Archive
Census of general purpose computers installed in the 1960s
In the 1960s a small number of computer manufacturers sold a relatively small number of general purpose computers (IBM dominated the market). Between 1962 and 1974 the magazine Computers and Automation published a monthly census listing the total number of installed, and unfilled orders for, general purpose computers. A pdf of all the scanned census data is available on Bitsavers.
Over the last 10-years, I have made sporadic attempts to convert the data in this pdf to csv form. The available tools do a passable job of generating text, but the layout of the converted text is often very different from the visible layout presented by a pdf viewer. This difference is caused by the pdf2text tools outputting characters in the order in which they occur within the pdf. For example, if a pdf viewer shows the following text, with numbers showing the relative order of characters within the pdf file:
1 2 6
3 7
4 5 8 |
the output from pdf2text might be one of the four possibilities:
1 2 1 2 1 1
3 3 2 2
4 5 4 3 3
6 5 4 5 4
7 6 6 5
8 7 7 6
8 8 7
8 |
One cause of the difference is the algorithm pdf2text uses to decide whether characters occur on the same line, i.e., do they have the same vertical position on the same page, measured in points ( inch, or ≈ 0.353 mm)?
inch, or ≈ 0.353 mm)?
When a pdf is created by an application, characters on the same visual line usually have the same vertical position, and the extracted output follows a regular pattern. It’s just a matter of moving characters to the appropriate columns (editor macros to the rescue). Missing table entries complicate the process.
The computer census data comes from scanned magazines, and the vertical positions of characters on the same visual line are every so slightly different. This vertical variation effectively causes pdf2text to output the discrete character sequences on a variety of different lines.
A more sophisticated line assignment algorithm is needed. For instance, given the x/y position of each discrete character sequence, a fuzzy matching algorithm could assign the most likely row and column to each sequence.
The mupdf tool has an option to generate html, and this html contains the page/row/column values for each discrete character sequence, and it is possible to use this information to form reasonably laid out text. Unfortunately, the text on the scanned pages is not crisply sharp and mupdf produces o instead of 0, and l not 1, on a regular basis; too often for me to be interested in manually correctly the output.
Tesseract is the ocr tool of choice for many, and it supports the output of bounding box information. Unfortunately, running this software regularly causes my Linux based desktop to reboot.
I recently learned about Amazon’s Textract service, and tried it out. The results were impressive. Textract doesn’t just map characters to their position on the visible page, it is capable of joining multiple rows within a column and will insert empty strings if a column/row does not contain any characters. For instance, in the following image of the top of a page:

the column names are converted to "NAME OF MANUFACTURER","NAME OF COMPUTER", etc., and the empty first column/row are mapped to "".
The conversion is not quiet 100% accurate, but then the input is not 100% accurate; a few black smudges are treated as a single-quote or decimal point, and comma is sometimes treated as a fullstop. There were around 20 such mistakes in 11,000+ rows of numbers/names. There were six instances where two lines were merged into a single row, when the lines should have each been a separate row.
Having an essentially accurate conversion to csv available, does not remove the need for data cleaning. The image above contains two examples of entries that need to be corrected: the first column specifies that it is a continuation of a column on the previous page (over 12 different abbreviated forms of continued are used) Honeywell (cont'd) -> Honeywell, and other pages use a slightly different name for a particular computer DATA-matic 1000 -> Datamatic 1000. There are 350+ cleaning edits in my awk script that catch most issues (code+data).
How useful is this data?
Early computer census data in csv form is very rare, and now lots of it is available. My immediate use is completing a long-standing dataset conversion.
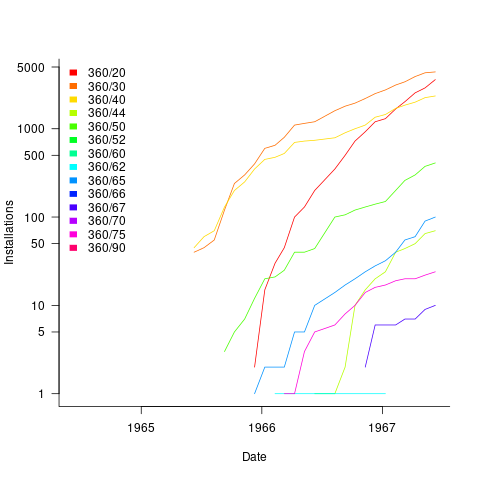
Obtaining the level of detail in this census, on a monthly basis, requires some degree of cooperation from the manufacturer. June 1967 appears to be the last time that IBM supplied detailed information, and later IBM census entries are listed as round estimates (and only for a few models).
The plot below shows the growth in the number of IBM 360 installations, for various models (unfilled orders date back to May 1964; code+data):
Grammar checking in 2018
I am a big fan of using tools to find problems quickly. Polishing the draft material for my evidence-based software engineering book, I have been finding an annoying number of grammatical mistakes :-(.
LanguageTool is what I use to check my grammar; it is the best tool of its kind that I know, and supports lots of different languages.
I also have an awk script that looks for new instances of previous mistakes I have made. It rarely flags anything, I seem to be in a continual state of making new grammatical mistakes.
Stung by a recent series is blatant mistakes, I have been searching for a better tool. What did I find:
- The 2014 Conference on Computational Natural Language Learning shared task was grammatical error correction,
- a bibliography of papers on grammatical error correction,
- LMGEC-Lite: the latest research tool (I will download the Billion Word Benchmark dataset, to build the 4G training dataset, from which the 10G language model is created, another day),
- a machine translation approach that automates grammatical error correction, i.e., rewrites what has been written. Perhaps I should use this tool on some of the software engineering papers I read, it could not make them any worse.
So, lots of interesting stuff, but nothing better that is usable.
I keep looking at the interesting things that spaCY can do (if you are looking to integrate language processing in your app, spaCY is currently the best language processing library). Does anybody know of grammar checking work being done using spaCY (LanguageTool is based around a parsing engine that is rather long in the tooth now)?
Anybody interested in organizing a grammar checking tool hack day in London?
Semantic pattern matching (Coccinelle)
I have just discovered Coccinelle a tool that claims to fill a remarkable narrow niche (providing semantic patch functionality; I have no idea how the name is pronounced) but appears to have a lot of other uses. The functionality required of a semantic patch is the ability to write source code patterns and a set of transformation rules that convert the input source into the desired output. What is so interesting about Coccinelle is its pattern matching ability and the ability to output what appears to be unpreprocessed source (it has to be told the usual compile time stuff about include directory paths and macros defined via the command line; it would be unfair of me to complain that it needs to build a symbol table).
Creating a pattern requires defining identifiers to have various properties (eg, an expression in the following example) followed by various snippets of code that specify the pattern to match (in the following <… …> represents a bracketed (in the C compound statement sense) don’t care sequence of code and the lines starting with +/- have the usual patch meaning (ie, add/delete line)). The tool builds an abstract syntax tree so urb is treated as a complete expression that needs to be mapped over to the added line).
@@ expression lock, flags; expression urb; @@ spin_lock_irqsave(lock, flags); <... - usb_submit_urb(urb) + usb_submit_urb(urb, GFP_ATOMIC) ...> spin_unlock_irqrestore(lock, flags); |
Coccinelle comes with a bunch of predefined equivalence relations (they are called isomophisms) so that constructs such as if (x), if (x != NULL) and if (NULL != x) are known to be equivalent, which reduces the combinatorial explosion that often occurs when writing patterns that can handle real-world code.
It is written in OCaml (I guess there had to be some fly in the ointment) and so presumably borrows a lot from CIL, perhaps in this case a version number of 0.1.3 is not as bad as it might sound.
My main interest is in counting occurrences of various kinds of patterns in source code. A short-term hack is to map the sought-for pattern to some unique character sequence and pipe the output through grep and wc. There does not seem to be any option to output a count of the matched patterns … yet 🙂
Recent Comments