending on the architecture, special attention is often paid to align memory for vector units, to pack variables to avoid wasted space, etc. This information may be stored in a ROM, or it may be calculated during initialization before the main event loop starts.
Most embedded system guides strongly discourage unbounded loops, recursion, etc. This bounds both execution time and stack space. Multi-threading is rare and strictly managed. Expect an event loop, often constantly running, sometimes select()-style. Many loops check flags that are set by custom interrupt handlers.
Many optimizations performed for embedded systems are not readily apparent in the final product. They only stand out when compared to the original reference implementation. Algebraic simplifications, numeric approximations, statistical approximations, and re-ordering calculations to produce useful byproducts are all examples of this.
@D Herring
Register file? We are starting to talk rather up market cpus here.
All programs contain bit-twiddling, but if it is tucked away in a library to amount of source code involved will be small. The same goes for library calls, although in some cases the counts for embedded code will be zero rather than just very small.
Recursion is not that common outside of compilers and computer science stuff. Call-backs are common in user interface code.
Code size is an obvious differentiator, especially with 4-bit targets (of which I have no hands on experience).
16-bit integers and extensive use of 8-bit values for arithmetic operations is the one clear signal I could think of.