Archive
Estimating variance when measuring source
Yesterday I finally delivered a paper on if/switch usage measurements to the ACCU magazine editor and today I read about a switch statement usage that, if common, would invalidate a chunk of my results. Does anything jump out at you in the following snippet?
switch (x) { case 1: { z++; ... break; } ... |
Yes, those { } delimiting the case-labeled statement sequence. A quick check of my C source benchmarks showed this usage occurring in around 1% of case-labels. Panic over.
What is the statistical significance, i.e., variance, of that 1%? Have I simply measured an unrepresentative sample, what would be a representative sample and what would be the expected variance within a representative sample?
I am interested in commercial software development, and so I have selected half a dozen or so largish code bases as my source benchmark, preferably written in a commercial environment even if currently available as Open source. I would prefer this benchmark to be an order of magnitude larger, and perhaps I will get around to adding more programs soon.
My if/switch measurements were aimed at finding usage characteristics that varied between the two kinds of selection statements. One characteristic measured was the number of equality tests in the associated controlling expression. For instance, in:
if (x == 1 || x == 2) z--; else if (x == 3) z++; |
the first controlling expression contains two equality tests, and the second one equality test.
Plotting the percentage of equality tests that occur in the controlling expressions of if-if/if-else-if sequences and switch statements, we get the following:
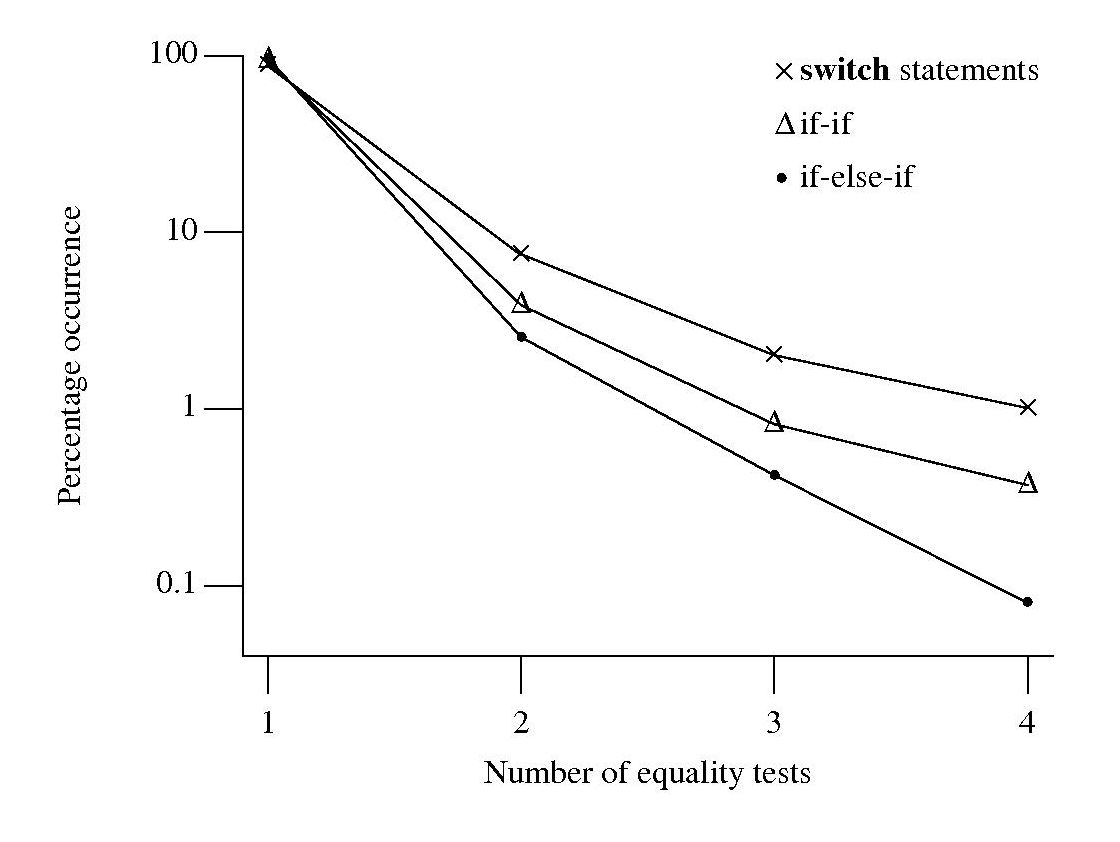
Do these results indicate that if-if/if-else-if sequences and switch statements differ in the number of equality tests contained in their controlling expressions? If I measured a completely different set of source code, would the results be very different?
To answer this question, a probability model is needed. Take as an example, the controlling expressions present in an if-if sequence. If each controlling expression is independent of the others, then the probability of two equality tests, for instance, occurring in any of these expressions is constant and thus given a large sample the distribution of two equality tests in the source has a binomial distribution. The same argument can be applied to other numbers of equality tests and other kinds of sequence.

For each measurement point in the above plot the associated error bars span the square-root of the variance of that point (assuming a binomial distribution, for a normal distribution the length of this span is known as the standard deviation). The error bars overlap, suggesting that the apparent difference in percentage of equality tests in each kind of sequence is not statistically significant.
The existence of some dependency between controlling expression equality tests would invalidate this simply analysis, or at least reduce its reliability. I did notice that in a sequence that containing two equality tests, the controlling expression that contained it tended to appear later in the sequence (the reverse of the example given above). Did I notice this because I tend to write this way? A question for another day.
Using Coccinelle to match if sequences
I have been using Coccinelle to obtain measurements of various properties of C if and switch statements. It is rare to find a tool that does exactly what is desired, but it is often possible to combine various tools to achieve the desired result.
I am interested in measuring sequences of if-else-if statements and one of the things I wanted to know was how many sequences of a given length occurred. Writing a pattern for each possible sequence was the obvious solution, but what is the longest sequence I should search for? A better solution is to use a pattern that matches short sequences and writes out the position (line/column number) where they occur in the code, as in the following Coccinelle pattern:
@ if_else_if_else @ expression E_1, E_2; statement S_1, S_2, S_3; position p_1, p_2; @@ if@p_1 (E_1) S_1 else if@p_2 (E_2) S_2 else S_3 @ script:python @ expr_1 << if_else_if_else.E_1; expr_2 << if_else_if_else.E_2; loc_1 << if_else_if_else.p_1; loc_2 << if_else_if_else.p_2; @@ print "--- ifelseifelse" print loc_1[0].line, " ", loc_1[0].column, " ", expr_1 print loc_2[0].line, " ", loc_2[0].column, " ", expr_2 |
noting that in a sequence of source such as:
if (x == 1) stmt_1; else if (x == 2) stmt_2; else if (x == 3) stmt_3; |
the tokens if (x == 2) will be matched twice, the first setting the position metavariable p_2 and then setting p_1. An awk script was written to read the Coccinelle output and merge together adjacent pairs of matches that were part of a longer if-else-if sequence.
The first pattern did not concern itself with the form of the controlling expression, it simply wrote it out. A second set of patterns was used to match those forms of controlling expression I was interested in, but first I had to convert the output into syntactically correct C so that it could be processed by Coccinelle. Again awk came to the rescue, converting the output:
--- ifelseifelse 186 2 op == FFEBLD_opSUBRREF 191 7 op == FFEBLD_opFUNCREF --- ifelseifelse 1094 3 anynum && commit 1111 8 ( c [ colon + 1 ] == '*' ) && commit |
into a separate function for each matched sequence:
void f_1(void) { // --- ifelseifelse /* 186 2 */ op == FFEBLD_opSUBRREF ; /* 191 7 */ op == FFEBLD_opFUNCREF ; } void f_2(void) { // --- ifelseifelse /* 1094 3 */ anynum && commit ; /* 1111 8 */ ( c [ colon + 1 ] == '*' ) && commit ; } |
The Coccinelle pattern:
@ if_eq_1 @ expression E_1; constant C_1, C_2; position p_1, p_2; @@ E_1 == C_1@p_1 ; E_1 == C_2@p_2 ; @ script:python @ expr_1<< if_eq_1.E_1; const_1 << if_eq_1.C_1; const_2 << if_eq_1.C_2; loc_1 << if_eq_1.p_1; loc_2 << if_eq_1.p_2; @@ print loc_1[0].line, " ", loc_1[0].column, " 3 ", expr_1, " == ", const_1 print loc_2[0].line, " ", loc_2[0].column, " 2 ", expr_1, " == ", const_2 |
matches a sequence of two statements which consist of an expression being compared for equality against a constant, with the expression being identical in both statements. Again positions were written out for post-processing, i.e., joining together matched sequences.
I was interested in any sequence of if-else-if that could be converted to an equivalent switch-statement. Equality tests against a constant is just one form of controlling expression that meets this requirement, another is the between operation. Separate patterns could be written and run over the generated C source containing the extracted controlling expressions.
Breaking down the measuring process into smaller steps reduced the amount of time needed to get a final result (with Coccinelle 0.1.19 the first pattern takes round 70 minutes, thanks to Julia Lawall‘s work to speed things up, an overhead that only has to occur once) and allows the same controlling expression patterns to be run against the output of both the if-else-if and if-if patterns.
At the end of this process I ended up with a list information (line numbers in source code and form of controlling expression) on if-statement sequences that could be rewritten as a switch-statement.
Recent Comments