Archive
Evolution has selected humans to prefer adding new features
Assume that clicking within any of the cells in the image below flips its color (white/green). Which cells would you click on to create an image that is symmetrical along the horizontal/vertical axis?

In one study, 80% of subjects added a block of four green cells in each of the three white corners. The other 20% (18 of 91 subjects) made a ‘subtractive’ change, that is, they clicked the four upper left cells to turn them white (code+data).
The 12 experiments discussed in the paper People systematically overlook subtractive changes by Adams, Converse, Hales, and Klotz (a replication) provide evidence for the observation that when asked to improve an object or idea, people usually propose adding something rather than removing something.
The human preference for adding, rather than removing, has presumably evolved because it often provides benefits that out weigh the costs.
There are benefits/costs to both adding and removing.
Creating an object:
- may produce a direct benefit and/or has the potential to increase the creator’s social status, e.g., ‘I made that’,
- incurs the cost of time and materials needed for the implementation.
Removing an object may:
- produce savings, but these are not always directly obvious, e.g., simplifying an object to reduce the cost of adding to it later. Removing (aka sacking) staff is an unpopular direct saving,
- generate costs by taking away any direct benefits it provides and/or reducing the social status enjoyed by the person who created it (who may take action to prevent the removal).
For low effort tasks, adding probably requires less cognitive effort than removing; assuming that removal is not a thoughtless activity. Chesterton’s fence is a metaphor for prudence decision-making, illustrating the benefit of investigating to find out if any useful service provided by what appears to be a useless item.
There is lots of evidence that while functionality is added to software systems, it is rarely removed. The measurable proxy for functionality is lines of code. Lots of source code is removed from programs, but a lot more is added.
Some companies have job promotion requirements that incentivize the creation of new software systems, but not their subsequent maintenance.
Open source is a mechanism that supports the continual adding of features to software, because it does not require funding. The C++ committee supply of bored consultants proposing new language features, as an outlet for their creative urges, will not dry up until the demand for developers falls below the supply of developers.
Update
The analysis in the paper More is Better: English Language Statistics are Biased Toward Addition by Winter, Fischer, Scheepers, and Myachykov, finds that English words (based on the Corpus of Contemporary American English) associated with an increase in quantity or number are much more common than words associated with a decrease. The following table is from the paper:
Word Occurrences
add 361,246
subtract 1,802
addition 78,032
subtraction 313
plus 110,178
minus 14,078
more 1,051,783
less 435,504
most 596,854
least 139,502
many 388,983
few 230,946
increase 35,247
decrease 4,791 |
Word length lexical decision data
Well chosen identifier names can reduce the effort needed to understand the code containing them, compared to badly chosen identifiers.
An identifier might have a name that creates a semantic association in the mind of the reader about the role of the variable within a function definition (e.g., outer_counter) or an association with the information contained in the variable (e.g., max_fruit).
Code is not always read like prose text, developers might quickly scan through the source looking for something. In this case short identifier names are best because it reduces the number of characters that need to be scanned.
If you want to make life difficult for anyone who has to read your code, add a visually boring common prefix to every identifier, e.g., uacc. Readers start looking up a word in memory based in the first few characters while they process the remaining characters in a word, and eye tracking studies have found that that character sequence information is used to plan eye saccades (where to move the eyes next). A short bland sequence can really throw a spanner in the works of our over-learned reading skills.
I once researched a detailed analysis of the issues involved in a cost/benefit analysis of identifier selection. The good news is that I think I covered everything, the bad news is that the various kinds of data on human character sequence usage needed to perform the analysis was/is not available.
Today I got my hands on lots of performance data on the affect of word length on visual word recognition; thanks to Boris New (code and data)
The plot below shows the mean response time of 819 subjects performing a lexical decision task (respond yes/no on whether a character sequence is a word or nonword); each subject was tested on a subset of around 3,000 out of 33,608 words.
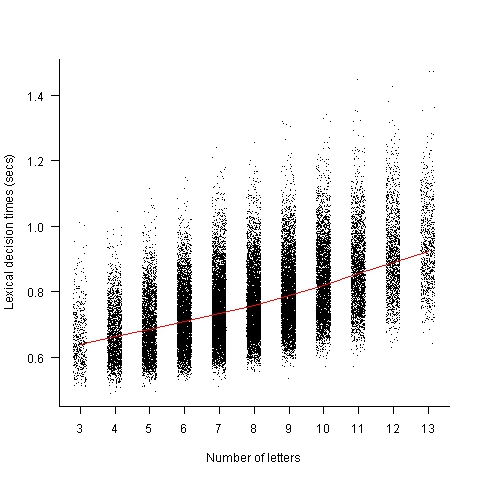
Note, this data is for single words. There are bound to be all sorts of interaction effects when two words/nonwords occur together in an identifier, e.g., semantic priming.
Word length is only one of several factors that have been found to effect people’s performance in processing words; others include the word frequency effect and age of acquisition (when the word was learned, which is correlated with word frequency).
Have fun with this.
Generating sounds-like and accented words
I have always been surprised by the approaches other people have taken to generating words that sound like a particular word or judging whether two words sound alike. The aspell program letter sequence is in its dictionary; the Soundex algorithm is often used to compare whether two words sound alike and has the advantage of being very simple and delivers results that many people seem willing to accept. Over 25 years ago I wrote some software that used a phoneme based approach and while sorting through a pile of papers recently I came across an old report used as the basis for that software. I decided to implement a word sounds-like tool to show people how I think sounds-like should be done. To reduce the work involved this initial tool is based on what I already know, which in some cases is very out of date.
Phonemes are the basic units of sound and any sounds-like software needs to operate on a word’s phoneme sequence, not its letter sequence. The way to proceed is to convert a word’s letter sequence to its phoneme sequence, manipulate the phoneme sequence to create other sequences that have a spoken form similar to the original word and then convert these new sequences back to letter sequences.
A 1976 report by Elovitz, Johnson, McHugh and Shore contains a list of 329 rules for converting a word’s letter sequence into a phoneme sequence. It seemed to me that this same set of rules could be driven in reverse to map a phoneme sequence back to a letter sequence (the complications involved in making this simple idea work will be discussed in another article).
Once we have a phoneme sequence how might it be modified to create similar sounding words?
The distinctive feature theory assigns ten or so features to every phoneme, these denote details such as such things as manner and place of articulation. I decided to use these features as the basis of a distance metric between two phonemes (e.g., the more features two phonemes had in common the more similar they sounded). The book “Phonology theory and analysis” by Larry M. Hyman contains the required table of phoneme/distinctive features. Yes, I am using a theory from the 1950s and a book from the 1970s, but to start with I want to recreate what I know can be done before moving on to use more modern theories/data.
In practice this approach generates too many letter sequences that just don’t look like English words. The underlying problem is that the letter/phoneme rules were not designed to be run in reverse. Rather than tune the existing rules to do a better job when run in reverse I used the simpler method of filtering using letter bigrams to remove non-English letter sequences (e.g., ‘ck’ is not acceptable at the start of a word letter sequence). In preInternet times word bigram information was obtained from specialist cryptographic publishers, but these days psychologists researching human reading are a very good source of reliable information (or at least one I am familiar with).
I have implemented this approach and the system currently supports the generation of:
- letter sequences that sound the same as the input word, e.g., cowd, coad, kowd, koad.
- letter sequences that sound similar to the input word, e.g., bite, dight, duyt, gight, guyt, might, muyt, pight, puyt, bit, byt, bait, bayt, beight, beet, beat, beit, beyt, boyt, boit, but, bied, bighd, buyd, bighp, buyp, bighng, buyng, bighth, buyth, bight, buyt
- letter sequences that sound like the input word said with a German accent, e.g., one, vun and woven, voughen, vuphen.
The output can be piped through a spell checker to remove nondictionary letter sequences.
How accurate are the various sequence translations? Based on a comparison against manual translation of several thousand words from the Brown corpus Elovitz et al claim around 90% of words in random text will be correctly translated to phonemes. I have not done any empirical analysis of the performance of the rules when used to convert phoneme sequences to letters; it will obviously be less than 90%.
The source code of the somewhat experimental tool is available for download. Please note that the code has only been built on Linux, is likely to be fragile in various places and needs a recent copy of the pcre library. Bug reports welcome.
Some of the uses for a word’s phoneme sequence include:
- matching names contained in information transcribed using different conventions or by different people (i.e., slight spelling differences).
- better word splitting at the end of line in LaTeX. Word splitting decisions are best made using sound units.
- better spell checking, particularly for non-native English speakers when coupled with a sound model of common mistakes made by speakers of other languages.
- aid to remembering partially forgotten words whose approximate sound can be remembered.
- inventing trendy spellings for words.
Where next?
Knowledge of the written and spoken word had moved forward in the last 25 years and various other techniques that might improve the performance of the tool are now available. My interest in the written, rather than the spoken, form of code means I have only followed written/sound conversion at a superficial level; reader suggestions on more modern theories, models and data sources that might be used to improve the tools performance are most welcome. A few of my own thoughts:
- As I understand it modern text to speech systems are driven by models derived through machine learning (i.e., some learning algorithm has processed lots of data). There might be existing models out there that can be used, otherwise the MRC Psycholinguistic Database is a good source for lots for word phoneme sequences and perhaps might be used to learn rules for both letter to phoneme and phoneme to letter conversion.
- Is Distinctive feature theory the best basis for a phoneme sounds-like metric? If not which theory should be used and where can the required detailed phoneme information be found? Hyman gives yes/no values for each feature while the first edition of Ladeforded’s “A Course in Phonetics” gives percentage contribution values for the distinctive features of some phonemes; subsequent editions don’t include this information. Is a complete table of percentage contribution of each feature to every phoneme available somewhere?
- A more sophisticated approach to sounds-like would take phoneme context into account. A slightly less crude approach would be to make use of phoneme bigram information extracted from the MRC database. What is really needed is a theory of sounds-like and some machine usable rules; this would hopefully support the adding and removal of phonemes and not just changing existing ones.
As part of my R education I plan to create an R sounds-like package.
In the next article I will talk about how I used and abused the PCRE (Perl Compatible Regular Expressions) library to recognize a context dependent set of rules and generate corresponding output.
Recent Comments