Archive
The Whitehouse report on adopting memory safety
Last month’s Whitehouse report: BACK TO THE BUILDING BLOCKS: A Path Towards Secure and Measurable Software “… outlines two fundamental shifts: the need to both rebalance the responsibility to defend cyberspace and realign incentives to favor long-term cybersecurity investments.”
From the abstract: “First, in order to reduce memory safety vulnerabilities at scale, … This report focuses on the programming language as a primary building block, …” Wow, I never expected to see the term ‘memory safety’ in a report from the Whitehouse (not that I recall ever reading a Whitehouse report). And, is this the first Whitehouse report to talk about programming languages?
tl;dr They mistakenly to focus on the tools (i.e., programming languages), the focus needs to be on how the tools are used, e.g., require switching on C compiler’s memory safety checks which currently default to off.
The report’s intent is to get the community to progress from defence (e.g., virus scanning) to offence (e.g., removing the vulnerabilities at source). The three-pronged attack focuses on programming languages, hardware (e.g., CHERI), and formal methods. The report is a rallying call to the troops, who are, I assume, senior executives with no little or no knowledge of writing software.
How did memory safety and programming languages enter the political limelight? What caused the Whitehouse claim that “…, one of the most impactful actions software and hardware manufacturers can take is adopting memory safe programming languages.”?
The cited reference is a report published two months earlier: The Case for Memory Safe Roadmaps: Why Both C-Suite Executives and Technical Experts Need to Take Memory Safe Coding Seriously, published by an alphabet soup of national security agencies.
This report starts by stating the obvious (at least to developers): “Memory safety vulnerabilities are the most prevalent type of disclosed software vulnerability.” (one Microsoft reports says 70%). It then goes on to make the optimistic claim that: “Memory safe programming languages (MSLs) can eliminate memory safety vulnerabilities.”
This concept of a ‘memory safe programming language’ leads the authors to fall into the trap of believing that tools are the problem, rather than how the tools are used.
C and C++ are memory safe programming languages when the appropriate compiler options are switched on, e.g., gcc’s sanitize flags. Rust and Ada are not memory safe programming languages when the appropriate compiler options are switched on/off, or object/function definitions include the unsafe keyword.
People argue over the definition of memory safety. At the implementation level, it includes checks that storage is not accessed outside of its defined bounds, e.g., arrays are not indexed outside the specified lower/upper bound.
I’m a great fan of array/pointer bounds checking and since the 1980s have been using bounds checking tools to check my C programs. I found bounds checking is a very cost-effective way of detecting coding mistakes.
Culture drives the (non)use of bounds checking. Pascal, Ada and now Rust have a culture of bounds checking during development, amongst other checks. C, C++, and other languages have a culture of not having switching on bounds checking.
Shipping programs with/without bounds checking enabled is a contentious issue. The three main factors are:
- Runtime performance overhead of doing the checks (which can vary from almost nothing to a factor of 5+, depending on the frequency of bounds checked accesses {checks don’t need to be made when the compiler can figure out that a particular access is always within bounds}). I would expect the performance overhead to be about the same for C/Rust compilers using the same compiler technology (as the Open source compilers do). A recent study found C (no checking) to be 1.77 times faster, on average, than Rust (with checking),
- Runtime memory overhead. Adding code to check memory accesses increases the size of programs. This can be an issue for embedded systems, where memory is not as plentiful as desktop systems (recent survey of Rust on embedded systems),
- Studies (here and here) have found that programs can be remarkably robust in the presence of errors. Developers’ everyday experience is that programs containing many coding mistakes regularly behave as expected most of the time.
If bounds checking is enabled on shipped applications, what should happen when a bounds violation is detected?
Many bounds violations are likely to be benign, and a few not so. Should users have the option of continuing program execution after a violation is flagged (assuming they have been trained to understand the program message they are seeing and are aware of the response options)?
Java programs ship with bounds checking enabled, but I have not seen any studies of user response to runtime errors.
The reason that C/C++ is the language used to write so many of the programs listed in vulnerability databases is that these languages are popular and widely used. The Rust security advisory database contains few entries because few widely used programs are written in Rust. It’s possible to write unsafe code in Rust, just like C/C++, and studies find that developers regularly write such code and security risks exist within the Rust ecosystem, just like C/C++.
There have been various attempts to implement bounds checking in x86
processors. Intel added the MPX instruction, but there were problems with the specification, and support was discontinued in 2019.
The CHERI hardware discussed in the Whitehouse report is not yet commercially available, but organizations are working towards commercial products.
Software engineering experiments: sell the idea, not the results
A new paper investigates “… the feasibility of stealthily introducing vulnerabilities in OSS via hypocrite commits (i.e., seemingly beneficial commits that in fact introduce other critical issues).” Their chosen Open source project was the Linux kernel, and they submitted three patches to the kernel review process.
This interesting idea blew up in their faces, when the kernel developers deduced that they were being experimented on (they obviously don’t have a friend on the inside). The authors have come out dodging and weaving.
What can be learned by reading the paper?
Firstly, three ‘hypocrite commits’ is not enough submissions to do any meaningful statistical analysis. I suspect it’s a convenience sample, a common occurrence in software engineering research. The authors sell three as a proof-of-concept.
How many of the submitted patches passed the kernel review process?
The paper does not say. The first eight pages provide an introduction to the Open source development model, the threat model for introducing vulnerabilities, and the characteristics of vulnerabilities that have been introduced (presumably by accident). This is followed by 2.5 pages of background and setup of the experiment (labelled as a proof-of-concept).
The paper then switches (section VII) to discussing a different, but related, topic: the lifetime of (unintended) vulnerabilities in patches that had been accepted (which I think should have been the topic of the paper. This interesting discussion is 1.5 pages; also see The life and death of statically detected vulnerabilities: An empirical study, covered in figure 6.9 in my book.
The last two pages discuss mitigation, related work, and conclusion (“…a proof-of-concept to safely demonstrate the practicality of hypocrite commits, and measured and quantified the risks.”; three submissions is not hard to measure and quantify, but the results are not to be found in the paper).
Having the paper provide the results (i.e., all three commits spotted, and a very negative response by those being experimented on) would have increased the chances of negative reviewer comments.
Over the past few years I have started noticing this kind of structure in software engineering papers, i.e., extended discussion of an interesting idea, setup of experiment, and cursory or no discussion of results. Many researchers are willing to spend lots of time discussing their ideas, but are unwilling to invest much time in the practicalities of testing them. Some reviewers (who decide whether a paper is accepted to publication) don’t see anything wrong with this approach, e.g., they accept these kinds of papers.
Software engineering research remains a culture of interesting ideas, with evidence being an optional add-on.
Linux has a sleeper agent working as a core developer
The latest news from Wikileaks, that GCHQ, the UK’s signal intelligence agency, has a sleeper agent working as a trusted member of the Linux kernel core development team should not come as a surprise to anybody.
The Linux kernel is embedded as a core component inside many critical systems; the kind of systems that intelligence agencies and other organizations would like full access.
The open nature of Linux kernel development makes it very difficult to surreptitiously introduce a hidden vulnerability. A friendly gatekeeper on the core developer team is needed.
In the Open source world, trust is built up through years of dedicated work. Funding the right developer to spend many years doing solid work on the Linux kernel is a worthwhile investment. Such a person eventually reaches a position where the updates they claim to have scrutinized are accepted into the codebase without a second look.
The need for the agent to maintain plausible deniability requires an arm’s length approach, and the GCHQ team made a wise choice in targeting device drivers as cost-effective propagators of hidden weaknesses.
Writing a device driver requires the kinds of specific know-how that is not widely available. A device driver written by somebody new to the kernel world is not suspicious. The sleeper agent has deniability in that they did not write the code, they simply ‘failed’ to spot a well hidden vulnerability.
Lack of know-how means that the software for a new device is often created by cutting-and-pasting code from an existing driver for a similar chip set, i.e., once a vulnerability has been inserted it is likely to propagate.
Perhaps it’s my lack of knowledge of clandestine control of third-party computers, but the leak reveals the GCHQ team having an obsession with state machines controlled by pseudo random inputs.
With their background in code breaking, I appreciate that GCHQ have lots of expertise to throw at doing clever things with pseudo random numbers (other than introducing subtle flaws in public key encryption).
What about the possibility of introducing non-random patterns in randomised storage layout algorithms (he says, waving his clueless arms around)?
Which of the core developers is most likely to be the sleeper agent? His codename, Basil Brush, suggests somebody from the boomer generation, or perhaps reflects some personal characteristic; it might also be intended to distract.
What steps need to be taken to prevent more sleeper agents joining the Linux kernel development team?
Requiring developers to provide a record of their financial history (say, 10-years worth), before being accepted as a core developer, will rule out many capable people. Also, this approach does not filter out ideologically motivated developers.
The world may have to accept that intelligence agencies are the future of major funding for widely used Open source projects.
Update
Turns out the sleeper agent was working on xz.
MI5 agent caught selling Huawei exploits on Russian hacker forums
An MI5 agent has been caught selling exploits in Huawei products, on an underground Russian hacker forum (a paper analyzing the operation of these forums; perhaps the researchers were hired as advisors). How did this news become public? A reporter heard Mr Wang Kit, a senior Huawei manager, complaining about not receiving a percentage of the exploit sale, to add to his quarterly sales report. A fair point, given that Huawei are funding a UK centre to search for vulnerabilities.
The ostensive purpose of the Huawei cyber security evaluation centre (funded by Huawei, but run by GCHQ; the UK’s signals intelligence agency), is to allay UK fears that Huawei have added back-doors to their products, that enable the Chinese government to listen in on customer communications.
If this cyber centre finds a vulnerability in a Huawei product, they may or may not tell Huawei about it. Obviously, if it’s an exploitable vulnerability, and they think that Huawei don’t know about it, they could pass the exploit along to the relevant UK government department.
If the centre decides to tell Huawei about the vulnerability, there are two good reasons to first try selling it, to shady characters of interest to the security services:
- having an exploit to sell gives the person selling it credibility (of the shady technical kind), in ecosystems the security services are trying to penetrate,
- it increases Huawei’s perception of the quality of the centre’s work; by increasing the number of exploits found by the centre, before they appear in the wild (the centre has to be careful not to sell too many exploits; assuming they manage to find more than a few). Being seen in the wild adds credibility to claims the centre makes about the importance of an exploit it discovered.
How might the centre go about calculating whether to hang onto an exploit, for UK government use, or to reveal it?
The centre’s staff could organized as two independent groups; if the same exploit is found by both groups, it is more likely to be found by other hackers, than an exploit found by just one group.
Perhaps GCHQ knows of other groups looking for Huawei exploits (e.g., the NSA in the US). Sharing information about exploits found, provides the information needed to more accurately estimate the likelihood of others discovering known exploits.
How might Huawei estimate the number of exploits MI5 are ‘selling’, before officially reporting them? Huawei probably have enough information to make a good estimate of the total number of exploits likely to exist in their products, but they also need to know the likelihood of discovering an exploit, per man-hour of effort. If Huawei have an internal team searching for exploits, they might have the data needed to estimate exploit discovery rate.
Another approach would be for Huawei to add a few exploits to the code, and then wait to see if they are used by GCHQ. In fact, if GCHQ accuse Huawei of adding a back-door to enable the Chinese government to spy on people, Huawei could claim that the code was added to check whether GCHQ was faithfully reporting all the exploits it found, and not keeping some for its own use.
The 2019 Huawei cyber security evaluation report
The UK’s Huawei cyber security evaluation centre oversight board has released it’s 2019 annual report.
The header and footer of every page contains the text “SECRET”“OFFICIAL”, which I assume is its UK government security classification. It lends an air of mystique to what is otherwise a meandering management report.
Needless to say, the report contains the usually puffery, e.g., “HCSEC continues to have world-class security researchers…”. World class at what? I hear they have some really good mathematicians, but have serious problems attracting good software engineers (such people can be paid a lot more, and get to do more interesting work, in industry; the industry demand for mathematicians, outside of finance, is weak).
The most interesting sentence appears on page 11: “The general requirement is that all staff must have Developed Vetting (DV) security clearance, …”. Developed Vetting, is the most detailed and comprehensive form of security clearance in UK government (to quote Wikipedia).
Why do the centre’s staff have to have this level of security clearance?
The Huawei source code is not that secret (it can probably be found online, lurking in the dark corners of various security bulletin boards).
Is the real purpose of this cyber security evaluation centre, to find vulnerabilities in the source code of Huawei products, that GCHQ can then use to spy on people?
Or perhaps, this centre is used for training purposes, with staff moving on to work within GCHQ, after they have learned their trade on Huawei products?
The high level of security clearance applied to the centre’s work is the perfect smoke-screen.
The report claims to have found “Several hundred vulnerabilities and issues…”; a meaningless statement, e.g., this could mean one minor vulnerability and several hundred spelling mistakes. There is no comparison of the number of vulnerabilities found per effort invested, no comparison with previous years, no classification of the seriousness of the problems found, no mention of Huawei’s response (i.e., did Huawei agree that there was a problem).
How many vulnerabilities did the centre find that were reported by other people, e.g., the National Vulnerability Database? This information would give some indication of how good a job the centre was doing. Did this evaluation centre find the Huawei vulnerability recently disclosed by Microsoft? If not, why not? And if they did, why isn’t it in the 2019 report?
What about comparing the number of vulnerabilities found in Huawei products against the number found in vendors from the US, e.g., CISCO? Obviously back-doors placed in US products, at the behest of the NSA, need not be counted.
There is some technical material, starting on page 15. The configuration and component lifecycle management issues raised, sound like good points, from a cyber security perspective. From a commercial perspective, Huawei want to quickly respond to customer demand and a dynamic market; corners are likely to be cut off good practices every now and again. I don’t understand why the use of an unnamed real-time operating system was flagged: did some techie gripe slip through management review? What is a C preprocessor macro definition doing on page 29? This smacks of an attempt to gain some hacker street-cred.
Reading between the lines, I get the feeling that Huawei has been ignoring the centre’s recommendations for changes to their software development practices. If I were on the receiving end, I would probably ignore them too. People employed to do security evaluation are hired for their ability to find problems, not for their ability to make things that work; also, I imagine many are recent graduates, with little or no practical experience, who are just repeating what they remember from their course work.
Huawei should leverage its funding of a GCHQ spy training centre, to get some positive publicity from the UK government. Huawei wants people to feel confident that they are not being spied on, when they use Huawei products. If the government refuses to play ball, Huawei should shift its funding to a non-government, open evaluation center. Employees would not need any security clearance and would be free to give their opinions about the presence of vulnerabilities and ‘spying code’ in the source code of Huawei products.
Does public disclosure of vulnerabilities improve vendor response?
Does public disclosure of vulnerabilities in vendor products result in them releasing a fix more quickly, compared to when the vulnerability is only disclosed to the vendor (i.e., no public disclosure)?
A study by Arora, Krishnan, Telang and Yang investigated this question and made their data available 🙂 So what does the data have to say (its from the US National Vulnerability Database over the period 2001-2003)?
The plot below is a survival curve for disclosed vulnerabilities, the longer it takes to release a patch to fix a vulnerability, the longer it survives.
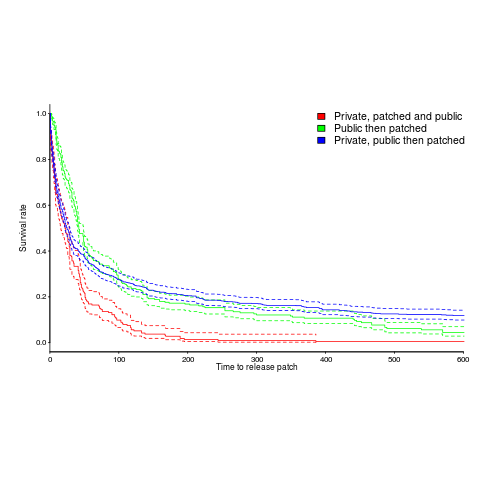
There is a popular belief that public disclosure puts pressure on vendors to release patchs more quickly, compared to when the public knows nothing about the problem. Yet, the survival curve above clearly shows publically disclosed vulnerabilities surviving longer than those only disclosed to the vendor. Is the popular belief wrong?
Digging around the data suggests a possible explanation for this pattern of behavior. Those vulnerabilities having the potential to cause severe nastiness tend not to be made public, but go down the path of private disclosure. Vendors prioritize those vulnerabilities most likely to cause the most trouble, leaving the less troublesome ones for another day.
This idea can be checked by building a regression model (assuming the necessary data is available and it is). In one way or another a lot of the data is censored (e.g., some reported vulnerabilities were not patched when the study finished); the Cox proportional hazards model can handle this (in fact, its the ‘standard’ technique to use for this kind of data).
This is a time dependent problem, some vulnerabilities start off being private and a public disclosure occurs before a patch is released, so there are some complications (see code+data for details). The first half of the output generated by R’s summary function, for the fitted model, is as follows:
Call:
coxph(formula = Surv(patch_days, !is_censored) ~ cluster(ID) +
priv_di * (log(cvss_score) + y2003 + log(cvss_score):y2002) +
opensource + y2003 + smallvendor + log(cvss_score):y2002,
data = ISR_split)
n= 2242, number of events= 2081
coef exp(coef) se(coef) robust se z Pr(>|z|)
priv_di 1.64451 5.17849 0.19398 0.17798 9.240 < 2e-16 ***
log(cvss_score) 0.26966 1.30952 0.06735 0.07286 3.701 0.000215 ***
y2003 1.03408 2.81253 0.07532 0.07889 13.108 < 2e-16 ***
opensource 0.21613 1.24127 0.05615 0.05866 3.685 0.000229 ***
smallvendor -0.21334 0.80788 0.05449 0.05371 -3.972 7.12e-05 ***
log(cvss_score):y2002 0.31875 1.37541 0.03561 0.03975 8.019 1.11e-15 ***
priv_di:log(cvss_score) -0.33790 0.71327 0.10545 0.09824 -3.439 0.000583 ***
priv_di:y2003 -1.38276 0.25089 0.12842 0.11833 -11.686 < 2e-16 ***
priv_di:log(cvss_score):y2002 -0.39845 0.67136 0.05927 0.05272 -7.558 4.09e-14 *** |
The explanatory variable we are interested in is priv_di, which takes the value 1 when the vulnerability is privately disclosed and 0 for public disclosure. The model coefficient for this variable appears at the top of the table and is impressively large (which is consistent with popular belief), but at the bottom of the table there are interactions with other variable and the coefficients are less than 1 (not consistent with popular belief). We are going to have to do some untangling.
cvss_score is a score, assigned by NIST, for the severity of vulnerabilities (larger is more severe).
The following is the component of the fitted equation of interest:
*(0.34+0.4*y2002)-1.4*y2003)}")
where:  is 0/1,
is 0/1, ") varies between 0.8 and 2.3 (mean value 1.8),
varies between 0.8 and 2.3 (mean value 1.8),  and
and  are 0/1 in their respective years.
are 0/1 in their respective years.
Applying hand waving to average away the variables:
)} right e^{{priv~di}(1.6-0.6-(0.7/3+1.4/3))} right e^{{priv~di}*0.3}")
gives a (hand waving mean) percentage increase of *100 right 35%") , when
, when priv_di changes from zero to one. This model is saying that, on average, patches for vulnerabilities that are privately disclosed take 35% longer to appear than when publically disclosed
The percentage change of patch delivery time for vulnerabilities with a low cvvs_score is around 90% and for a high cvvs_score is around 13% (i.e., patch time of vulnerabilities assigned a low priority improves a lot when they are publically disclosed, but patch time for those assigned a high priority is slightly improved).
I have not calculated 95% confidence bounds, they would be a bit over the top for the hand waving in the final part of the analysis. Also the general quality of the model is very poor; Rsquare= 0.148 is reported. A better model may change these percentages.
Has the situation changed in the 15 years since the data used for this analysis? If somebody wants to piece the necessary data together from the National Vulnerability Database, the code is ready to go (ok, some of the model variables may need updating).
Update: Just pushed a model with Rsquare= 0.231, showing a 63% longer patch time for private disclosure.
Hiring experts is cheaper in the long run
The SAMATE (Software Assurance Metrics And Tool Evaluation) group at the US National Institute of Standards and Technology recently started hosting a new version of test suites for checking how good a job C/C++/Java static analysis tools do at detecting vulnerabilities in source code. The suites were contributed by the NSA‘s Center for Assured Software.
Other test suites hosted by SAMATE contain a handful of tests and have obviously been hand written, one for each kind of vulnerability. These kind of tests are useful for finding out whether a tool detects a given problem or not. In practice problems occur within a source code context (e.g., control flow path) and a tool’s ability to detect problems in a wide range of contexts is a crucial quality factor. The NSA’s report on the methodology used looked good and with the C/C++ suite containing 61,387 tests it was obviously worth investigating.
Summary: Not a developer friendly test suite that some tools will probably fail to process because it exceeds one of their internal limits. Contains lots of minor language infringements that could generate many unintended (and correct) warnings.
Recommendation: There are people in the US who know how to write C/C++ test suites, go hire some of them (since this is US government money there are probably rules that say it has to go to US companies).
I’m guessing that this test suite was written by people with a high security clearance and a better than average knowledge of C/C++. For this kind of work details matter and people with detailed knowledge are required.
Another recommendation: Pay compiler vendors to add checks to their compilers. The GCC people get virtually no funding to do front end work (nearly all funding comes from vendors wanting backend support). How much easier it would be for developers to check their code if they just had to toggle a compiler flag; installing another tool introduces huge compatibility and work flow issues.
I had this conversation with a guy from GCHQ last week (the UK equivalent of the NSA) who are in the process of spending £5 million over the next 3 years on funding research projects. I suspect a lot of this is because they want to attract bright young things to work for them (student sponsorship appears to be connected with the need to pass a vetting process), plus universities are always pointing out how more research can help (they are hardly likely to point out that research on many of the techniques used in practice was done donkey’s years ago).
Some details
Having over 379,000 lines in the main function is not a good idea. The functions used to test each vulnerability should be grouped into a hierarchy; main calling functions that implement say the top 20 categories of vulnerability, each of these functions containing calls to the next level down and so on. This approach makes it easy for the developer to switch in/out subsets of the tests and also makes it more likely that the tool will not hit some internal limit on function size.
The following log string is good in theory but has a couple of practical problems:
printLine("Calling CWE114_Process_Control__w32_char_connect_socket_03_good();"); CWE114_Process_Control__w32_char_connect_socket_03_good(); |
C89 (the stated version of the C Standard being targeted) only requires identifiers to be significant to 32 characters, so differences in the 63rd character might be a problem. From the readability point of view it is a pain to have to check for values embedded that far into a string.
Again the overheads associated with storing so many strings of that length might cause problems for some tools, even good ones that might be doing string content scanning and checking.
The following is a recurring pattern of usage and has undefined behavior that is independent of the vulnerability being checked for. The lifetime of the variable shortBuffer terminates at the curly brace, }, and who knows what might happen if its address is accessed thereafter.
data = NULL; { /* FLAW: Point data to a short */ short shortBuffer = 8; data = &shortBuffer; } CWE843_Type_Confusion__short_68_badData = data; |
A high quality tool would report the above problem, which occurs in several tests classified as GOOD, and so appear to be failing (i.e., generating a warning when none should be generated).
The tests contain a wide variety of minor nits like this that the higher quality tools are likely to flag.
February 2012 news in the programming language standard’s world
Yesterday I was at the British Standards Institute for a meeting of the programming languages committee. Some highlights and commentary:
- The first Technical Corrigendum (bug fixes, 47 of them) for Fortran 2008 was approved.
- The Lisp Standard working group was shutdown, through long standing lack of people interested in taking part; this happened at the last SC22 meeting, the UK does not have such sole authority.
- WG14 (C Standard) has requested permission to start a new work item to create a new annex to the standard containing a Secure Coding Standard. Isn’t this the area of expertise of WG23 (Language vulnerabilities)? Well, yes; but when the US Department of Homeland Security is throwing money at cyber security increasing the number of standards’ groups working on the topic creates more billable hours for consultants.
- WG21 (C++ Standard) had 73 people at their five day meeting last week (ok, it was in Hawaii). Having just published a 1,300+ page Standard which no compiler yet comes close to implementing they are going full steam ahead creating new features for a revised standard they aim to publish in 2017. Does the “Hear about the upcoming features in C++” blogging/speaker circuit/consulting gravy train have that much life left in it? We will see.
The BSI building has new lifts (elevators in the US). To recap, lifts used to work by pressing a button to indicate a desire to change floors, a lift would arrive, once inside one or more people needed press buttons specifying destination floor(s). Now the destination floor has to be specified in advance, a lift arrives and by the time you have figured out there are no buttons to press on the inside of the lift the doors open at the desired floor. What programming language most closely mimics this new behavior?
Mimicking most languages of the last twenty years the ground floor is zero (I could not find any way to enter a G). This rules out a few languages, such as Fortran and R.
A lift might be thought of as a function that can be called to change floors. The floor has to be specified in advance and cannot be changed once in the lift, partial specialization of functions and also the lambda calculus springs to mind.
In a language I just invented:
// The lift specified a maximum of 8 people lift = function(p_1, p_2="", p_3="", p_4="", p_5="", p_6="", p_7="", p_8="") {...} // Meeting was on the fifth floor first_passenger_5th_floor = function lift(5); second_passenger_4th_floor = function first_passenger_fifth_floor(4); |
the body of the function second_passenger_4th_floor is a copy of the body of lift with all the instances of p_1 and p_2 replaced by the 5 and 4 respectively.
Few languages have this kind of functionality. The one that most obviously springs to mind is Lisp (partial specialization of function templates in C++ does not count because they are templates that are still in need of an instantiation). So the ghost of the Lisp working group lives on at BSI in their lifts.
Recent Comments