Archive
Local variable naming: some previously unexplored factors
Naming is a complicated topic, with factors including the semantic associations triggered by a name in the developer’s mind (e.g., arithmetic or bitwise operand), visual similarity to other identifiers, and usability (e.g., fewer characters).
Within a method, local variables coexist with other local variables that are visible over some number of lines of code.
Does the size of a method, in lines of code, or number of local variables have an impact on the names chosen (e.g., does the need to think up many different names affect the length of the name chosen)?
The paper A Large-Scale Investigation of Local Variable Names in Java Programs: Is Longer Name Better for Broader Scope Variable? appears to address this question, but the paper is not freely available (although its data is available). I learned about it, and its data, while reading another paper: Reanalysis of Empirical Data on Java Local Variables with Narrow and Broad Scope by Dror Feitelson.
The data was extracted from 1,000 popular Java projects, whose 46,283 files contained 637,077 local variables. The collected information includes: source filename, name, line variable defined, and line last used. Additional columns include the number of characters in the name, and a classification of the components of the name (e.g., dictionary word, abbreviation, number).
For the following analysis, I mapped each variable to a most likely associated method by coalescing overlapping variable defined/last-used ranges. A total of 204,503 methods were formed.
To analyse the impact of other local variables and method size on naming, we first need some information on the number of local variables defined in Java methods, and the number of lines contained in Java methods.
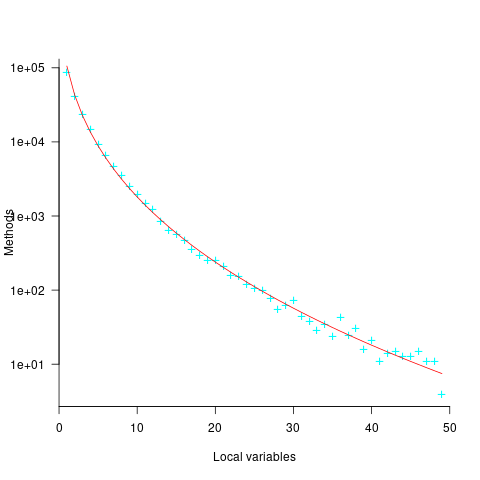
Approximately 50% of Java methods define five or fewer local variables. The plot below shows the number of Java methods defining a given number of local variables; the fitted regression equation, red line, has the form  , where
, where  is the number of local variables (code+data):
is the number of local variables (code+data):
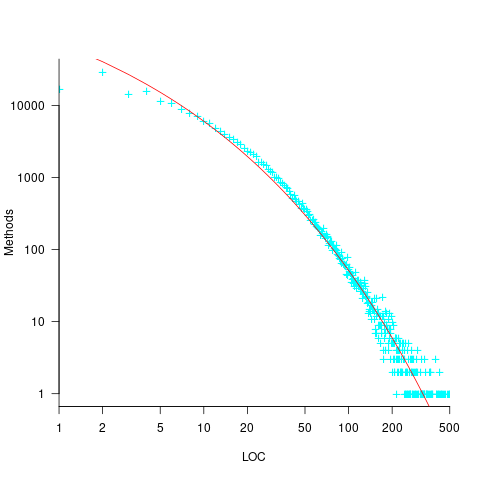
The reason most method define few local variables is that most methods only contain a few lines. The plot below shows the number of Java methods containing an estimated number of lines of code; the fitted regression equation, red line, has the form  , where
, where  is estimated lines of code (code+data):
is estimated lines of code (code+data):
The plot below shows the number of local variables against estimated lines of code in the corresponding method; the fitted regression equation, red line, has the form  , where is the number of local variables (code+data):
, where is the number of local variables (code+data):
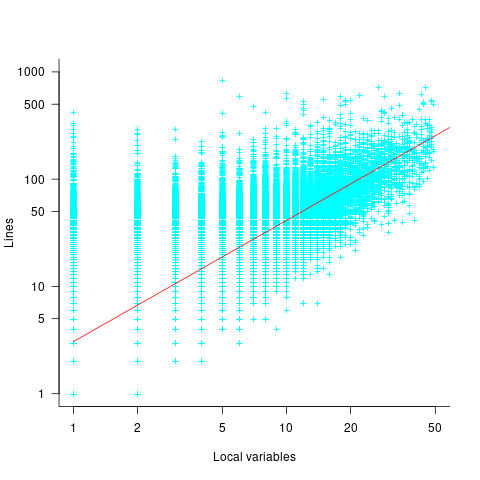
The strong connection between the number of lines of code and number of local variables in a method means that these two factors are effectively interchangeable in a regression model.
A local variable name is likely to be chosen before all, or even any, of the code that uses it is written. The hypothesis that the choice of a variable name is influenced by the length of a method, or the span of lines over which the variable is used, assumes some degree of foresight on the part of the developer.
The cited papers posed the question at the start of this post, and I built a variety of regression models looking to find those factors that are the best predictors of the length of the name (measured in characters or number of subcomponents), or the extent to which the length of the name predicted the amount of code over which it was used (either as a percentage or actual number of lines). Factors used include: order of variable definition in function, percentage of method code over which variable was used. See code+data.
The better models explained up to around 5% of the variance in the data. So there is an effect, but it’s very small. For instance, the model , where
, where  is the number of lines between variable definition and its last use, and
is the number of lines between variable definition and its last use, and  is the number of characters in its name, is effectively a relationship between the mean value of these two factors that captures some of the variance around their means.
is the number of characters in its name, is effectively a relationship between the mean value of these two factors that captures some of the variance around their means.
Unexpected experimental effects
The only way to find out the factors that effect developers’ source code performance is to carry out experiments where they are the subjects. Developer performance on even simple programming tasks can be effected by a large number of different factors. People are always surprised at the very small number of basic operations I ask developers to perform in the experiments I run. My reply is that only by minimizing the number of factors that might effect performance can I have any degree of certainty that the results for the factors I am interested in are reliable.
Even with what appear to be trivial tasks I am constantly surprised by the factors that need to be controlled. A good example is one of the first experiments I ever ran. I thought it would be a good idea to replicate, using a software development context, a widely studied and reliably replicated human psychological effect; when asked to learn and later recall/recognize a list of words people make mistakes. Psychologists study this problem because it provides a window into the operation structure of the human memory subsystem over short periods of time (of the order of at most tens of seconds). I wanted to find out what sort of mistakes developers would make when asked to remember information about a sequence of simple assignment statements (e.g.,
qbt = 6;).I carefully read the appropriate experimental papers and had created lists of variables that controlled for every significant factor (e.g., number of syllables, frequency of occurrence of the words in current English usage {performance is better for very common words}) and the list of assignment statements was sufficiently long that it would just overload the capacity of short term memory (about 2 seconds worth of sound).
The results contained none of the expected performance effects, so I ran the experiment again looking for different effects; nothing. A chance comment by one of the subjects after taking part in the experiment offered one reason why the expected performance effects had not been seen. By their nature developers are problem solvers and I had set them a problem that asked them to remember information involving a list of assignment statements that appeared to be beyond their short term memory capacity. Problem solvers naturally look for patterns and common cases and the variables in each of my carefully created list of assignment statements could all be distinguished by their first letter. Subjects did not need to remember the complete variable name, they just needed to remember the first letter (something I had not controlled for). Asking around I found that several other subjects had spotted and used the same strategy. My simple experiment was not simple enough!
I was recently reading about an experiment that investigated the factors that motivate developers to comment code. Subjects were given some code and asked to add additional functionality to it. Some subjects were given code containing lots of comments while others were given code containing few comments. The hypothesis was that developers were more likely to create comments in code that already contained lots of comments, and the results seemed to bear this out. However, closer examination of the answers showed that most subjects had cut and pasted chunks (i.e., code and comments) from the code they were given. So code the percentage of code in the problem answered mimicked that in the original code (in some cases subjects had complicated the situation by refactoring the code).