Archive
One code path dominates method execution
A recurring claim is that most reported faults are the result of coding mistakes in a small percentage of a program’s source code, with the 80/20 ‘rule’ being cited for social confirmation. I think there is something to this claim, but that the percentages are not so extreme.
A previous post pointed out that reported faults are caused by users. The 80/20 observation can be explained by users only exercising a small percentage of a program’s functionality (a tiny amount of data supports this observation). Surprisingly, there are researchers who believe that a small percentage of the code has some set of characteristics which causes it to contain most of a program’s coding mistakes (this belief has the advantage that a lot of source code is easily accessible and can be analysed to produce papers).
To what extent does user input direct program execution towards a small’ish subset of the code available to be executed?
The recent paper: Monitoring the Execution of 14K Tests: Methods Tend to Have One Path That Is Significantly More Executed by Andre Hora counted the number of times each path through a method’s source code was executed, when the method was called, for the 5,405 methods in 25 Python programs. These programs were driven by their 14,177 tests, rather than user input. The paper is focused on testing, in particular developer that developers tend to focus on positive tests.
Test suites are supposed to exercise all of a program’s source, so it is to be expected that these measurements will show a wider dispersion of code coverage than might be expected of typical user input.
The measurements also include a count of the lines executed/not executed along each executed method path. No information is provided on the number of unexecuted paths.
Within a method, there is always going to one path through the code that is executed more often than any other path. What this study found is that the most common path is often executed many more times than the other paths. The plot below shows, for each method (each +), the percentage of all calls to a method where the most common path was executed, against the total number of executed paths for that method; red/blue lines are fitted power law/exponential regression models, and the grey line shows the case where percentage executed is the fraction for a given number of paths (code+data):
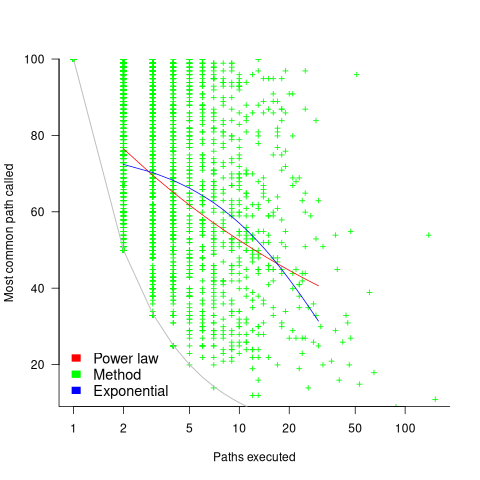
On average, the most common path is executed around four times more often than the second most commonly executed path.
While statistically significant, the fitted models do not explain much of the variance in the data. An argument can be made for either a power law and exponential distribution, and not having a feel for what to expect, I fitted both.
Non-error paths through a method have been found to be longer than the error paths. These measurements do not contain the information needed to attempt to replicate this finding.
New paths through a method are created by conditional statements, and the percentage of such statements in a method tends to be relatively constant across methods. The plot below shows the percentage of all calls to a method where the most common path was executed, where the method (each +) contains a given LOC; red/blue lines are fitted power law/exponential regression models (code+data):
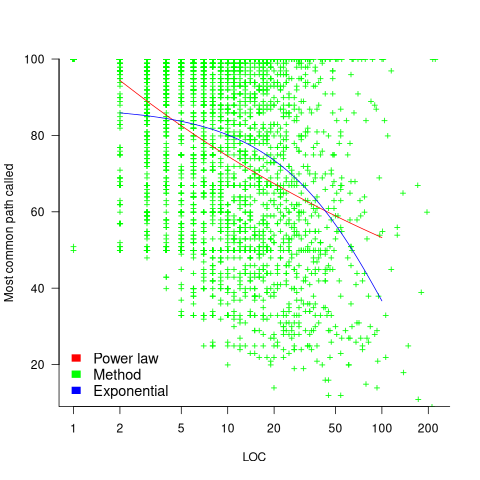
The models fitted to against LOC are better than those fitted against paths executed, but still not very good. A possible reason is that some methods will have unexecuted paths, LOC is a good proxy for total paths, and most common path percentage depends on total paths.
On average, 56% of a method’s LOC are executed along the most frequently executed path. When weighted by the number of method calls, the percentage is 48%.
The results of this study show that a call to most methods is likely to be dominated by the execution of one sequence of code. Another way that in which a small amount of code can dominate program execution is when most calls are to a small subset of the available methods. The plot below shows a density plot for the total number of calls to each method (code+data):

Around 62% of methods are called less than 100 times, while 2.6% are called over 10,000 times.
Mutation testing: its days in the limelight are over
How good a job does a test suite do in detecting coding mistakes in the program it tests?
Mutation testing provides one answer to this question. The idea behind mutation testing is to make a small change to the source code of the program under test (i.e., introduce a coding mistake), and then run the test suite through the mutated program (ideally one or more tests fail, as-in different behavior should be detected); rinse and repeat. The mutation score is the percentage of mutated programs that cause a test failure.
While Mutation testing is 50-years old this year (although the seminal paper did not get published until 1978), the computing resources needed to research it did not start to become widely available until the late 1980s. From then, until fuzz testing came along, mutation testing was probably the most popular technique studied by testing researchers. A collected bibliography of mutation testing lists 417 papers and 16+ PhD thesis (up to May 2014).
Mutation testing has not been taken up by industry because it tells managers what they already know, i.e., their test suite is not very good at finding coding mistakes.
Researchers concluded that the reason industry had not adopted mutation testing was that it was too resource intensive (i.e., mutate, compile, build, and run tests requires successively more resources). If mutation testing was less resource intensive, then industry would use it (to find out faster what they already knew).
Creating a code mutant is not itself resource intensive, e.g., randomly pick a point in the source and make a random change. However, the mutated source may not compile, or the resulting mutant may be equivalent to one created previously (e.g., the optimised compiled code is identical), or the program takes ages to compile and build; techniques for reducing the build overhead include mutating the compiler intermediate form and mutating the program executable.
Some changes to the source are more likely to be detected by a test suite than others, e.g., replacing <= by > is more likely to be detected than replacing it by < or ==. Various techniques for context dependent mutations have been proposed, e.g., handling of conditionals.
While mutation researchers were being ignored by industry, another group of researchers were listening to industry's problems with testing; automatic test case generation took off. How might different test case generators be compared? Mutation testing offers a means of evaluating the performance of tools that arrived on the scene (in practice, many researchers and tool vendors cite statement or block coverage numbers).
Perhaps industry might have to start showing some interest in mutation testing.
A fundamental concern is the extent to which mutation operators modify source in a way that is representative of the kinds of mistakes made by programmers.
The competent programmer hypothesis is often cited, by researchers, as the answer to this question. The hypothesis is that competent programmers write code/programs that is close to correct; the implied conclusion being that mutations, which are small changes, must therefore be like programmer mistakes (the citation often given as the source of this hypothesis discusses data selection during testing, but does mention the term competent programmer).
Until a few years ago, most analysis of fixes of reported faults looked at what coding constructs were involved in correcting the source code, e.g., 296 mistakes in TeX reported by Knuth. This information can be used to generate a probability table for selecting when to mutate one token into another token.
Studies of where the source code was changed, to fix a reported fault, show that existing mutation operators are not representative of a large percentage of existing coding mistakes; for instance, around 60% of 290 source code fixes to AspectJ involved more than one line (mutations usually involve a single line of source {because they operate on single statements and most statements occupy one line}), another study investigating many more fixes found only 10% of fixes involved one line, and similar findings for a study of C, Java, Python, and Haskell (a working link to the data, which is a bit disjointed of a mess).
These studies, which investigated the location of all the source code that needs to be changed, to fix a mistake, show that existing mutation operators are not representative of most human coding mistakes. To become representative, mutation operators need to be capable of making coupled changes across multiple lines/functions/methods and even files.
While arguments over the validity of the competent programmer hypothesis rumble on, the need for multi-line changes remains.
Given the lack of any major use-cases for mutation testing, it does not look like it is worth investing lots of resources on this topic. Researchers who have spent a large chunk of their career working on mutation testing will probably argue that you never know what use-cases might crop up in the future. In practice, mutation research will probably fade away because something new and more interesting has come along, i.e., fuzz testing.
There will always be niche use-cases for mutation. For instance, how likely is it that a random change to the source of a formal proof will go unnoticed by its associated proof checker (i.e., the proof checking tool output remains unchanged)?
A study based on mutating the source of Coq verification projects found that 7% of mutations had no impact on the results.
Hiring experts is cheaper in the long run
The SAMATE (Software Assurance Metrics And Tool Evaluation) group at the US National Institute of Standards and Technology recently started hosting a new version of test suites for checking how good a job C/C++/Java static analysis tools do at detecting vulnerabilities in source code. The suites were contributed by the NSA‘s Center for Assured Software.
Other test suites hosted by SAMATE contain a handful of tests and have obviously been hand written, one for each kind of vulnerability. These kind of tests are useful for finding out whether a tool detects a given problem or not. In practice problems occur within a source code context (e.g., control flow path) and a tool’s ability to detect problems in a wide range of contexts is a crucial quality factor. The NSA’s report on the methodology used looked good and with the C/C++ suite containing 61,387 tests it was obviously worth investigating.
Summary: Not a developer friendly test suite that some tools will probably fail to process because it exceeds one of their internal limits. Contains lots of minor language infringements that could generate many unintended (and correct) warnings.
Recommendation: There are people in the US who know how to write C/C++ test suites, go hire some of them (since this is US government money there are probably rules that say it has to go to US companies).
I’m guessing that this test suite was written by people with a high security clearance and a better than average knowledge of C/C++. For this kind of work details matter and people with detailed knowledge are required.
Another recommendation: Pay compiler vendors to add checks to their compilers. The GCC people get virtually no funding to do front end work (nearly all funding comes from vendors wanting backend support). How much easier it would be for developers to check their code if they just had to toggle a compiler flag; installing another tool introduces huge compatibility and work flow issues.
I had this conversation with a guy from GCHQ last week (the UK equivalent of the NSA) who are in the process of spending £5 million over the next 3 years on funding research projects. I suspect a lot of this is because they want to attract bright young things to work for them (student sponsorship appears to be connected with the need to pass a vetting process), plus universities are always pointing out how more research can help (they are hardly likely to point out that research on many of the techniques used in practice was done donkey’s years ago).
Some details
Having over 379,000 lines in the main function is not a good idea. The functions used to test each vulnerability should be grouped into a hierarchy; main calling functions that implement say the top 20 categories of vulnerability, each of these functions containing calls to the next level down and so on. This approach makes it easy for the developer to switch in/out subsets of the tests and also makes it more likely that the tool will not hit some internal limit on function size.
The following log string is good in theory but has a couple of practical problems:
printLine("Calling CWE114_Process_Control__w32_char_connect_socket_03_good();"); CWE114_Process_Control__w32_char_connect_socket_03_good(); |
C89 (the stated version of the C Standard being targeted) only requires identifiers to be significant to 32 characters, so differences in the 63rd character might be a problem. From the readability point of view it is a pain to have to check for values embedded that far into a string.
Again the overheads associated with storing so many strings of that length might cause problems for some tools, even good ones that might be doing string content scanning and checking.
The following is a recurring pattern of usage and has undefined behavior that is independent of the vulnerability being checked for. The lifetime of the variable shortBuffer terminates at the curly brace, }, and who knows what might happen if its address is accessed thereafter.
data = NULL; { /* FLAW: Point data to a short */ short shortBuffer = 8; data = &shortBuffer; } CWE843_Type_Confusion__short_68_badData = data; |
A high quality tool would report the above problem, which occurs in several tests classified as GOOD, and so appear to be failing (i.e., generating a warning when none should be generated).
The tests contain a wide variety of minor nits like this that the higher quality tools are likely to flag.
Recent Comments